🍓 简介:java系列技术分享(👉持续更新中…🔥)
🍓 初衷:一起学习、一起进步、坚持不懈
🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏
🍓 希望这篇文章对你有所帮助,欢迎点赞 👍 收藏 ⭐留言 📝🍓 更多文章请点击

简介及安装请查看这篇:Elasticsearch简介及安装
文章目录
- 一、 正向索引
- 二、 倒排索引
- 三、 正向索引和倒排索引的区别
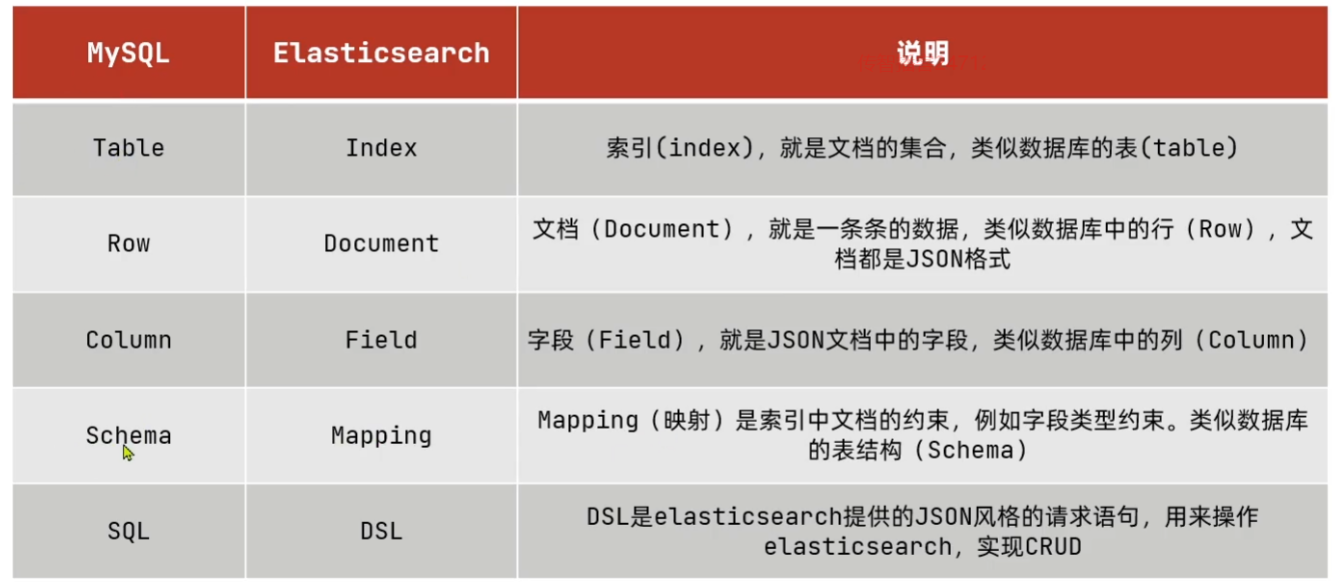
- 三、与Mysql的概念对比
- 四、分词器(粗细力度拆分)
- 4.1 原始分词器
- 4.2 IK分词器
- 4.3 安装IK分词器
- 4.3.1 在线安装`较慢`
- 4.3.2 离线安装ik插件`推荐`
- 4.4 ik分词器测试
- 4.5 IK分词器--拓展词库
- 五、mapping属性介绍
- 六、 索引库操作(类似表操作)
- 6.1 创建索引库
- 6.2 查询
- 6.3 删除
- 6.4 修改
- 七、 文档操作(类似表中每条数据操作)
- 7.1 添加
- 7.2 查询
- 7.3 删除
- 7.4 修改

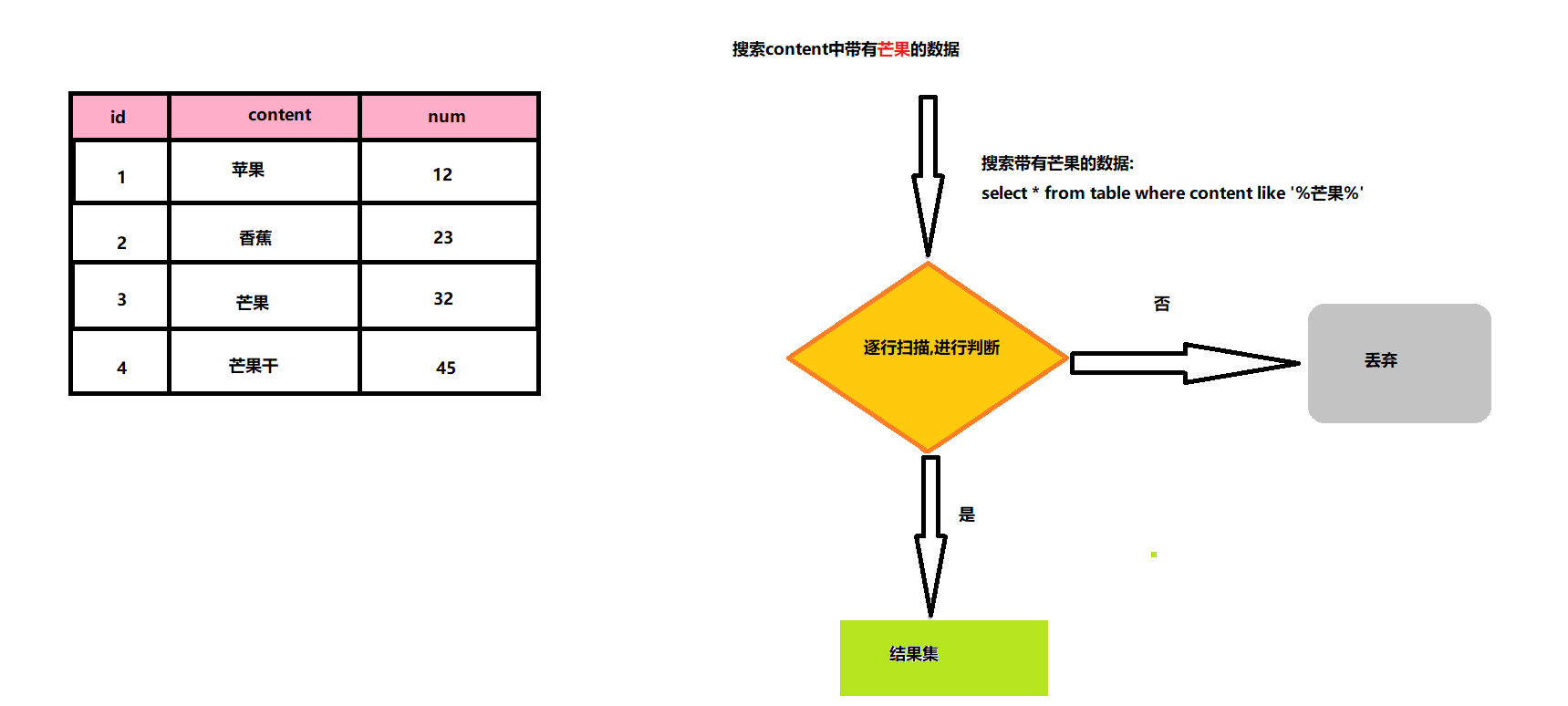
一、 正向索引
基于文档id创建索引,查询时先找文档,然后判断是否包含词条
正向索引(也称为“文档索引”或“内容索引”)是将文档ID与文档内容、单词相关联的关系。这意味着可以通过文档ID获取文档的内容。在构建索引时,它的结构相对简单,建立方便且易于维护。然而,在查询时需要对所有文档进行扫描,以确保没有遗漏,这会使得检索时间大大延长,检索效率低下。
数据库Mysql采用正向索引,例如:给表中的id建立索引,如下图所示
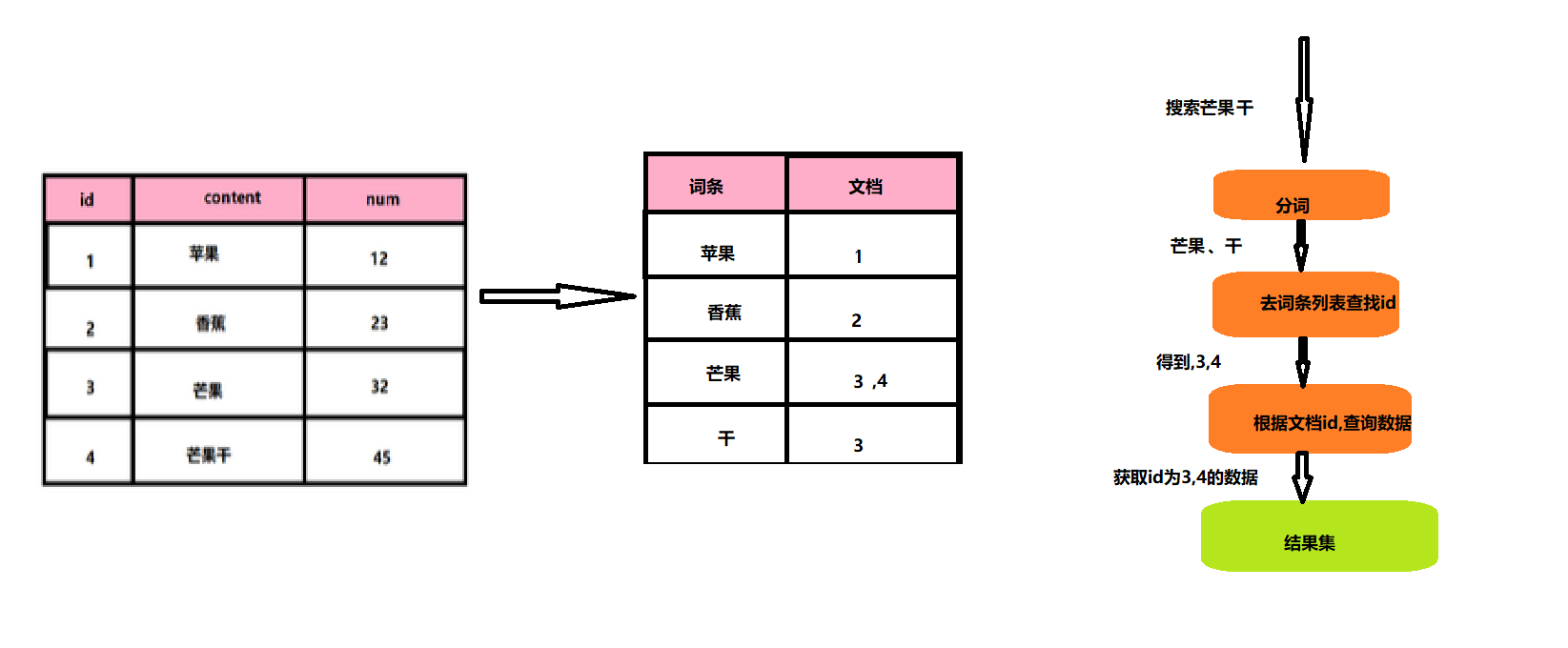
二、 倒排索引
对文档内容分词,对词条创建索引,并记录词条所在文档信息,查询时先根据词条查询文档id,然后获取文档
倒排索引是单词到文档ID的关联关系。也就是说,通过单词可以搜索到对应的文档ID。倒排索引是搜索引擎的核心,因为它们允许我们根据关键字快速找到相关的文档。倒排索引主要由两个部分组成:单词词典(Trem Dictionary)和倒排列表(Posting List)。单词词典记录了所有的文档分词后的结果,而倒排列表则记录了单词对应文档的集合。此外,倒排索引还包含位置(Position)和偏移(Offset)信息,用于词语搜索和高亮显示。
名词介绍:
文档(document): 每条数据就是一个文档词条(term): 文档按照语义分成的词语
三、 正向索引和倒排索引的区别
正向索引:
-
优点:
- 可以给多个字段创建索引
- 根据索引字段搜索,排序速度非常快
-
缺点:
- 根据非所以呢字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引
-
优点:
- 根据词条搜索,模糊搜索时速度非常快
-
缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
三、与Mysql的概念对比
Mysql: 擅长事务类型操作,可以确保数据的安全性和一致性
Elasticsearch:擅长海量数据的搜索,分析,计算
四、分词器(粗细力度拆分)
4.1 原始分词器
Elasticsearch在
创建倒排索引时需要对文档分词;`- 在搜索时,需要对用户输入内容分词`
- 但是默认的分词规则
对中文处理并不好。(如下)
我们希望按照词分

4.2 IK分词器
处理中文分词,一般会使用IK分词器GitHub地址:https://github.com/medcl/elasticsearch-analysis-ik
ik_smart :最少切分,粗粒度
ik_max_word :最细切分,细粒度
4.3 安装IK分词器
4.3.1 在线安装较慢
# 进入容器内部docker exec -it es /bin/bash# 在线下载并安装./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出exit#重启容器docker restart es# 查看es日志docker logs -f es
4.3.2 离线安装ik插件推荐
因为根据上篇Elasticsearch简介及安装中我们知道,我们的插件数据卷为:es-plugins
- 因此,通过下面命令查看:查看数据卷目录
docker volume inspect es-plugins - 目录被挂载到了:
/var/lib/docker/volumes/es-plugins/_data这个目录中。 - 将下载的ik分词器文件(GItHub地址中下载或者
到我的主页中的资源进行下载)放到该目录下 - 重启容器
# 重启容器 docker restart es # 查看es日志 docker logs -f es
4.4 ik分词器测试
ik_smart 分词器最少切分,粗粒度
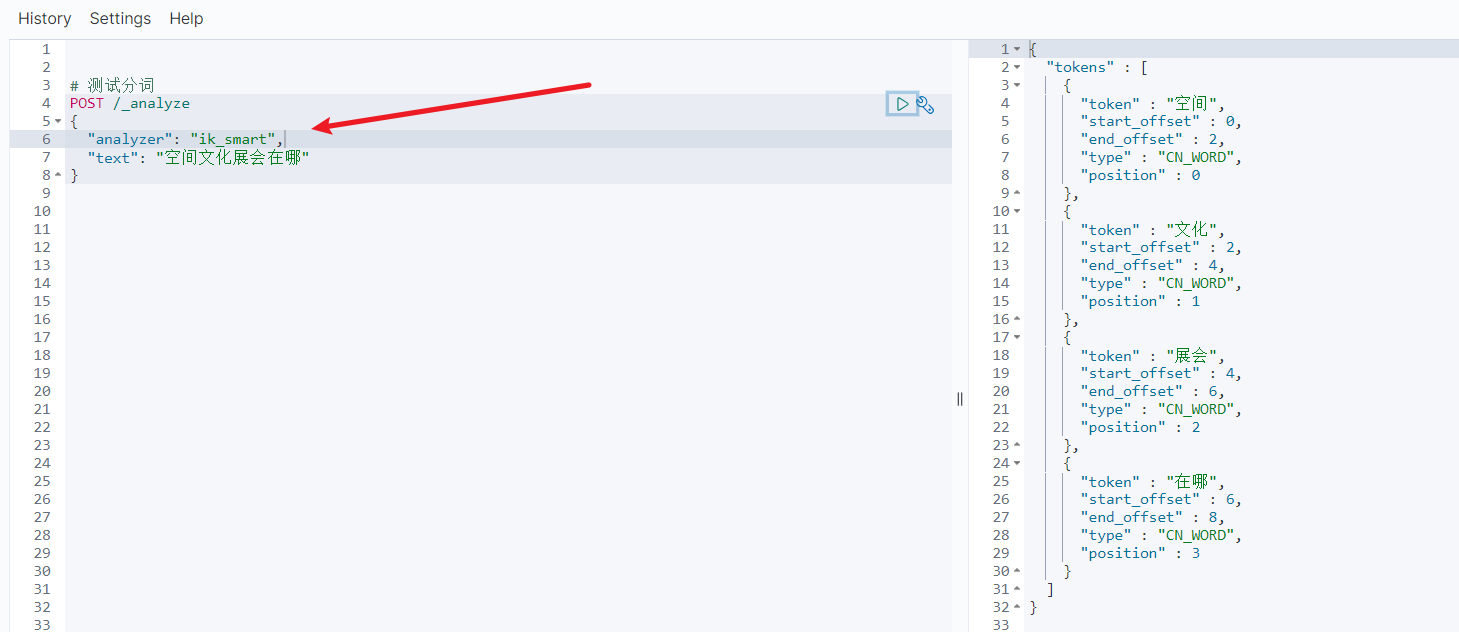
ik_max_word 分词器最细切分,细粒度
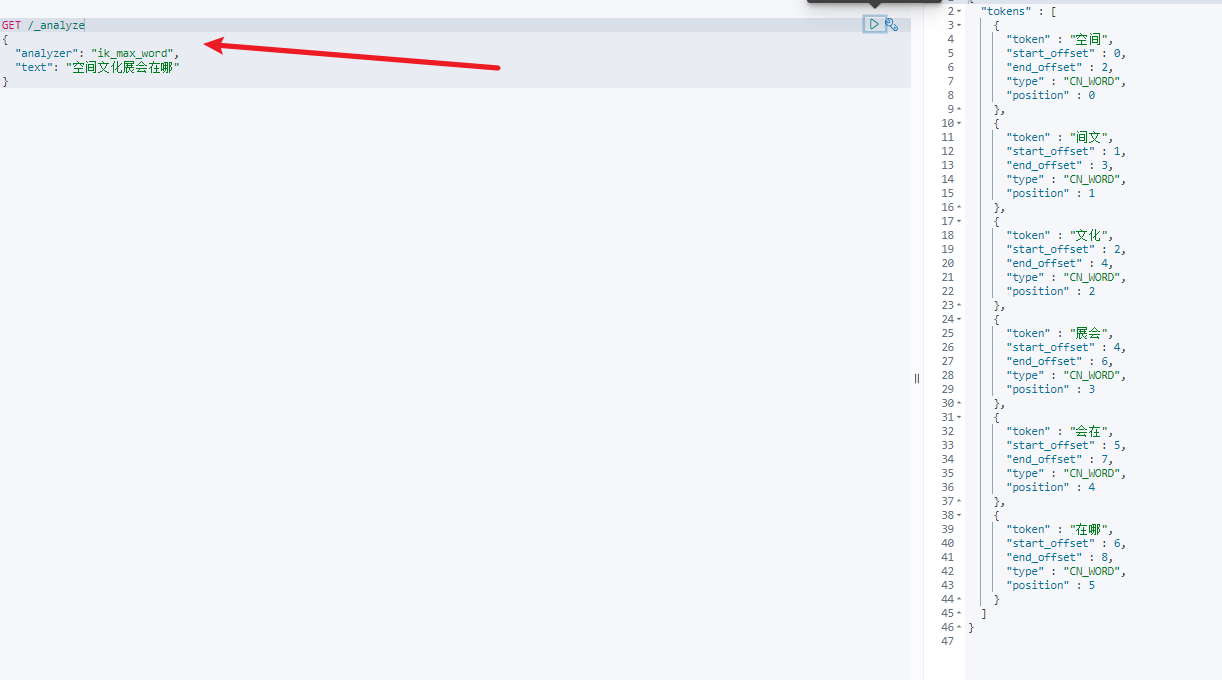
4.5 IK分词器–拓展词库
比如我想实现让上图中的text字段的空间文化分成一个词语
首先我们来看下ik分词器的词库如何配置
-
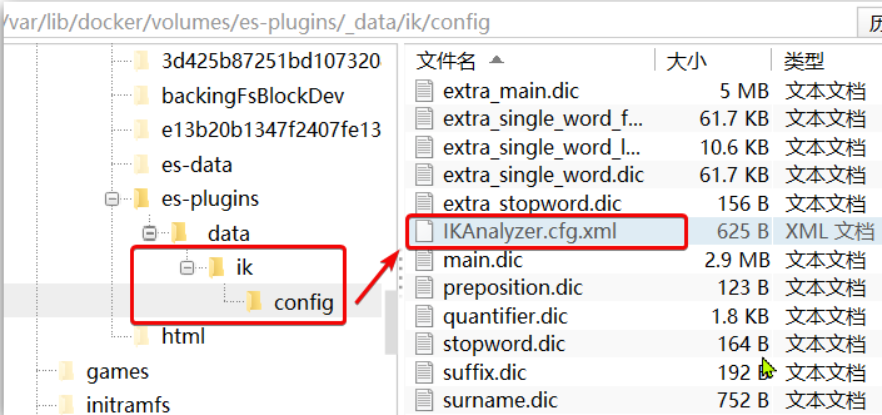
和上文中一样先查看ik分词器安装的位置
docker volume inspect es-plugins -
打开IK分词器config目录:
-
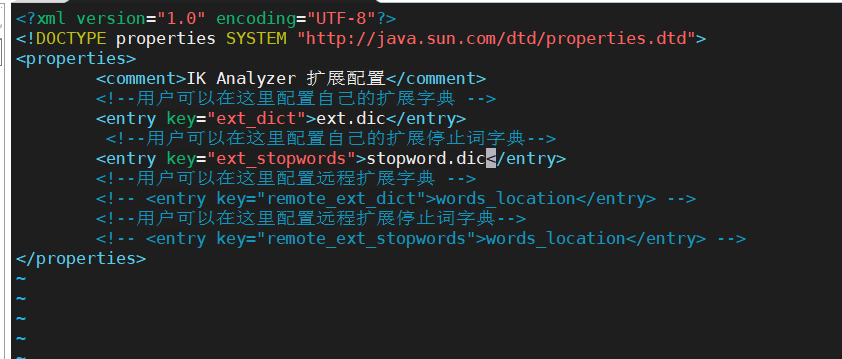
只需要修改一个ik分词器目录中的config目录中的ilAnalyzer.cfg.xml文件即可
 `
` -
拓展词典和停止词典在当前配置文件的所在目录 在ext.dic文件中(没有新建即可),添加想要的拓展词语即可;
停止词典同理一样

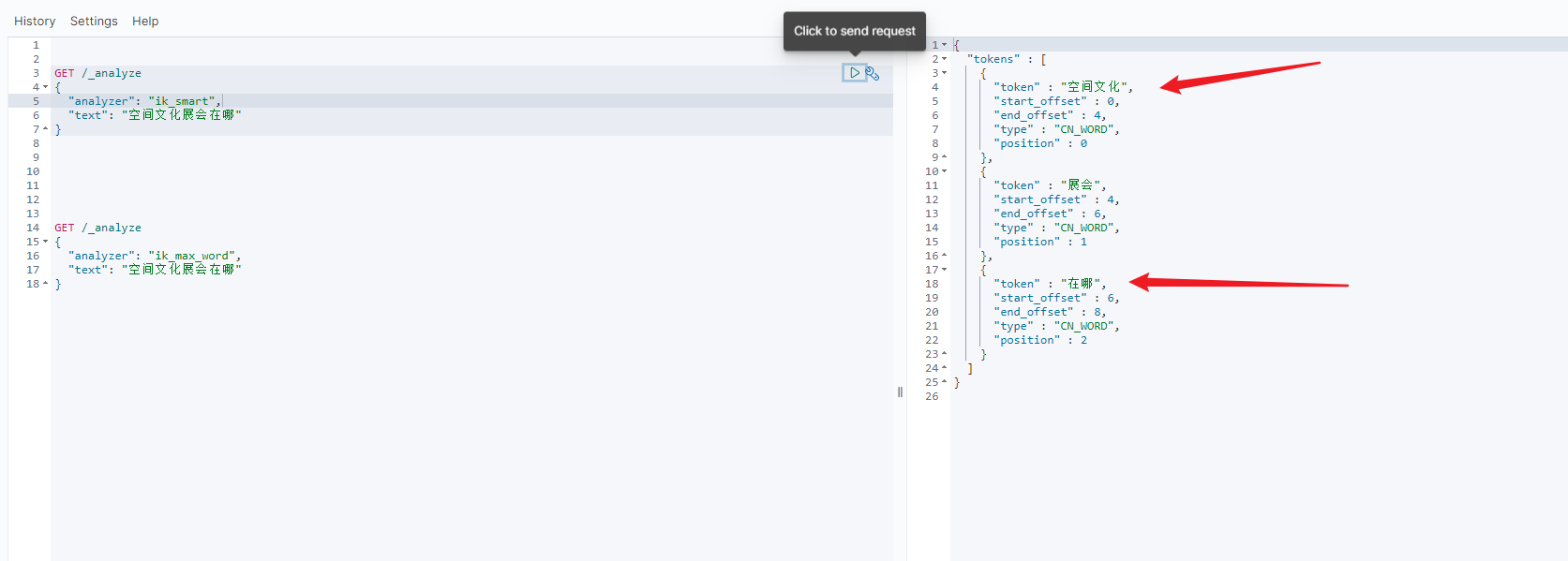
- 最后重启es
docker restart es# 查看 日志 docker logs -f es- 测试发现成功
五、mapping属性介绍
Mapping(映射)是索引文档的约束,例如:字段数据类型约束,等等
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/getting-started.html

六、 索引库操作(类似表操作)
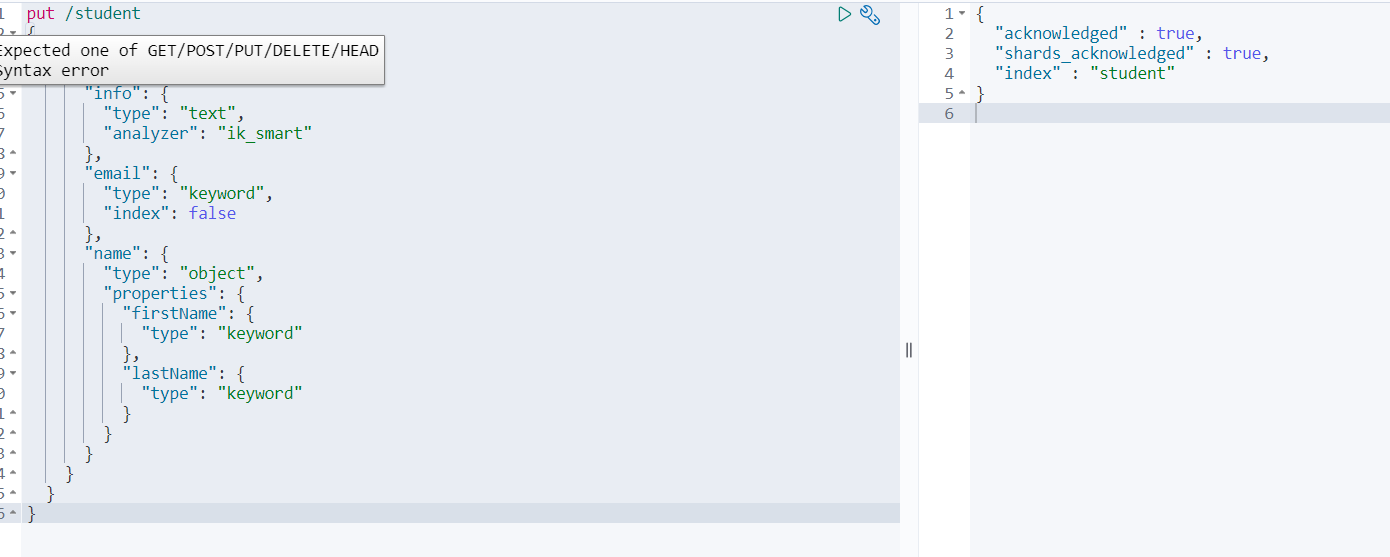
6.1 创建索引库
上述有介绍其含义,例如:type为text可分词,keyword精确值也就是不可分词
put /student
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email": {"type": "keyword","index": false},"name": {"properties": {"firstName": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}
创建成功
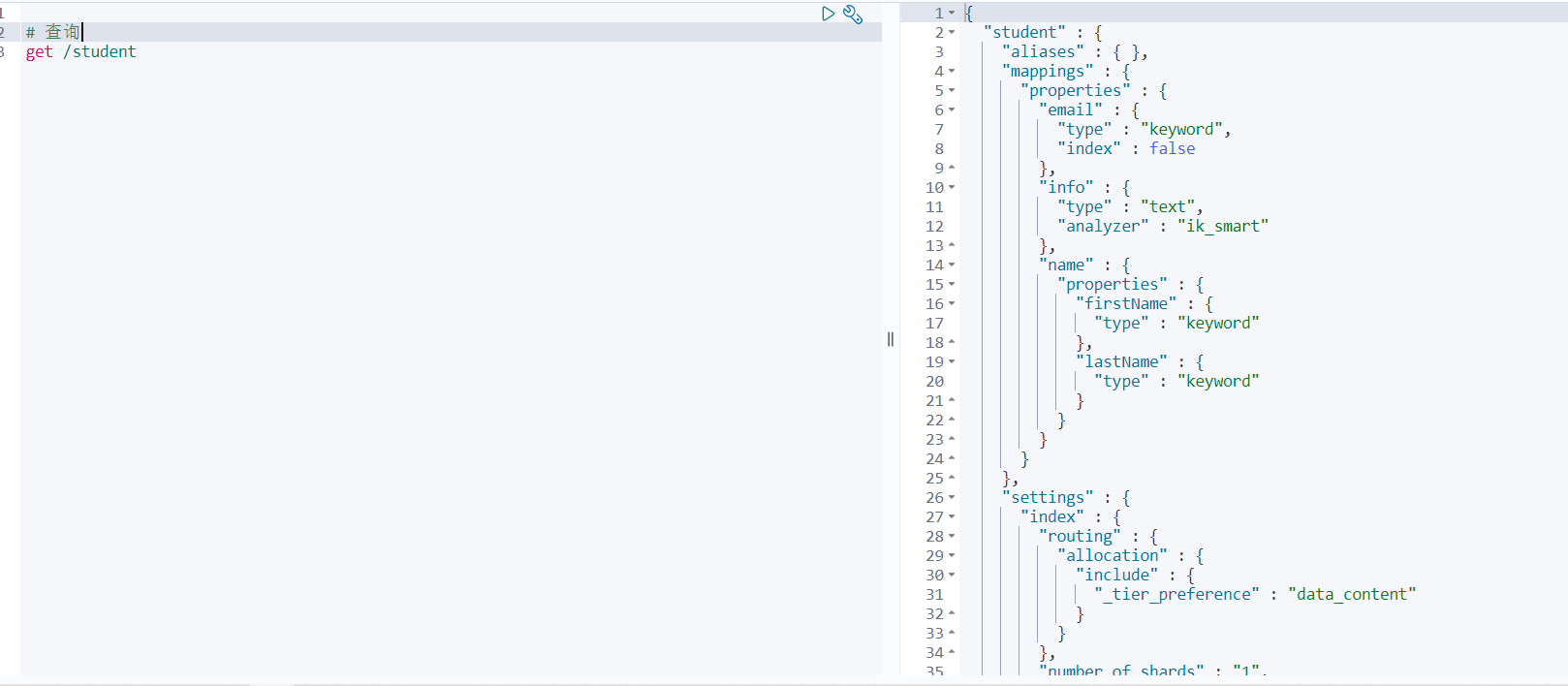
6.2 查询
GET /索引库名
6.3 删除
DELETE /索引库名

6.4 修改
以后字段类型不可修改,只能新增字段
 再次查看成功添加
再次查看成功添加

七、 文档操作(类似表中每条数据操作)
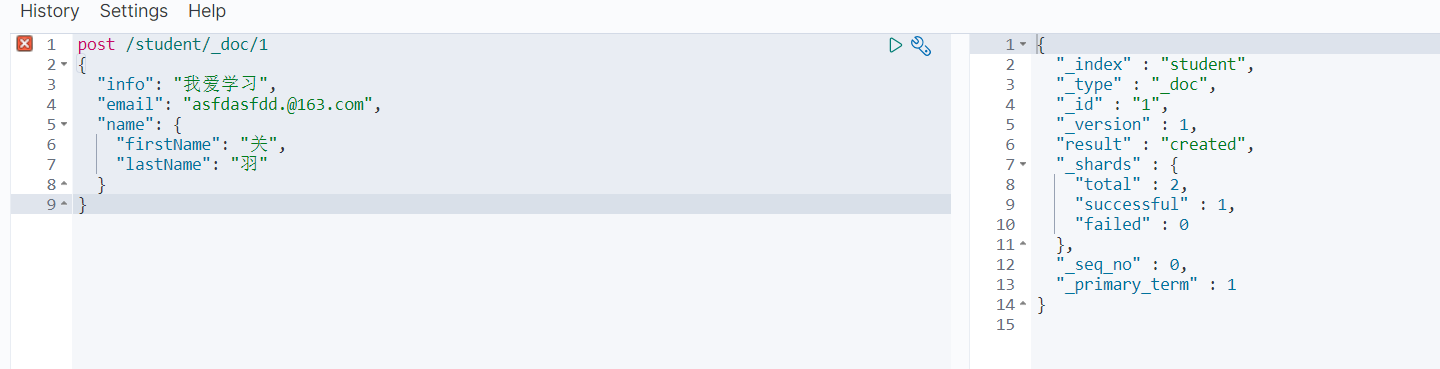
7.1 添加
post /student/_doc/1
{"info": "我爱学习","email": "asfdasfdd.@163.com","name": {"firstName": "关","lastName": "羽"}
}
7.2 查询

7.3 删除
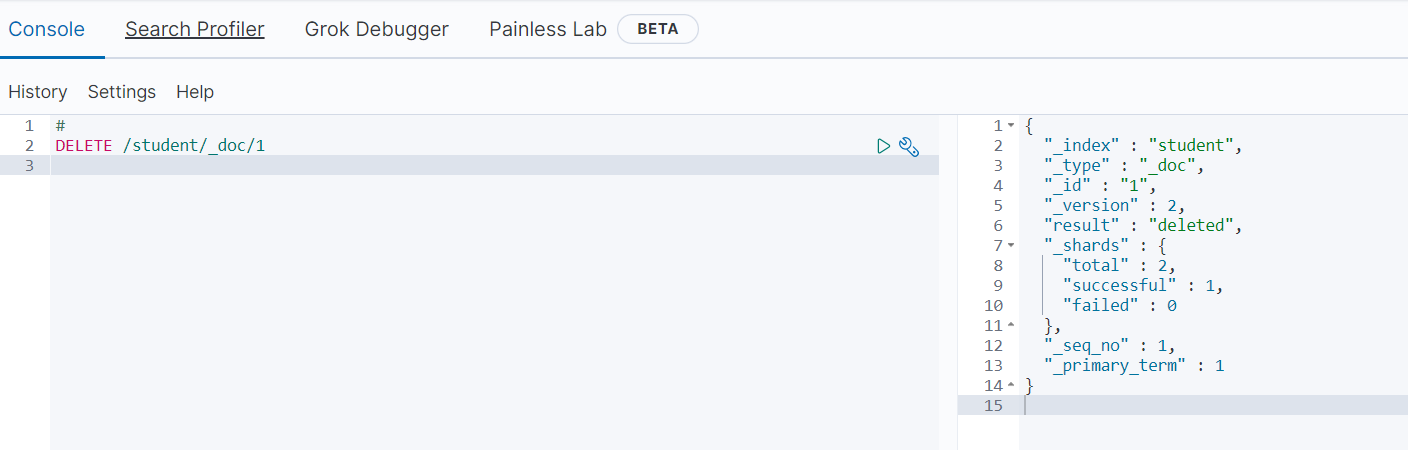
发现删除成功了

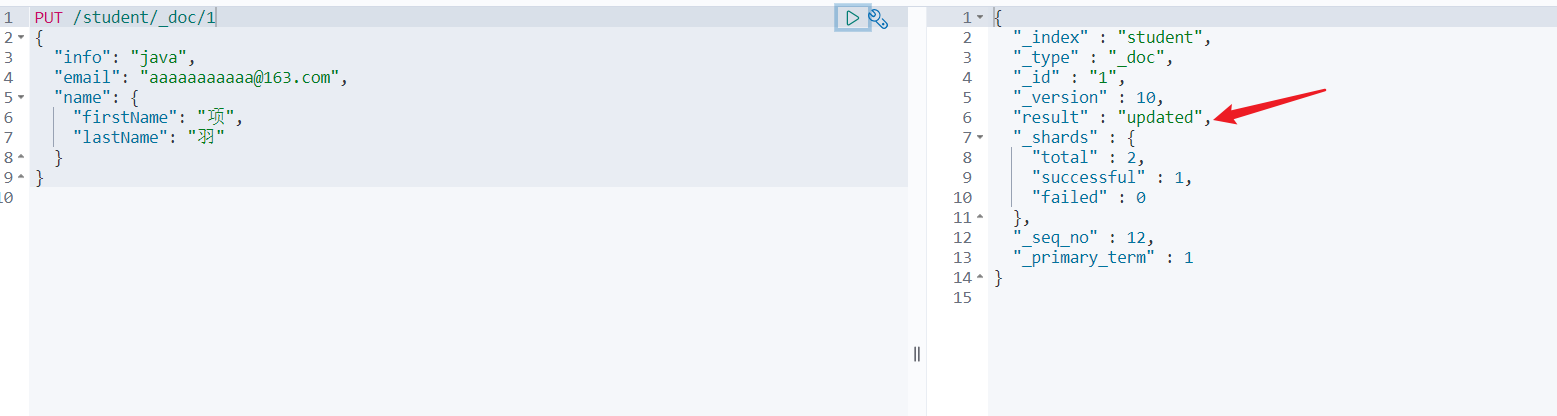
7.4 修改
方式一:全量修改,会删除旧文档,添加新文档
那么存在为修改,不存在时为新增
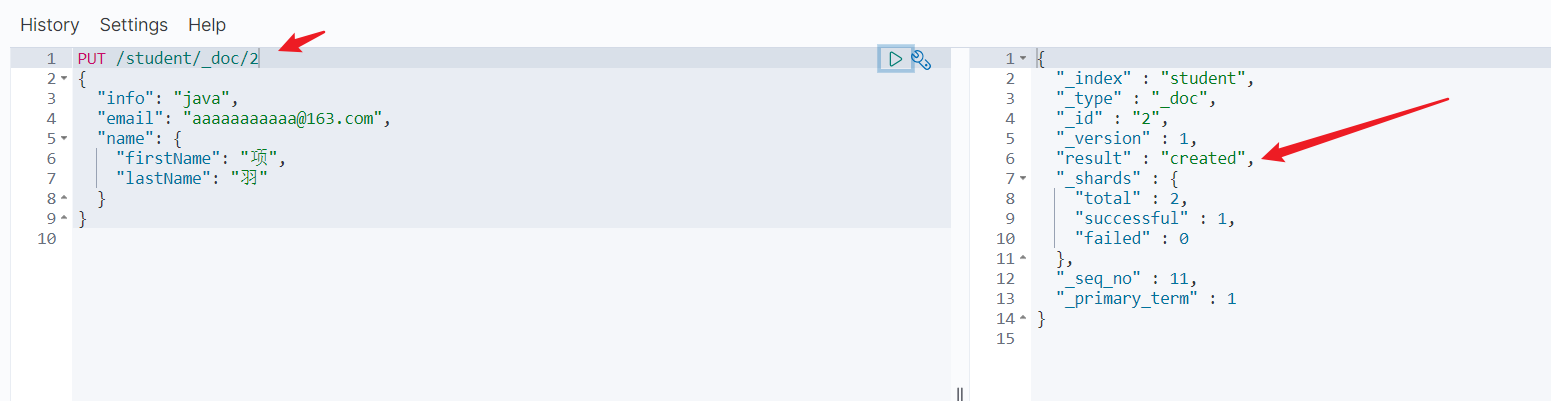
方式二:增量修改,修改指定字段

![]()