Yy DeepSeek-R1?别信新闻
它真的是那个打败 OpenAI 的开源黑马模型,还是又一条假新闻?
Fabio Matricardi
它真的那么厉害……是在哪方面?
前言:DeepSeek在大模型小型以及优化的道路上探索蒸馏和纯强化学习的路径获得的一点成绩确实让美国人紧张了一把,但同时也招致了更严格的封锁!中华老祖宗的祖训在大部分时候或许都是有意义的:厚积薄发,韬光养晦。今天的文章则是来自国外的一名AI作者对DeepSeek的相对客观的评估结论报告。
“我不相信他们说的,你也不该相信。为了保持一致,你甚至不该相信我的话!”
但我会用事实和证据来证明我的观点。
已经有人开始指出这些模型的训练数据中隐藏的偏见和宣传:另一些人则在测试它们,验证它们的实际能力。
对我来说,我又一次得到了对自己预测的确认:中国要赢下 AI 竞赛了!
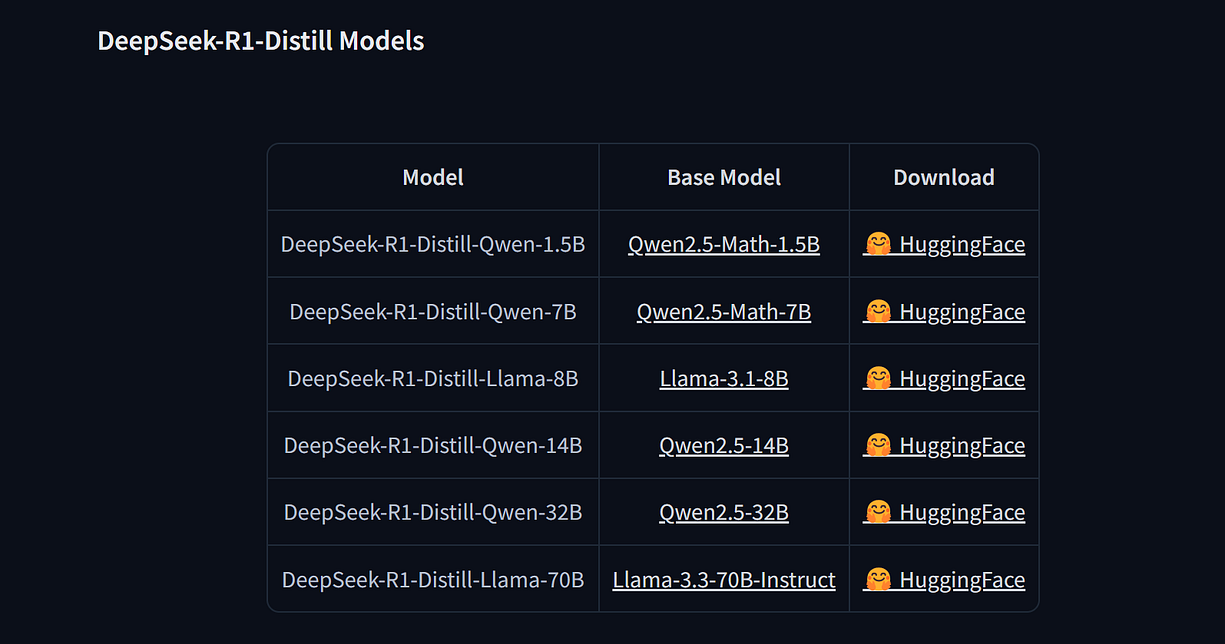
这篇文章讲的是全新的推理家族——DeepSeek-R1-Zero 和 DeepSeek-R1,特别是 DeepSeek 从这些大块头中蒸馏出来的模型。而我们要评测的是这个家族里最小的那个。
DeepSeek-R1 是开源的,正在挑战 OpenAI 的 Model o1
当 DeepSeek-AI 实验室发布他们的第一代推理模型——DeepSeek-R1-Zero 和 DeepSeek-R1 时,生成式 AI 社区炸开了锅。有人狂吹,也有人狠批,甚至可以写一本书了。
顺便说一句,这一节的标题直接来自 DeepSeek 的官方网页。对我来说,这仍然只是一个“说法”而已。

DeepSeek-R1 是 Mixture of Experts(MoE)模型,采用反思(Reflection)范式训练,基于 DeepSeek-V3
这个模型很庞大,总共有 6710 亿 个参数,但在推理时只有 370 亿 处于激活状态。
根据他们的发布说明,这个模型的 32B 和 70B 版本 可以与 OpenAI-o1-mini 相媲美。而在我看来,中国 AI 实验室真正的成就是:他们用更弱的基础模型(Qwen-2.5、Llama-3.1 和 Llama-3.3)在 R1 蒸馏数据 上进行训练,从而造出了另外六个模型。
如果你不太理解“蒸馏”是什么意思,简单来说,蒸馏就是让一个更大、更强的模型用“合成数据”来“教”一个更小的模型。
但你试过它们吗?
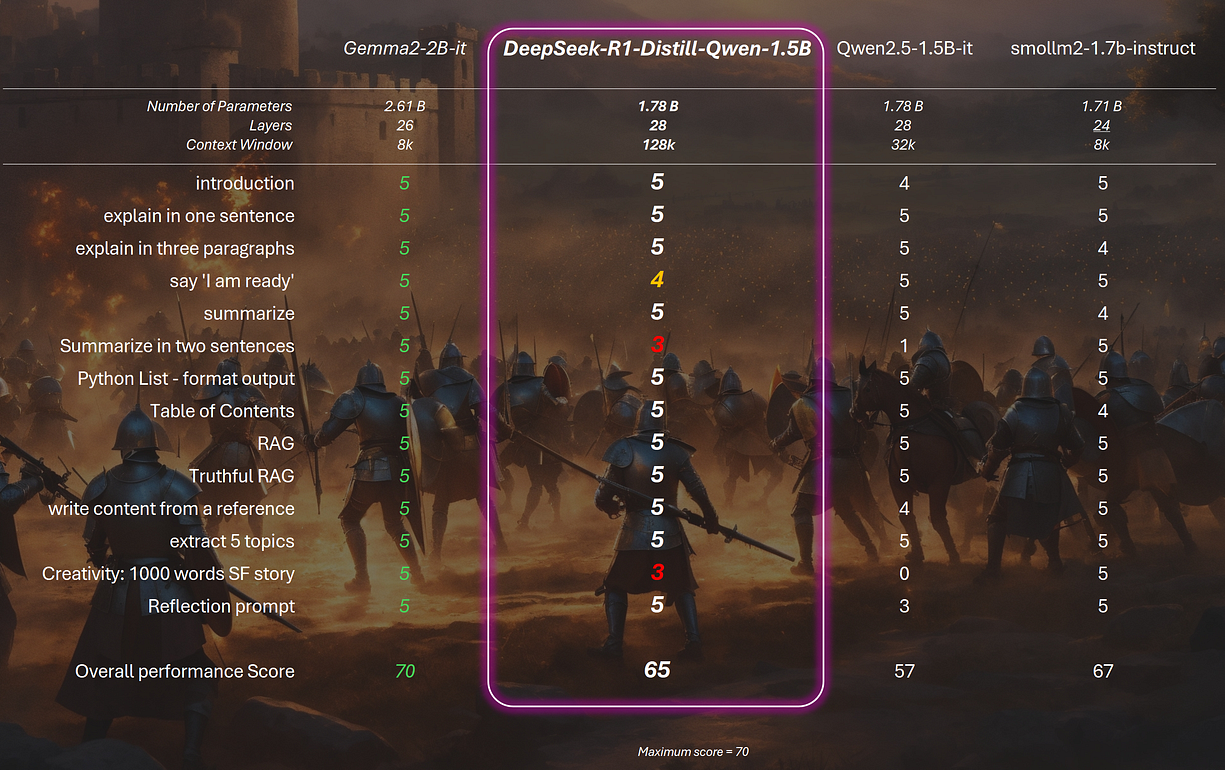
我自己测试过,以下是我的评测结果。所有日志和运行代码都在我的 GitHub 仓库里,你可以自己跑一遍:
https://github.com/fabiomatricardi/YouAreTheBenchmark/tree/main/DeepSeek R1 Distill Qwen 1.5B?source=post_page-----4874c4542797--------------------------------
以下是我个人基准测试的结果:

基于反馈修订后的基准测试结
推理模型的诞生
推理模型的核心是反思提示(Reflection Prompt),这个概念自 Reflection 70B 发布以来成为焦点。https://x.com/mattshumer_/status/1831767014341538166
它的训练方法是 Reflection-Tuning,这是一种让 LLM(大语言模型)自己修正错误的技术。
这种方法最近在研究论文和提示工程技术中成为趋势——我们基本上是在强迫 LLM“思考”。更具体地说,生成式 AI 现在太快了!
由于下一个 token 生成的计算约束,模型能进行的计算量取决于它之前看到的 token 数量。
有一篇很有趣的论文《Think before you speak: Training Language Models With Pause Tokens》(在发言前思考:用暂停 token 训练语言模型)提出了一种方法——在预训练和推理时加入
https://arxiv.org/abs/2310.02226?source=post_page-----4874c4542797--------------------------------
暂停训练的实证评估(Pause-Training)
我们对 仅解码(decoder-only) 模型(参数规模分别为 1B 和 130M)进行了 暂停训练(pause-training) 的实证评估,并在 C4 语料库 进行因果预训练(causal pretraining)。然后,我们在多个下游任务上进行了测试,包括 推理(reasoning)、问答(QA)、一般理解(general understanding)和事实召回(fact recall)。
我们的主要发现是:
如果模型在预训练和微调(fine-tuning)阶段都加入了推理时延迟(inference-time delays),它的性能会得到提升。
在 1B 规模的模型上,我们发现其在 9 项任务中的 8 项上都取得了提升,其中最显著的改进如下:
• 在 SQuAD QA 任务 上,EM(Exact Match)分数提升 18%。
• 在 CommonSenseQA 任务 上,准确率提升 8%。
• 在 GSM8k(数学推理任务) 上,准确率提升 1%。
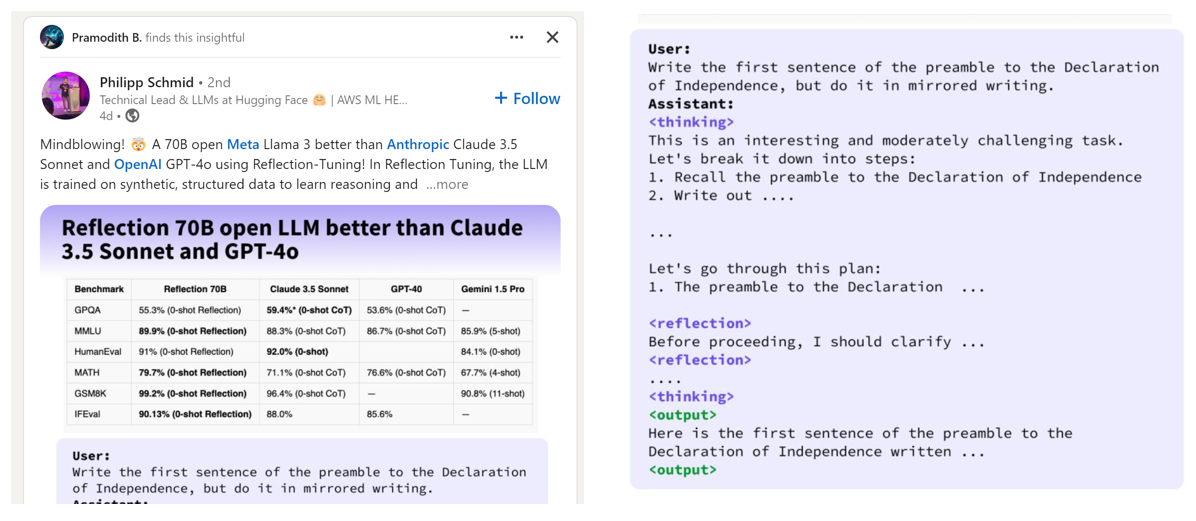
Reflection 70B 的起源
Reflection 70B 的承诺 最早可以追溯到 2024 年 9 月,当时 Matt Shumer 在 Twitter 上宣布他的 SOTA(State-of-the-Art,最先进) 模型,具备 反思步骤推理(Reflection Steps Reasoning) 能力。
根据作者的说法,Reflection 70B 的核心技术非常简单,但威力巨大。
当前的 LLM 存在的问题:幻觉与自我纠正
目前的 大语言模型(LLM) 有产生幻觉(hallucination)的倾向,但它们无法意识到自己何时产生了幻觉。
Reflection-Tuning 技术让 LLM 能够识别自己的错误,并在最终作答前进行修正。
Reflection 70B 的训练细节
这个模型可以在 Hugging Face Hub 上找到,它的训练过程如下:
-
以 Llama 3.1 70B Instruct 作为基础模型。
-
训练数据全部来自 Glaive 生成的合成数据。
显然,这一切的成功都归功于一种特殊的提示词技巧(prompt technique)。
让我们来看看具体细节——
(配图,来自 LinkedIn)
哇哦,看来在模型生成输出之前让它“思考(Think)”和“反思(Reflect)”确实能够提升推理能力,并减少错误。
DeepSeek-R1 不是“差不多”
这些模型在生成最终输出之前会先自言自语地思考,这一点和人类的思维方式更相似。
反思范式虽然开启了这个思路(但这篇论文其实是 2023 年的),DeepSeek 采用的却是另一种方法:
“我们首次尝试使用纯强化学习(RL)来提升语言模型的推理能力……目标是探索 LLM 是否能在完全没有监督数据的情况下进化自身。”—来自DeepSeek的论文
这个模型在推理阶段会动态扩展 Chain-of-Thought(CoT)推理过程。最近,后训练(Post-training)成为整个训练流程中的重要环节,被证明能提高推理任务的准确度、增强模型对社会价值的对齐性,并且适应用户偏好,而所需的计算资源比预训练少得多。
但是说实话:它真的很烦人!

这模型太啰嗦了!
或许在技术上,展示 LLM 逐步推导的过程是有用的(就像软件测试中的 DEBUG 过程),但连最简单的互动都会吐一大堆没用的话。
看看这段对话:
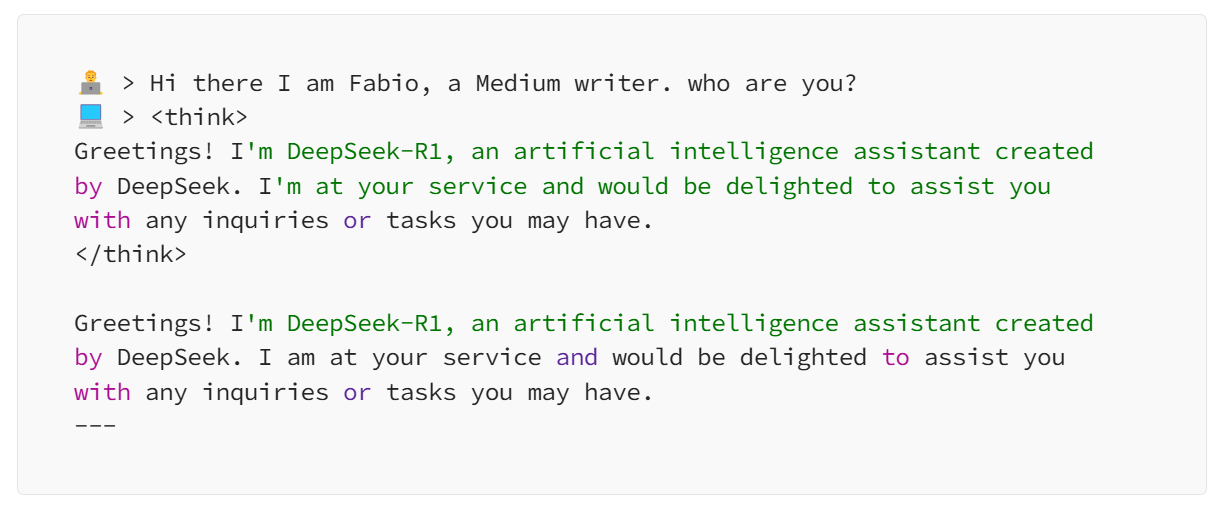
啊这……能不能别自言自语了?!
但它在 RAG 和事实性任务上表现不错
由于 DeepSeek-R1 的推理过程会显式展示模型如何得出答案,它在 RAG(检索增强生成) 任务上表现得相当出色。
来看另一个例子:

它会在

偏见是个“神话”
我要直说了。
所有语言模型,无论是 DeepSeek 还是 OpenAI,都不可能完全无偏见。
甚至 OpenAI 的模型都是“美国化”的!
我不是美国人,所以我很清楚这一点。
想要一个完全没有偏见的“上帝模型”?算了吧,那是彻底的乌托邦幻想。
比起迎合所谓“包容性”,我更愿意看到一个坦诚但有时我不喜欢的答案,而不是那种模棱两可、毫无信息量的回答。
你呢?
自己试试吧!
我创建了一个 GitHub 仓库,帮助你在自己的电脑上运行 DeepSeek-R1。
即使是低配设备(甚至手机)也能跑!
https://github.com/fabiomatricardi/Deepseek-R1-qwen1.5B
结论
DeepSeek-R1 确实很厉害,尤其在推理和 RAG 任务上。
不过,它的啰嗦模式可能不适合自动化任务。
但反思范式绝对是朝着 AGI 迈出的重要一步。
未来 Transformer 架构会怎么演化?拭目以待!