一、介绍
Google Benchmark 是一个用于 C++ 的微基准测试库。它旨在帮助开发者编写出更高效、更具表现力的基准测试代码。通过使用 Google Benchmark,可以方便地测量函数或代码片段的性能,并且能够生成详细的报告。
二、安装与配置
2.1 安装
在Ubuntu环境中安装Google Benchmark库可以通过多种方式进行,包括使用包管理器直接安装预编译的版本或者从源代码自行编译。
以下是两种常见的方法:
方法一:通过Ubuntu的包管理器安装(推荐)
对于较新的Ubuntu版本,Google Benchmark可能已经包含在官方仓库中,你可以通过apt命令直接安装。
安装Google Benchmark:
使用下面的命令来安装Google Benchmark及其开发文件。
sudo apt update
sudo apt install google-benchmark
如果你需要CMake配置文件和头文件,还可以安装 libbenchmark-dev 包:
sudo apt install libbenchmark-dev
验证安装:安装完成后,你可以通过以下命令检查是否正确安装了Google Benchmark:
dpkg -l | grep benchmark
这种方法的优点是简单快捷,并且通常会自动处理依赖关系。
方法二:从源代码编译安装
如果你需要最新的功能或修复,可以从GitHub上获取源代码并自行编译。
安装依赖项:
首先,确保你已经安装了必要的构建工具和依赖项。你可以使用以下命令来安装这些工具:
sudo apt install cmake git build-essential
克隆Google Benchmark仓库:
使用Git将Google Benchmark的仓库克隆到本地机器上。
git clone https://github.com/google/benchmark.git
cd benchmark
创建构建目录并编译:
创建一个用于构建的子目录,并进入该目录进行编译。
mkdir build && cd build
cmake ..
make -j$(nproc) # 使用所有可用的核心加速编译过程
安装Google Benchmark:编译成功后,你可以选择安装它到系统路径下。
sudo make install
验证安装:同样地,可以使用
dpkg -l | grep benchmark
或者尝试编写一个小的C++程序来测试安装是否成功。
这种方法允许你获得最新版本的Google Benchmark,并且可以自定义编译选项。但是,它也要求你手动解决任何可能出现的依赖问题。
【使用 CMake】:
在 CMake 项目中,可以通过以下方式引入 Google Benchmark:
find_package(benchmark REQUIRED)
add_executable(my_benchmark main.cpp)
target_link_libraries(my_benchmark benchmark::benchmark)
2.2 配置
确保你的编译器支持 C++11 或更高版本,并且在 CMake 中设置相应的标准:
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
三、基本用法
3.1 创建基准测试
创建一个基准测试非常简单。你需要定义一个函数,并使用 BENCHMARK 宏来注册该函数。例如:
#include <benchmark/benchmark.h>static void BM_StringCreation(benchmark::State& state) {for (auto _ : state) {std::string empty_string;benchmark::DoNotOptimize(empty_string);}
}
BENCHMARK(BM_StringCreation);BENCHMARK_MAIN();
3.2 运行基准测试
编译并运行你的基准测试程序。你可以通过命令行参数来控制基准测试的行为。例如:
g++ -std=c++11 -I/usr/include -L/usr/lib/x86_64-linux-gnu -o benchmark_test benchmark_test.cpp -lbenchmark -pthread./benchmark_test --benchmark_filter=BM_StringCreation
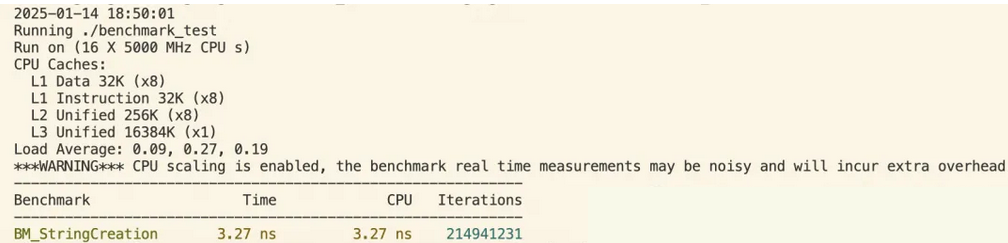
这段benchmark测试的结果数据提供了关于BM_StringCreation基准测试的详细信息,包括运行环境、CPU特性、负载平均值以及具体的性能测量结果。以下是对这些数据的解释:
【测试环境】:
日期和时间:2025-01-14 18:51:03
执行命令:./benchmark_test
CPU配置:
核心数:16个逻辑处理器
频率:5000 MHz(即5GHz)
缓存层次结构:
L1数据缓存:32KB,共有8个(可能每个物理核心两个)
L1指令缓存:32KB,共有8个(同样,可能每个物理核心两个)
L2统一缓存:256KB,共有8个(每个物理核心一个)
L3统一缓存:16384KB(16MB),共享给所有核心
系统负载:在测试开始时,系统的1分钟、5分钟和15分钟平均负载分别为0.07, 0.23, 0.18,这表明系统几乎空闲。
【性能测量结果】:
Benchmark名称:BM_StringCreation
Time (实际时间):3.27 ns(纳秒),这是每次调用BM_StringCreation函数的实际耗时。
CPU (CPU时间):3.27 ns,与实际时间相同,说明几乎没有上下文切换或其他非CPU相关的延迟。
Iterations (迭代次数):210,470,863 次,这是Google Benchmark框架自动确定的最佳迭代次数,以提供足够数量的数据点来计算统计平均值并减少随机误差的影响。
【进一步解读】:
从这些数据中我们可以得出几个结论:
快速操作:创建一个空的std::string对象是非常快的操作,平均只需要3.27纳秒。这是因为这个操作非常轻量级,主要涉及分配少量内存(如果有的话)和初始化对象状态。
高精度计时器:能够测量到纳秒级别的精度,说明测试环境使用了高分辨率的时间计数器。
高效的CPU利用率:实际时间和CPU时间相等,意味着几乎没有等待I/O或者其他资源的情况发生,整个过程都在CPU上高效完成。
大量的迭代:高达2亿多次的迭代次数进一步验证了这是一个非常快速的操作,同时也保证了结果的可靠性。
总的来说,这段benchmark测试显示BM_StringCreation是一个极其高效的函数,它几乎不会成为性能瓶颈。如果你的目标是评估更复杂或者更耗时的操作,这样的快速操作可以作为参考基线,帮助你理解其他部分相对于这一基础操作的表现如何。对于如此快速的操作,即使是很小的变化也可能显著影响结果,因此在优化这类代码时需要特别小心,确保你的修改确实带来了实质性的改进。
四、高级功能
4.1 参数化基准测试
有时候你可能需要对不同的输入进行基准测试。Google Benchmark 提供了参数化基准测试的功能。
例如:
static void BM_StringCopy(benchmark::State& state) {std::string x = "hello";for (auto _ : state) {std::string copy(x);benchmark::DoNotOptimize(copy);}
}
BENCHMARK(BM_StringCopy)->Arg(5)->Arg(10)->Arg(20);BENCHMARK_MAIN();
4.2 自定义计时器
Google Benchmark 允许你自定义计时器,以适应不同的需求。
例如:
class MyTimer : public benchmark::Timer {
public:MyTimer() : start_(std::chrono::high_resolution_clock::now()) {}double ElapsedTime() const override {return std::chrono::duration_cast<std::chrono::nanoseconds>(std::chrono::high_resolution_clock::now() - start_).count() /1e9;}private:std::chrono::time_point<std::chrono::high_resolution_clock> start_;
};BENCHMARK_RELATIVE(MyCustomBenchmark, n) {MyTimer timer;while (n--) {// Your code here}return timer.ElapsedTime();
}
BENCHMARK_REGISTER_F(MyFixture, MyCustomBenchmark)->Range(1, 10000);
4.3 固定迭代次数
有时候你可能希望固定迭代次数,而不是让 Google Benchmark 自动选择。可以使用 函数来实现:
BENCHMARK(BM_StringCreation)->Iterations(1000);
五、结果分析
Google Benchmark 会生成详细的报告,包括每个基准测试的平均时间、方差等统计信息。你可以通过命令行参数来控制输出格式和详细程度。例如:
./my_benchmark --benchmark_format=json
总结
Google Benchmark 是一个强大且灵活的基准测试工具,可以帮助你更好地理解和优化代码性能。通过本文档的学习,你应该已经掌握了如何安装、配置和使用 Google Benchmark。希望你在实际项目中能够充分利用这个工具,提升代码的性能。
素材来源官方媒体/网络新闻