一、问题描述:
- 在进行sam模型迁移到昇腾的时候存在精度问题,模型链接:
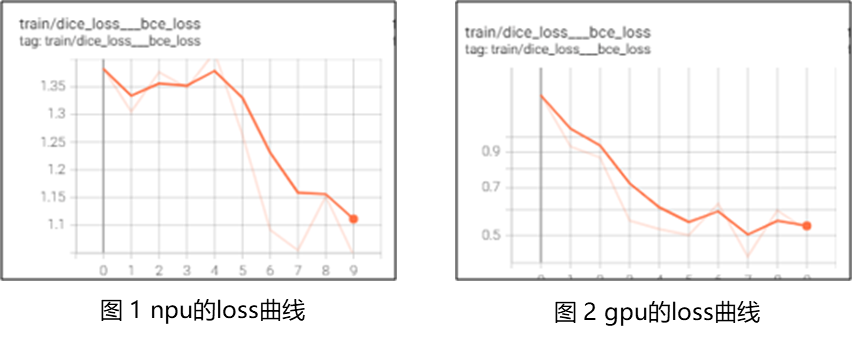
https://github.com/facebookresearch/segment-anything - 两台机器上训练loss图对比,发现从一开始训练的时候就出现了差别,从图中对比看出来npu第一步
就开始没有向下收敛,而gpu是向下收敛。
二、问题分析过程
-
准备dump精度对比看看区别,使用Ascend开源仓的msprobe工具进行精度对比
https://gitee.com/ascend/mstt/blob/master/debug/accuracy_tools/msprobe/docs/01.installation.md
工具安装命令:点击查看代码
`pip install mindstudio-probe` -
然后在训练脚本部分加代码,按照示例添加代码
使用示例可参见Ascend开源仓的PyTorch 场景的精度数据采集示例代码 2.1 快速上手和2.2 采集完整的前反向数据。 -
添加start函数
功能说明:启动精度数据采集,在模型初始化之后的位置添加,需要与 stop 函数一起添加在 for 循环内。model:指定具体的 torch.nn.Module,默认未配置,level 配置为"L0"或"mix"时,必须在该接口或 PrecisionDebugger 接口中配置该参数。 本接口中的 model 比 PrecisionDebugger 中 model 参数优先级更高,会覆盖 PrecisionDebugger 中的 model 参数。点击查看代码
debugger.start(model=None) -
添加stop函数
功能说明:停止精度数据采集,在 start 函数之后的任意位置添加,若需要 dump 反向数据,则需要添加在反向计算代码(如,loss.backward)之后。点击查看代码
debugger.stop()点击查看代码
from msprobe.pytorch import PrecisionDebugge debugger = PrecisionDebugger(config_path='./config.json') ... debugger.start() # 一般在训练循环开头启动工具 ... # 循环体 debugger.stop() # 一般在训练循环末尾结束工具 debugger.step() # 在训练循环的最后需要重置工具,非循环场景不需要这里的config.json也可以设置很多种类型,这里选用tensor模式和mix级。
点击查看代码
{"task": "tensor","dump_path": "/home/data_dump","rank": [],"step": [],"level": "mix","tensor": {"scope": [],"list":[],"data_mode": ["all"]} } -
直接运行训练脚本,在数据dump下来之后 跟gpu的精度进行对比。

npu在这里丢了image_embedding的梯度,因为该模型用到了Reg_op(RepeatInterleaveGrad)这个算子,接下来分析cann包是否有这个算子 发现是有的 但是通过进入python后调用torch_npu.repeat_interleave_backward_tensor这个函数,发现调用失败。


调用失败显示 :AttributeError: module 'torch_npu' has no attribute 'repeat_interleave_backward_tensor'
-
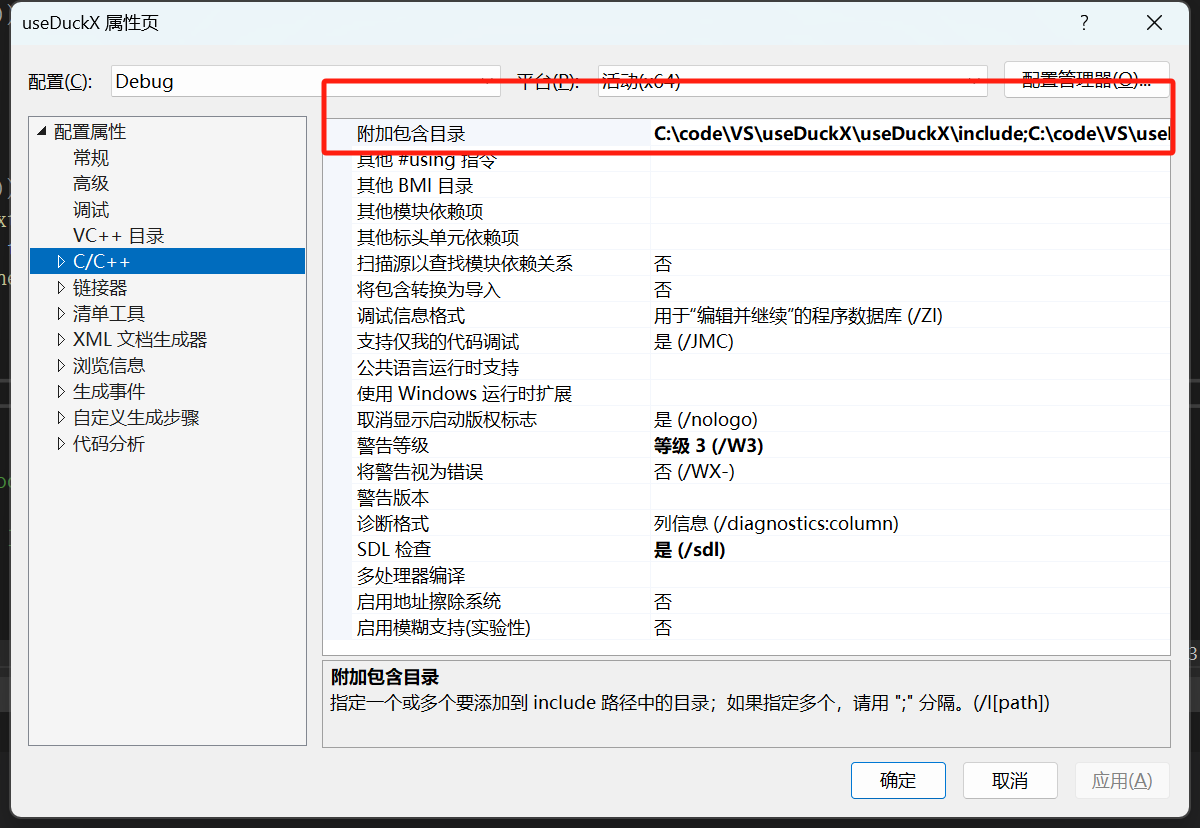
查看torch_npu版本,发现是2.1post3和pytorch2.1版本不配套。
三、解决方法:
通过查看昇腾torch_npu的版本与pytorch的配套表,选择对应的torch_npu版本:https://gitee.com/ascend/pytorch
选用配套版本后,函数调用成功,loss图也正常。