License: CC BY-NC-SA 4.0
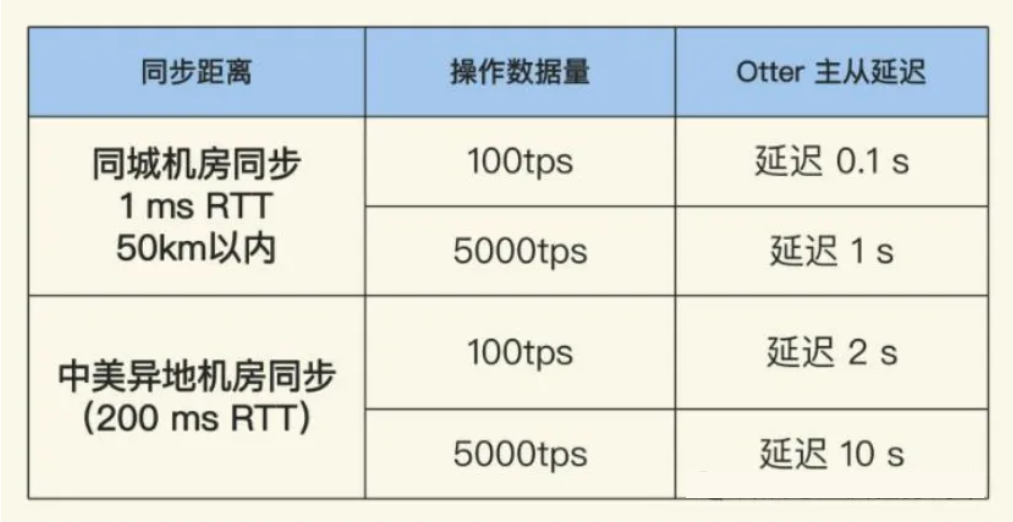
seq2seq:输出长度由模型自行决定。例如语音识别,机器翻译。
即使不是 seq2seq 的问题,也可以用 seq2seq model 大力出奇迹。例如文法剖析,将「deep learning is very powerful」拆成「(S (NP deep learning) (VP is (ADJV very helpful)))」这种形式(感觉像 lisp)。简单来说就是把语法树转成括号序列,是个序列就能上 seq2seq. seq2seq 还可以用于 multi-label classification,在这种任务里一个物品可以同时属于多个种类。由于不知道 label 的数目,因此可以看成一个不定长的 sequence,然后就是熟悉的 seq2seq 了。还有图像中的物品识别,一张图中物品个数不是定值。
一般的 seq2seq 会分为 encoder 和 decoder 两块。encoder 要做的就是输入一排向量,输出另一排向量。transformer 的 encoder 就包含了 self-attention(以及一些别的层)。encoder 使用 residual network。它由多个 block 组成,对一个 block,它把输入和经过 self-attention 层的输出相加,做 layer normalization(对一个向量考虑它的所有维度均值和方差的 normalization). 完了之后再扔给 fc 层,(normalization 后的向量)也与 fc 层的输出结果相加,然后再 layer normalization,这就是 residual network 里一个 block 干的事。
也有别的设计可以做到更优。上面是原论文的架构。
下面是 decoder. 一种常见的 decoder 是 autoregressive,以语音识别为例。它读入由 encoder 产生的向量序列和自己已经生成的 token,然后生成下一个 token。decoder 的架构与 encoder 大同小异,每个 block 从一层 self-attention 变为连续的两层 masked self-attention。所谓 masked,就是一个词只能注意到它自己和之前的词,把注意力矩阵相应部分设为 \(- \infty\) 再做 softmax 即可实现。
decoder 的输入最前方要加一个特殊的 token 标记开始,输出最后要加一个 token 标记结束。这两个 token 由于不同时出现,可以直接用同一个表示开始和结束。
与 autoregressive(AT)对应的就是 non-autoregressive(NAT). NAT 输入 encoder 的输出和一堆 begin token,每个 begin token 对应输出一个 token. 但如何知道要输出多长呢?
有两种策略:
- 用一个 classifier 决定输出长度
- 输入一大堆 begin token,然后忽略 end token 之后的东西
NAT 的优势是它可以并行计算,但一般来说 NAT 的表现还是打不过 AT。
encoder 的输出不是直接给 decoder 当输入的,中间还有 cross attention. 它看起来有点像缝合怪,\(\vec q\) 来自 decoder,\(\vec k, \vec v\) 来自 encoder. 得到的结果会丢给 fc 层。但是 encoder 和 decoder 都有很多层,拿哪些层呢?原始的论文里是拿 encoder 的最后一层给 decoder 的每一层,但其他的方式也可以尝试。
下面是训练的过程,以语音识别为例。先将数据进行人工标注(先考虑有标准答案的情况),decoder 输出每个字其实都是一个 distribution,所以可以上 cross entropy. 它和分类很像。但是 decoder 的输入来自自己之前输出的 token,所以为了避免一步错步步错,会采取 teacher forcing(把它之间输出的 token 换成标准答案并让它输出下一个 token)的方法。这个名字有种莫名其妙的感觉。
训练的一些 tips:
-
有的时候机器不用自己创造,直接从输入里照抄就行。例如看到「我是某某」,回答「你好,某某」,就可以直接抄对方输入的名字。文章摘要的方法是类似的。详细介绍在 这个链接.
-
guided attention:避免机器漏掉输入序列的某些信息。详细了解可以搜索:monotonic attention, location-aware attention
-
每次 decoder 输出一个 token 时,输出的实际上是一个概率分布。每次选概率最大的那个作为一种贪心算法,可能陷入局部最优,而 beam search 就是另一种搜索算法,用起来比较玄学。LHY 总结说标准答案越单一的任务越适合用 beam search.
-
更有创造力的任务往往要在 decoder 里加一点随机性。(不完美反而是一种完美?)
-
本课的作业评价标准是看 BLEU score,但训练时 loss 函数是 cross entropy. 当然也可以用 BLEU score 做 loss,但它不可微,于是梯度下降就失效了。
但是 LHY 给了一个方法:遇到你在 optimization 无法解决的问题,用 reinforcement learning 硬 train 一发就行了。
-
训练的时候看到的都是正确答案,但测试的时候不一定。这种现象叫 exposure bias,一种可能的解决方法是训练的时候就给 decoder 一些错误答案。这种方法叫 scheduled sampling.




![[Tools] Vite intro](https://img2024.cnblogs.com/blog/364241/202502/364241-20250204013645359-792153170.png)
![[2025.2.3 MySQL学习] 分库分表](https://img2024.cnblogs.com/blog/3574171/202502/3574171-20250204014920912-767662819.png)