在计算生物学和生物信息学领域,机器学习技术正迅速改变着我们对生物系统的研究方式。然而,随着模型复杂度的增加,如何解释这些模型的行为并从中提取生物学意义,成为了一个亟待解决的问题。
最近,卡内基梅隆大学的Jian Ma和Ameet Talwalkar团队在《Nature Methods》杂志上发表了一篇题为“Applying interpretable machine learning in computational biology—pitfalls, recommendations and opportunities for new developments”的综述文章,为我们提供了关于可解释机器学习(IML)在计算生物学中应用的全面视角。

IML:为何重要?
机器学习模型,尤其是深度学习模型,因其强大的预测能力而被广泛应用于计算生物学,例如基因表达预测、蛋白质相互作用分析和生物医学图像处理等。然而,这些模型通常被视为“黑箱”,难以理解其决策过程。
可解释机器学习的出现,旨在通过解释模型的预测结果,帮助研究人员验证模型是否真正反映了生物学机制,从而为生物学研究提供更可靠的工具。
IML两大类方法
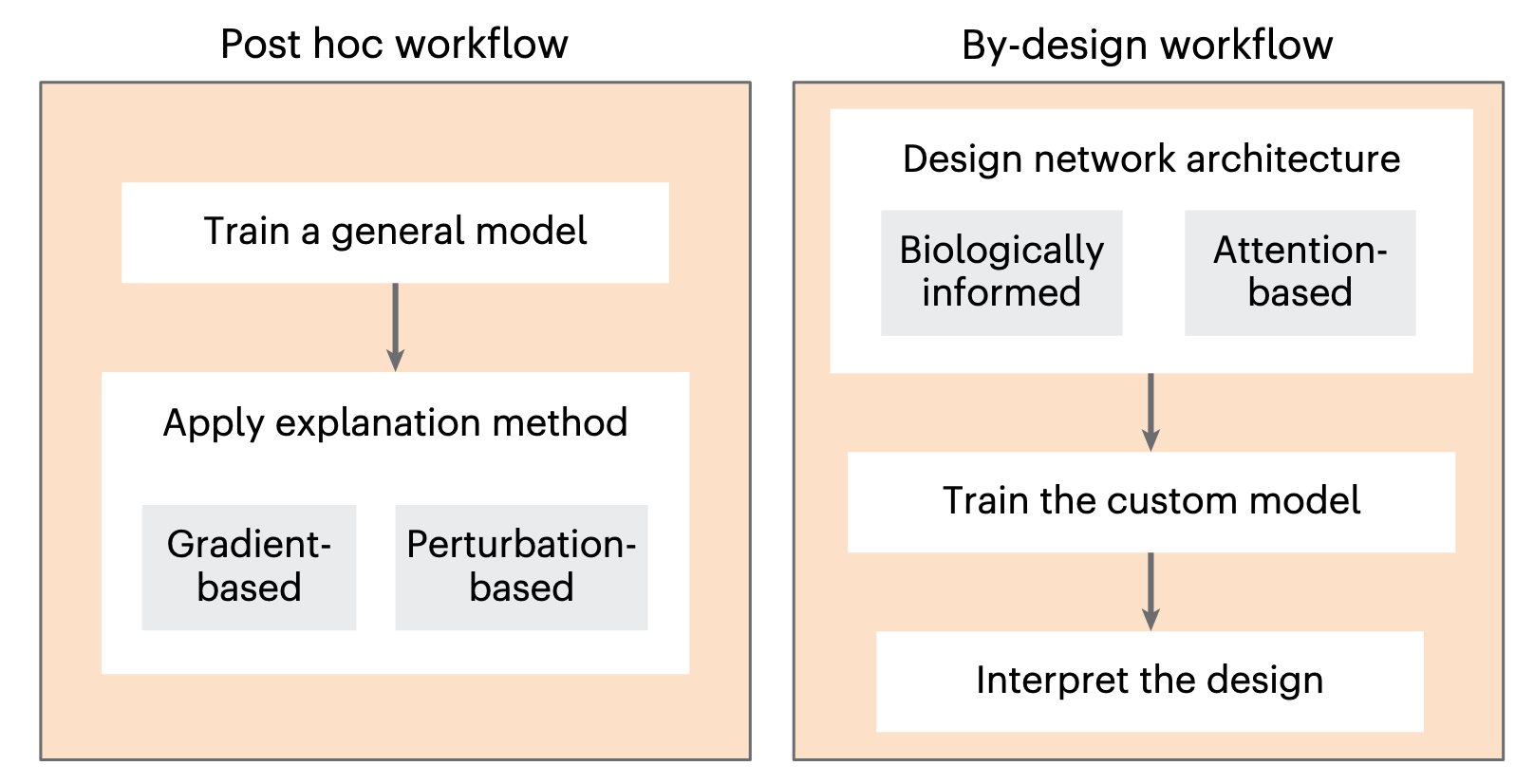
文章介绍了两类主要的IML方法:事后解释(Post hoc explanations) 和设计时解释(By-design explanations) 。
-
事后解释是在模型训练完成后进行的,具有模型不可知性,适用于各种模型。常见的方法包括基于梯度的方法(如DeepLIFT、Integrated Gradients)和基于扰动的方法(如SHAP、LIME)。这些方法通过计算输入特征的重要性分数,帮助研究人员理解哪些特征对模型的预测贡献最大。
-
设计时解释则是将可解释性嵌入模型架构中,例如线性模型、决策树和生物学驱动的神经网络。这类方法通过设计模型使其自然具备可解释性,例如将生物通路信息整合到神经网络中,使得模型的隐藏节点对应于生物实体,从而可以直接解释其权重。
IML评估指标
文章中介绍了两类主要的评估IML方法的指标:忠实度(Faithfulness)和 稳定性(Stability)。
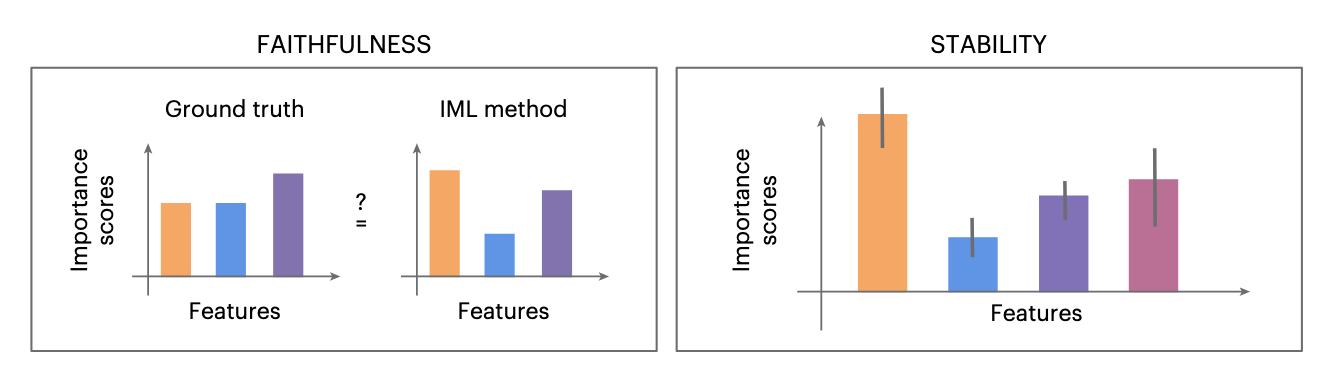
忠实度(Faithfulness)
定义: 忠实度是评估IML方法生成的解释与底层机器学习模型真实机制之间一致性的度量。它反映了解释在多大程度上准确地揭示了模型的决策过程。
评估方法:
- 基准测试:通过在多个数据集上进行基准测试,比较不同IML方法生成的解释与已知的真实机制。例如,在基因表达预测模型中,可以使用已知的基因调控网络作为真实机制的参考,评估IML方法是否能够准确识别出与基因调控相关的特征。
- 合成数据:在一些情况下,研究人员会使用合成数据来编码真实逻辑的变化,从而评估IML方法的忠实度。然而,文章指出,在计算生物学中,合成数据可能无法完全捕捉真实生物过程的复杂性,因此在实际应用中可能需要更多地依赖真实数据来评估忠实度。
应用场景: 在计算生物学中,例如在分析转录因子结合位点的预测模型时,忠实度评估可以帮助研究人员确定IML方法是否能够准确识别出影响转录因子结合的关键序列模式。
稳定性(Stability)
定义: 稳定性是衡量IML方法生成的解释在面对输入数据的小扰动时的一致性。它回答了“对于相似的输入,解释是否一致?”的问题。
评估方法:
- 输入扰动:通过对输入数据进行小的扰动(例如,改变DNA序列中的一个核苷酸),观察IML方法生成的特征重要性分数是否发生显著变化。如果解释在输入扰动下保持稳定,那么该IML方法的稳定性较好。
- 重复实验:在相同的模型和数据集上多次运行IML方法,评估生成的解释是否一致。例如,使用不同的随机种子或不同的模型初始化进行多次实验,观察特征重要性分数的分布情况。
应用场景: 在细胞图像分类任务中,稳定性评估可以帮助研究人员确定IML方法是否能够一致地识别出与细胞表型相关的图像特征,即使在图像存在轻微噪声或变化的情况下。
IML应用:从序列到图像
IML方法在计算生物学中的应用非常广泛,涵盖了从DNA、RNA和蛋白质序列分析到生物医学图像处理的多个领域。例如,通过分析基因表达数据,IML可以帮助识别关键生物标志物;在序列分析中,IML能够揭示调控基因表达的重要序列模式;在图像分析中,IML可以突出显示细胞图像中与特定表型相关的区域。
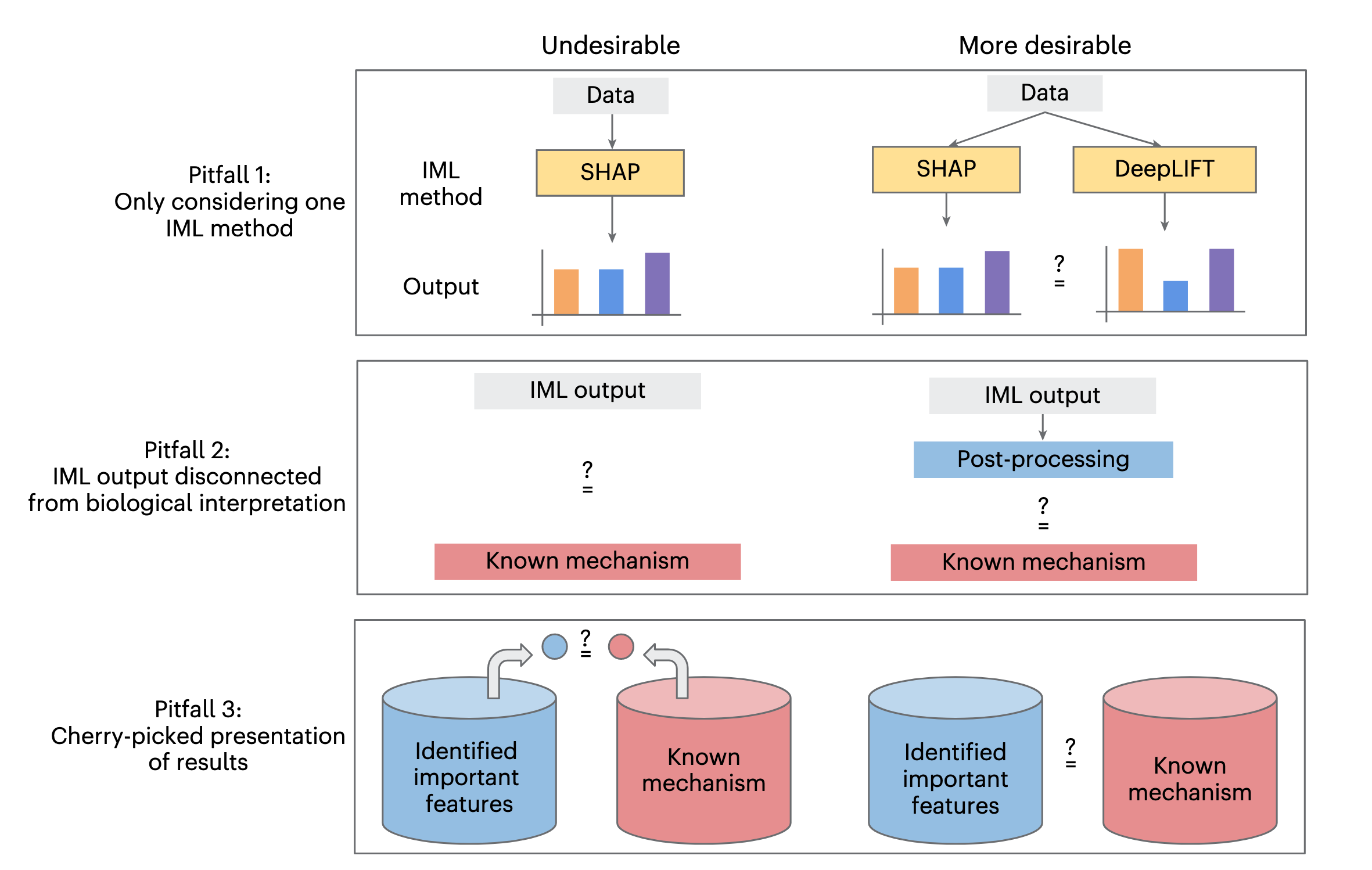
然而,文章也指出了当前IML应用中常见的三个陷阱:
- 仅依赖单一IML方法 :不同IML方法可能因算法和假设不同而产生不同的解释结果。例如,在转录因子结合位点的分析中,不同的IML方法可能会识别出不同的关键序列模式。因此,建议结合多种IML方法进行分析,以获得更全面的模型行为理解。
- IML输出与生物学解释脱节 :IML方法虽然可以识别出重要的特征,但这些特征并不一定直接对应于生物学意义。例如,在DNA序列分析中,需要通过后续分析(如序列模式发现或统计富集分析)将重要性分数转化为生物学解释。
- 选择性展示结果 :许多研究仅展示与已知生物学机制一致的IML结果,而忽略了其他可能揭示新机制的特征。这种选择性展示可能导致对模型行为的片面理解。因此,建议对整个数据集进行全面分析,并评估特征重要性的一致性。
大语言模型时代:IML的新机遇
随着大语言模型(LLMs)在计算生物学中的应用不断增加,如何解释这些复杂模型的行为成为了一个新的挑战。文章提出了几个发展方向:
-
生物数据的分词策略 :如何选择合适的分词方法以更好地反映生物学背景,是当前的一个关键问题。例如,DNA序列的分词方法可能影响对基因调控网络的解释。
-
针对LLMs的IML方法 :现有的LLMs解释技术(如注意力机制)在生物学中的应用仍处于初级阶段。未来需要开发更多适合生物学的解释方法,例如将LLMs的输出转化为可验证的生物学假设。
-
多模态数据的解释 :随着多模态数据(如基因组学与表观基因组学数据)的整合,如何解释不同模态之间的相互作用,也成为了一个亟待解决的问题。
总结与展望
可解释机器学习在计算生物学中的应用前景广阔,但也面临着诸多挑战。文章不仅为我们提供了IML方法的全面概述,还指出了当前应用中的常见问题,并提出了未来发展的方向。对于计算生物学和生物信息学的研究人员来说,这篇文章无疑是一个宝贵的资源,它提醒我们在追求模型预测能力的同时,不要忽视对模型行为的深入理解和解释。
在这个快速发展的领域,我们期待更多的研究能够填补IML方法与生物学应用之间的差距,从而推动计算生物学迈向一个新的高度。
参考文献
Chen, Valerie, et al. "Applying interpretable machine learning in computational biology—pitfalls, recommendations and opportunities for new developments." Nature methods 21.8 (2024): 1454-1461.