最近,DeepSeek大火,想必大家都有所耳闻,各路媒体从各个方面报道了DeepSeek这家神秘的公司的各方面消息,这家低调的技术公司用一组硬核数据回应了所有关注:
千亿参数规模下实现0.5元/百万tokens的API调用成本,91.5%的中文基准测试得分,推理效率较传统架构提升5倍。
DeepSeek的AI大模型作为国产之光,不仅刷新了国产大模型的天花板,更标志着普惠AI时代的实质性突破。
我们看新闻的同时,不应该只停留在听说的层面上,应该深入体验并实践于各种应用场景:有人用它来帮自己写文章,有人用它来帮自己思考做决策,甚至有人用它来suanming,真是脑洞大开,破局圈友应该是行动最快的那群人。
本文将带领大家本地部署 DeepSeek+Dify,零成本搭建自己的私有知识库。
学会本文搭建方法后,我们也可以把自己的个人资料,过往输出文章,日记等所有个人信息上传到本地知识库,打造自己的私人助理。
当然,还可以有很多其他应用场景,比如:智能客服,智能题库。
本文,将按照以下主线展开:
• 安装Docker
• 安装Ollama
• 安装Dify
• 创建应用
• 创建知识库

一、下载并安装docker
网址:
https://www.docker.com/
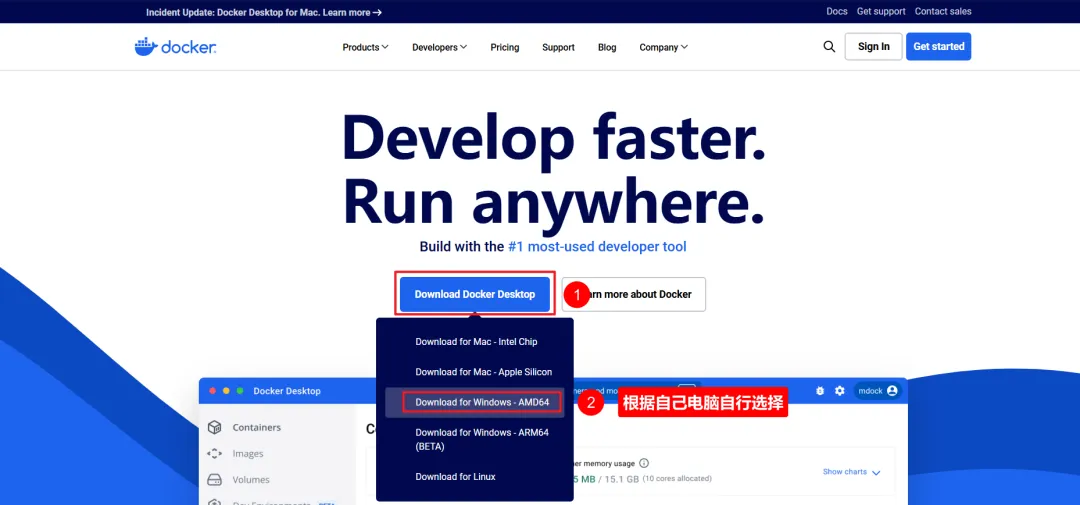
一路点击下一步安装即可,因为docker会用到hyper-v,如果电脑没开启hyper-v,可能会需要重启一次。
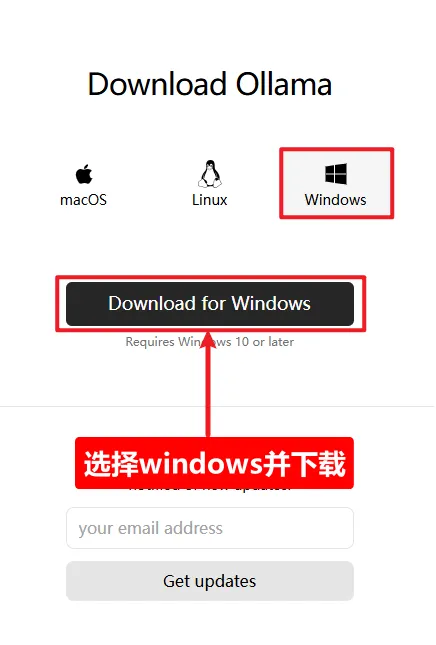
二、下载ollama
Ollama 是一个开源的本地化工具,旨在简化大型语言模型(LLMs)的本地运行和部署。它专注于让用户能够轻松在个人计算机或服务器上运行多种开源语言大模型(如deepseek ,qwen,Llama、Mistral、Gemma等),而无需依赖云端服务或复杂的配置流程。
网址:
https://ollama.com/
安装完成后,桌面右下角会显示ollama图标

三、安装deepseek-r1模型
3.1 找到模型
在ollama官网首页的搜索框,点击一下即可看到deepseek-r1在第一个位置,可见热度之高啊!
可以看到模型有根据参数分为1.5b,7b,8b,14b,32b,70b,671b等,我们需要根据自己电脑选择下载对应参数的模型。
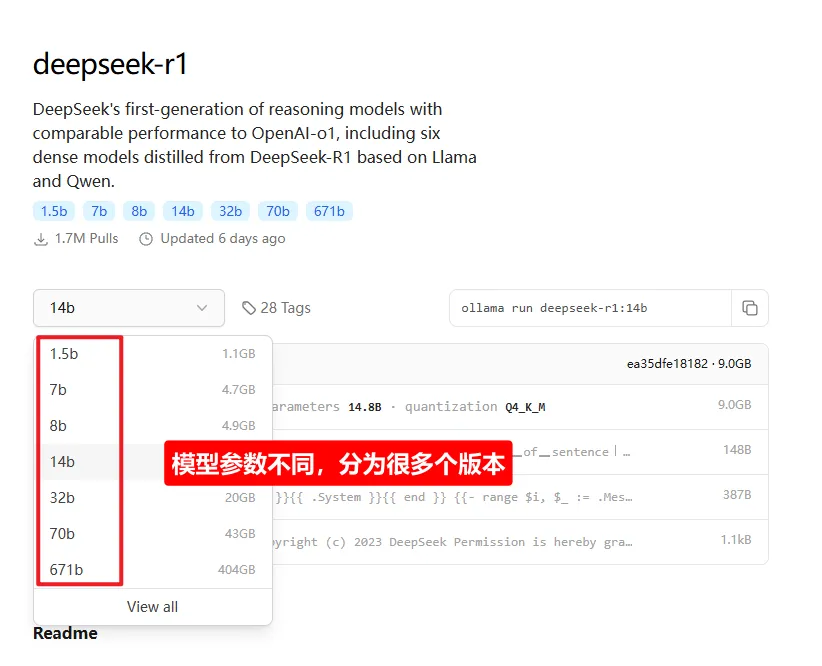
3.2 如何选择适合自己电脑的模型?
我的电脑配置如下:

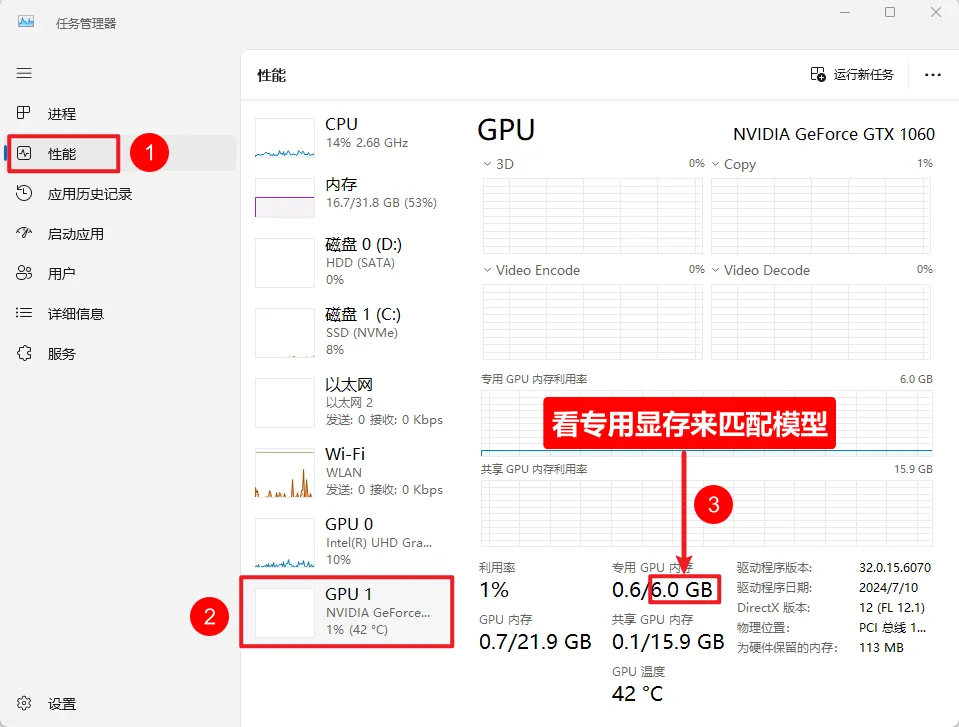
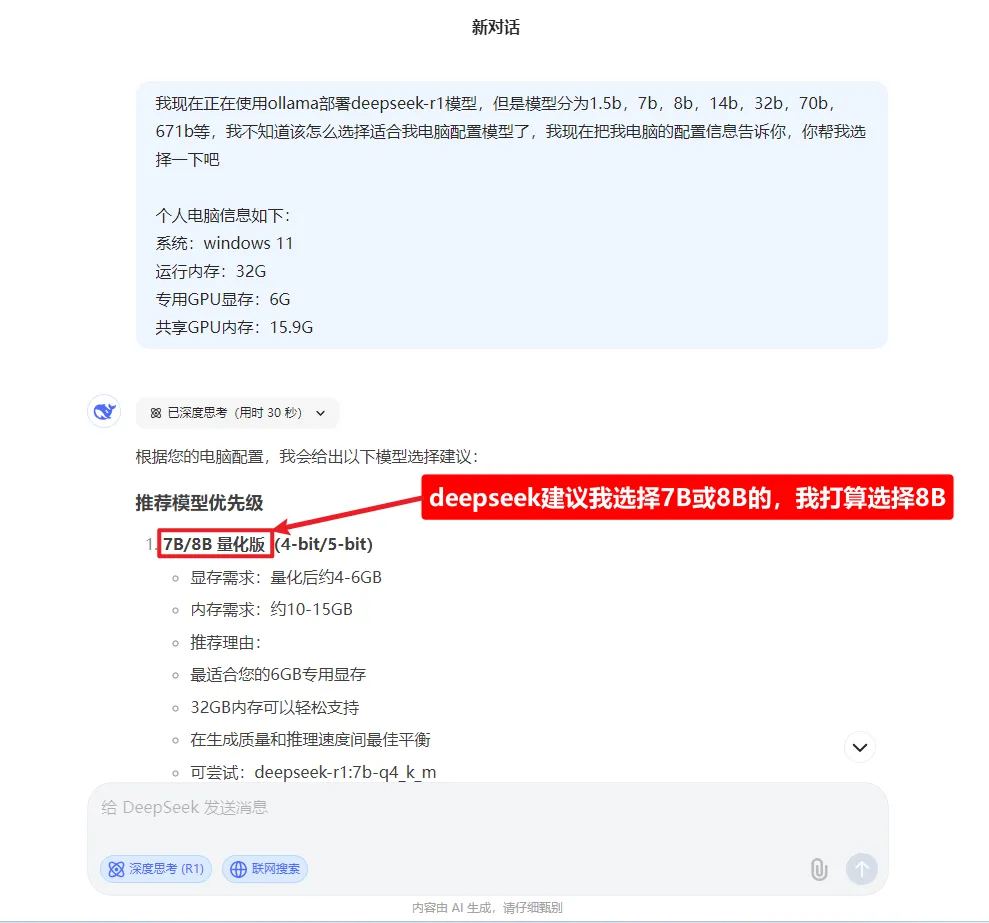
问一下deepseek,让他帮我们选择,提示词如下:
我现在正在使用ollama部署deepseek-r1模型,但是模型分为1.5b,7b,8b,14b,32b,70b,671b等,我不知道该怎么选择适合我电脑配置模型了,我现在把我电脑的配置信息告诉你,你帮我选择一下吧个人电脑信息如下:
系统:windows 11
运行内存:32G
专用GPU显存:6G
共享GPU内存:15.9G
3.3 安装r1模型
ollama run deepseek-r1:8b
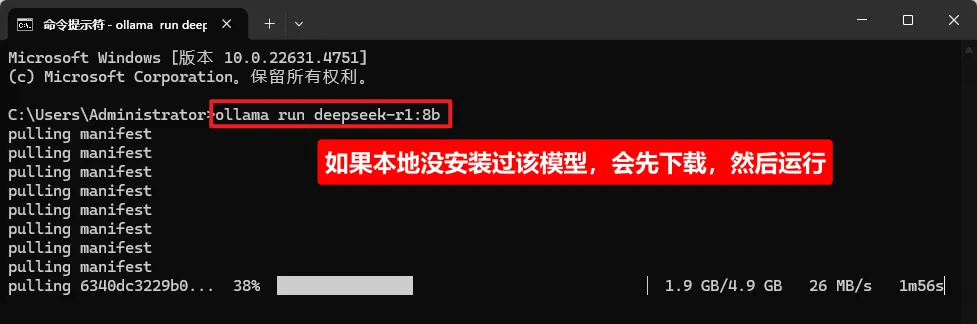
ollama安装完后,没有图形界面,安装大模型,可以类比为docker拉取镜像,因为很多操作命令类似
3.4 测试
安装完成后,会自动运行大模型,我们输入一个问题测试一下:

四、安装dify
dify官网地址:
http://difyai.com/
dify官网文档:
https://docs.dify.ai/zh-hans
dify项目github地址:
https://github.com/langgenius/dify
4.1 先了解一下dify
这里简单介绍一下dify,需要详细了解的可以看dify的官网或官方文档。
Dify.AI 是一个开源的大模型应用开发平台,旨在帮助开发者轻松构建和运营生成式 AI 原生应用。该平台提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等全方位的能力,使开发者能够专注于创造应用的核心价值,而无需在技术细节上耗费过多精力。
从创建应用页面可以看到,他可以创建:聊天助手,Agent,文生文应用,对话工作流,任务编排工作流等

支持接入的大模型供应商几乎涵盖了全球所有知名大模型供应商
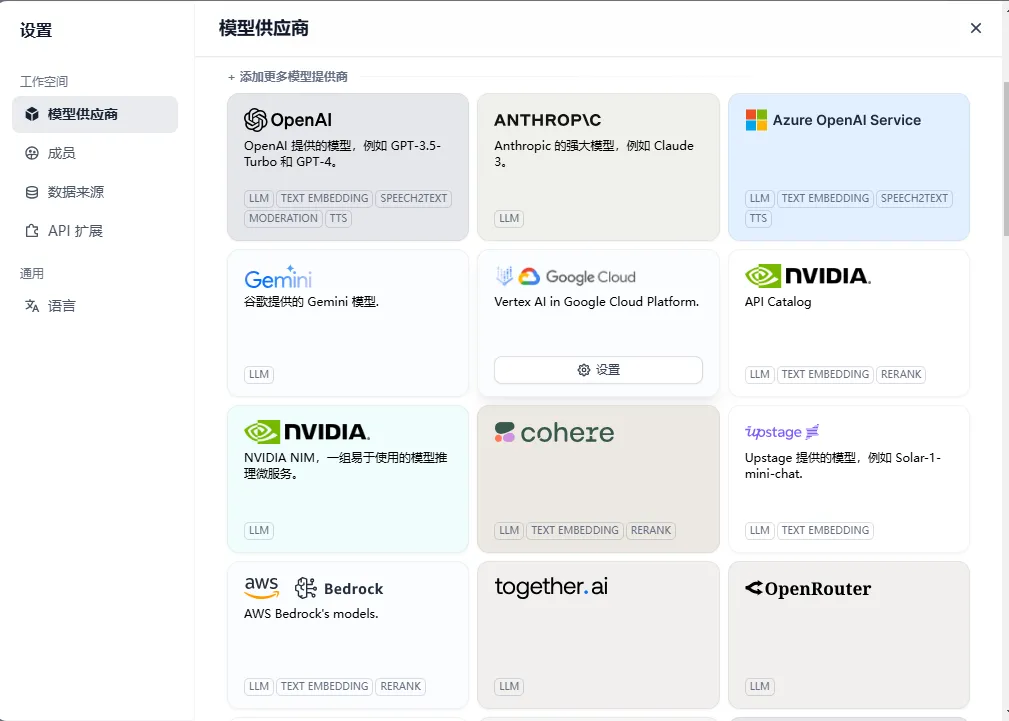
当然也包括国内的deepseek,ollama

他也支持从已有文本,Notion,网页等数据源创建知识库:
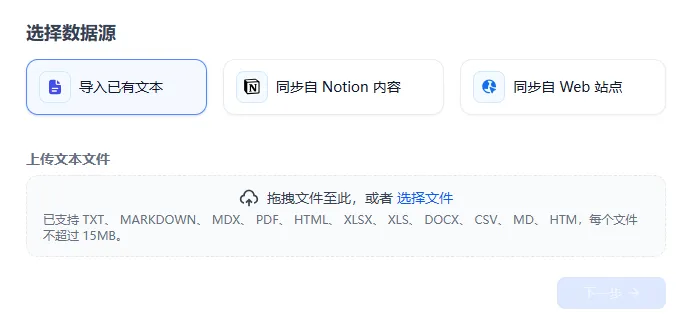
这就意味着,我们可以通过部署本地大模型,企业知识库,来部署企业私有化AI应用,比如:企业垂直领域的销售客服,HR用来培训企业招聘来的新员工,教育机构可以部署私有题库。并通过api的形式灵活构建自己的应用。
4.2 下载dify项目压缩包

4.3 安装dify环境
1、进入项目根目录找到docker文件夹
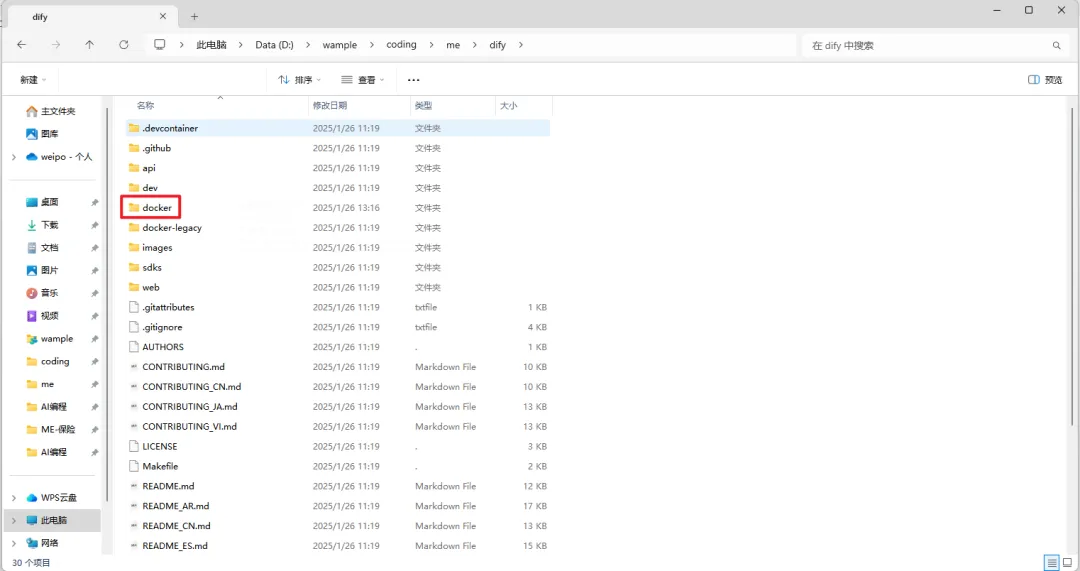
2、.env文件重命名
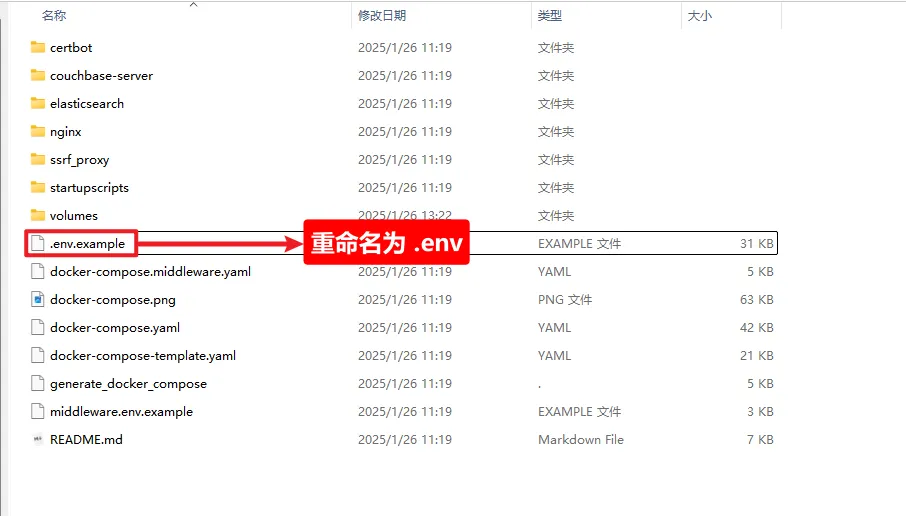
3、右键打开命令行
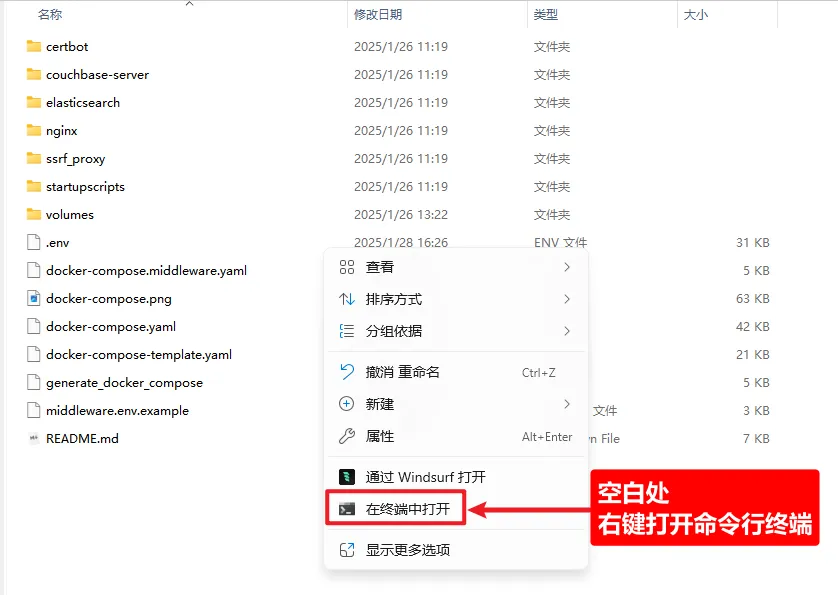
4、运行docker环境
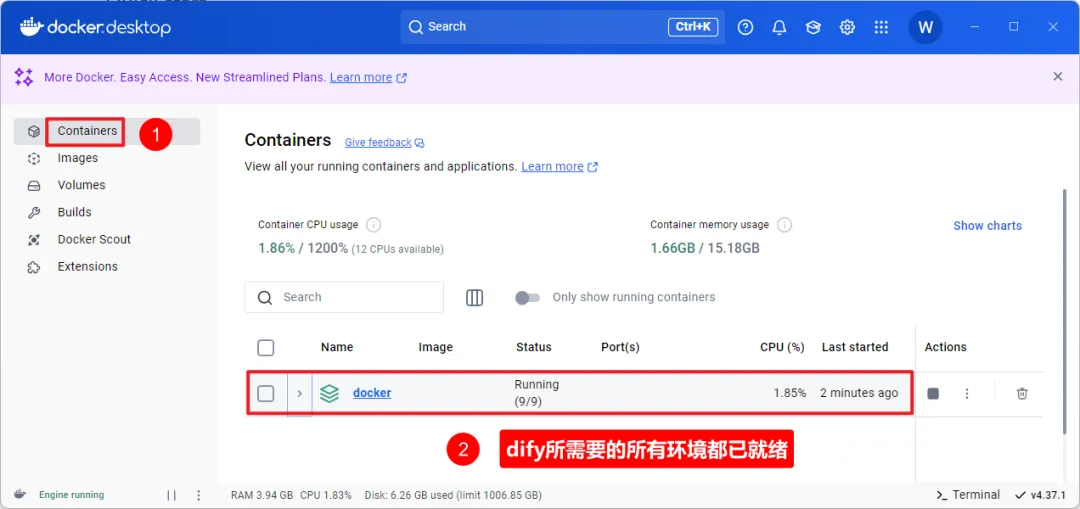
docker compose up -d

此时回到docker桌面客户端可看到,所有dify所需要的环境都已经运行起来了
4.4 安装dify
在浏览器地址栏输入即可安装:
http://127.0.0.1/install
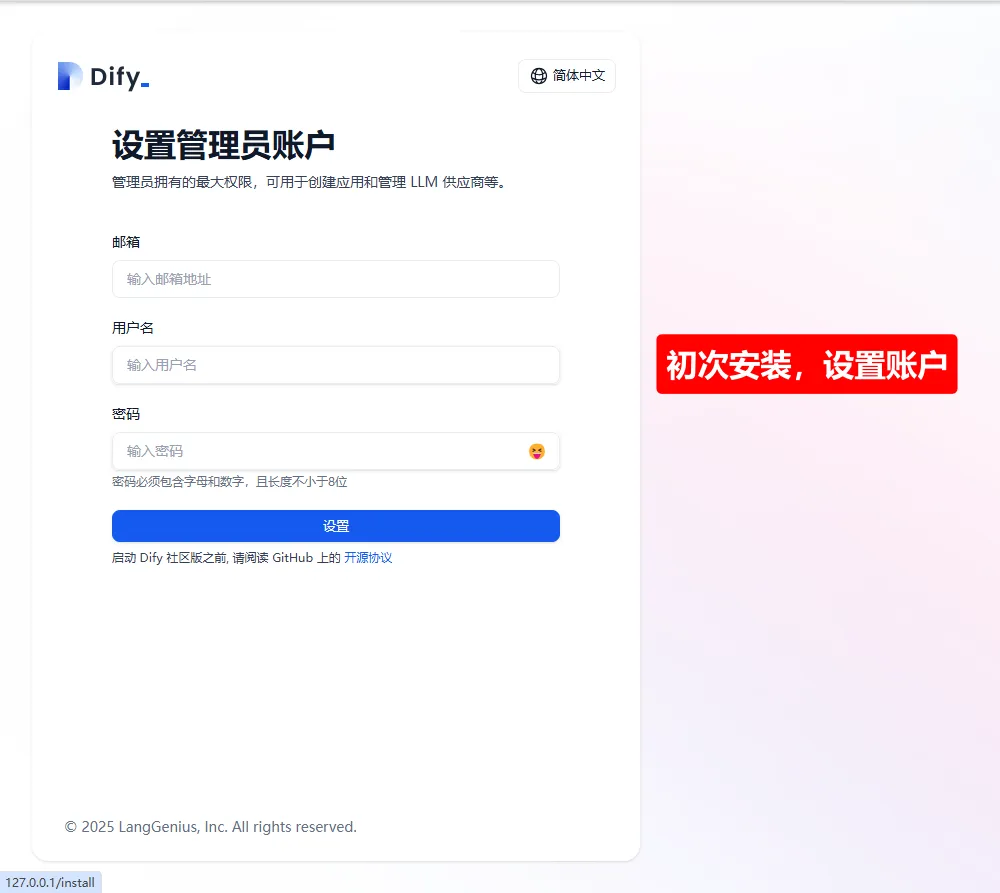
然后登录账号
进入dify主页如下:
五、如何将本地大模型与dify关联起来?
由于本教程的dify是通过docker部署的,也就是说,项目是运行在docker容器内部的,但是我们的ollama是运行在本地电脑的,但是他们是在同一台电脑上的,这就意味着,要想dify能够访问ollama提供的服务,需要获取到本地电脑的内网IP即可。
5.1 获取本机内网IP
打开命令行:win+r
输入:cmd
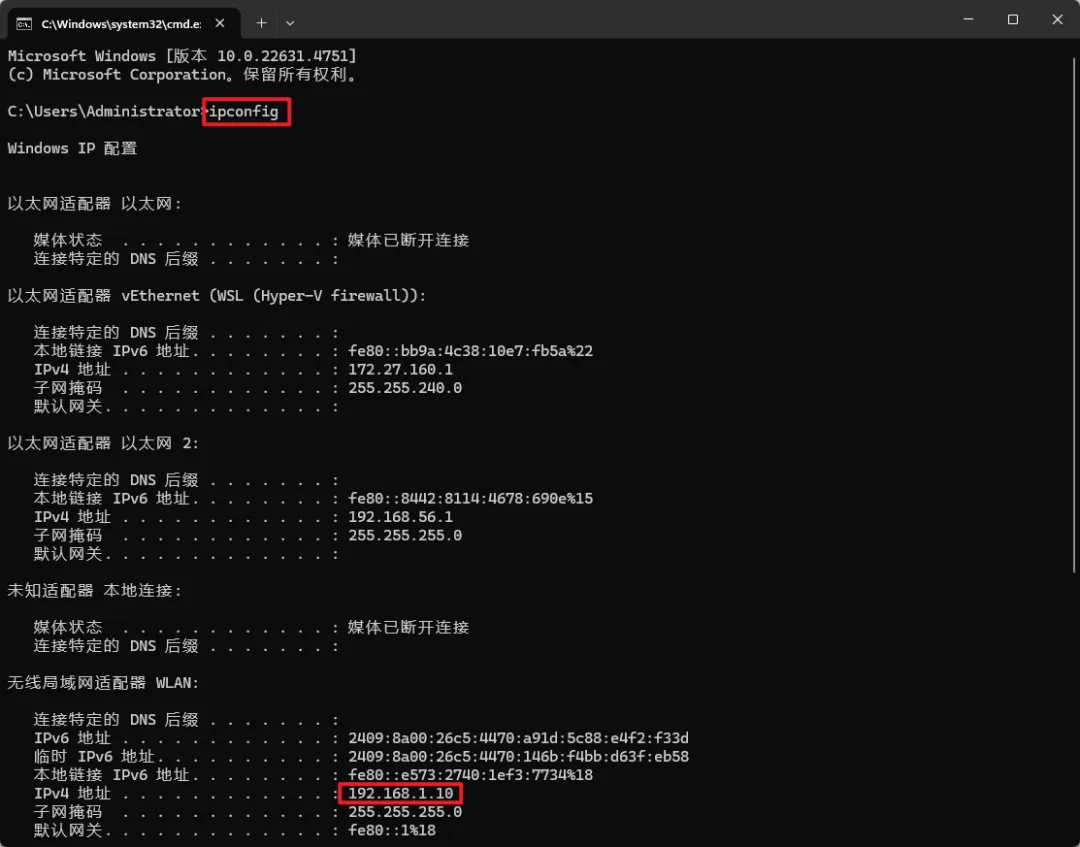
在命令行输入:ipconfig,并找到当前连接的网络适配器(如“无线局域网适配器 WLAN”或“以太网适配器”),下方显示的 IPv4 地址 即为内网IP(如 192.168.x.x 或 10.x.x.x)
5.2 配置本地内网IP到dify的docker部署配置文件内
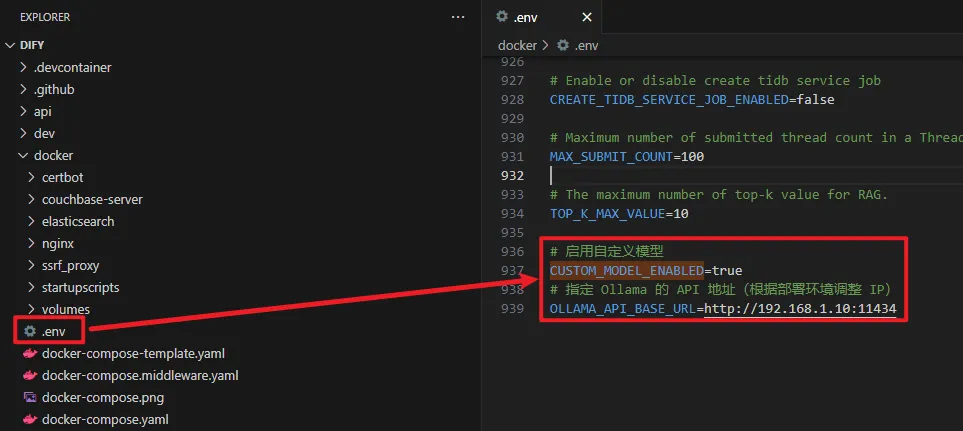
找到dify项目下的docker文件夹并进入,前面已经将.env.example改为了.env文件了,在末尾填上以下配置:
# 启用自定义模型
CUSTOM_MODEL_ENABLED=true
# 指定 Ollama 的 API 地址(根据部署环境调整 IP)
OLLAMA_API_BASE_URL=http://192.168.1.10:11434
5.3 配置大模型
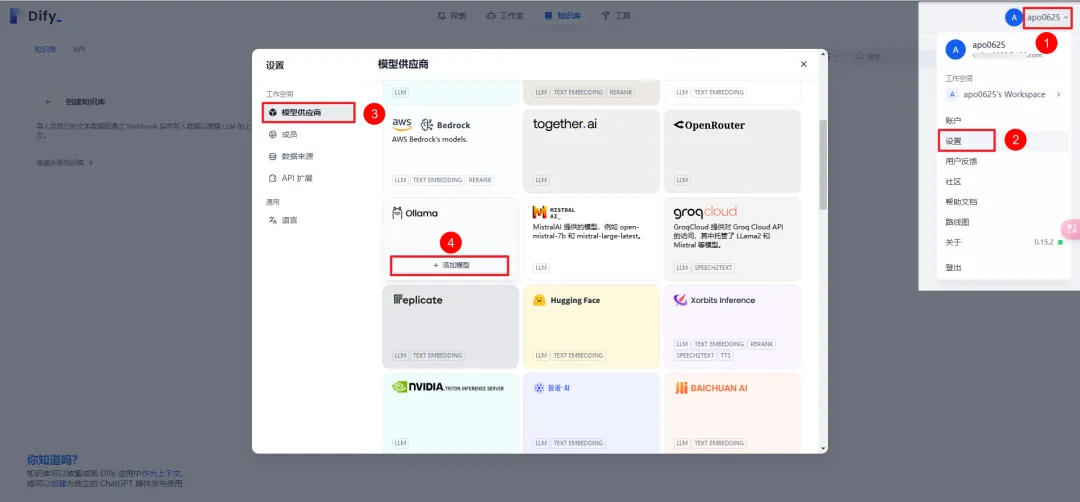

5.4 设置系统模型
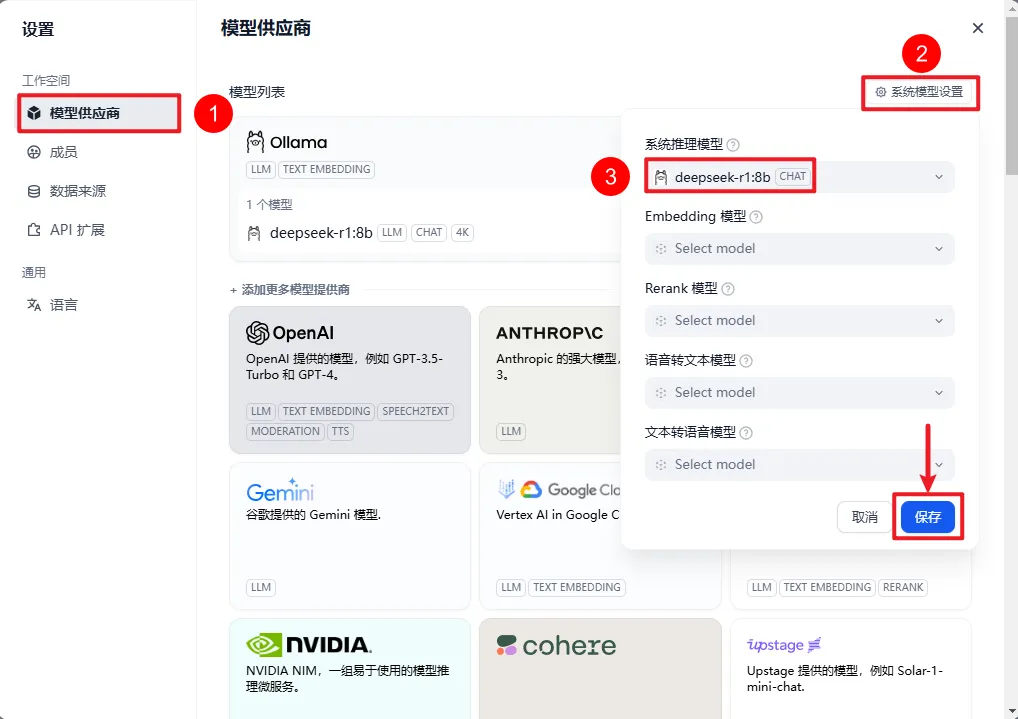
到此,dify就与前面部署的本地大模型关联起来了
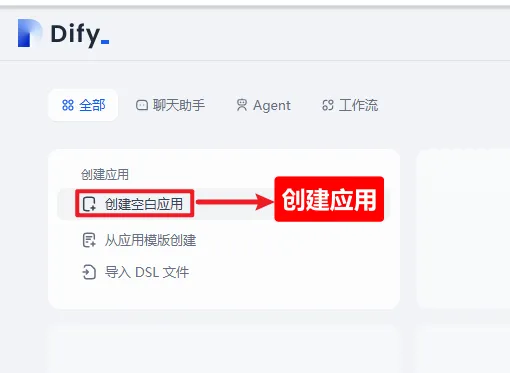
六、创建一个应用
6.1 创建空白应用
6.2 应用配置
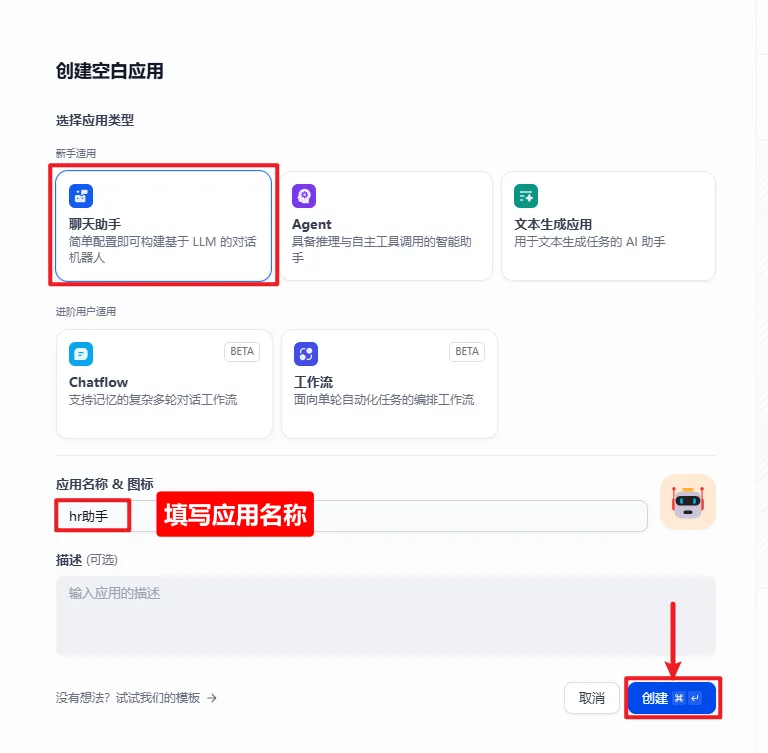
6.3 配置当前应用的大模型

6.4 测试
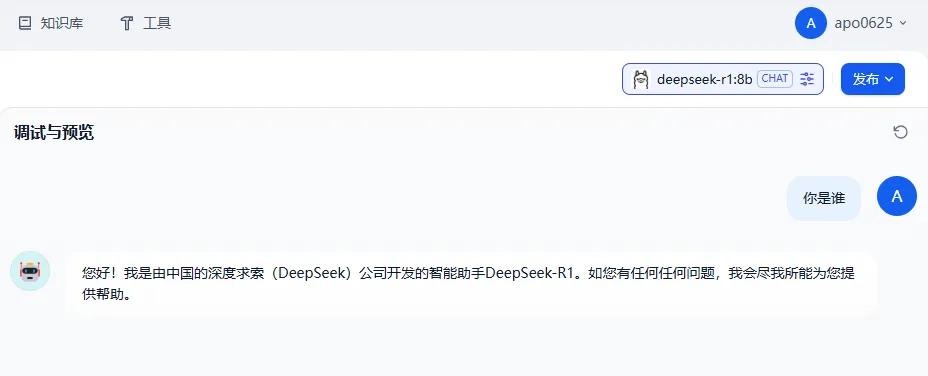
这表明,dify与本地部署的大模型deepseek-r1连通了,但是,我想让他的回答是基于我的私有知识库作为上下文来和我聊天怎么办?这就需要用到本地知识库了
七、创建本地知识库
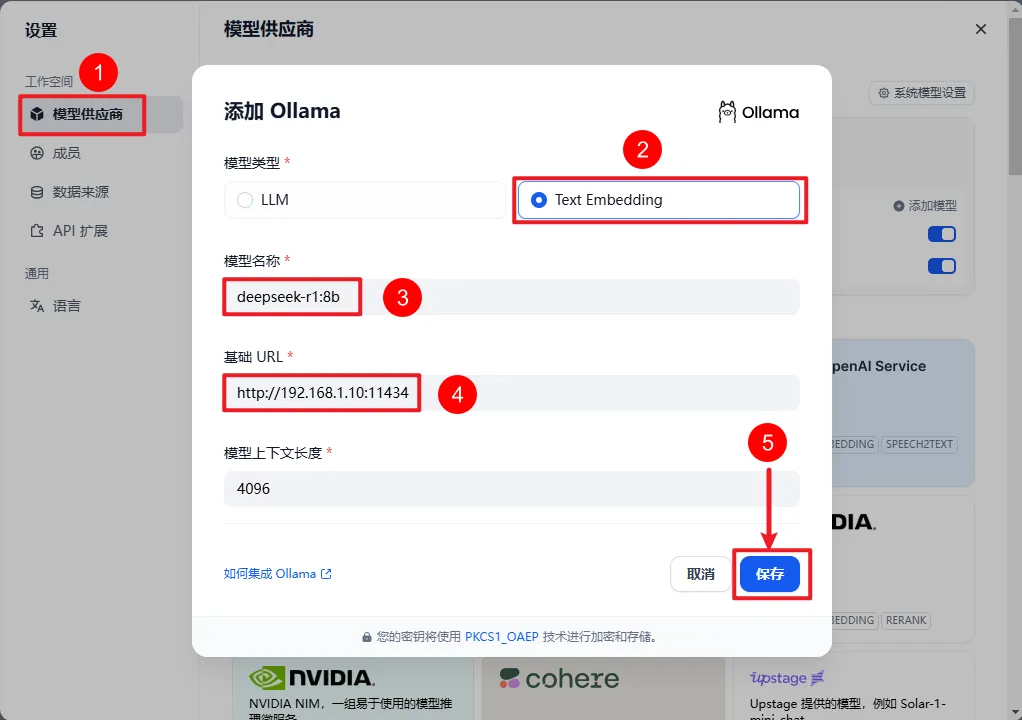
7.1 添加Embedding模型
为什么要添加Embedding模型?
Embedding模型的作用是将高维数据(如文本、图像)转换为低维向量,这些向量能够捕捉原始数据中的语义信息。常见的应用包括文本分类、相似性搜索、推荐系统等。
我们上传的资料要通过Embedding模型转换为向量数据存入向量数据库,这样回答问题时,才能根据自然语言,准确获取到原始数据的含义并召回,因此我们需要提前将私有数据向量化入库。
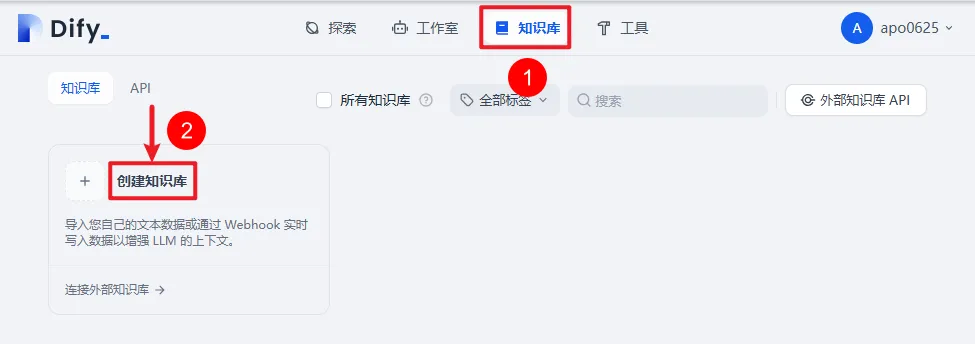
7.2 创建知识库
7.3 上传资料
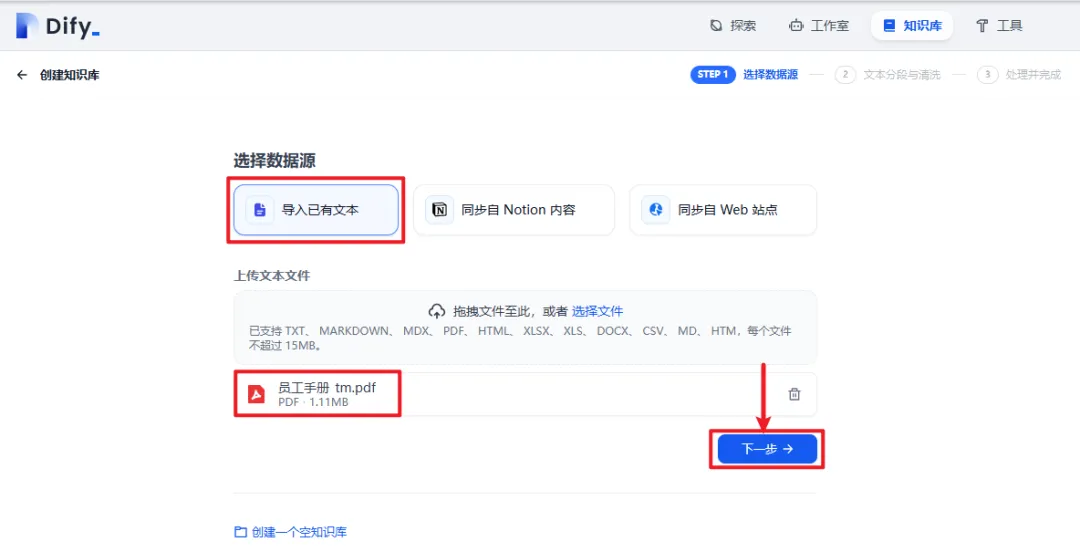
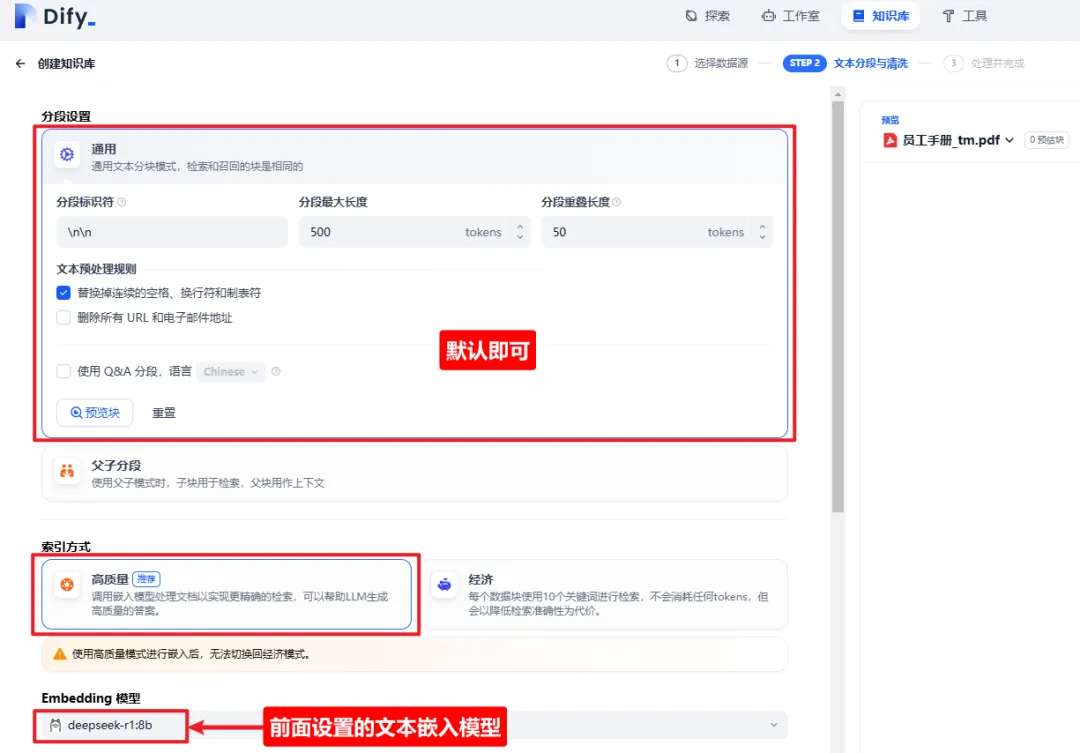
7.4 保存并处理

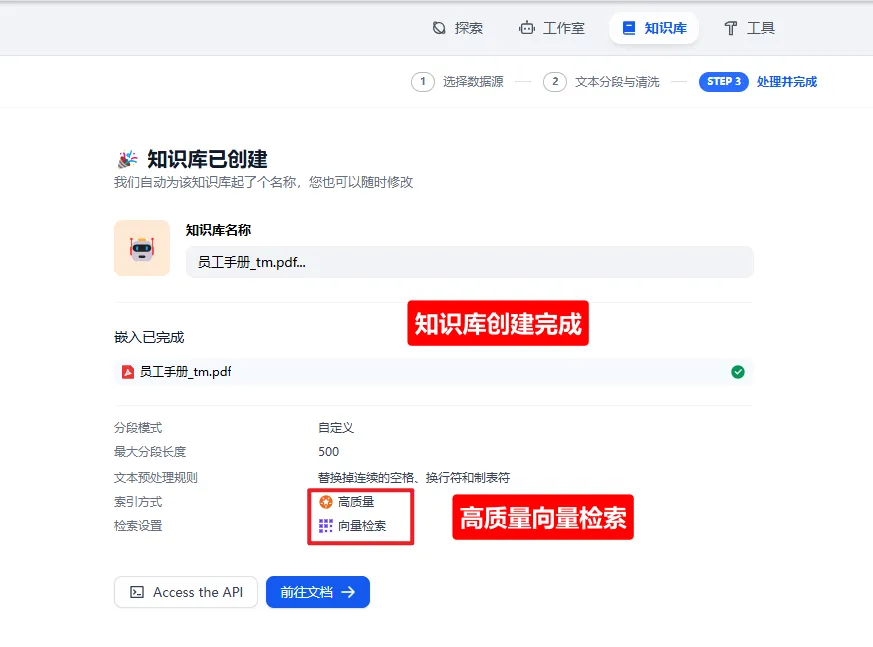
7.5 知识库创建完成
八、添加知识库为对话上下文
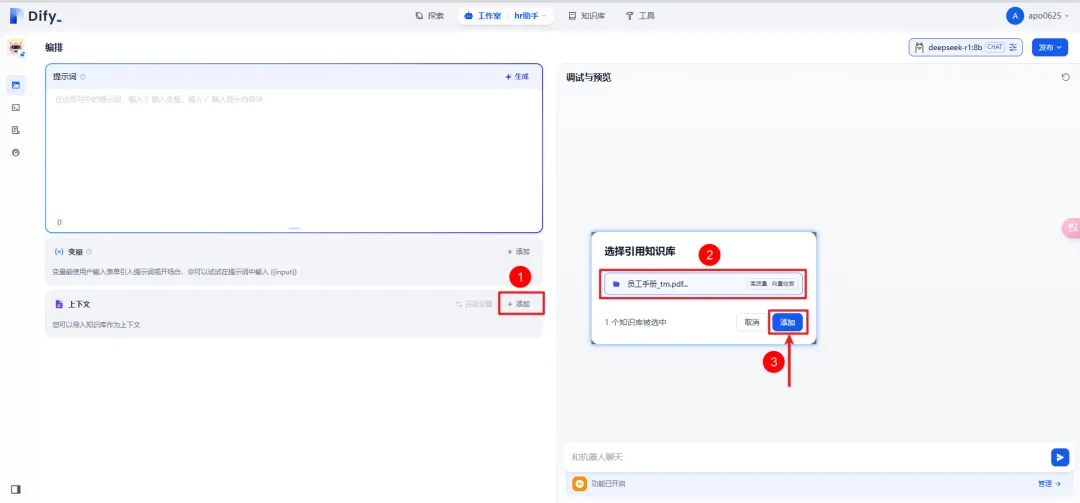
8.1 应用内添加知识库
回到刚才的应用聊天页面,添加知识库
8.2 保存当前应用设置
如果只是当前应用内调试可以不必更新,但是如果想把当前应用发布为对外api服务或者持久化保存,就需要保存当前应用设置,记得实时保存当前设置。

8.2 测试
思考过程具有浓厚的deepseek风格,就好像真的有一个很认真的人在翻看文档一样,它把自己翻看文档的过程,清晰的展示了出来,最后给出自己的结论,非常严谨。如果是个特定的学术知识库,他一定还能帮你推演,思考,总结,非常方便。
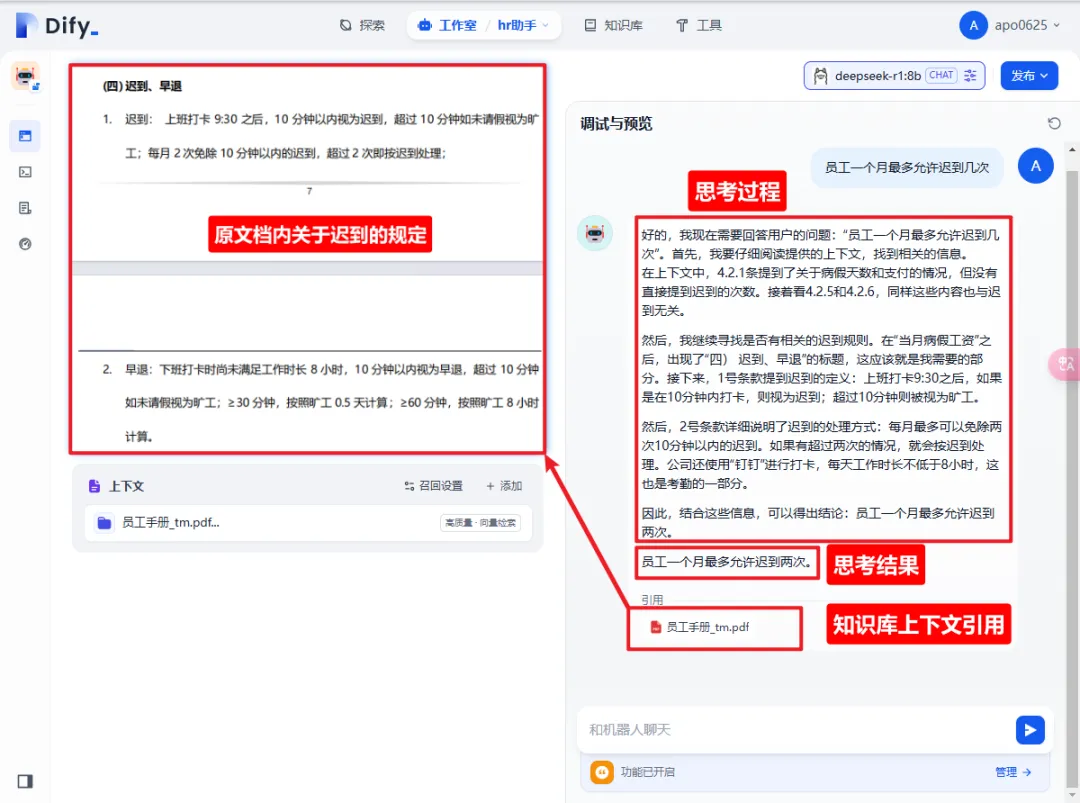
如果感觉回答的效果还不满意,可以对召回参数进行调整。
或者可以参考官方文档,做其他详细设置:
https://docs.dify.ai/zh-hans/guides/knowledge-base
九、结语
DeepSeek作为可以私有化本地部署的大模型,加上Dify这个组合,我们还可以有很多其他应用场景,比如:智能客服,智能题库。
也可以把自己的个人资料,过往输出文章,日记等所有个人信息上传到本地知识库,打造自己的私人助理。
Dify还有很多其他功能,有了deepseek这样的优秀国产AI大模型加持,我们可以做更多智能体应用。当然,Dify也可以像coze一样,发布为对外服务的api,这样,它就可以结合cursor快速做出更多的AI应用。
原创 阿坡 阿坡RPA
![[Tools] Vite intro](https://img2024.cnblogs.com/blog/364241/202502/364241-20250204013645359-792153170.png)
![[2025.2.3 MySQL学习] 分库分表](https://img2024.cnblogs.com/blog/3574171/202502/3574171-20250204014920912-767662819.png)



![0x80070035错误怎么解决?Win11/Win10访问NAS smba共享文件夹提示无法找到路径[Path not found]](https://img2024.cnblogs.com/blog/1386950/202502/1386950-20250203225908135-756671083.webp)


![E96 Tarjan缩点+树上背包 P2515 [HAOI2010] 软件安装](https://img2024.cnblogs.com/blog/1973969/202502/1973969-20250203222323609-1615497131.png)