一、Milvus介绍
上一小节中,全面介绍了向量和向量数据库,今天详细介绍下其中比较出名的开源数据库Milvus。希望对你有帮助
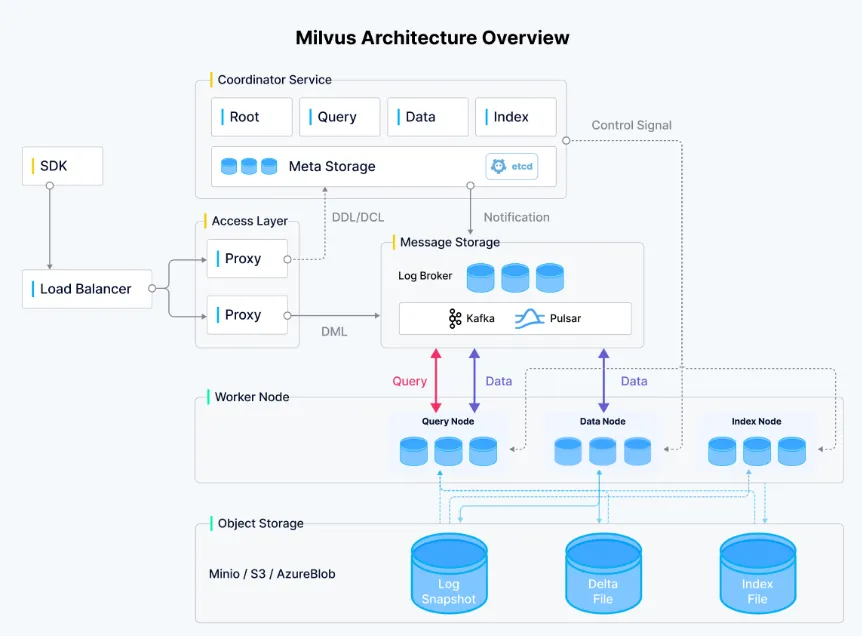
Milvus 是一个开源的、高性能的向量数据库,专为海量向量数据的快速检索而设计。在人工智能、计算机视觉、推荐系统和其他需要处理大规模向量数据的领域有着广泛应用。
以下是从产品功能、技术特点和优势等方面对 Milvus 的详细介绍:
Milvus的产品功能
1、向量检索:
支持基于欧氏距离、内积和余弦相似度的近似最近邻(ANN)检索。
支持高维向量数据的高效检索,适用于图像、视频、音频和自然语言处理等领域。
2、多模态数据管理:
除了支持向量数据,Milvus 还提供对结构化数据、非结构化数据的管理和检索能力。
3、分布式架构:
支持分布式存储和计算,能够处理 PB 级的数据,并且具备较高的扩展性。
4、数据持久化:
自动执行数据持久化操作,确保数据的持久保存和快速恢复。
5、实时插入和查询:
支持实时数据插入和快速查询,满足在线服务的需求。
6、多种索引类型:
提供多种索引类型(如 IVF、IVF_SQ8、HNSW、ANNOY 等),用户可以根据具体应用场景选择合适的索引算法。
7、丰富的 API 和客户端支持:
提供多种 API 和客户端库,支持 Python、Java、Go 等主流编程语言,方便用户进行二次开发。
Milvus的技术特点
1、高性能:
通过优化的数据结构和算法,Milvus 能够实现高效的向量数据检索,适应不同的使用场景需求。
2、分布式架构:
采用分布式架构,具备线性扩展能力,可以处理大规模数据并保持高吞吐量和低延迟。
3、灵活的索引机制:
支持多种索引类型,并允许用户根据数据特点和查询需求选择和调整索引,提供灵活的检索方案。
4、自动数据分片和负载均衡:
自动将数据分片存储到不同的节点上,并进行负载均衡,确保系统的高可用性和高性能。
5、高可用性和容错性:
通过多副本机制和数据持久化策略,保证数据的高可用性和容错性。
6、强大的查询优化:
内置查询优化器,能够智能优化查询路径,提升查询效率。
Milvus的优势
1、开源和社区支持:
Milvus 是一个开源项目,有一个活跃的社区,提供丰富的文档和示例代码,方便用户快速上手和使用。
2、高扩展性:
采用分布式架构,具备很强的扩展性,能够轻松扩展至数百节点,处理 PB 级数据。
3、多场景适用性:
适用于多种应用场景,包括图像检索、视频检索、推荐系统、自然语言处理等领域。
4、易于集成:
提供丰富的 API 和多个编程语言的客户端库,便于集成到现有系统中。
5、高性能:
通过优化的向量检索算法和索引机制,能够在大规模数据下保持高性能的检索能力。
6、全面的数据支持:
不仅支持向量数据,还支持结构化和非结构化数据,能够满足多样化的数据管理需求。
Milvus 是一个功能强大、高性能的向量数据库,专为大规模向量数据的检索和管理而设计。其主要特点包括高性能、分布式架构、灵活的索引机制、高可用性和容错性等。凭借这些特点和优势,Milvus 在人工智能、计算机视觉、推荐系统等领域有着广泛的应用。作为一个开源项目,Milvus 拥有活跃的社区和丰富的文档支持,是开发者进行大规模向量数据处理和检索的理想选择。
二、docker 安装
Milvus的安装是通多docker镜像安装的,所以之前先安装docker
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine
sudo yum remove docker*sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.reposudo yum-config-manager \--add-repo \https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.reposudo sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repoyum list docker-ce --showduplicates | sort -r# 注意docker-ce 和 containerd.io的版本
sudo yum install docker-ce-17.12.1.ce-1.el7.centos containerd.io-_1.2.13-2 docker-buildx-plugin docker-compose-pluginsudo systemctl start docker
sudo docker run hello-world
三、Milvus 安装
Milvus安装参考官方文档
https://milvus.io/blog/how-to-get-started-with-milvus.md
mkdir milvus_compose
cd milvus_compose
wget https://github.com/milvus-io/milvus/releases/download/v2.2.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
vim /etc/docker/daemon.json
sudo systemctl daemon-reload
sudo systemctl restart docker
docker-compose up -d# 安装 python接口库
pip install pymilvus
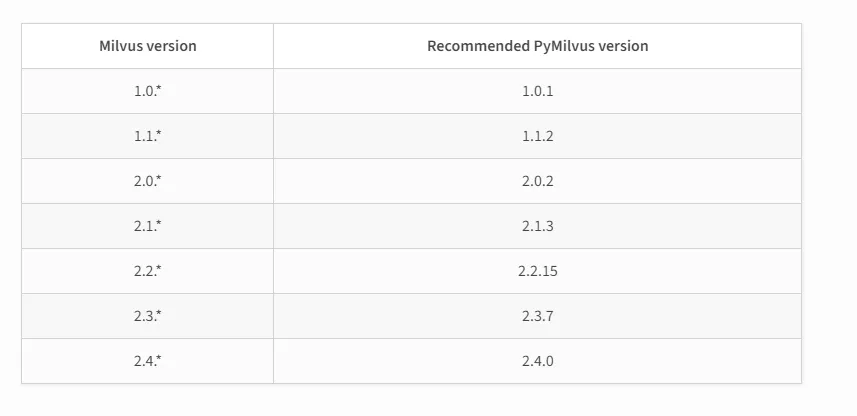
需要注意Milvus和python的对应版本
四、milvus基本操作
pymilvus 是 Milvus 的官方 Python SDK,用于与 Milvus 向量数据库进行交互。pymilvus 提供了丰富的 API 用于管理集合、索引、插入数据和执行查询等操作。以下是 pymilvus 的一些基本操作介绍,包括连接到 Milvus、创建集合、插入数据、构建索引和执行查询。
1、 安装 pymilvus
首先,你需要安装 pymilvus 库:
pip install pymilvus
2、连接到 Milvus
使用 connections.connect 方法连接到 Milvus 实例:
from pymilvus import connections# 连接到本地 Milvus 实例
connections.connect(alias="default", host="localhost", port="19530")
3、创建集合
创建一个新的集合,包括定义集合的名称和字段(例如,向量字段和 id 字段):
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType# 定义字段
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True)
vector_field = FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128)# 定义集合的 Schema
schema = CollectionSchema(fields=[id_field, vector_field], description="example collection")# 创建集合
collection = Collection(name="example_collection", schema=schema)
4、 插入数据
向集合中插入数据:
import numpy as np# 生成一些示例数据
ids = [i for i in range(10)]
vectors = np.random.random((10, 128)).tolist()# 插入数据
collection.insert([ids, vectors])
5、 构建索引
为向量字段构建索引以加速查询:
# 定义索引参数
index_params = {"metric_type": "L2","index_type": "IVF_FLAT","params": {"nlist": 128}
}# 创建索引
collection.create_index(field_name="vector", index_params=index_params)
6、 执行查询
执行向量检索查询:
# 加载集合到内存
collection.load()# 生成查询向量
query_vectors = np.random.random((1, 128)).tolist()# 定义搜索参数
search_params = {"metric_type": "L2","params": {"nprobe": 10}
}# 执行搜索
results = collection.search(data=query_vectors, anns_field="vector", param=search_params, limit=3,expr=None
)# 输出结果
for result in results:for hit in result:print(f"ID: {hit.id}, Distance: {hit.distance}")
7、管理集合
查看集合信息:
# 获取集合信息
print(collection.num_entities) # 显示集合中的实体数
删除集合:
# 删除集合
collection.drop()
8、 断开连接
完成所有操作后,可以断开与 Milvus 的连接:
connections.disconnect(alias="default")
总结
通过以上步骤,你可以使用 pymilvus 执行基本的 Milvus 操作,包括连接到 Milvus、创建集合、插入数据、构建索引和执行查询。这些操作构成了使用 Milvus 进行向量数据处理的基础。pymilvus 提供了丰富的 API,可以在实际应用中满足各种向量数据管理和检索的需求。
个人观点,仅供参考
原创 WedO实验君 人工智能微客