一. 子模型的基本架构
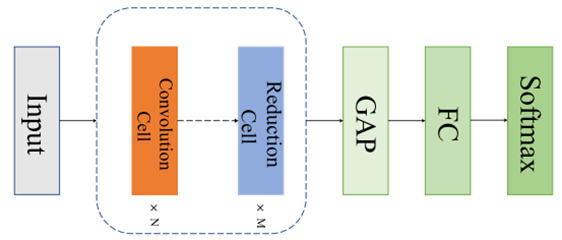
子模型由N个卷积单元和M个缩减单元按一定规则排列后加上GAP层、FC层和Softmax层组成。关键:通过引入卷积单元和缩减单元,充分发挥了CNN模型强大的特征提取能力。
整个结构中后面三层是确定的,中间的卷积单元和缩减单元要从搜索空间中获取。
二. 搜索空间
NAS的核心思想是搜索空间可以表示为一个有向无环图(DAG)。
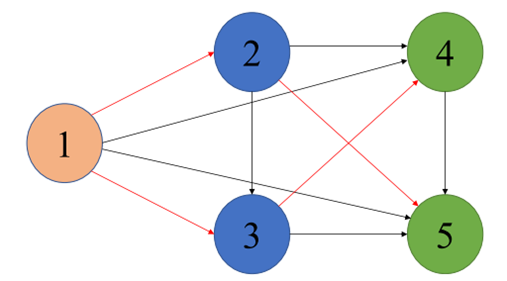
由5个节点组成的图代表整个搜索空间,节点代表着不同的局部计算操作(如卷积、池化等),因此和普通神经网络一样,每个节点都有其局部计算的特定参数。边表示信息的流动方向。红色箭头及其连接的节点在搜索空间中构成一个候选子单元。当某个子单元包含了某个节点时就会使用到这个节点对应的参数。因此,这种设计实现了所有子模型之间的参数共享。
为了更清晰地说明通过取DAG的子图来得到一个单元的过程,这里用五个节点组成的图来举例,但是在实际的搜索过程中,搜索空间包含了足够多的可能的节点和连接。这种结构有很大的优势,一方面:这种DAG方式使得搜索空间具有很大的灵活性和可能性,能够涵盖各种不同的网络结构,从而能从中获取各种的候选子单元,增加了找到最优解(最优架构)的机会。另一方面:子模型可以共享权值,从而避免了从头开始训练子模型,该方法显著缩短了从大量候选网络中寻找最优子模型的时间。
搜索空间的主要目的是为获取构建子模型的基础组件。从DAG中采样不同的候选子单元,当采样得到的子图满足卷积单元的构建规则时,就形成卷积单元;当子图满足缩减单元的构建规则时,便得到缩减单元。将获取到的卷积单元和缩减单元按照一定顺序排列,多个卷积单元和缩减单元堆叠,共同构成子模型的主体结构。并在此基础上,添加输入层用于接收数据,添加GAP层进行全局平均池化以降低数据维度,添加FC层进行全连接操作整合特征,添加Softmax层用于将输出转换为概率分布,完成分类任务,最终形成完整的子模型。
三.搜索策略——强化学习
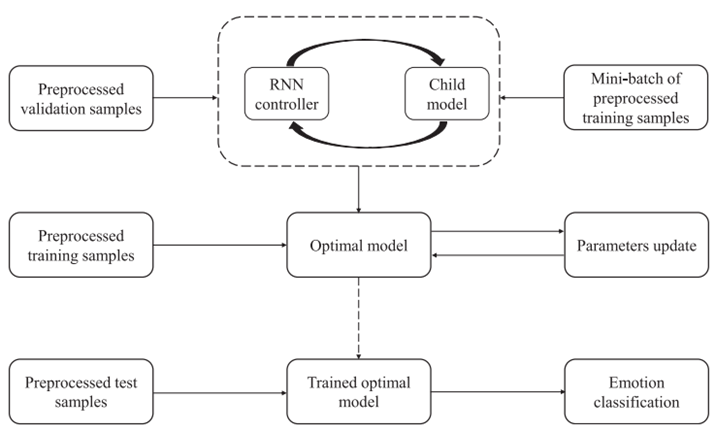
强化学习搜索程序:
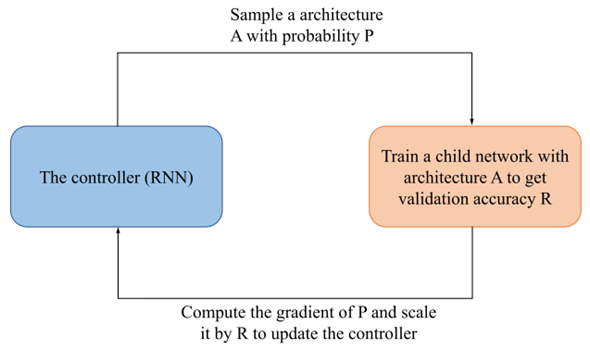
LSTM控制器作为智能体,按照一定概率P(也就是基于当前策略函数![]() ,这里
,这里![]() 是控制器参数)从搜索空间中采样一个架构A(子模型m)。然后在验证集上训练采样得到的子模型,并得到验证准确率R。它被用作强化学习中的reward,用于评估当前采样得到的子模型的优劣。然后用策略梯度法,根据上面的策略函数和奖励R,通过缩放梯度来更新智能体(控制器)的参数
是控制器参数)从搜索空间中采样一个架构A(子模型m)。然后在验证集上训练采样得到的子模型,并得到验证准确率R。它被用作强化学习中的reward,用于评估当前采样得到的子模型的优劣。然后用策略梯度法,根据上面的策略函数和奖励R,通过缩放梯度来更新智能体(控制器)的参数![]() 。通过迭代不断调整
。通过迭代不断调整![]() ,让控制器学会搜索更优的子模型架构。
,让控制器学会搜索更优的子模型架构。
3.1 LSTM控制器及其训练过程
3.1.1 控制器结构
在整个NAS框架中,控制器的主要任务是决定子单元内部的节点选择和连接方式,从而在基于搜索空间构建卷积单元和缩减单元。
控制器是一个具有 100 个隐藏单元的长短期记忆网络(LSTM)。它以自回归的方式工作,即前一步的输出作为下一步的输入。在初始步骤,会向控制器输入一个空嵌入。这种结构设计使得控制器能够基于之前的决策信息,不断调整后续的决策,从而逐步构建出复杂的神经网络架构。控制器细节如下:
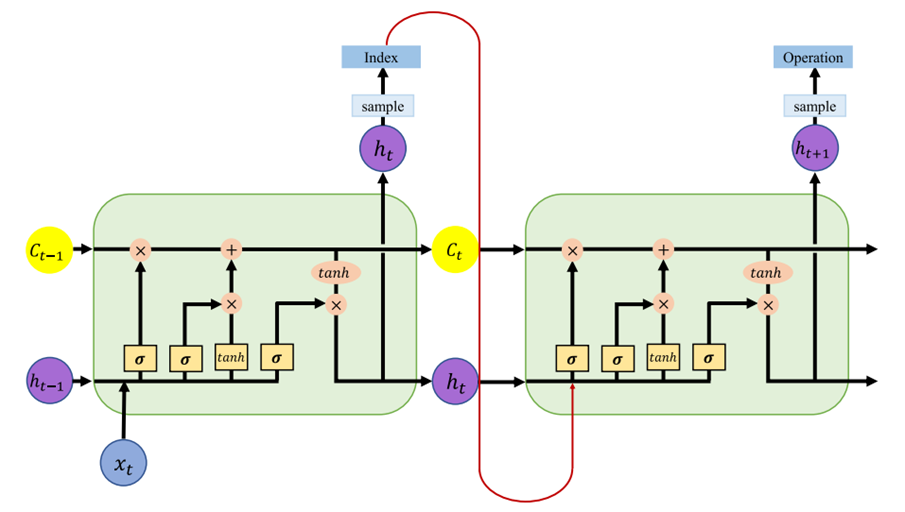
左半部分用于选择当前节点的连接关系,右半部分用于选择当前节点的操作。
图中![]() 表示当前输入,
表示当前输入,![]() 代表前一时刻的隐藏状态,
代表前一时刻的隐藏状态,![]() 表示前一时刻的细胞记忆。这些信息是控制器在每个时刻进行决策的基础输入。
表示前一时刻的细胞记忆。这些信息是控制器在每个时刻进行决策的基础输入。
左半部分:输入在经过遗忘门、输入门和输出门之后,输出一个表示当前节点连接关系的“Index”。这个“Index”决定了当前节点与其他节点的连接关系。
右半部分:输入前面得到的连接关系Index、t时刻的隐藏状态![]() 、t时刻的细胞记忆
、t时刻的细胞记忆![]() 。同样的经过一个LSTM结构,最终输出“Operation”,代表当前节点要执行的操作(如卷积、池化等操作)。
。同样的经过一个LSTM结构,最终输出“Operation”,代表当前节点要执行的操作(如卷积、池化等操作)。
随着时间步的推进,控制器不断重复上述步骤,逐步确定整个神经网络架构中各个节点的连接和操作,最终构建出一个完整的子模型架构。
3.1.2 训练控制器
在训练控制器时,子模型的参数![]() 会被固定,此时通过更新策略参数
会被固定,此时通过更新策略参数![]() 来最大化期望奖励
来最大化期望奖励![]() ,这里的奖励
,这里的奖励![]() 是验证数据集的一小部分上计算得到的准确率。根据策略函数
是验证数据集的一小部分上计算得到的准确率。根据策略函数![]() 和准确率R通过策略梯度法更新参数
和准确率R通过策略梯度法更新参数![]() ,其中使用Adam自适应调整学习率。
,其中使用Adam自适应调整学习率。
3.2 训练子模型
当训练子模型时,固定控制器策略![]() 。这意味着在这个阶段,控制器采样子模型的方式保持不变,专注于调整子模型的参数
。这意味着在这个阶段,控制器采样子模型的方式保持不变,专注于调整子模型的参数![]() 。子模型本质是神经网络架构,
。子模型本质是神经网络架构,![]() 涵盖网络中各层的权重矩阵与偏置向量。
涵盖网络中各层的权重矩阵与偏置向量。
具体过程是:通过执行带动量的梯度下降,来最小化期望损失函数![]() 。这里的是
。这里的是![]() 子模型的损失函数,在训练数据集的一小部分上采用标准交叉熵损失计算。通过标准反向传播计算梯度
子模型的损失函数,在训练数据集的一小部分上采用标准交叉熵损失计算。通过标准反向传播计算梯度![]() 。采用了蒙特卡罗估计来估计这个期望损失函数的梯度,即
。采用了蒙特卡罗估计来估计这个期望损失函数的梯度,即
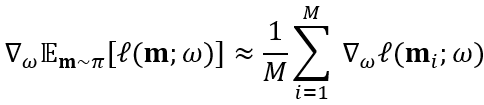
其中![]() 是从控制器策略中采样得到的,文中经验性地将M设为1。这样,子模型的共享参数
是从控制器策略中采样得到的,文中经验性地将M设为1。这样,子模型的共享参数![]() 利用从策略函数
利用从策略函数![]() 中采样得到的子模型的梯度信息来更新,在整个搜索过程中不断训练优化。
中采样得到的子模型的梯度信息来更新,在整个搜索过程中不断训练优化。
3.3 模型训练过程
整体训练过程:

1.初始化阶段:
将预处理后的EEG数据划分为训练集、验证集和测试集
2.控制器和子模型交互训练:
使用训练集的一小部分和验证集的一小部分分别训练子模型和控制器。训练过程中子模型和控制器参数更新交替进行,并多次迭代。流程细节如下:
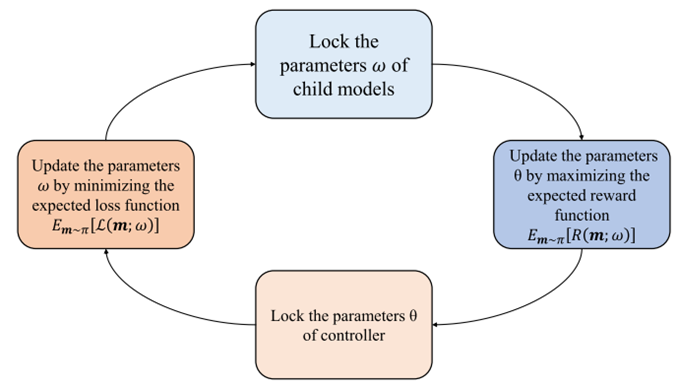
首先锁定子模型的参数![]() 使其保持不变。然后通过最大化期望奖励函数
使其保持不变。然后通过最大化期望奖励函数![]() 来更新控制器参数
来更新控制器参数![]() 。之后将其锁定。最后通过最小化期望损失函数来更新参数
。之后将其锁定。最后通过最小化期望损失函数来更新参数![]() 。按此步骤循环往复,通过这种不断交替更新控制器和子模型参数的方式,逐步搜索和优化出性能更优的神经网络架构。
。按此步骤循环往复,通过这种不断交替更新控制器和子模型参数的方式,逐步搜索和优化出性能更优的神经网络架构。
3.训练最优模型
在多次迭代后,从众多训练过的模型中选择奖励最高的模型,然后对该模型进行从头开始的重新训练。使用训练集数据,使模型在训练数据上达到更好的性能。
4.测试过程
将测试集输入到训练好的最优模型中,进行情感分类,输出最终的情感分类结果。
四.卷积单元和缩减单元的搜索机制
前面提到,从DAG中采样不同的候选子单元,当采样得到的子图满足卷积单元的构建规则时,就形成卷积单元;当子图满足缩减单元的构建规则时,便得到缩减单元。那这些规则是什么样的呢?
节点决策方式:对于节点![]() ,控制器从先前的
,控制器从先前的![]() 个节点中采样两个节点,并从5种可用操作中采样任意两种操作。例如,当
个节点中采样两个节点,并从5种可用操作中采样任意两种操作。例如,当![]() 时,从节点1和节点2这两个先前节点中采样两个节点(可以重复采样同一个节点),并从5种操作中选两种;当
时,从节点1和节点2这两个先前节点中采样两个节点(可以重复采样同一个节点),并从5种操作中选两种;当![]() 时,从节点1、节点2和节点3这三个先前节点中采样两个节点,再选两种操作,依此类推。(5种可用的操作是:
时,从节点1、节点2和节点3这三个先前节点中采样两个节点,再选两种操作,依此类推。(5种可用的操作是:![]() 可分离卷积、
可分离卷积、![]() 可分离卷积、
可分离卷积、![]() 平均池化、
平均池化、![]() 最大池化、恒等映射,这里几乘几指的是卷积核或者池化窗口的尺寸大小)
最大池化、恒等映射,这里几乘几指的是卷积核或者池化窗口的尺寸大小)
以为B=4为例说明卷积单元的搜索过程,在这种设定下,DAG中有4个节点,其中节点1和节点2是输入节点,控制器不对它们进行操作,设其输出分别为![]() .
.
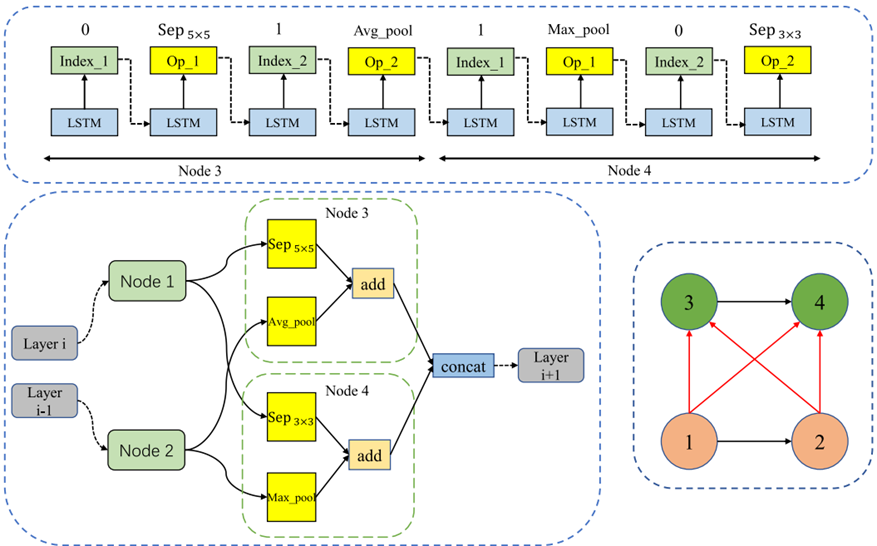
上图
LSTM控制器在搜索空间中为节点3和节点4进行决策的过程。控制器的工作原理是左部分为当前节点选连接关系,右部分为当前节点选操作方式,体现在图例中就是:对于节点3,左部分控制器选择节点1进行连接,再将其输出输入右部分,选出要进行的操作。再输入下一个LSTM隐藏单元,选择与它连接的下一个节点,以及要进行的操作。节点四同样。
左下
控制器对节点3进行操作,从先前节点(节点1和节点2)中采样,即选连接关系,并对采样节点执行操作。【这里采样了节点1,对它执行可分离卷积![]() ( sep_conv);采样节点2,执行
( sep_conv);采样节点2,执行![]() 平均池化(
平均池化(![]() ave_pool)操作,得到节点3的输出
ave_pool)操作,得到节点3的输出![]() 】
】
节点4同样先选连接关系再执行操作。【对于节点4,控制器采样节点2,并对其执行![]() 最大池化(
最大池化(![]() max_pool)操作;采样节点1,并对其执行
max_pool)操作;采样节点1,并对其执行![]() 可分离卷积操作,节点4的输出
可分离卷积操作,节点4的输出![]() 】
】
该卷积单元的输出可表示为结束节点![]() .
.
右下
举例的DAG如图,其中红色箭头代表激活的连接。实际搜索空间的DAG不只四个,结构要更复杂。

五.文章创新点
1.提出基于强化学习的新型数据驱动NAS框架,可自动为EEG情感识别设计网络架构。
2.NAS的核心是子模型间的参数共享,通过将搜索空间设计为有向无环图实现。每个节点有特定参数,仅在相应计算激活时使用,这种设计使所有子模型间的参数共享成为可能,有助于发现理想的网络结构,实现离散计算和连接决策。此策略加快了网络搜索过程。
3.通过在子模型中引入堆叠的卷积单元和缩减单元,充分利用CNN强大的特征提取能力,为模型架构带来了创新。构建了一个层次化的特征提取体系,从原始 EEG 信号逐步提取低级到高级的特征,能捕捉EEG信号不同尺度的局部特征,使得模型可以在不同分辨率下对数据进行特征提取,适应 EEG 信号的复杂特性,实现对数据的深度特征挖掘。