注:编译、测试之前运行sudo sysctl vm.mmap_rnd_bits=28
BusTub's architecture:

1. Query Processing (查询处理层)
负责将输入的 SQL 查询转化为可执行的物理查询计划。
- Parser(解析器):将输入的 SQL 字符串解析为抽象语法树 (AST),检查 SQL 语法是否合法。
- Binder(绑定器):对 AST 进行语义分析,绑定表名、列名到数据库中的具体对象,并验证其存在性。
- Planner(计划生成器):根据绑定后的语法树生成逻辑查询计划,描述查询的高层操作序列。
- Optimizer(优化器):应用如过滤下推、连接重排等优化策略,优化逻辑查询计划,生成具体的物理查询计划。
2. Query Execution(查询执行层)
负责根据物理查询计划执行操作,生成查询结果。
- Executor(执行器)
实现查询计划中各物理操作(如扫描、过滤、连接、排序等)。采用迭代器模式, 每个执行器实现自己的逻辑,通过调用其子执行器的 Next 方法逐步获取数据并逐一进行加工(例如过滤、投影、连接等)。
3. Concurrency Control (并发控制层)
管理多事务并发执行,保证数据库的一致性和隔离性。
- Transaction Manager(事务管理器):
- 管理事务的生命周期,包括开启、提交、回滚。
- 通过锁机制或 MVCC(多版本并发控制)技术实现事务隔离。
- 保证事务遵循 ACID 特性(原子性、一致性、隔离性、持久性)。
- 提供死锁检测与恢复机制。
4. Storage(存储层)
负责数据的物理存储与管理,为上层提供高效的数据操作接口。
- Index(索引模块)
提供高效数据检索功能,支持 B+ 树、哈希表等索引结构,实现查找、插入、删除及范围查询。 - Table Heap(表堆模块)
管理表中记录的物理存储布局,支持记录的增删改查操作,提供记录的迭代访问。 - Buffer Pool Manager(缓冲池管理器)
- 管理内存与磁盘之间的数据交换。
- 提供页面缓存机制,使用替换算法(如 LRU)优化内存利用率。
- 提供一致的内存视图,屏蔽底层存储细节。
- Disk Manager(磁盘管理器)
- 管理磁盘文件的读写操作,为页面提供底层 I/O 支持。
- 负责数据的持久化,支持页级别的读写接口。
- 与缓冲池管理器配合,实现高效数据访问。
Proj0: C++ Primer (实现写时复制字典树)
写时复制字典树每次修改都会在共用部分节点的同时复制必要节点得到一棵新树。

Task1. Copy-On-Write Trie
实现Trie类中的Get(), Put(), Remove()函数,使字典树每次修改不会改变原来的树,而是在共用部分节点的基础上新建一棵树。
困难与解决:
(1)对智能指针的不熟悉: 翻阅cppreference;
(2)val可能不可复制: 在复制时使用使用移动语义;
(3)写时复制的实现: 插入时用迭代法复制,删除时使用递归.
Task2. Concurrent Key-Value Store
实现TrieStore类的Get(), Put(), Remove()函数,使其线程安全。
Proj1: Buffer Pool Manager (实现内存缓冲池)
如果直接使用mmap让OS管理文件在磁盘和内存之间的映射会导致数据一致性问题(无法控制OS的flush)和加锁等问题,因此DBMS需要自己实现Buffer Pool Manager来管理文件。内存缓冲池是磁盘的缓存,以页(帧)为单位,映射方法是全相联映射,替换算法是LRUK算法。所有对磁盘的操作都要先读到内存缓冲池。
补充知识:OLTP(联机事务处理)和OLAP(联机分析处理),两种存储模型,前者侧重写密集型(大量增删改),后者侧重读密集型(复杂查询).
Task1. LRU-K Replacement Policy
实现缓冲池的LRUK替换算法,即选择最近第k次访问的时间戳离当前时间戳最远的页(帧)进行替换。该算法相比LRU更好地考虑了频率因素,解决了LRU在访问频率高但最近一次访问距离远时性能不佳的问题。其中LRUK_replacer类维护一个哈希表<frame_id, LRUKNode>,每次替换遍历该哈希表查看LRUKNode中的信息来选择将被替换的frame_id; LRUKNode保存对应帧被访问的信息,是一个最长为k的时间戳链表。
困难与解决:
(1)线程安全方面所有对哈希表的访问都加一把大锁,同步粒度不够细。
Task2. Disk Scheduler
实现DiskScheduler类对磁盘请求进行FIFO调度。该类维护一个线程安全的请求队列,并且创建一个工作线程专门负责从该队列中调度请求并完成请求。
Task3. Buffer Pool Manager
利用LRUK_replacer和DiskScheduler实现BufferPoolManager类管理内存池。该类在构造时new一个Page类数组作为内存池,其中Page类有元数据(page_id, valid, dirty, pin_count)和一个固定大小数据区。类中page_table管理page_id和frame_id的映射,page_id是系统某个页的id,frame_id是内存池中某个帧的id,即Page数组的下标。
(1)实现NewPage(), 为系统创建一个新页(page_id++),从free_list中或通过替换得 到一个frame_id,修改对应Page的元数据并完成映射。
(2)实现FetchPage(), 获取对应页(Page*),如果在内存中则直接返回,否则先读到 内存,完成映射再返回。
(3)实现DeletePage(), 删除对应页,将帧回收到free_list.
(4)实现FlushPage(), FlushAll()主动将页写回磁盘。注意写磁盘时要给page加读 锁,因为可能其他线程正在使用这一页。
(5)UnpinPage()减少Page的pin_cnt同时设置dirty位。注意原来dirty=true的不 能将其设置为false.
困难与解决:
(1)buffer pool管理的是page的元数据,而page中的锁管理的是page的data, 所以buffer pool中不需要对page加锁。
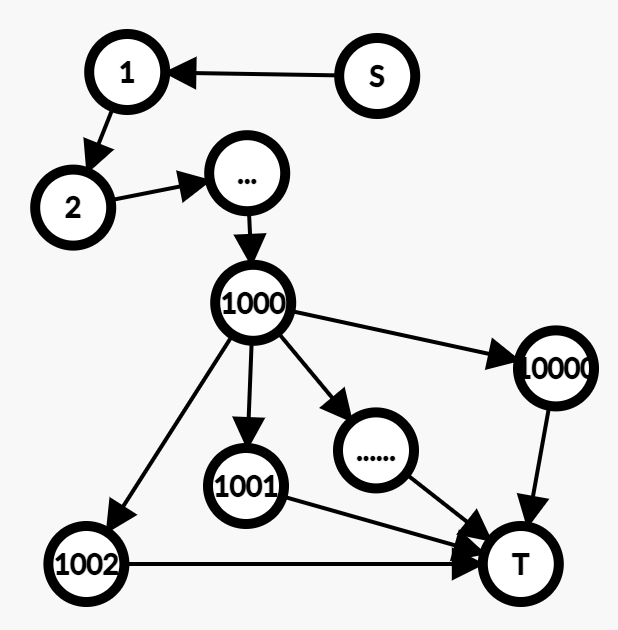
Extendible Hash(可扩展哈希)是分层的哈希表,以位串为哈希值,根据当前元素最少需要多少位来分辨而动态地调整哈希表的长度。可解决Chained Hash的链表无限增长导致查询效率降低的问题。传统的可扩展哈希分层为Directory和Bucket,在Directory中以哈希值为索引找对应Bucket,Bucket存放若干元素,且Directory的大小可动态变化。Bustub的哈希表在此基础上加了一层Header,用于索引Directory,不过Header的大小是静态的。且哈希值高n位用于索引Directory,低x位用于索引Bucket.

与B+树索引对比:
Extendible Hash Table:
- 适合 单值查询 O(1) 和 快速插入/删除(不需要调整树结构)。
- 不适合需要 范围查询 或 顺序访问 的场景(需要全表扫描)。
- 如果哈希冲突可能需要频繁扩展导致性能下降。
B+ Tree:
- 适合 范围查询、顺序访问 和 复杂查询。
- 在高并发或频繁插入/删除(需要调整树结构)的场景下性能可能略逊。
补充知识:布隆过滤器,用于快速判断一个key是否存在,只有Insert和Lookup两个操作,Insert时将多个Hash函数应用到key上,将bitmap中对应位都置为1;Lookup则是检查对应位是否都为1. 有一定概率误判。
Task1. Read/Write Page Guards
封装对页的访问(PageGuard),使对页的访问满足RAII,即生命周期结束时会自动Unpin,此外还有ReadPageGuard和WritePageGuard,自动加读写锁和释放读写锁。
Task2. Extendible Hash Table Pages
实现可扩展哈希相关类(HeaderPage, DirectoryPage, BucketPage).
(1)HeaderPage有成员
max_depth: 哈希值中用于索引的位数;
directory_page_ids: 存储对应Directory的page_id.
(2)DirectoryPage有成员
max_depth: 可用于索引的最大位数;
bucket_page_ids: 存储对应Bucket的page_id;
global_depth: 当前Directory用于索引的位数, 表长 = 2^gd;
local_depth: 对应Bucket实际用于索引的位数, 如下图的A只需要0就可以索引到。

Bucket满时插入,①若ld == gd,则gd++, Directory长度翻倍; ②Bucket分裂,且分裂后Bucket的ld++, 重新映射, 元素重新分配; ③再次索引,若还满则重复前面的步骤。
(3)BucketPage有成员
size_: 当前Bucket有多少元素;
max_size_: Bucekt最多有多少元素;
array: 存放元素的数组.
Task3. Extendible Hashing Implementation
实现可扩展哈希表类(DiskExtendibleHashTable), 是索引表,有index_name,即创建一个索引就是创建一个该类实体。本lab中只实现唯一索引,不能重复。该类有GetVal(), Insert(), Remove()三个函数,主要在于实现插入时的扩容、分裂、重映射,以及删除时的合并、缩容、重映射。
(1)在这些过程中要用到Task2中的各类,并用Task1中的PageGuard管理,可扩 展哈希在从上一层获取到下一层的idx后就可以Drop(Unpin, Unlatch)掉上一层的Page 了。
(2)插入时用while循环判断只要bucket满: { 若ld == gd, directory扩容(gd++); 收集元素并清空旧桶, 创建新桶, 再重新映射, 将收集的元素重新分配; }.
(3)删除后, while循环判断只要bucket或split bucket有一个空且二者ld相等, 就合 并二者(删除空的page并重新映射), 循环体末尾更新bucket变量和split bucket变量。 合并完后若可以缩容(ld < gd)就缩容(gd--).
Proj3: Query Execution (实现查询优化和查询执行)
SQL语句在经过Parser(解析器)、Binder(绑定器)和Planner (计划生成器)后变为逻辑执行计划,还需要由Optimizer(优化器)进行优化生成物理执行计划,然后交由Executor(执行器)以迭代器模式进行执行。
其中迭代器模式指:每个执行器实现自己的逻辑,通过调用其子执行器的 Next 方法逐步获取数据并逐一进行加工(例如过滤、投影、连接等)。
例: SELECT * FROM table WHERE column > 10:
(1)表扫描执行器:
- SeqScanExecutor 的 Next 函数从表堆(Table Heap)中逐条读取数据。
- 每次调用 Next,它会返回一个记录(元组)及其位置(RID)。
(2)过滤器执行器:
- FilterExecutor 的 Next 函数调用 SeqScanExecutor 的 Next,获取下一个元组。
- 检查元组是否符合过滤条件(column > 10)。
- 如果符合条件,返回元组;否则继续调用 SeqScanExecutor 的 Next 直到找到符合条件的元组或没有更多元组。
执行器部分主要类有Plan, Expression, Executor, 分别有最基本的抽象类和各种执行器的派生类,其他类有ExecutorEngine, ExecutorFactory, ExecutorContext等执行入口、辅助工具或上下文。
其中Plan是 查询处理层 生成的执行计划树的节点,描述的是执行的静态蓝图,包含若干个Expression;Expression是具体表达式,调用其Evaluate函数得到对应结果;Executor是执行器实例,为树形结构,与Plan树一一对应。
执行流程:
ExecutionEngine 创建并调用执行器树:
ExecutionEngine 由Plan树根节点递归创建执行器树,并调用根执行器的 Init 和 Next 方法开始执行。(每个执行器的Init()先递归调用子执行器的Init()),
Executor 调用 Plan:
每个执行器实例根据对应的Plan节点逻辑执行操作,Plan是Executor的“蓝 图”。
Executor 调用 Expression:
如果Plan节点中有表达式,Executor会调用表达式的Evaluate方法来计算值。
例如:
FilterExecutor会调用表达式来判断是否满足过滤条件。
ProjectionExecutor会调用表达式来计算需要的列值。
优化器部分是Optimizer类中的各个函数对应各种优化策略,从Plan树根节点开始递 归应用到每个Plan节点,这些策略主要包括:
1.将嵌套循环连接优化为哈希连接
OptimizeNLJAsHashJoin
背景:嵌套循环连接的时间复杂度高,尤其是当连接条件包含等值条件时,哈希连接可以显著提高性能。
2.将嵌套循环连接优化为索引连接
OptimizeNLJAsIndexJoin
背景:当存在适合的索引时,使用索引直接定位连接元组可以避免全表扫描,大幅提高连接效率。
3.将过滤条件直接合并到顺序扫描
OptimizeMergeFilterScan
背景:避免在过滤条件之外生成冗余的 Filter Plan Node,直接在扫描阶段过滤无关元组。
4.将顺序扫描优化为索引扫描
OptimizeSeqScanAsIndexScan
背景:当查询涉及等值条件,且目标列上存在合适的索引时,可以使用索引扫描代替顺序扫描,减少 I/O 开销。
5.将排序和限制(Limit)操作优化为 Top-N 算法
OptimizeSortLimitAsTopN
背景:Top-N 是一种仅提取部分结果的高效算法,比常规排序再限制的方式性能更高。
6.消除恒为 true 的过滤条件
OptimizeEliminateTrueFilter
背景:一些过滤条件在优化过程中可能退化为常量 true,删除这些无意义的过滤操作可以提高执行效率。
补充知识:Join分为三类:NestedLoopJoin:两个for循环扫描两个表进行对比,适 用于表规模较小时;
HashJoin:先扫描外表(较小的表)构造哈希表,然后扫描 内表与哈希表中对应外表元组进行对比,适用于两表规模 差距大时;
MergJoin:两个指针类似Merge的方式扫描两个有序 表,适用于两个表有序时;
Task1. Access Method Executors
实现对表进行读写的执行器,即增删查改,以及扫描优化。
(1) SeqScan执行器:利用Table Iterator从Table Heap中顺序读取tuple,判断是 否满足谓词,满足则返回它的副本和对应的rid(每个tuple的唯一标识);
(2) Insert执行器:从孩子节点Values Executor中获得要插入的tuple,并将其插入 到table中,同时对该table的每个索引获取该tuple的key tuple以及rid形成键值对 [ key tuple, rid] 插入到对应的索引中;( rid是tuple的rid );
(3) Update执行器:从孩子节点获得要更新的tuple,删除它们,然后利用expressions 和旧的tuple得到新的tuple,再插入即可。同时更新表相关的索引,也是先删除后 插入;
(4) Delete执行器:标记删除;
(5) IndexScan执行器:以plan中谓词的列为key从对应索引中的底层数据结构 (23fall为extendible hash table)获取所有对应的rids,由于23fall只支持unique key, 故只可能找到0个或1个rid,然后获取该rid对应的tuple,判断是否满足谓词即可。
(6) SeqScanToIndexScan优化:当有等值条件子句时,优化前的做法是先用 SeqScanExecutor进行全表扫描然后用FilterExecutor进行谓词过滤,而优化器可以将谓 词过滤下放到SeqScan,然后根据谓词所作用的列是否有索引将SeqScan转化为 IndexScan. 本Proj只转换单一等值谓词。
Task2. Aggregation & Join Executors
实现聚合函数执行器和连接执行器。
(1)Aggregation执行器:聚合执行器在执行时维护一个哈希表(unordered_map), key是group by的列值,value是各个聚合函数的结果集,每次Next函数根据输入的 tuple生成key和value插入到哈希表或合并结果。由于聚合函数的值需要遍历完整张 表才能得到,故在Init阶段就要遍历整张表,Next每次返回group by列+aggregation 列,即哈希表的key+value. 注意:空表如果没有group by则返回0或NULL,有则不 输出。
(2)NestedLoopJoin执行器:只需实现内连接和左连接,嵌套循环扫描两张表,满 足则输出,否则一直扫描,内表(右孩子的输出表)到末尾了则调用它的Init(),这里出了 些bug因为之前实现的执行器Init()没有重置状态变量,重置下就好了。
Task3. HashJoin Executor and Optimization
实现哈希连接和连接优化(NPL优化为Hash)。
(1)HashJoin执行器:维护一个哈希表(unordered_multimap<HashJoinKey,Tuple>), 类似Aggregation执行器自定义一个HashJoinKey类和它的哈希函数,用plan的表达 式计算各元组的HashJoinKey,在Init()中用右表构造哈希表(方便左连接),然后在 Next中扫描左表结合哈希表生成结果。注意由于哈希冲突,哈希表应是multimap.
(2)NLJAsHashJoin优化:将谓词是由AND结合的等值比较的NLJ优化为HashJoin, 递归判断谓词是否满足,如果是AND则继续左右递归,如果是EQUAL则获取哈希连 接所需的key表达式,应注意等值比较的左边不一定是连接的左表,要判断一下。
Task4. Sort + Limit Executors + Window Functions + Top-N Optimization
实现order by和limit的执行器,再将order by+limit优化为topn,最后再实现窗口函数。
(1)Sort执行器:按order by的顺序为优先级对元组进行排序,在Init阶段构造 SortKey然后用std::sort排序,SortKey用std::vector存储需要排序的列值,再根据顺 序写出less逻辑即可。注意sql没有规定order by必须稳定。
(2)limit执行器:只允许输出前n个元组,注意不足n个的情况。
(3)Top-N优化:order by+limit n可以优化为top n算法,即维护一个大小为n的 大根堆,当某元素比堆顶小时弹出堆顶元素,该元素入堆。注意最后输出需要升序,也 就还需要一个小根堆来负责输出。
(4)WindowFunction执行器:窗口函数,语法是FUNC() OVER (PARTITION BY col ORDER BY col ROWS BETWEEN...),和聚合函数不同的是他是给每行都加上函数值, selecet还可以选取原来的列。这里只需实现partition by和order by(且同一次查询order by字段相同),如果有order by则每一行计算从分区首行到当前行的函数值,如果没有 则都是整个分区的函数值。由于测试不检查输出顺序,即不用按partition by连着输出, 故可以直接整体排序,然后对每个tuple单独计算每个win_func (因为partition by可 能不一样,不能所有函数一起计算),以partition by列,win_func_idx (该函数在输出 元组中的列下标,把投影合并了)和win_func_type(用于做对应计算)共同组成key,以 函数值,sort_key(用于实现rank()), prev_rank和cur_rank为value,构建哈希表获取函数值,构成元组。


![[HarekazeCTF2019]baby_rop2(read的libc)](https://img2024.cnblogs.com/blog/3546944/202501/3546944-20250118165155633-2144929146.png)