随机匹配
为了帮大家更快地发现和自己兴趣相同的朋友
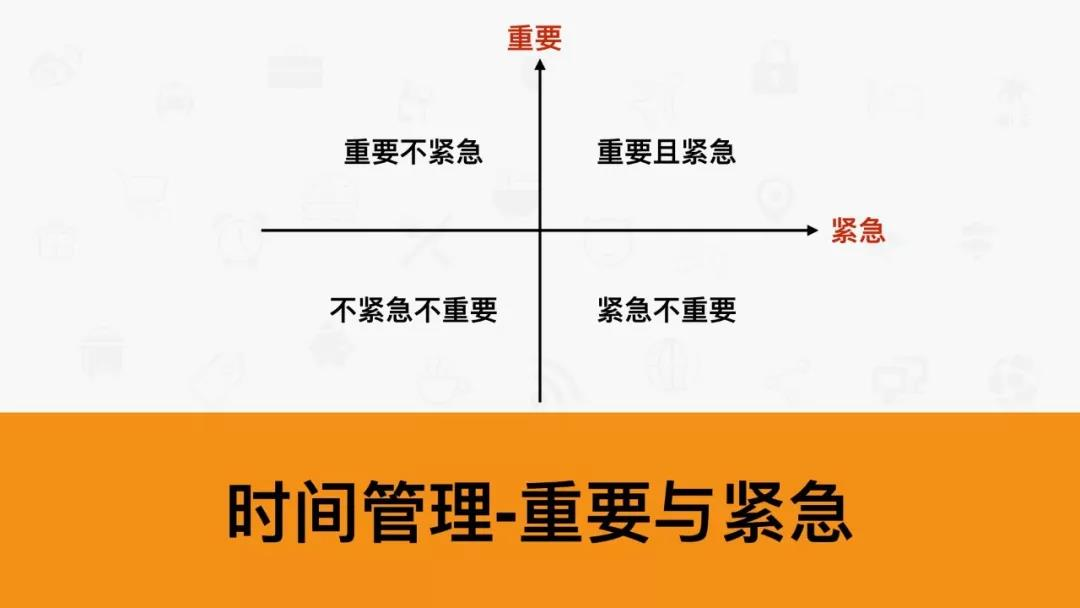
匹配 1 个还是匹配多个?
答:匹配多个,并且按照匹配的相似度从高到低排序
怎么匹配?(根据什么匹配)
答:标签 tags
还可以根据 user_team 匹配加入相同队伍的用户
本质:找到有相似标签的用户
举例:
用户 A:[Java, 大一, 男]
用户 B:[Java, 大二, 男]
用户 C:[Python, 大二, 女]
用户 D:[Java, 大一, 女]
1. 怎么匹配
- 找到有共同标签最多的用户(TopN)
- 共同标签越多,分数越高,越排在前面
- 如果没有匹配的用户,随机推荐几个(降级方案)
编辑距离算法:https://blog.csdn.net/DBC_121/article/details/104198838
最小编辑距离:字符串 1 通过最少多少次增删改字符的操作可以变成字符串 2
余弦相似度算法:https://blog.csdn.net/m0_55613022/article/details/125683937(如果需要带权重计算,比如学什么方向最重要,性别相对次要)
2. 怎么对所有用户匹配,取 TOP(下一期的内容)
直接取出所有用户,依次和当前用户计算分数,取 TOP N(54 秒)
优化方法:
-
切忌不要在数据量大的时候循环输出日志(取消掉日志后 20 秒)
-
Map 存了所有的分数信息,占用内存解决:维护一个固定长度的有序集合(sortedSet),只保留分数最高的几个用户(时间换空间)e.g.【3, 4, 5, 6, 7】取 TOP 5,id 为 1 的用户就不用放进去了
-
细节:剔除自己 √
-
尽量只查需要的数据:
-
过滤掉标签为空的用户 √
-
根据部分标签取用户(前提是能区分出来哪个标签比较重要)
-
只查需要的数据(比如 id 和 tags) √(7.0s)
-
提前查?(定时任务)
-
提前把所有用户给缓存(不适用于经常更新的数据)
-
提前运算出来结果,缓存(针对一些重点用户,提前缓存)
大数据推荐,比如说有几亿个商品,难道要查出来所有的商品?
难道要对所有的数据计算一遍相似度?
匹配通用
检索 => 召回 => 粗排 => 精排 => 重排序等等
检索:尽可能多地查符合要求的数据(比如按记录查)
召回:查询可能要用到的数据(不做运算)
粗排:粗略排序,简单地运算(运算相对轻量)
精排:精细排序,确定固定排位
匹配算法
最短距离算法
* 编辑距离算法(用于计算最相似的两组标签)
* 原理:https://blog.csdn.net/DBC_121/article/details/104198838
TreeMap内部排序
-
SortedMap(java.util.SortedMap)接口是Map的子接口,SortedMap中增加了元素的排序,这意味着可以给SortedMap中的元素排序。
-
SortedMap的实现TreeMap
SortedMap接口的实现TreeMap (java.util.TreeMap). -
创建TreeMap
可以通过TreeMap的构造函数创建TreeMap 实例:
SortedMap sortedMap = new TreeMap();
- 创建TreeMap使用Comparator
可以使用Comparator的实现作为TreeMap 构造函数的参数 ,这个Comparator将用于对存储在SortedMap中的键、值对的键进行排序:
Comparator comparator = new MyComparatorImpl();
SortedMap sortedMap = new TreeMap(comparator);
- 排序
SortedMap中的排序顺序要么是元素的自然排序顺序(如果它们实现了java.lang.Comparable),或由Comparator确定的顺序。