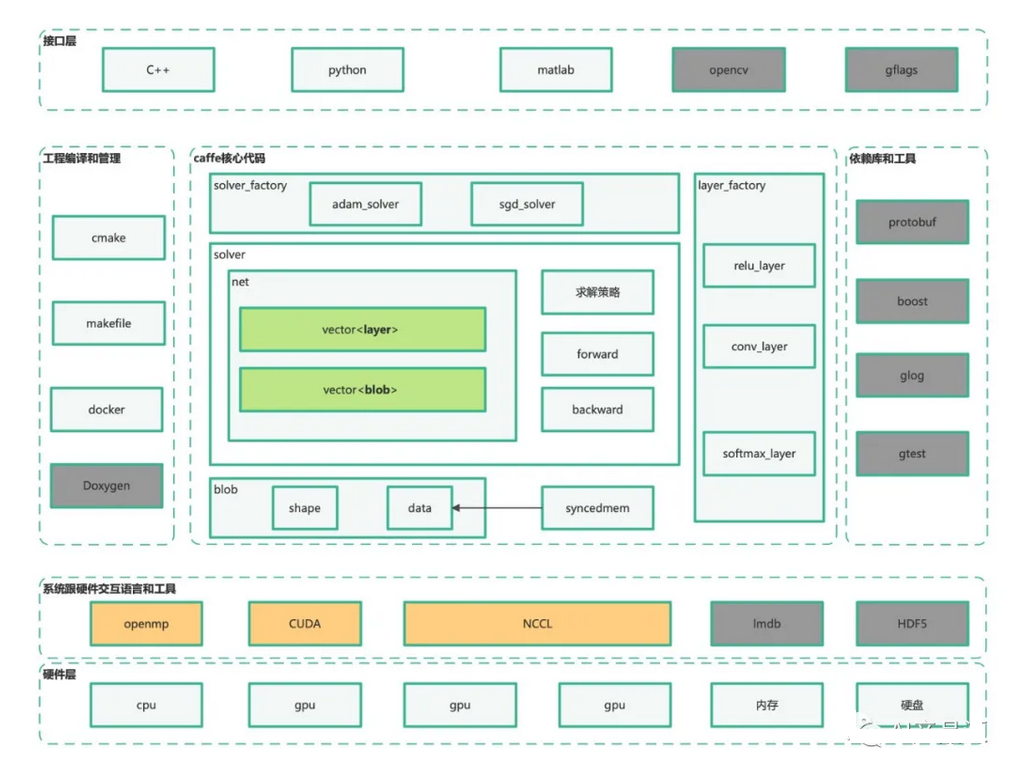
D.动态名单和提前终止
我们提出了一种动态列表和提前终止策略,以在图遍历过程中利用这些信息,如算法1所示。我们观察到,大多数查询在较小的T(候选列表大小)处收敛(找到它们的真实k-NN)。进一步增加T不会提高这些查询的召回率,只会增加计算成本。图6-(a)显示了DiskANN的这一趋势。我们看到在小T处收敛比迅速增加。对于像GLOVE这样的数据集,即使在大T下也具有较低的召回率,我们预计在给定的T下收敛的查询会更少,但总体趋势是一样的。基于此,我们设计了一种新的提前终止技术,该技术在图遍历过程中使用动态列表迭代调整T(第16行)。
E.顶点索引的间隙编码
图ANNS算法存储NN索引和原始数据。这导致了两个问题:
1. 获取顶点索引(NN索引)会在搜索过程中产生显著的数据访问开销,如图6-(b)所示,占80%至90%。
2.神经网络指数的大小与原始数据相当。现有算法使用统一的32-b整数来表示顶点索引。但是,不同图尺度的统一位宽是多余的,因为log2 N⌉-b足以表示大小为N的数据集的顶点索引。Proxima使用间隙编码来节省NN索引所需的空间和数据移动。图5-(a)显示了由12个元素的邻接表表示的4个索引和3个NN的示例。未压缩的32-b邻接列表消耗384-b空间。相比之下,间隙编码包括两个步骤:
首先,按升序对每行中的NN索引进行排序,然后将排序后的索引转换为除第一个索引外的前一个索引的差值。在这种情况下,比特宽度由最大差值的比特决定。因此,所需的空间减少到168-b。我们的实验表明,1M到100M数据集的图形需要20-b到26-b的间隙编码,导致至少19%到37%的图形索引数据压缩。压缩的图索引也有助于实现更快的图遍历,因为索引获取的开销减少了。

图6 (a)GLOVE、DEEP1M、SIFT的搜索收敛趋势。(b)使用不同程度的R进行内存流量细分。
A.架构概述
图7展示了Proxima加速器的架构,由两个主要部分组成:3D NAND磁贴和搜索引擎。Proxima是一个独立的近存储加速器,可以实现数据存储和高效的ANNS功能。这是通过利用先进的异构集成技术实现的,该技术将3D NAND晶片和CMOS晶片连接起来,以获得更好的效率和存储容量。

图7 3D NAND闪存中的Proxima加速器。
B.Proxima执行流程
Proxima加速器的执行主要由两个步骤组成:
1.图形数据预加载和
2.查询图搜索。在图搜索之前,需要使用第IV-E节所示的拟议数据映射方案将原始数据、原始数据的PQ代码和NN索引预存储到相应的物理地址中。
在存储了所需的数据后,图8显示了图搜索过程中搜索引擎内部的数据。整个图搜索包括四个步骤:步骤1是新查询的初始阶段,PQ模块根据查询数据计算非对称距离表(ADT)。计算出的ADT被传输到调度器指定的目标队列中的ADT内存。在步骤2中,队列中的候选列表弹出未评估的顶点,仲裁器生成相应的地址以从3D NAND核中获取NN索引(算法1中的第4-6行)。
获取的NN索引首先通过布隆过滤器来更新新访问的顶点,并过滤掉之前计算的顶点。然后,这些未访问顶点的PQ码由距离计算模块提取和计算(算法1中的第6-8行)。
在步骤3中,在访问了所有邻居之后,需要进行排序以选择前L个候选者(算法1中的第10行)。所实现的Bitonic分拣机是所有搜索队列共享的分拣机,因为它可以提供足够的吞吐量。
在基于PQ距离的搜索完成后,候选列表内存中的顶部顶点将使用其原始数据重新排序(算法1中的第12行)。图8中的步骤4对此进行了说明。同时,候选列表还检查是否满足提前终止条件。

图8 搜索引擎的内部架构。
我们基于3D NAND模拟器开发了一个模拟器,以预测图9中96层3D NAND的密度、面积和读取延迟之间的权衡,作为Proxima内核的设计指南。较大的页面大小可能会导致超过10 4ns的读取延迟。之前的工作表明,预充电和放电过程约占页面读取延迟的90%。长的预充电和放电时间是由数百个块和广泛的页面大小产生的大电容负载造成的。我们定制了Proxima 3D NAND内核,以减少长时间的读取延迟并提高数据粒度。

图9 96层3D NAND ffash的密度、面积和读取延迟权衡。
图索引重新排序。从ANNS工具生成的图具有高度随机的索引分布。我们首先对索引进行重新排序以增加其局部性,而不是直接映射不规则图索引。如图10-(a)所示,图索引的重新排序是基于顶点的访问频率。
较热(更频繁)的顶点具有较小的索引,这意味着入口点从0开始。顶点访问频率的计算基于随机采样基础数据的图搜索轨迹。图索引的重新排序有助于提高索引的局部性。
数据分配和地址转换。大多数图形搜索操作都与PQ代码和图形索引有关,而在重新排序步骤中,需要访问原始数据以进行精确的距离计算。我们让Proxima将原始数据单独存储在一些3D NAND内核中,而PQ代码和图形索引则存储在一起。如图10-(b)所示,我们使用核心级轮转地址映射方案,将具有连续索引的数据分配给连续的核心。此方案有助于最大限度地提高内存利用率。每个页面使用相同的比特长度来存储节点向量和相关的NN索引(度数<R的节点被填充到R以对齐地址)。图10-(a)显示了3D NAND内核每页中PQ代码和图形索引的耦合存储格式。

图10 (a)图索引重新排序和热节点重复。(b)地址映射。



![[2025.1.21 MySQL学习] 基本概念](https://img2024.cnblogs.com/blog/3574171/202501/3574171-20250121030322226-820748876.png)