- 数据库编码
- 不要使用 SQL_ASCII
- 为什么不呢?
- 你什么时候应该?
- 不要使用 SQL_ASCII
- 工具使用
- 不要使用 psql -W 或 --password
- 为什么不呢?
- 你什么时候应该?
- 不要使用规则
- 为什么不呢?
- 你什么时候应该?
- 不要使用表继承
- 为什么不呢?
- 你什么时候应该?
- 不要使用 psql -W 或 --password
- SQL 构造
- 不要使用 NOT IN
- 为什么不呢?
- 你什么时候应该?
- 不要使用大写的表名或列名
- 为什么不呢?
- 你什么时候应该?
- 不要使用 BETWEEN (尤其是时间戳)
- 为什么不呢?
- 你什么时候应该?
- 不要使用 NOT IN
- 日期/时间存储
- 不要使用时间戳(没有时区)
- 为什么不呢?
- 你什么时候应该?
- 不要使用时间戳(不带时区)来存储 UTC 时间
- 为什么不呢?
- 你什么时候应该?
- 不要使用timetz
- 为什么不呢?
- 你什么时候应该?
- 不要使用CURRENT_TIME
- 为什么不呢?
- 你什么时候应该?
- 不要使用时间戳(0)或时间戳(0)
- 为什么不呢?
- 你什么时候应该?
- 不要使用 +/-HH:mm 作为文本时区名称
- 为什么不呢?
- 你什么时候应该?
- 不要使用时间戳(没有时区)
- 文本存储
- 不要使用 char(n)
- 为什么不呢?
- 你什么时候应该?
- 即使对于固定长度标识符也不要使用 char(n)
- 为什么不呢?
- 你什么时候应该?
- 默认情况下不要使用 varchar(n)
- 为什么不呢?
- 你什么时候应该?
- 不要使用 char(n)
- 其他数据类型
- 不要用钱
- 为什么不呢?
- 你什么时候应该?
- 不要使用串口
- 为什么不呢?
- 你什么时候应该?
- 不要用钱
- 验证
- 不要使用
trust通过 TCP/IP 进行身份验证(host,hostssl)- 为什么不呢?
- 你什么时候应该?
- 不要使用
翻译自: https://wiki.postgresql.org/wiki/Don't_Do_This#When_should_you.3
非原创, 使用网页翻译所得, 仅记录作为笔记
数据库编码
不要使用 SQL_ASCII
为什么不呢?
对于所有编码转换函数来说, SQL_ASCII表示“无转换”。也就是说,原始字节被简单地视为新编码中的内容,接受有效性检查,而不考虑它们的含义。除非非常小心,否则SQL_ASCII数据库通常最终会存储许多不同编码的混合,而无法可靠地恢复原始字符。
你什么时候应该?
如果您的输入数据已经处于无标签编码的绝望混合中,例如 IRC 通道日志或不符合 MIME 的电子邮件,那么 SQL_ASCII 可能是最后的手段,但请考虑首先使用bytea ,或者是否可以自动检测 UTF8并假设非 UTF8 数据采用某种特定编码,例如 WIN1252。
工具使用
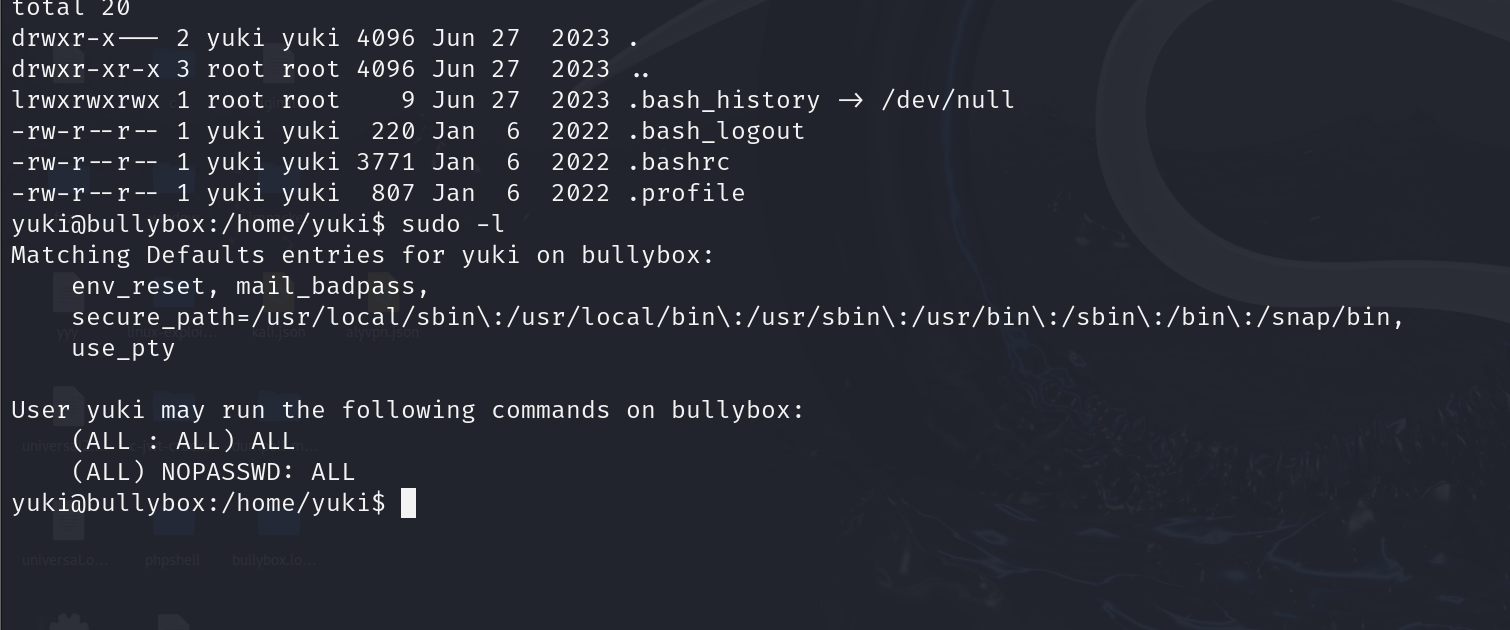
不要使用 psql -W 或 --password
不要使用 psql -W 或者 psql --password 。
为什么不呢?
使用 --password 或 -W 标志将告诉psql在尝试连接到服务器之前提示您输入密码 - 因此即使服务器不需要密码,也会提示您输入密码。
它从来都不是必需的,就好像服务器确实需要密码一样,psql 会提示您输入密码,并且在设置权限时可能会非常混乱。如果您使用 -W 连接到配置为允许您通过以下方式访问的服务器 peer 身份验证 您可能认为它需要密码,但实际上不需要。如果您登录的用户没有设置密码,或者您在提示时输入了错误的密码,您仍然会登录并认为您拥有正确的密码 - 但您将无法登录从其他客户端(通过本地主机连接)或以其他用户身份登录时。
你什么时候应该?
从来没有,几乎没有。它将节省与服务器的往返路程,但仅此而已。
不要使用规则
不要使用规则。如果您认为需要,请改用触发器。
为什么不呢?
规则非常强大,但它们的作用却并不像看上去那样。它们看起来像是一些条件逻辑,但实际上它们重写了查询以对其进行修改或向其添加其他查询。
这意味着所有重要的规则都是不正确的。
关于他们,德佩斯还有更多话要说。
你什么时候应该?
绝不。虽然重写器是VIEW的实现细节,但没有理由直接撬开这个盖板。
不要使用表继承
不要使用表继承。如果您认为需要,请改用外键。
为什么不呢?
表继承是一种时尚的一部分,其中数据库与面向对象的代码紧密耦合。事实证明,紧密耦合的事物实际上并没有产生预期的结果。
你什么时候应该?
从来没有……几乎。现在表分区是本机完成的,表继承的常见用例已被处理元组路由等的本机功能所取代,无需定制代码。
如果您在紧要关头并希望使用该扩展来进行行版本控制以代替缺乏 SQL 2011 支持,则极少数例外之一就是temporal_tables扩展。表继承将提供一个小快捷方式,而不是使用UNION ALL来获取历史行和当前行。即使如此,在使用父表时您也应该警惕警告。
SQL 构造
不要使用 NOT IN
不要使用NOT IN或NOT和IN的任意组合,例如NOT (x IN (select…)) 。
为什么不呢?
两个原因:
- 如果存在空值,
NOT IN会以意想不到的方式运行:
select * from foo where col not in (1,null); -- always returns 0 rowsselect * from foo where foo.col not in (select bar.x from bar); -- returns 0 rows if any value of bar.x is null
发生这种情况是因为如果 col=1, col IN (1,null)返回TRUE ,否则返回NULL (即它永远不能返回FALSE )。由于NOT (TRUE)为FALSE ,但NOT (NULL)仍为NULL ,因此NOT (col IN (1,null)) (与col NOT IN (1,null)相同)无法返回在任何情况下都是TRUE 。
- 由于上面的第 1 点,
NOT IN (SELECT ...)优化效果不是很好。特别是,规划器无法将其转换为反连接,因此它要么成为散列子计划,要么成为普通子计划。散列子计划速度很快,但规划器只允许该计划用于小型结果集;简单的子计划慢得可怕(实际上是 O(N²))。这意味着性能在小规模测试中可能看起来不错,但一旦超过大小阈值,性能就会降低 5 个或更多数量级;你不希望这种情况发生。
替代解决方案:在大多数情况下, NOT IN (SELECT …)的 NULL 行为并不是故意需要的,可以使用**NOT EXISTS** (SELECT …)重写查询:
select * from foo where not exists (select from bar where foo.col = bar.x);
你什么时候应该?
NOT IN ( *list,of,values,...* )基本上是安全的,除非列表中可能有空值(通过参数或其他方式)。因此,在从查询结果中排除特定常量值时,有时使用它是很自然的,甚至是明智的。
不要使用大写的表名或列名
不要使用NamesLikeThis,使用names_like_this。
为什么不呢?
PostgreSQL 将表、列、函数和其他所有内容的所有名称折叠为小写,除非它们是“双引号”的。
所以 create table Foo() 将创建一个名为 foo , 尽管 create table "Bar"() 将创建一个名为 Bar 。
这些选择命令将起作用: select * from Foo , select * from foo , select * from "Bar" 。
这些将因“没有这样的表”而失败: select * from "Foo" , select * from Bar , select * from bar 。
这意味着,如果您在表名或列名中使用大写字符,则必须始终双引号它们或从不双引号它们。手动操作这已经够烦人的了,但是当您开始使用其他工具访问数据库时,其中一些工具总是引用所有名称,而另一些工具则不然,这会变得非常混乱。
坚持使用 az、0-9 和下划线作为名称,您永远不必担心引用它们。
你什么时候应该?
如果在报告输出中显示“漂亮”的名称很重要,那么您可能需要使用它们。但是您也可以使用列别名在表中使用小写名称,并且仍然在查询的输出中获得漂亮的名称: select character_name as "Character Name" from foo 。
不要使用 BETWEEN (尤其是时间戳)
为什么不呢?
BETWEEN使用闭区间比较:指定范围两端的值都包含在结果中。
这是以下形式的查询的一个特殊问题
SELECT * FROM blah WHERE timestampcol BETWEEN '2018-06-01' AND '2018-06-08'
这将包括时间戳恰好为 2018-06-08 00:00:00.000000 的结果,但不包括当天晚些时候的时间戳。因此,该查询可能看起来有效,但是一旦您在午夜准确地获得了一个条目,您最终就会重复计算它。
相反,请执行以下操作:
SELECT * FROM blah WHERE timestampcol >= '2018-06-01' AND timestampcol < '2018-06-08'
你什么时候应该?
BETWEEN对于整数或日期等离散量是安全的,只要您记住范围的两端都包含在结果中即可。但这是一个坏习惯。
日期/时间存储
不要使用时间戳(没有时区)
不要使用 timestamp 类型来存储时间戳,使用 timestamptz (也称为 timestamp with time zone ) 反而。
为什么不呢?
timestamptz 记录单个时刻。尽管顾名思义,它并不存储时间戳,而只是存储一个时间点,描述为自 UTC 2000 年 1 月 1 日以来的微秒数。您可以在任何时区插入值,它将存储该值描述的时间点。默认情况下,它将显示您当前时区的时间,但您可以使用 at time zone 以在其他时区显示它。
因为它存储一个时间点,所以它会通过涉及在不同时区输入的时间戳的算术来做正确的事情 - 包括来自夏令时变化不同侧的同一位置的时间戳之间。
timestamp (也称为 timestamp without time zone ) 不会执行任何操作,它只是存储您提供的日期和时间。您可以将其视为日历和时钟的图片,而不是时间点。如果没有附加信息 - 时区 - 你不知道它记录的时间。因此,不同位置的时间戳之间或夏季和冬季的时间戳之间的算术可能会给出错误的答案。
因此,如果您要存储的是时间点,而不是时钟图片,请使用 timestamptz。
有关时间戳的更多信息。
你什么时候应该?
如果您以抽象方式处理时间戳,或者只是从应用程序中保存和检索它们,而您不会对它们进行算术运算,那么时间戳可能适合。
不要使用时间戳(不带时区)来存储 UTC 时间
不幸的是,将 UTC 值存储在timestamp without time zone中是一种通常从缺乏可用时区支持的其他数据库继承的做法。
请改用timestamp with time zone 。
为什么不呢?
因为数据库无法知道 UTC 是列值的预期时区。
这使得许多其他有用的时间计算变得复杂。例如,“u.timezone 给出的时区的最后一个午夜”变为:
date_trunc('day', now() AT TIME ZONE u.timezone) AT TIME ZONE u.timezone AT TIME ZONE 'UTC'
而“u.timezone 中x.datecol之前的午夜”则变为:
date_trunc('day', x.datecol AT TIME ZONE 'UTC' AT TIME ZONE u.timezone)AT TIME ZONE u.timezone AT TIME ZONE 'UTC'
你什么时候应该?
如果与不支持时区的数据库的兼容性胜过所有其他考虑因素。
不要使用timetz
不要使用 timetz 类型。你可能想要 timestamptz 反而。
为什么不呢?
甚至手册也告诉您它只是为了 SQL 合规性而实现的。
time with time zone 类型是由 SQL 标准定义的,但该定义所表现出的属性会导致实用性受到质疑。在大多数情况下,日期、时间、不带时区的时间戳和带时区的时间戳的组合应提供任何应用程序所需的完整范围的日期/时间功能。
你什么时候应该?
绝不。
不要使用CURRENT_TIME
不要使用CURRENT_TIME函数。使用其中合适的一个:
CURRENT_TIMESTAMP或now()如果您想要timestamp with time zone,LOCALTIMESTAMP如果你想要一个timestamp without time zone,CURRENT_DATE如果您想要date,- 如果您想要
timeLOCALTIME
为什么不呢?
它返回timetz类型的值,请参阅上一个条目。
你什么时候应该?
绝不。
不要使用时间戳(0)或时间戳(0)
不要对时间戳列或转换为时间戳使用精度规范,尤其是不要使用 0。
使用date_trunc('second', blah)代替。
为什么不呢?
因为它四舍五入小数部分,而不是像每个人所期望的那样截断它。这可能会导致意想不到的问题;考虑一下,当您将now()存储到这样的列中时,您可能会在未来半秒内存储一个值。
你什么时候应该?
绝不。
不要使用 +/-HH:mm 作为文本时区名称
为什么不呢?
PostgreSQL 不接受用固定时区偏移量来代替 ISO 时区名称或缩写。如果您指定这样的偏移量,它将被解释为自定义 POSIX 时区规范,但不幸的是,正值向西移动,而负值向东移动(ISO 约定将向东移动表示为负值。)
请注意,如果您提供间隔类型值,则 ISO 约定适用。因此,如果您确实想指定固定偏移量,您可以编写:
时区间隔“04:00”
你什么时候应该?
ISO 格式的字符串 timestamptz 文字可以使用带符号的偏移量编写,并且符号的方向由 ISO 约定解释。
选择 '2024-01-31 17:16:25+04'::timestamptz; -- 产生下午 1 点(UTC)
文本存储
不要使用 char(n)
不要使用类型 char(n) 。你可能想要 text 。
为什么不呢?
插入char(n)字段中的任何字符串都将用空格填充到声明的宽度。这可能不是您真正想要的。
手册说:
字符类型的值在物理上用空格填充到指定的宽度 n,并以这种方式存储和显示。但是,在比较两个字符类型的值时,尾随空格被视为语义上无关紧要并被忽略。在空白很重要的排序规则中,这种行为可能会产生意外的结果;例如
SELECT 'a '::CHAR(2) collate "C" < E'a\n'::CHAR(2)返回 true,即使 C 语言环境会认为空格大于换行符。将字符值转换为其他字符串类型之一时,尾随空格将被删除。请注意,尾随空格在字符变化和文本值中具有语义意义,并且在使用模式匹配时,即 LIKE 和正则表达式。
那应该会吓跑你。
空间填充确实浪费了空间,但并没有使操作速度更快;事实上恰恰相反,这要归功于在许多情况下需要删除空格。
需要注意的是,从存储的角度来看char(n)不是固定宽度类型。实际字节数会有所不同,因为字符可能占用多个字节,因此存储的值无论如何都被视为可变长度(即使存储中包含空格填充)。
你什么时候应该?
当您移植使用固定宽度字段的非常非常旧的软件时。或者,当您阅读上面手册中的片段并认为“是的,这完全有道理,并且非常符合我的要求”,而不是胡言乱语并逃跑。
即使对于固定长度标识符也不要使用 char(n)
有时,人们对“不要使用char(n) ”的回应是“但我的值必须始终是 N 个字符长”(例如国家/地区代码、哈希值或来自其他系统的标识符)。即使在这些情况下,使用char(n)仍然是一个坏主意。
使用text或文本上的域,并带有CHECK(length(VALUE)=3)或 CHECK(VALUE ~ '^[[:alpha:]]{3}$') 或类似的。
为什么不呢?
因为char(n)不会拒绝太短的值,所以它只是默默地用空格填充它们。因此,使用带有检查确切长度约束的text并没有实际的好处。作为奖励,这样的检查还可以验证该值的格式是否正确。
请记住,使用char(n)相对于varchar(n)没有任何性能优势。事实上,事实恰恰相反。出现的一个特殊问题是,如果您尝试将char(n)字段与驱动程序已明确指定text或varchar类型的参数进行比较,您可能会意外地无法使用索引进行比较。这可能很难调试,因为它不会显示在手动查询中。
你什么时候应该?
绝不。
默认情况下不要使用 varchar(n)
不要使用类型 varchar(n) 默认情况下。考虑 varchar (无长度限制)或 text 反而。
为什么不呢?
varchar(n) 是一个可变宽度文本字段,如果您尝试向其中插入长度超过 n 个字符(而不是字节)的字符串,则会抛出错误。
varchar (没有 (n) ) 或者 text 类似,但没有长度限制。如果将相同的字符串插入到三个字段类型中,它们将占用完全相同的空间量,并且您将无法测量性能上的任何差异。
如果您真正需要的是一个有长度限制的文本字段,那么 varchar(n) 就很好,但是如果您选择任意长度并选择 varchar(20) 作为姓氏字段,那么您将来在 Hubert Blaine 时将面临生产错误的风险Wolfeschlegelsteinhausenbergerdorff 注册接受您的服务。
有些数据库没有可以容纳任意长文本的类型,或者即使有,也不像 varchar(n) 那样方便、高效或得到良好支持。这些数据库的用户经常会使用类似的东西 varchar(255) 当他们真正想要的是 text 。
如果您需要约束字段中的值,您可能需要比最大长度更具体的东西 - 也许还有最小长度,或者有限的字符集 - 并且检查约束可以完成所有这些事情以及最大字符串长度。
你什么时候应该?
当你想要的时候,真的。如果您想要一个文本字段,如果您在其中插入太长的字符串,则会抛出错误,并且您不想使用显式检查约束,那么 varchar(n) 是一个非常好的类型。只是不要不加思考就自动使用它。
此外,与文本类型不同,varchar 类型属于 SQL 标准,因此它可能是编写超级可移植应用程序的最佳选择。
其他数据类型
不要用钱
这 money 数据类型实际上不太适合存储货币值。数字或(很少)整数可能更好。
为什么不呢?
有很多原因。
它是一种定点类型,作为机器 int 实现,因此用它进行算术运算速度很快。但它不处理一分钱(或其他货币的等值物),它的舍入行为可能不是您想要的。
它不存储具有值的货币,而是假设所有货币列都包含数据库的lc_monetary区域设置指定的货币。如果出于任何原因更改 lc_monetary 设置,则所有资金列都将包含错误的值。这意味着,如果您在 lc_monetary 设置为“en_US.UTF-8”时插入“$10.00”,则如果 lc_monetary 发生更改,您检索到的值可能是“10,00 Lei”或“¥1,000”。
将值存储为数字,并可能在相邻列中使用货币,可能会更好。
你什么时候应该?
如果您只使用单一货币,不处理小数美分,只进行加法和减法,那么货币可能是正确的选择。
不要使用串口
对于新应用程序,应改用标识列。
为什么不呢?
串行类型有一些奇怪的行为,使架构、依赖关系和权限管理变得不必要的麻烦。
你什么时候应该?
- 如果您需要 PostgreSQL 版本 10 之前的支持。
- 在与表继承的某些组合中(但请参阅那里)
- 更一般地说,如果您以某种方式对多个表使用相同的序列,尽管在这些情况下,显式声明可能比串行类型更可取。
验证
不要使用 trust 通过 TCP/IP 进行身份验证( host , hostssl )
不要使用 trust 在任何生产环境中通过任何 TCP/IP 方法(例如 host、hostssl)进行身份验证。
特别是不要在您的 pg_hba.conf 文件:
host all all 0.0.0.0/0 trust
它允许互联网上的任何人作为集群中的任何 PostgreSQL 用户进行身份验证,包括 PostgreSQL 超级用户。
您可以选择一系列更适合建立与 PostgreSQL 的远程连接的身份验证方法。设置基于密码的身份验证方法相当容易,建议是 scram-sha-256 这在 PostgreSQL 10 及更高版本中可用。
为什么不呢?
手册说:
trust身份验证仅适用于 TCP/IP 连接,前提是您信任每台允许连接到服务器的计算机上的每个用户。pg_hba.conf指定的行trust。除了来自 localhost (127.0.0.1) 的连接之外,对任何 TCP/IP 连接使用信任很少是合理的。
和 trust 身份验证,任何用户都可以声称自己是任何其他用户,并且 PostgreSQL 将信任该断言。这意味着某人可以声称自己是 postgres 超级用户帐户和 PostgreSQL 将接受该声明并允许他们登录。
为了更进一步,允许 trust 身份验证用于 local 生产环境中的 UNIX 套接字连接,因为任何有权访问运行 PostgreSQL 的实例的人都可以以任何用户身份登录。
你什么时候应该?
简短的回答是永远不会。
更长的答案是有几种情况 trust 身份验证可能是合适的:
- 作为可信网络上 CI/CD 作业的一部分,针对 PostgreSQL 服务器运行测试
- 在本地开发计算机上工作,但只允许通过本地主机进行 TCP/IP 连接
但您应该看看是否有任何替代方法更适合您。例如,在基于 UNIX 的系统上,您可以使用以下命令连接到本地开发环境 peer 验证。