DeepSeek-R1 的训练过程确实可以类比为人类的教育过程,尤其是知识传递和学习的方式。下面我将用人类教育的方式来解释 DeepSeek-R1 的训练过程和意义。
1. 启蒙阶段(冷启动数据)
人类教育:在人类教育中,启蒙阶段是孩子开始学习基础知识的阶段。比如,孩子在幼儿园或小学低年级时,会学习字母、数字、简单的词汇和基本的语法。这些基础知识为后续的学习打下基础。
DeepSeek-R1:在 DeepSeek-R1 的训练中,冷启动数据就像是启蒙阶段的基础知识。这些数据通常包括高质量的推理示例,帮助模型快速理解任务的基本模式。通过这些冷启动数据,模型可以初步掌握推理任务的基本要求,为后续的训练打下基础。
2. 基础学习(微调 DeepSeek-V3-Base 模型)
人类教育:在基础学习阶段,学生会系统地学习各个学科的基础知识,比如数学、语文、科学等。这些知识帮助学生建立一个全面的知识体系。
DeepSeek-R1:在 DeepSeek-R1 的训练中,使用冷启动数据对 DeepSeek-V3-Base 模型进行微调,就像是学生在基础学习阶段系统地学习各个学科的基础知识。通过微调,模型可以更好地理解和处理各种推理任务,建立一个全面的知识体系。
3. 强化学习(推理导向的 RL)
人类教育:在强化学习阶段,学生会通过大量的练习和反馈来巩固和提升自己的知识和技能。比如,学生会做大量的数学题、写作文、做实验等,通过这些练习来提高自己的能力。
DeepSeek-R1:在 DeepSeek-R1 的训练中,推理导向的强化学习(RL)就像是学生通过大量的练习和反馈来巩固和提升自己的知识和技能。通过 RL,模型可以不断优化自己的推理能力,提高在各种任务上的表现。
4. 筛选和优化(拒绝采样生成新的 SFT 数据)
人类教育:在教育过程中,老师会根据学生的作业和考试成绩来筛选出优秀的作品,作为范例供其他学生学习。这些优秀的作品通常具有高质量和代表性,可以帮助学生更好地理解和掌握知识。
DeepSeek-R1:在 DeepSeek-R1 的训练中,拒绝采样生成新的 SFT 数据就像是老师筛选出优秀的作品。通过对 RL 检查点进行拒绝采样,生成高质量的推理答案,这些答案被用于后续的训练,帮助模型学习到更高质量的推理链。
5. 综合学习(重新训练 DeepSeek-V3-Base 模型)
人类教育:在综合学习阶段,学生会将各个学科的知识综合起来,形成一个完整的知识体系。比如,学生会学习跨学科的项目,将数学、科学和语文等知识结合起来,解决实际问题。
DeepSeek-R1:在 DeepSeek-R1 的训练中,重新训练 DeepSeek-V3-Base 模型就像是学生将各个学科的知识综合起来。通过结合新的 SFT 数据和来自 DeepSeek-V3 在写作、事实问答和自我认知等领域的监督数据,模型可以更好地处理各种任务,形成一个完整的知识体系。
6. 巩固和提升(额外的 RL 过程)
人类教育:在巩固和提升阶段,学生会通过更多的练习和反馈来进一步提升自己的能力。比如,学生会参加模拟考试、做更多的练习题,通过这些方式来巩固和提升自己的知识和技能。
DeepSeek-R1:在 DeepSeek-R1 的训练中,额外的 RL 过程就像是学生通过更多的练习和反馈来巩固和提升自己的能力。通过考虑所有场景的提示,模型可以进一步优化自己的推理能力,提高在各种任务上的表现。
7. 最终成果(获得 DeepSeek-R1 检查点)
人类教育:经过一系列的学习和训练,学生最终会取得优异的成绩,比如在考试中获得高分,或者在竞赛中获奖。这些成果是学生学习过程的最终体现。
DeepSeek-R1:经过上述步骤,DeepSeek-R1 最终获得一个高性能的检查点,其性能与 OpenAI-o1-1217 相当。这个检查点是模型训练过程的最终成果,体现了模型在各种任务上的优秀表现。
总结
DeepSeek-R1 的训练过程可以类比为人类的教育过程,从启蒙阶段的基础学习,到强化学习的巩固和提升,再到筛选和优化的综合学习,最终形成一个高性能的模型。这个过程不仅提高了模型的推理能力,还增强了模型的泛化能力和适应性,就像学生通过系统的学习和训练,最终成为知识渊博、能力出众的人才。
好学生 Deepseek 的学习过程
QQ:273352165
evlon#126.com
转载请注明出处。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/880721.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
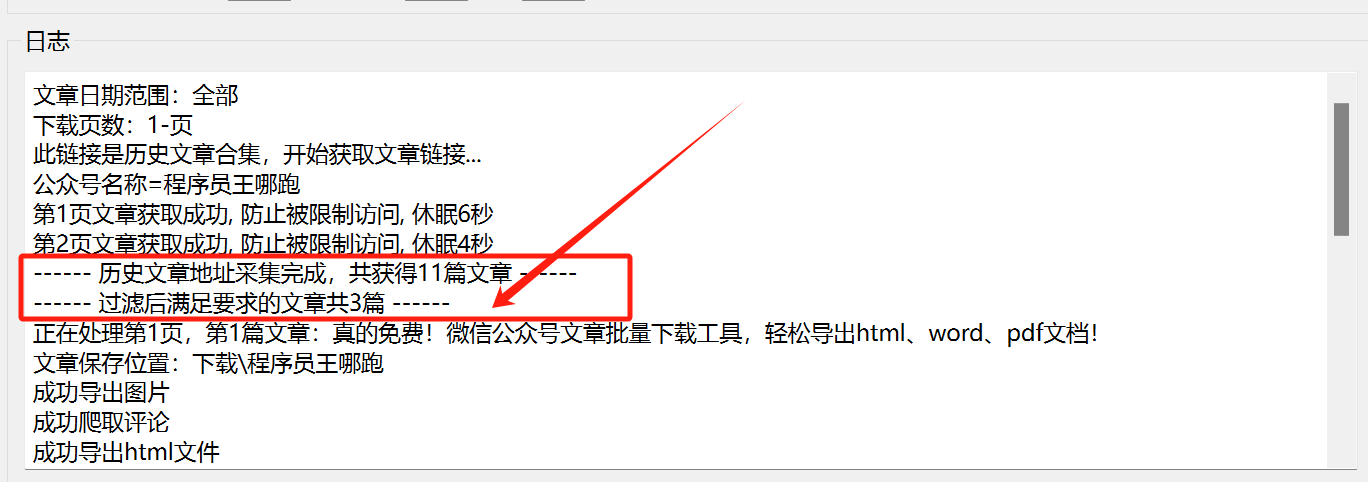
真的不错!微信公众号文章批量下载工具3.0版,支持评论、图片、word文件导出!
一、前言
之前发布的旧版本的说明,可以看下之前发布的这3篇文章:
真的免费!微信公众号文章批量下载工具,轻松导出html、word、pdf文档!
微信公众号文章批量下载工具1.2版本更新,轻松导出html、word、pdf文档!
重磅更新!微信公众号文章批量下载工具2.0版,轻松导出html、…

十二. Redis 集群操作配置(超详细配图,配截图详细说明)
十二. Redis 集群操作配置(超详细配图,配截图详细说明)
@目录十二. Redis 集群操作配置(超详细配图,配截图详细说明)1. 为什么需要集群-高可用性2. 集群概述(及其搭建)3. Redis 集群的使用4. Redis 集群故障恢复5. Redis 集群的 Jedis 开发(使用Java程序连接 Redis 同时开启集…

Docker:Docker搭建Jenkins并共用宿主机Docker部署服务(六)跨服务器远程部署前端服务
前言
继续完成跨服务器远程部署前端服务,Jenkins的搭建与插件安装可以观看上一篇文章:https://www.cnblogs.com/nhdlb/p/18561435
配置SSH远程服务器连接
这里需要安装 SSH 连接的插件,可以观看上一篇文章进行安装。开始配置SSH连接保存!!
新建视图
方便将整个项目的前端和…

一文详解文件摆渡系统是什么?企业需要什么样的文件摆渡产品?
文件摆渡系统是一种旨在实现企业内不同网络、安全域、网段之间的文件传输、同步、共享、管理与处理的工具或平台。文件摆渡系统的主要作用是确保文件能够在不同的存储环境、操作系统、应用程序或部门之间有效传递,同时保障文件的安全性、完整性和合规性。一、文件摆渡系统的核…

IvorySQL 升级指南:从 3.x 到 4.0 的平滑过渡
日前,IvorySQL 4.0 重磅发布,全面支持 PostgreSQL 17,并且增强了对 Oracle 的兼容性。关于 IvorySQL 4.0 的介绍,各位小伙伴可以通过这篇文章回顾:IvorySQL 4.0 发布:全面支持 PostgreSQL 17.
在 IvorySQL 4.0 发布后,有小伙伴私下询问升级方法,那么本篇文章就来详细描…


Ftrans数据跨境传输方案,推动数据跨境安全有序自由流动!
在全球数字经济快速发展的今天,数据跨境传输流动已成为企业国际化不可回避的重要议题。根据权威机构数据,全球跨境数据流量每年增长超过30%,企业数据出境已从简单的信息传输,演变为复杂的合规性管理。
目前,我国数据跨境传输安全管理体系已经初步构建形成。《网络安全法》…

如何打造高效、统一的供应商协同平台?
供应商协同,简单说就是把供需双方的各种“需求”找到对应的“供应”来匹配。这种“需求”和“供应”更多的不是实物,而是资讯、方法和活动。各企业需要一个供应商协同平台实现协同管理,供应链节点各企业形成共同的彼此认同的价值取向和文化理念,建立全面的战略合作伙伴关系…
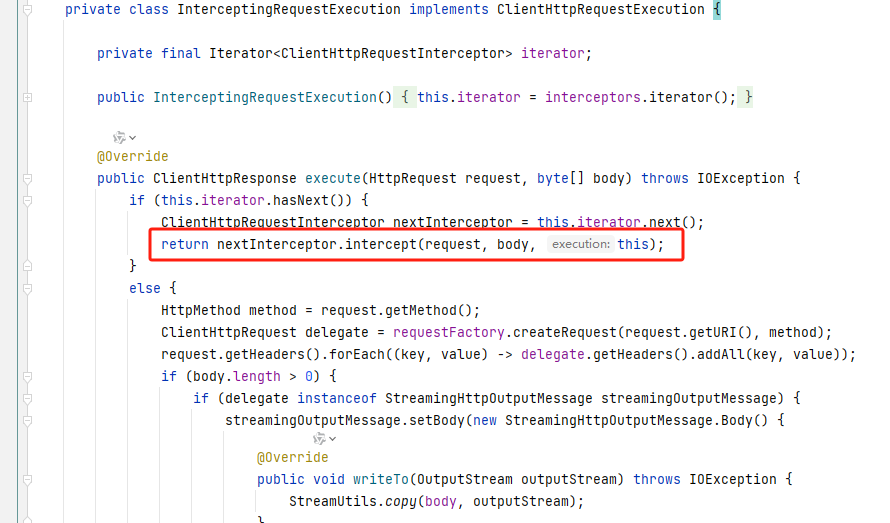
RestClient 通过拦截器实现请求加密
今天我发现了一个关于请求加密的有效写法,特此分享给大家。如果你的加密需求是将请求参数也包含在内,通常情况下,我们需要先将请求体转换成 JSON 格式或其他对象类型,再使用字符串的形式进行加密操作。以下是伪代码示例,展示了这一过程的实现方法:
String payloadString …

读算法简史:从美索不达米亚到人工智能时代10纠错和加密
通信系统需纠错,汉明码优化校验和;互联网设计缺安全,公钥加密RSA成基石,保障数据传输安全,现广泛用于万维网SSL。1. 纠错
1.1. 像互联网这样的通信系统,被设计成将信息的精确副本从发送方传输到接收方
1.2. 通常,接收到的信号会受到电子噪声的污染1.2.1. 噪声是任何会破…