1. 服务雪崩
1.1 什么是服务雪崩?
在微服务中,假如一个或者多个服务出现故障,如果这时候,依赖的服务还在不断发起请求,或者重试,那么这些请求的压力会不断在下游堆积,导致下游服务的负载急剧增加。不断累计之下,可能会导致故障的进一步加剧,可能会导致级联式的失败,甚至导致整个系统崩溃,这就叫服务雪崩。
1.2 防止服务雪崩的措施
防止服务雪崩,可以采用这些措施:
-
服务高可用部署:确保各个服务都具备高可用性,通过冗余部署、故障转移等方式来减少单点故障的影响。
-
限流和熔断:对服务之间的请求进行限流和熔断,以防止过多的请求涌入导致后端服务不可用。
-
缓存和降级:合理使用缓存来减轻后端服务的负载压力,必要时对服务进行降级,保证核心功能的可用性。
2. 服务熔断和服务降级
2.1 什么是服务熔断?
服务熔断是微服务架构中的容错机制,用于保护系统免受服务故障或异常的影响。当某个服务出现故障或异常时,服务熔断可以快速隔离该服务,确保系统稳定可用。
它通过监控服务的调用情况,当错误率或响应时间超过阈值时,触发熔断机制,后续请求将返回默认值或错误信息,避免资源浪费和系统崩溃。
服务熔断还支持自动恢复,重新尝试对故障服务的请求,确保服务恢复正常后继续使用。
2.2 什么是服务降级?
服务降级是也是一种微服务架构中的容错机制,用于在系统资源紧张或服务故障时保证核心功能的可用性。
当系统出现异常情况时,服务降级会主动屏蔽一些非核心或可选的功能,而只提供最基本的功能,以确保系统的稳定运行。通过减少对资源的依赖,服务降级可以保证系统的可用性和性能。
它可以根据业务需求和系统状况来制定策略,例如替换耗时操作、返回默认响应、返回静态错误页面等。
2.3 常见的熔断降级方案实现
常见的服务熔断降级的实现方案:
| 框架 | 实现方案 | 特点 |
|---|---|---|
| Spring Cloud | Netflix Hystrix | - 提供线程隔离、服务降级、请求缓存、请求合并等功能 - 可与 Spring Cloud 其他组件无缝集成 - 官方已宣布停止维护,推荐使用 Resilience4j 代替 |
| Spring Cloud | Resilience4j | - 轻量级服务熔断库 - 提供类似于 Hystrix 的功能 - 具有更好的性能和更简洁的 API - 可与 Spring Cloud 其他组件无缝集成 |
| Spring Cloud Alibaba | Sentinel | - 阿里巴巴开源的流量控制和熔断降级组件 - 提供实时监控、流量控制、熔断降级等功能 - 与 Spring Cloud Alibaba 生态系统紧密集成 |
| Dubbo | 自带的熔断降级机制 | - Dubbo 框架本身提供的熔断降级机制 - 可通过配置实现服务熔断和降级 - 与 Dubbo的 RPC 框架紧密集成 |
2.4 Hystrix 如何实现服务容错?
Hystrix 虽然已经不再更新,但它是非常经典的服务容错开源库,提供了多种机制来保护系统:
-
服务熔断(Circuit Breaker):Hystrix 通过设置阈值来监控服务的错误率或响应时间。当错误率或响应时间超过预设的阈值时,熔断器将会打开,后续的请求将不再发送到实际的服务提供方,而是返回预设的默认值或错误信息。 这种方式可以快速隔离故障服务,防止故障扩散,提高系统的稳定性和可用性。
-
服务降级(Fallback):当服务熔断打开时,Hystrix 可以提供一个备用的降级方法或返回默认值,以保证系统继续正常运行。开发者可以定义降级逻辑,例如返回缓存数据、执行简化的逻辑或调用其他可靠的服务,以提供有限但可用的功能。
/*** 服务降级示例**/@Servicepublic class MyService {@HystrixCommand(fallbackMethod = "fallbackMethod")public String myServiceMethod() {// 实际的服务调用逻辑// ...}public String fallbackMethod() {// 降级方法的逻辑,当服务调用失败时会执行此方法// 可以返回默认值或执行其他备用逻辑// ...}} -
请求缓存(Request Caching):Hystrix 可以缓存对同一请求的响应结果,当下次请求相同的数据时,直接从缓存中获取,避免重复的网络请求,提高系统的性能和响应速度。
-
请求合并(Request Collapsing):Hystrix 可以将多个并发的请求合并为一个批量请求,减少网络开销和资源占用。一些高并发的场景下可以有效地减少请求次数,提高系统的性能。
-
实时监控和度量(Real-time Monitoring and Metrics):Hystrix 提供了实时监控和度量功能,可以对服务的执行情况进行监控和统计,包括错误率、响应时间、并发量等指标。通过监控数据,可以及时发现和解决服务故障或性能问题。
-
线程池隔离(Thread Pool Isolation):Hystrix 将每个依赖服务的请求都放在独立的线程池中执行,避免因某个服务的故障导致整个系统的线程资源耗尽。通过线程池隔离,可以提高系统的稳定性和可用性。
2.5 Sentinel 如何实现限流?
2.5.1 Sentinel 的限流控制步骤
Sentinel 通过动态管理限流规则,根据定义的规则对请求进行限流控制。具体实现步骤如下:
-
定义资源:在Sentinel中,资源可以是URL、方法等,用于标识需要进行限流的请求。
// 原本的业务方法. @SentinelResource(blockHandler = "blockHandlerForGetUser") public User getUserById(String id) {throw new RuntimeException("getUserById command failed"); }// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用 public User blockHandlerForGetUser(String id, BlockException ex) {return new User("admin"); } -
配置限流规则:在 Sentinel 的配置文件中定义资源的限流规则。规则可以包括资源名称、限流阈值、限流模式(令牌桶或漏桶)等。
private static void initFlowQpsRule() {List<FlowRule> rules = new ArrayList<>();FlowRule rule1 = new FlowRule();rule1.setResource(resource);// Set max qps to 20rule1.setCount(20);rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);rule1.setLimitApp("default");rules.add(rule1);FlowRuleManager.loadRules(rules); } -
监控流量:Sentinel会监控每个资源的流量情况,包括请求的QPS(每秒请求数)、线程数、响应时间等。
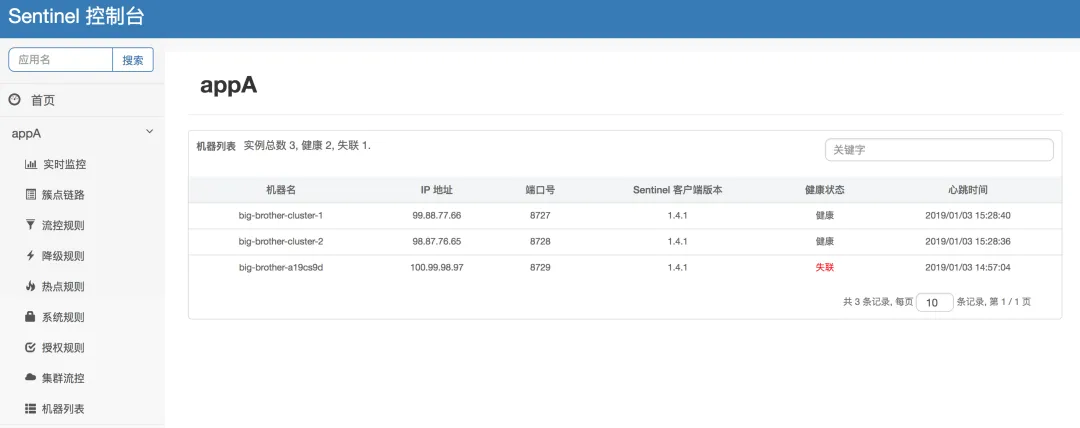
-
限流控制:当请求到达时,Sentinel会根据资源的限流规则判断是否需要进行限流控制。如果请求超过了限流阈值,则可以进行限制、拒绝或进行其他降级处理。
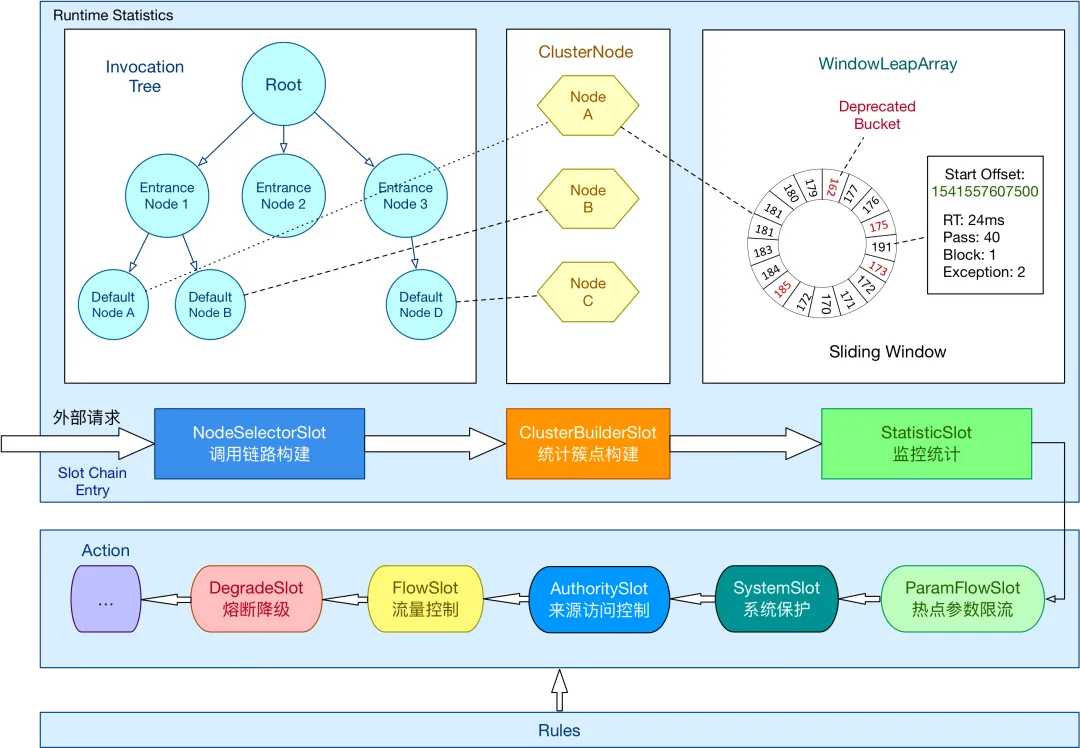
2.5.1 Sentinel 限流算法
Sentinel 使用滑动窗口限流算法来实现限流。
滑动窗口限流算法是一种基于时间窗口的限流算法。它将一段时间划分为多个时间窗口,并在每个时间窗口内统计请求的数量。通过动态地调整时间窗口的大小和滑动步长,可以更精确地控制请求的通过速率。
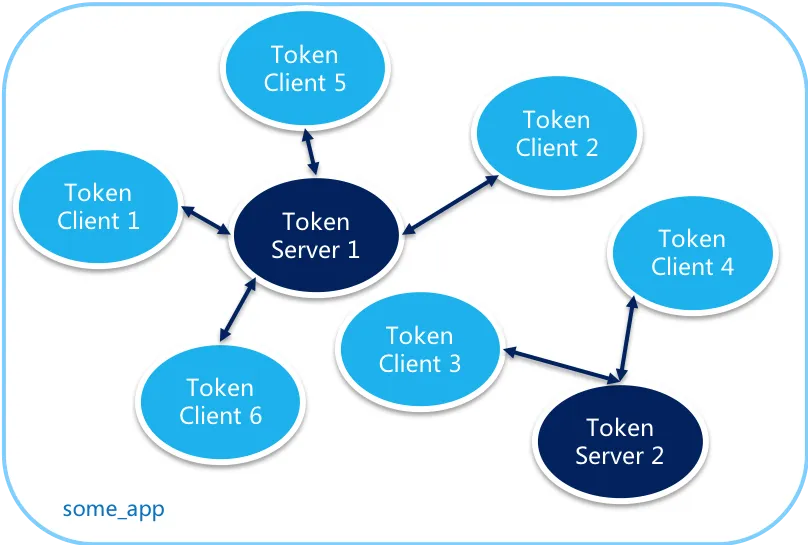
2.5.1 Sentinel 实现集群限流
Sentinel 利用 Token Server 和 Token Client 的机制来实现集群限流。
开启集群限流后,Client向Token Server发送请求,Token Server根据配置的规则决定是否限流。T
服务网关

![基于ESP32的桌面小屏幕实战[7]:第一个工程Hello world!以及打印日志](https://img2023.cnblogs.com/blog/3361035/202410/3361035-20241026160429956-17542463.png)