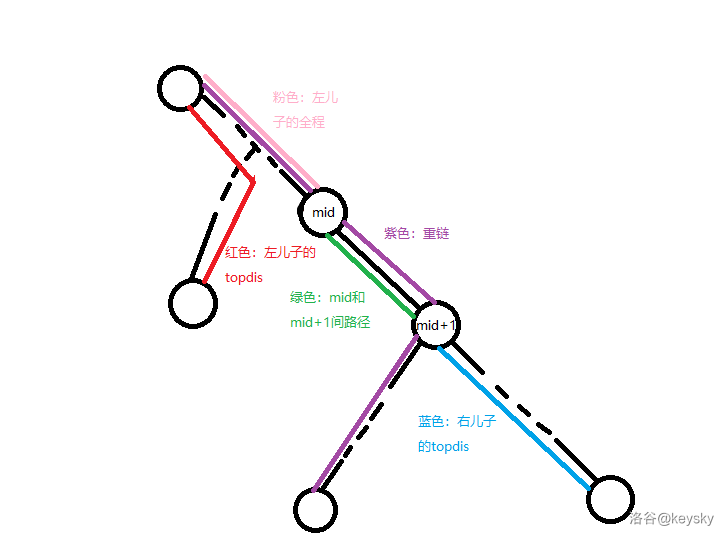
一、什么是向量
向量vector 通常出现在自然语言NLP领域,NLP中称为词嵌入word embedding,词嵌入的工作就是如何将人类语言中的词汇、短语或句子转化为计算机能够理解和操作的数学向量。

具体的,词嵌入(Word Embedding),是一种将词汇表中的每个单词或短语映射到一个固定大小的连续向量空间中的技术。这个向量空间通常具有几百到几千的维度,每个维度代表某个语言特征或语义属性。通过这种方式,相似的单词或短语在向量空间中会有相似的表示,这使得它们在数学上更易于比较和操作。
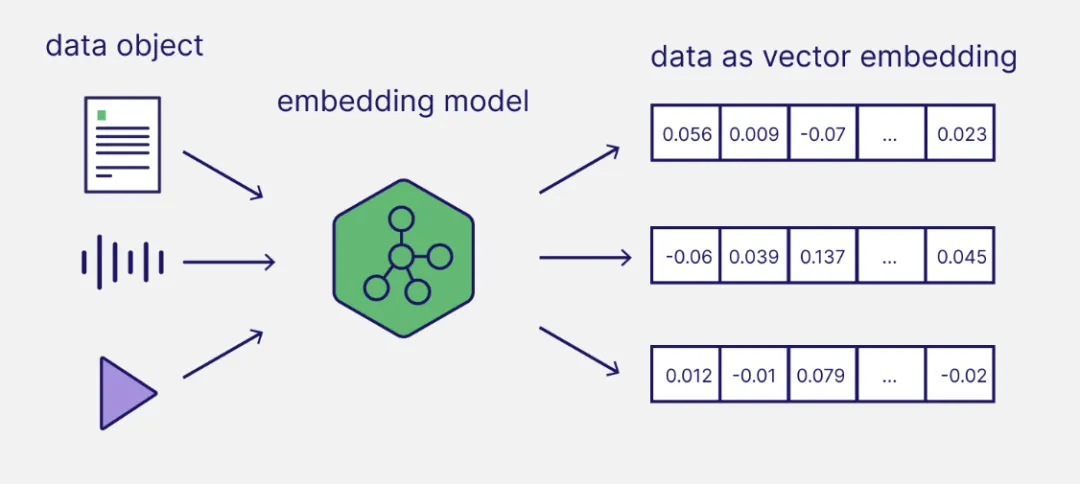
也就是生成的向量是可以表达输入文本的语义表征,这个语义表征和embedding模型学习的任务有关。比如学习分辨性别,语法和地理关系,在向量空间中,相同或相近语义的对象距离更近,这也是向量模型需要学习的目标。
当然,不止文本可以进行向量化,图片,音频都可以进行向量化。比较典型的例子就是人脸识别过程中,将人脸表征为一组向量,同一个人的不同图像向量距离很小,不同的人的图像向量距离大,以此来判断是否是同一个人。
二、为什么要向量化
在自然语言处理(NLP)中,向量化是一个至关重要的步骤,原因有多方面。以下是为什么我们要将文本数据向量化的一些主要原因:
1. 计算机可处理性
原始的文本数据(如单词、句子或段落)是离散的符号序列,计算机无法直接处理这种非数值型数据。
通过向量化,我们将这些符号转换为连续的数值向量,使得计算机能够对其进行数学运算和机器学习算法的处理。
2. 捕获语义信息
向量化不仅将单词转换为简单的标识符,还能够捕获单词之间的语义关系。
传统的独热编码(One-Hot Encoding)方法虽然为每个单词分配了一个唯一的标识符,但无法表示单词之间的相似性。而向量化方法(如Word2Vec、GloVe等)生成的词向量能够捕捉到单词之间的语义关系,使得相似的单词在向量空间中有相近的表示。
3. 处理复杂关系
在自然语言中,单词之间的关系往往比简单的共现关系更为复杂。
向量化方法能够学习到这些复杂的关系,如单词之间的类比关系(如“国王”之于“王后”类似于“男人”之于“女人”)和层次关系(如“动物”是“狗”和“猫”的上位词)。
4. 提高模型性能
在NLP任务中,如文本分类、情感分析、命名实体识别等,使用向量化表示的文本数据通常比使用原始文本数据或简单的独热编码表示能够获得更好的性能。
这是因为向量化表示能够捕获到文本中的深层语义信息,使得模型能够更好地理解和处理文本数据。
5. 便于计算相似度
在NLP中,我们经常需要计算文本之间的相似度或距离。
使用向量化表示后,我们可以使用各种距离度量方法(如欧氏距离、余弦相似度等)来计算文本向量之间的相似度或距离,从而实现对文本之间关系的量化分析。
6. 适用于深度学习模型
深度学习模型通常需要大量的输入数据,并且要求输入数据具有固定的维度。
通过向量化,我们可以将文本数据转换为固定维度的向量表示,使其适用于深度学习模型的处理。这有助于我们构建更加复杂和强大的NLP模型。
7. 跨语言处理
向量化方法不仅适用于单种语言,还可以扩展到多语言环境中。
通过训练跨语言的词向量模型,我们可以实现跨语言的文本表示和语义对齐,从而支持多语言的NLP任务。
综上所述,向量化在自然语言处理中扮演着至关重要的角色。它使得计算机能够处理和理解文本数据,捕获文本中的深层语义信息,提高NLP模型的性能,并支持跨语言的文本处理。
三、如何存储向量
向量数据库是专门用来存储和查询向量的数据库,其存储的向量主要来自于对文本、语音、图像、视频等的向量化。向量数据库在处理非结构化数据(如图像和音频)方面相比传统数据库具有显著优势。
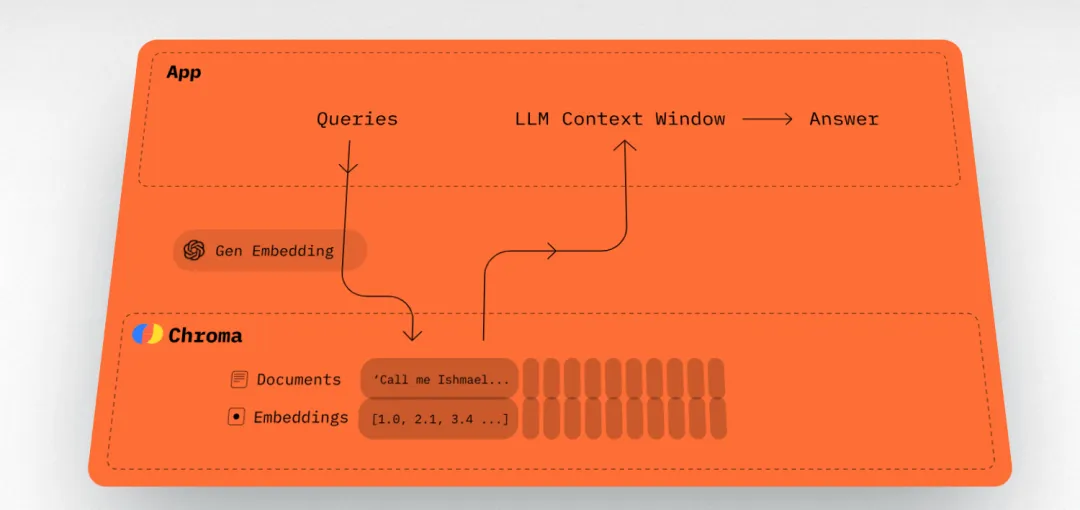
四、向量数据库的作用
提高查询效率:向量数据库采用高效的向量索引技术,可以实现快速的向量相似性查询,从而大大降低查询时间。
优化存储空间:大部分向量数据库采用数据压缩和编码技术,减少存储空间需求,同时降低数据传输和加载时间。
支持高维数据:向量数据库能够支持百万维甚至千万维以上的数据,满足高维数据分析的需求。
提高准确性:向量数据库提供高精度的相似度度量技术,相比传统数据库能更准确地进行数据匹配和检索。
自动化数据挖掘分析:向量数据库可以自动检测和分析数据中的相关特征,通过聚类、分类、推荐等方法自动生成或预测数据结果。
五、向量数据库的常用操作
建立索引:在向量数据库中建立索引是进行检索的关键步骤。根据数据的特点,选择合适的算法和参数进行索引建立。
查询处理:向量数据库通过VSM(Vector Space Model)对查询进行快速匹配,能够迅速返回匹配的文档。根据查询语句的特点,选择合适的查询策略进行处理。
结果评估:对于检索结果,可以根据实际情况进行评估和优化,如调整查询策略、优化索引结构等。
向量数据库作为一种高效的检索工具,在图像检索、文本挖掘、推荐系统等领域具有广泛的应用前景。通过利用高效的索引技术和算法,向量数据库能够实现对大规模非结构化数据的快速存储和查询,为企业和个人提供更加智能和高效的数据处理和分析方法。
六、常见向量数据产品
这里先简单罗列下常见的产品,后面会出一个专题来详细介绍每个产品
开源产品
Milvus: https://milvus.io/
Faiss: https://github.com/facebookresearch/faiss
Chroma: https://www.trychroma.com/
Weaviate: https://github.com/weaviate/weaviate
Qdrant: https://github.com/qdrant/qdrant
MongoDB: https://www.mongodb.com/
Elasticsearch: https://www.elastic.co/elasticsearch/
Pgvector: https://github.com/pgvector/pgvector
OpenSearch: https://opensearch.org/
ClickHouse: https://clickhouse.com/
Apache Cassandra: https://cassandra.apache.org/
上面最后六个是传统文档数据库,支持向量和文本的双重搜索,现在向量数据库也是一个火热的赛道
非开源产品
Pinecone: https://www.pinecone.io/
七、扩展阅读
什么是独热编码
独热编码(One-Hot Encoding),也被称为一位有效编码或“One-of-K”编码,是一种用于表示离散变量(Categorical Data)的编码方法。在机器学习和深度学习中,它经常被用来将离散变量转换为多维向量,以便于算法处理。
以下是关于独热编码的详细解释:
定义:
独热编码是一种将类别变量转换为机器学习算法易于利用的形式的过程。
在这种编码中,每个可能的取值都对应于高维空间的一个点,在这些点上取值为1,其余均为0。
原理:
Benz 编码为 [1, 0, 0]
BMW 编码为 [0, 1, 0]
Audi 编码为 [0, 0, 1]
假设我们有一组汽车品牌数据,包含三种品牌:Benz、BMW、Audi。
使用独热编码对这组数据进行编码后,可以得到以下结果:
可以看出,原本三种汽车品牌的离散数据被编码为了一组由3个元素组成的向量,每个元素的取值要么是0,要么是1。
特点:
独热编码将类别变量转换为二进制向量。
在向量的每个位置,只有一个元素为1,其余元素为0。
编码后的向量维度与类别变量的取值数量相同。
示例:
数字6的独热编码可能是 [0, 0, 0, 0, 0, 0, 1, 0, 0, 0](假设从左到右的顺序)。
在数字手写体识别中,如识别数字0到9,每个数字都可以被独热编码。
应用:
独热编码在机器学习和数据科学中非常常见,尤其是在处理分类数据时。
它使得算法能够更容易地处理和理解类别数据。
注意:
当类别变量取值数量很大时,独热编码会导致数据维度急剧增加,可能引发维度灾难(Curse of Dimensionality)问题。
在某些情况下,可能需要考虑其他编码方法,如标签编码(Label Encoding)或特征哈希(Feature Hashing)。
通过上述解释,我们可以看到独热编码是一种简单而有效的方法,用于将类别变量转换为机器学习算法易于利用的形式。
个人观点,仅供参考
原创 WedO实验君 人工智能微客