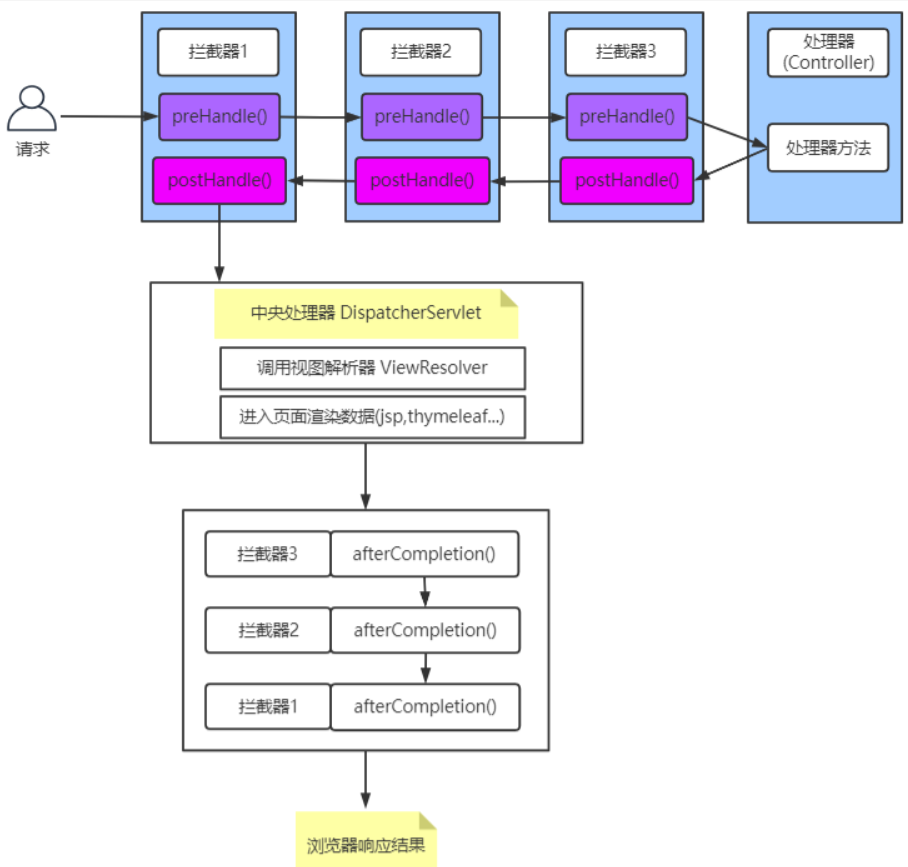
CLIP的底层架构是基于两个深度学习模型的组合:**图像编码器** 和 **文本编码器**,分别用来处理图像和文本数据。这两个编码器通过对比学习的方式进行联合训练,使图像和文本可以映射到共享的语义空间中。---### 1. **CLIP的架构核心** CLIP由以下两部分组成:#### **(1) 图像编码器** 用于提取图像的特征向量。 - **底层架构:**- CLIP支持使用两种不同的图像编码器:1. **ResNet**:一种经典的卷积神经网络(CNN),擅长提取图像的局部和全局特征。2. **Vision Transformer (ViT)**:一种基于Transformer架构的模型,利用自注意力机制,能够有效处理全局的图像特征。 - **作用:**- 接收输入图像(例如病理切片)并输出一个固定维度的向量,用于表示图像的语义特征。- ViT可以在较大的数据集上表现出比ResNet更强的泛化能力。#### **(2) 文本编码器** 用于提取文本的特征向量。 - **底层架构:**- CLIP的文本编码器基于 **Transformer**,类似于 GPT 或 BERT 的结构。Transformer使用多头自注意力机制,能够高效捕捉文本中单词之间的关系。 - **作用:**- 接收输入文本(例如“胃癌切片”)并将其转化为一个固定维度的向量,表示文本的语义信息。#### **(3) 对比学习目标** - 图像编码器和文本编码器分别提取特征后,CLIP使用 **对比损失(Contrastive Loss)** 来优化它们的输出。 - **机制:**- 将图像和文本的嵌入向量拉近(如果它们语义匹配)。- 将语义不相关的图像和文本嵌入向量拉远。 - **损失函数:** CLIP采用一种对比损失形式(InfoNCE),用来最大化匹配图像-文本对之间的相似性,同时最小化不匹配对之间的相似性。---### 2. **CLIP的详细流程** 1. **数据输入:**- 输入数据为图像-文本对,例如“一个全切片的肺癌组织图像”和对应的图像文件。 2. **特征提取:**- 图像编码器(ResNet或ViT)将图像处理为向量。- 文本编码器(Transformer)将文本处理为向量。 3. **相似性计算:**- 通过 **余弦相似度** 比较图像和文本的向量。- 目标是让匹配的图像和文本对在语义空间中的距离最小化,不匹配的对距离最大化。 4. **损失优化:**- 采用对比损失(Contrastive Loss)训练,使模型能够学到图像和文本之间的对应关系。---### 3. **底层模型设计的优势** #### **(1) Transformer架构的优势** - **全局注意力机制:** Transformer可以关注整个输入序列(文本或图像的所有像素),而非局部区域。 - **适应文本和图像:** Transformer既适用于自然语言处理(文本编码器),也可以用于图像分析(ViT)。 - **高效并行计算:** 通过多头注意力机制,Transformer能够并行处理大规模数据。#### **(2) 对比学习的优势** - **无需大规模标注:** 对比学习通过图像-文本对进行训练,不需要像素级或分类标注。 - **泛化能力强:** CLIP可以很好地适应未见过的任务或数据集(例如,给定一个新图像生成相关描述,或根据文本描述找到相关图像)。---### 4. **CLIP架构的总结** CLIP将 **Transformer** 用于文本和图像的编码,并利用 **对比学习** 将两者嵌入到统一的语义空间中。这种架构的关键在于: - 同时高效处理图像和文本。 - 通过大规模数据对模型进行训练,具备强大的跨任务泛化能力。 - ViT(Vision Transformer)和传统的ResNet架构在处理图像时提供了灵活性。如果你需要更深入的代码实现或公式推导,我也可以进一步提供!
具体解决的问题 该论文解决了癌症诊断和预后预测中病理图像分析的泛化性问题。传统的人工智能病理图像分析方法通常针对特定任务设计,存在以下主要问题:依赖于大量标注数据,难以处理多种癌症类型或不同病理实验室生成的图像。 泛化能力差,容易受图像来源、扫描仪和处理方法的影响。 论文提出了一种名为“CHIEF”的通用病理基础模型,旨在通过弱监督学习和自监督学习,从多种癌症的病理图像中提取可泛化的特征,用于癌细胞检测、肿瘤起源识别、基因组特征预测以及生存期预后等多种任务。 采用的方法与基于的原理 方法:双重预训练策略: 无监督学习:对来自19个解剖部位的1500万未标注的图像切片进行特征提取,捕获细胞微观形态特征。 弱监督学习:在60,530张全切片图像(44TB数据)上进行弱监督训练,捕获组织和癌症类型之间的全局模式差异。 弱监督全切片分析: 设计了一种高效的切片特征聚合框架,利用来自不同区域的组织信息提升癌症类型的预测能力。 跨任务优化: 基于模型提取的病理图像特征,针对具体任务(如癌症检测、基因组预测)进行微调。 基于的技术与原理:机器学习与深度学习:主要利用弱监督学习与自监督学习,减少对标注数据的依赖。 图像编码器与文本编码器结合:通过Contrastive Language-Image Pretraining (CLIP) 模型,结合解剖部位信息和图像特征,生成综合表示向量。 领域适配与泛化性提升:通过从多个国家和机构的数据中学习,增强模型对不同来源图像的适应能力。 创新点通用病理特征提取器: CHIEF作为一个多功能的特征提取框架,能够在多种癌症和任务之间迁移,提升了模型的通用性。 弱监督与无监督预训练结合: 双重预训练策略结合了微观细胞特征和组织上下文信息,使得模型对病理切片的表征更加全面。 高效的全切片聚合框架: 优化了弱监督学习中图像区域特征的整合方式,超越了传统注意力聚合方法。 跨领域泛化性能: CHIEF模型在来自24家医院和32个独立数据集的验证中,显著提升了对不同癌症组织的检测和预测性能(提升幅度高达36.1%)。 临床实用性增强: CHIEF可以实现对癌症起源、基因组特征和生存期的预测,为癌症诊断与治疗提供高效工具。
1.什么是双重预训练策略 2.Contrastive Language-Image Pretraining (CLIP)是什么,
### 1. **双重预训练策略** 双重预训练策略是该论文中提出的一种结合 **无监督学习** 和 **弱监督学习** 的方法,旨在提升模型的表征能力和泛化性能。具体包括以下两部分:#### **(1) 无监督预训练** - **目的:** 提取病理图像的基础特征,捕获显微细胞形态的多样性。 - **过程:**- 在 1500 万张未标注的病理图像切片(tiles)上进行预训练。- 无监督学习不依赖标签,使用的是图像自身的数据模式和分布。- 模型通过学习局部的显微特征(如细胞形态、核结构)建立基本的表征。 - **优点:**- 避免对大量标注数据的依赖。- 提供对多种癌症组织微观结构的广泛识别能力。#### **(2) 弱监督预训练** - **目的:** 学习全切片图像(Whole-Slide Images, WSIs)的全局上下文信息和组织模式。 - **过程:**- 在超过 60,530 张全切片图像上进行弱监督学习,这些数据来自 19 个解剖部位和多个癌症类型。- 弱监督方法依赖于切片级的粗粒度标签(如癌症类型、组织来源等),而不需要细粒度的像素级标注。- 模型通过识别组织区域之间的关系,学习宏观组织模式和癌症类型的特征。 - **优点:**- 结合全切片的组织上下文,提升对癌症起源和整体模式的识别能力。#### **双重策略的协同作用** - 无监督学习专注于微观的细胞特征,弱监督学习补充了全局的组织结构信息。 - 两种预训练方式相结合,使得模型既能捕捉微观特征,也能理解全局组织模式,从而在多种任务(如癌症检测、预后预测等)中表现优异。---### 2. **Contrastive Language-Image Pretraining (CLIP)**#### **CLIP是什么?** CLIP 是一种 **对比学习(Contrastive Learning)** 框架,由 OpenAI 提出,用于同时处理图像和文本的联合表征学习。CLIP 模型的主要目的是将图像和文本嵌入到一个共享的语义空间中,使得模型可以通过文本描述对图像进行分类或检索。#### **CLIP的原理** 1. **输入数据:**- 图像(如病理切片的图像)。- 与图像相关联的文本描述(如“来自胃部的组织切片”)。 2. **模型架构:**- 图像编码器:提取图像的嵌入表示。- 文本编码器:提取文本的嵌入表示。 3. **对比学习目标:**- 通过 **对比损失函数(Contrastive Loss)**,将图像和对应的文本对的嵌入向量拉近,而将不匹配的图像-文本对的嵌入拉远。- 换句话说,模型会学习到图像与文本之间的语义关系,使得语义相关的图像和文本可以在高维空间中靠近。#### **在论文中的应用** - **目的:** 融合病理图像的显微特征和解剖部位的先验知识。 - **过程:**- 图像编码器将全切片图像转化为特征向量,捕捉细胞和组织的形态特征。- 文本编码器处理描述图像来源和解剖部位的信息(例如“胃癌切片”)。- 图像与文本的联合嵌入增强了模型对组织和癌症类型的理解。 - **优势:**- 提升了模型对异质性病理数据的适应能力。- 提供了更丰富的语义信息,有助于癌症类型的分类和起源预测。#### **CLIP的核心特点** - **多模态学习:** 同时学习图像和文本的表征。 - **泛化能力强:** 在未见过的任务和数据上依然表现良好。 - **弱监督场景适配:** 不需要精细的标注数据,适合大规模病理数据分析。如果需要更详细的数学公式或实现细节,也可以进一步探讨!

![[Linux]线程](https://img2023.cnblogs.com/blog/3328328/202412/3328328-20241218195040443-1454985153.png)