摘要:本次更新聚焦AI与大数据的核心需求,推出网络拓扑感知调度、多集群AI作业调度等重磅特性,显著提升AI训练与推理任务的性能。
本文分享自华为云社区《Volcano v1.11 重磅发布!开启AI与大数据的云原生调度新纪元》,作者:云容器大未来。
作为云原生批量计算领域的事实标准,Volcano已经在AI、Big Data及高性能计算 (HPC) 等多种场景中获得广泛应用,吸引了来自30多个国家的800多名贡献者,累计代码提交数万次。Volcano已在国内外60+企业进行了生产落地,经受住了实际生产环境的考验,赢得了用户的广泛赞誉,为业界提供了云原生批量计算的卓越实践标准与解决方案。
随着用户使用场景的日益复杂,以及对资源利用率极致追求,特别是在AI大模型场景下,对训练与推理任务的性能、GPU资源利用率、可用性提出了更高的要求,促使Volcano不断拓展其应用场景,深入解决用户的核心诉求。Volcano目前的版本历程里共发布了28个release,针对批量计算的场景做了一系列功能增强和优化,帮助用户更好的将业务迁移到云原生平台,解决了诸多痛点问题,赢得了用户的广泛的喜爱与好评,用户与社区之间也形成了良好的互动,approver和reviewer数量累计发展了30+,达成了双赢互利的局面。

值此2025新年之际,Volcano新版本将会是一个新的里程碑,社区将在2025年引入一系列重大特性,继续深耕CNAI(Cloud Native AI 云原生AI)和大数据等领域,主要特性包括:
AI场景:
-
网络拓扑感知调度: 降低训练任务间的网络传输开销,优化大模型训练场景下的性能。
-
NPU卡调度和虚拟化能力: 提升NPU资源利用率。
-
GPU卡动态切分能力: 提供MIG与MPS动态切分能力,提升GPU资源利用率。
-
Volcano Global多集群AI作业调度: 支持跨集群的AI任务部署与拆分。
-
断点续训与故障恢复能力优化: 支持更细粒度的作业重启策略。
-
支持DRA:支持动态资源分配,灵活高效的管理异构资源。
大数据场景:
-
弹性层级队列能力: 帮助用户将大数据业务丝滑迁移到云原生平台。
微服务场景:
-
在离线混部与动态资源超卖: 提升资源利用率,同时保障在线业务QoS。
-
负载感知调度与重调度: 提供资源碎片整理和负载均衡能力。
Volcano v1.11的正式发布[1],标志着云原生批量计算迈入全新阶段!本次更新聚焦AI与大数据的核心需求,推出网络拓扑感知调度、多集群AI作业调度等重磅特性,显著提升AI训练与推理任务的性能。同时,在离线混部与动态资源超卖及负载感知重调度功能进一步优化资源利用率,确保在线业务的高可用性。此外,弹性层级队列为大数据场景提供了更灵活的调度策略。Volcano v1.11不仅是技术的飞跃,更是云原生批量计算领域的全新标杆!
重磅特性详解
本次发布的v1.11版本针对AI、大数据和资源利用率提升场景提供一系列重磅特性更新,主要包含:
▍网络拓扑感知调度:优化AI大模型训练性能
在AI大模型训练场景中,模型并行(Model Parallelism)将模型分割到多个节点上,训练过程中这些节点需要频繁进行大量数据交互。此时,节点间的网络传输性能往往成为训练的瓶颈,显著影响训练效率。数据中心的网络类型多样,如InfiniBand (IB)、RoCE、NVSwitch等,且网络拓扑复杂,通常包含多层交换机。两个节点间跨的交换机越少,通信延迟越低,吞吐量越高。因此,用户希望将工作负载调度到具有最高吞吐量和最低延迟的最佳性能域,尽可能减少跨交换机的通信,以加速数据交换,提升训练效率。
为此,Volcano提出了网络拓扑感知调度(Network Topology Aware Scheduling)策略,通过统一的网络拓扑API和智能调度策略,解决大规模数据中心AI训练任务的网络通信性能问题。
统一的网络拓扑API:精准表达网络结构
为了屏蔽数据中心网络类型的差异,Volcano定义了新的CRD HyperNode来表示网络拓扑,提供了标准化的API接口。与传统的通过节点标签(label)表示网络拓扑的方式相比,HyperNode具有以下优势:
-
语义统一:HyperNode提供了标准化的网络拓扑描述方式,避免了标签方式的语义不一致问题。
-
层级结构:HyperNode支持树状层级结构,能够更精确地表达实际的网络拓扑。
-
易于管理:集群管理员可以手动创建HyperNode,或通过网络拓扑自动发现工具维护HyperNode。
一个HyperNode表示一个网络拓扑性能域,通常映射到一个交换机。多个HyperNode通过层级连接,形成树状结构。例如,下图展示了由多个HyperNode构成的网络拓扑:
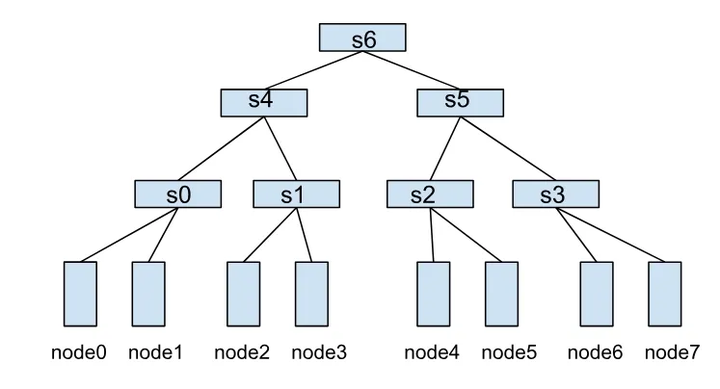
-
叶子HyperNode(s0、s1、s2、s3):子节点为集群中的真实节点。
-
非叶子HyperNode(s4、s5、s6):子节点为其他HyperNode。
在这种结构中,节点间的通信效率取决于它们之间的HyperNode层级跨度。例如:
-
node0 和 node1 同属于s0,通信效率最高。
-
node1 和 node2 需要跨两层HyperNode(s0→s4→s1),通信效率较低。
-
node0 和 node4 需要跨三层HyperNode(s0→s4→s6),通信效率最差。
HyperNode配置示例
以下是一个叶子HyperNode和非叶子HyperNode的配置示例:
叶子HyperNode示例:
apiVersion: topology.volcano.sh/v1alpha1 kind: HyperNode metadata:name: s0 spec:tier: 1 # HyperNode层级,层级越低通信效率越高members: # 子节点列表- type: Node # 子节点类型为Node selector:exactMatch: # 精确匹配name: node-0- type: Nodeselector:regexMatch: # 正则匹配pattern: node-[01]
非叶子HyperNode示例:
apiVersion: topology.volcano.sh/v1alpha1 kind: HyperNode metadata:name: s6 spec:tier: 3 # HyperNode层级members: # 子节点列表- type: HyperNode # 子节点类型为HyperNode selector:exactMatch: # 精确匹配 name: s4- type: HyperNodeselector:exactMatch:name: s5
基于网络拓扑的感知调度策略
Volcano Job和PodGroup可以通过 networkTopology 字段设置作业的拓扑约束,支持以下配置:
-
mode:支持 hard 和 soft 两种模式。
hard:硬约束,作业内的任务必须部署在同一个HyperNode内。
soft:软约束,尽可能将作业部署在同一个HyperNode下。
-
highestTierAllowed:与 hard 模式配合使用,表示作业允许跨到哪层HyperNode部署。
例如,以下配置表示作业只能部署在2层及以下的HyperNode内(如s4或s5),否则作业将处于Pending状态:
spec:networkTopology:mode: hardhighestTierAllowed: 2
通过这种调度策略,用户可以精确控制作业的网络拓扑约束,确保作业在满足条件的最佳性能域运行,从而显著提升训练效率。
未来展望
Volcano将持续优化网络拓扑感知调度功能,未来计划:
-
支持从节点标签自动转换为HyperNode CR,帮助用户迁移到Volcano。
-
集成底层网络拓扑自动发现工具,简化HyperNode的管理。
-
提供命令行工具,方便用户查看和管理HyperNode层级结构。
关于Network Topology Awre Scheduling的详细设计与使用指导,请参考
设计文档:Network Topology Aware Scheduling[2]。
使用文档:Network Topology Aware Scheduling | Volcano[3]。
由衷感谢社区开发者: @ecosysbin, @weapons97, @Xu-Wentao,@penggu, @JesseStutler, @Monokaix 对该特性的贡献!
▍弹性层级队列:灵活的多租户资源管理策略
在多租户场景中,资源分配的公平性、隔离性以及任务优先级控制是核心需求。不同部门或团队通常需要共享集群资源,同时又要确保各自的任务能够按需获得资源,避免资源争用或浪费。为此,Volcano v1.11 引入了弹性层级队列功能,大幅增强了队列的资源管理能力。通过层级队列,用户可以实现更细粒度的资源配额管理、跨层级资源共享与回收,以及灵活的抢占策略,从而构建高效、公平的统一调度平台。同时对于使用YARN的用户,可以使用Volcano无缝将大数据业务迁移到Kubernetes集群之上。
弹性层级队列的核心能力
Volcano的弹性层级队列具备以下关键特性,满足多租户场景下的复杂需求:
1. 支持配置队列层级关系:用户可以按需创建多级队列,形成树状结构。每个队列可以设置独立的资源配额和优先级,确保资源的合理分配。
2. 跨层级资源共享与回收:子队列资源空闲时,可以将资源共享给兄弟队列,当子队列提交任务时,可以从兄弟队列回收资源。
3. 细粒度的资源配额管理,每个队列可以设置以下资源参数:
capability:队列的资源容量上限。
deserved:队列应得的资源量。如果队列已分配的资源超过deserved值,超出的部分可以被回收。
guarantee:队列的资源预留量,这部分资源不会被其他队列共享,确保队列的最低资源保障。
4. 灵活的抢占策略:支持基于优先级的资源抢占,确保高优先级任务能够及时获得所需资源。
层级队列示意图
以下是一个简单的层级队列结构示例:
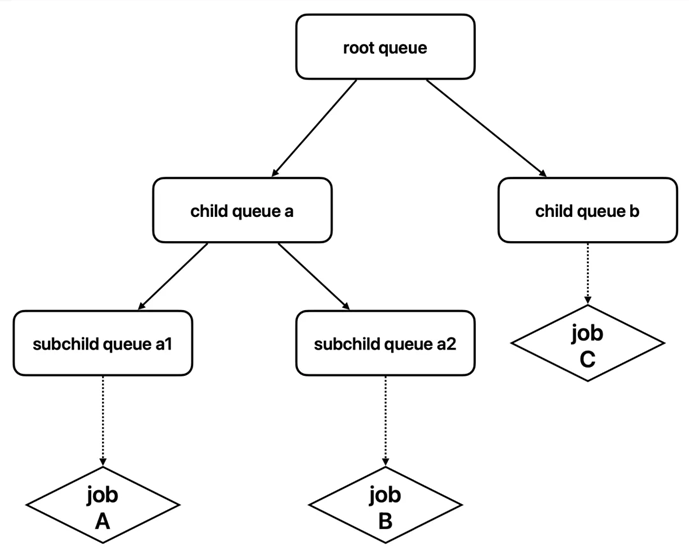
-
根队列:作为所有队列的父队列,负责全局资源的分配与管理。
-
部门队列:隶属于根队列,代表不同部门或团队的资源池。
-
子队列:隶属于部门队列,代表具体的项目或任务,用户可以将作业提交到叶子队列。
适用场景
-
多部门资源共享:在大型企业中,不同部门共享同一个集群,通过层级队列实现资源的公平分配与隔离。
-
大数据任务调度:从YARN迁移到Kubernetes的用户,可以利用Volcano的层级队列功能,无缝迁移大数据业务。
-
AI训练与推理:在AI场景中,不同训练任务或推理服务可以通过层级队列实现资源的动态分配与回收。
关于弹性层级队列详细设计与使用指导,请参考:
设计文档: hierarchical-queue-on-capacity-plugin[4]。
使用文档: Hierarchica Queue | Volcano[5]。
由衷感谢社区开发者: @Rui-Gan 对该特性的贡献!
▍多集群AI作业调度:跨集群的统一管理与高效调度
随着企业业务的快速增长,单个 Kubernetes 集群通常无法满足大规模 AI 训练和推理任务的需求。用户通常需要管理多个 Kubernetes 集群,以实现统一的工作负载分发、部署和管理。目前,已经有许多用户在多个集群中使用 Volcano,并使用 Karmada[6] 进行管理。为了更好地支持多集群环境中的 AI 任务,支持全局队列管理、任务优先级和公平调度等功能,Volcano 社区孵化了 Volcano Global[7]子项目。该项目将 Volcano 在单个集群中的强大调度能力扩展到多集群场景,为多集群 AI 任务提供统一的调度平台,支持跨集群任务分发、资源管理和优先级控制。
Volcano Global 在 Karmada 的基础上提供了以下增强功能,以满足多集群 AI 任务调度的复杂需求:
核心能力
Volcano Global在Karmada的基础上,提供了以下增强功能,满足多集群AI作业调度的复杂需求:
1. 支持Volcano Job的跨集群调度:用户可以在多集群环境中部署和调度Volcano Job,充分利用多个集群的资源,提升任务执行效率。
2. 队列优先级调度:支持跨集群的队列优先级管理,确保高优先级队列的任务能够优先获得资源。
3. 作业优先级调度与排队:在多集群环境中,支持作业级别的优先级调度和排队机制,确保关键任务能够及时执行。
4. 多租户公平调度:提供跨集群的多租户公平调度能力,确保不同租户之间的资源分配公平合理,避免资源争用。
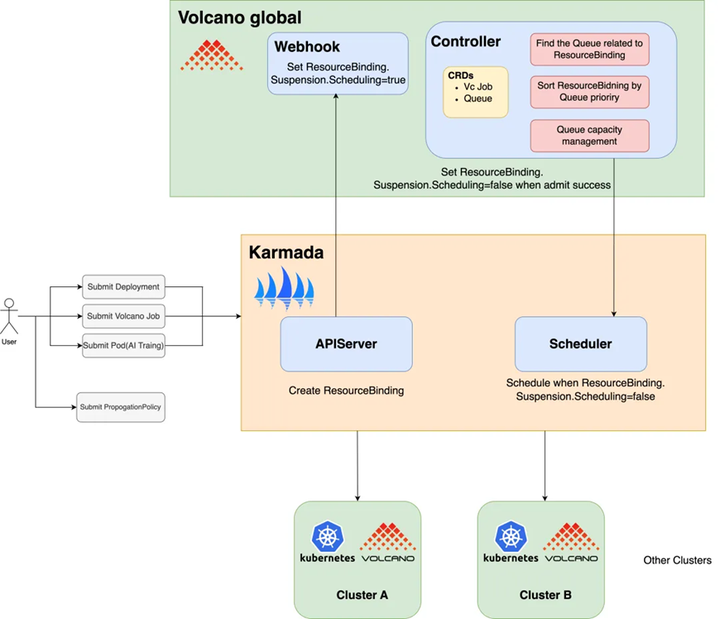
关于Volcano Global的详细部署和使用指导,请参考: Multi-Cluster AI Job Scheduling | Volcano[8]。
由衷感谢社区开发者: @Vacant2333, @MondayCha, @lowang-bh, @Monokaix 对该特性的贡献!
▍在离线混部与动态资源超卖:最大化资源利用率,保障业务稳定性
背景:资源利用率的挑战
随着云原生技术的快速发展,Kubernetes已成为云原生时代的“操作系统”,越来越多的业务迁移到Kubernetes平台。然而,尽管云原生技术带来了灵活性和可扩展性,数据中心的资源利用率仍然较低。在线业务(如微服务)通常具有明显的波峰波谷特征,在波谷时段,大量资源处于闲置状态,而在波峰时段,资源又可能不足。为了提升资源利用率并保障高优先级业务的SLO(Service Level Objective),Volcano推出了云原生混部解决方案,通过在离线混部与动态资源超卖,最大化集群资源利用率,同时确保在线业务的稳定性。
云原生混部的核心思想是将在线业务(如实时服务)和离线业务(如批处理任务)部署在同一个集群中。当在线业务处于波谷时,离线业务可以利用闲置资源;当在线业务达到波峰时,通过优先级控制压制离线业务,确保在线业务的资源需求。这种动态资源分配机制不仅提升了资源利用率,还保障了在线业务的服务质量。
业界实践:Volcano的独特优势
业界已有许多公司和用户对在离线混部技术进行了探索与实践,但仍存在一些不足,比如不能做到和Kubernetes完全解耦,超卖资源计算方式粗糙,在离线作业使用方式不一致、用户体验不友好等问题。基于这些问题,Volcano对在离线混部技术进行了深度优化,具备以下独特优势:
-
天然支持离线作业调度:Volcano Scheduler原生支持离线作业的调度与管理,无需额外适配。
-
无侵入式设计:对Kubernetes无侵入式修改,用户无需调整现有集群架构即可使用。
-
动态资源超卖:实时计算节点的可超卖资源,确保资源利用与业务QoS的平衡。
-
OS层面的隔离与保障:通过内核级别的资源隔离机制,确保在线业务的优先级和稳定性。
Volcano云原生混部解决方案:端到端的资源优化
Volcano的云原生混部解决方案从应用层到内核提供了端到端的资源隔离与共享机制,主要包括以下核心组件:
Volcano Scheduler:负责在离线作业的统一调度,提供队列、组、作业优先级、公平调度、资源预留等多种抽象,满足微服务、大数据、AI等多种业务场景的调度需求。
Volcano SLO Agent:每个节点上部署的SLO Agent实时监控节点的资源使用情况,动态计算可超卖的资源,并将这些资源分配给离线作业。同时,SLO Agent会检测节点的CPU/内存压力,在必要时驱逐离线作业,保障在线业务的优先级。
Enhanced OS:为了进一步强化资源隔离,Volcano在内核层面实现了精细化的QoS保障。通过cgroup接口,为在线和离线业务设置不同的资源限制,确保在线业务在高负载时仍能获得足够的资源。
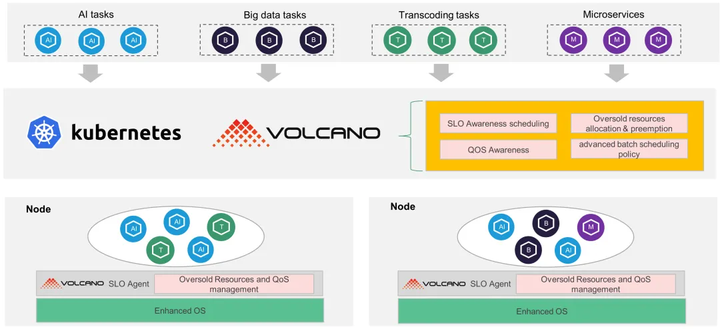
核心能力:资源利用与业务保障的双赢
Volcano云原生混部解决方案具备以下关键能力,帮助用户实现资源利用与业务稳定性的双赢:
-
统一调度:支持多种工作负载的统一调度,包括微服务、批处理作业和AI任务。
-
基于QoS的资源模型:为在线和离线业务提供基于服务质量(QoS)的资源管理,确保高优先级业务的稳定性。
-
动态资源超卖:根据节点的实时CPU/内存利用率,动态计算可超卖的资源,最大化资源利用率。
-
CPU Burst:允许容器临时超出CPU限制,避免在关键时刻被限流,提升业务响应速度。
-
网络带宽隔离:支持整机网络出口带宽限制,保障在线业务的网络使用需求。
关于Volcano云原生混部的详细设计和使用文档,请参考: Cloud Native Colocation | Volcano[9]。
由衷感谢社区开发者: @william-wang 对该特性的贡献!
▍负载感知重调度:智能均衡集群资源,告别资源热点
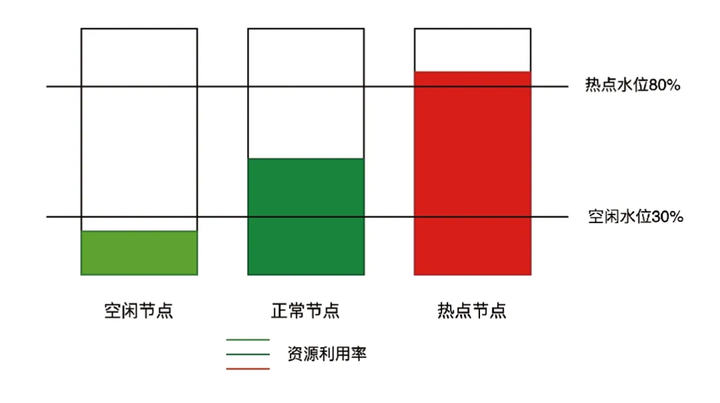
在Kubernetes集群中,随着工作负载的动态变化,节点资源利用率不均衡的问题时常发生,导致部分节点过热,影响整体集群的稳定性与效率。为了解决这一问题,Volcano v1.11 引入了负载感知重调度功能,基于节点的真实负载动态调整Pod分布,确保集群资源的均衡利用,避免资源热点,提升集群的整体性能与可靠性。负载感知重调度通过子项目 https://github.com/volcano-sh/descheduler 孵化。
核心能力:
-
真实负载感知调度:通过监控节点的CPU、内存等真实负载指标,动态调整Pod分布,避免仅依赖Pod Request的粗糙调度。
-
定时与动态触发:支持按CronTab定时任务或固定时间间隔触发重调度,灵活适应不同场景需求。
适用场景:
-
节点资源不均衡:当集群中部分节点资源利用率过高,而其他节点资源闲置时,负载感知重调度可自动平衡节点负载。
-
热点节点治理:当节点因高负载出现性能瓶颈或故障风险时,重调度可及时迁移Pod,保障业务稳定性。
技术亮点:
-
基于真实负载的重调度:相比传统的基于Pod Request的调度策略,Volcano的负载感知重调度更加精准,能够真实反映节点的资源使用情况。
-
无缝集成Kubernetes生态:与Kubernetes原生调度器兼容,无需额外配置即可实现负载感知重调度。
-
灵活的策略配置:用户可根据业务需求,自定义重调度的时间间隔或触发条件,确保调度的灵活性与可控性。
关于负载感知重调度的使用说明,请参考: Load-aware Descheduling | Volcano[10]
由衷感谢社区开发者: @Monokaix 对该特性的贡献!
▍细粒度的作业故障恢复策略:高效应对任务中断,提升训练效率
在AI、大数据和高性能计算(HPC)场景中,作业的稳定性和故障恢复能力至关重要。传统的作业故障恢复策略通常会在某个Pod失败时重启整个Job,这不仅浪费资源,还可能导致训练任务从头开始,严重影响效率。随着AI场景中断点续训和Checkpoint 技术的普及,单个Pod的失败不再需要重启整个Job。为此,Volcano v1.11 引入了细粒度的作业故障恢复策略,支持更灵活的故障处理机制,帮助用户高效应对任务中断,显著提升训练效率。
核心能力:
支持Pod粒度的重启策略
用户可以根据需求,设置仅重启失败的Pod或所属的Task,避免不必要的Job重启,减少资源浪费。
重启单个Pod:当某个Pod失败时,仅重启该Pod,不影响其他正常运行的任务。
policies: - event: PodFailedaction: RestartPod
重启整个Task:当某个Pod失败时,重启该Pod所属的Task(一组Pod),适用于需要保持任务组一致性的场景。
policies: - event: PodFailedaction: RestartTask
支持为 Action 设置超时时间
Pod失败可能是由临时性故障(如网络抖动或硬件问题)引起的,Volcano允许用户为故障恢复动作设置超时时间。如果在超时时间内Pod恢复正常,则不再执行重启操作,避免过度干预。
示例配置:若Pod失败后重启,10分钟内仍未恢复,则重启整个Job。
policies: - event: PodFailedaction: RestartPod - event: PodEvictedaction: RestartJobtimeout: 10m
新增PodPending事件处理
当Pod因资源不足或拓扑约束长期处于Pending状态时,用户可以为Pending事件设置超时时间。若超时后Pod仍未运行,则可以选择终止整个Job,避免资源浪费。
示例配置:若Pod处于Pending状态超过10分钟,则终止Job。
policies: - event: PodPendingaction: TerminateJobtimeout: 10m
适用场景:
-
AI大模型训练:在分布式训练中,单个Pod的失败不会影响整体训练进度,通过细粒度的故障恢复策略,可以快速恢复任务,避免从头开始训练。
-
大数据处理:在批处理任务中,部分任务的失败可以通过重启单个Pod或Task解决,无需重启整个作业,提升处理效率。
-
高性能计算:在HPC场景中,任务的稳定性和高效恢复至关重要,细粒度的故障恢复策略可以最大限度地减少任务中断时间。
技术亮点:
-
灵活的策略配置:用户可以根据业务需求,自定义故障恢复策略,支持Pod、Task和Job级别的重启操作。
-
超时机制:通过设置超时时间,避免因临时性故障导致的过度重启行为,提升作业的稳定性。
-
无缝兼容断点续训:与AI场景中的断点续训和Checkpoint技术完美结合,确保训练任务的高效恢复。
关于Volcano Job的详细设计和说明文档,请参考: How to use job policy[11]。
由衷感谢社区开发者: @bibibox 对该特性的贡献!
▍Volcano Dashboard:资源管理的可视化利器
Volcano dashboard是Volcano官方提供的资源展示仪表盘,用户在部署Volcano后,再部署Volcano dashboard,就可以通过图形界面展示集群中Volcano相关的资源,方便用户查询和操作,项目地址: https://github.com/volcano-sh/dashboard。
目前支持的功能有:
-
支持查看集群总览,包括Job数量、状态、完成率,Queue数量,Queue的资源利用率等。
-
支持查看Job列表和详情,支持模糊搜索匹配,支持按照Namespace、Queue、Status等条件过滤,支持Job排序展示。
-
支持查看Queue列表和详情,支持模糊搜索匹配,支持按照Status等条件过滤,支持Queue排序展示。
-
支持查看Pod的列表和详情,支持模糊搜索匹配,支持按照Namespace、Status等条件过滤,支持Pod排序展示。
由衷感谢社区开发者: @WY-Dev0, @Monokaix 对该特性的贡献!
▍Volcano支持Kubernetes v1.31
Volcano版本紧跟Kubernetes社区版本节奏,对Kubernetes的每个大版本都进行支持,目前最新支持的版本为v1.31,并运行了完整的UT、E2E用例,保证功能和可靠性。如果您想参与Volcano适配Kubernetes新版本的开发工作,
请参考:adapt-k8s-todo[12]进行社区贡献。
由衷感谢社区开发者: @vie-serendipity, @dongjiang1989 对该特性的贡献!
▍Volcano Job支持Preemption Policy
PriorityClass可以表示Pod的优先级,包含一个优先级数值和抢占策略,在调度和抢占的过程中,PriorityClass会被用来作为调度和抢占的依据,高优先级的Pod先于低优先级Pod调度,并且可以抢占低优先级的Pod,Volcano在Pod层面完整支持优先级调度和抢占策略,在Volcano Job层面支持基于priorityClass value的优先级调度和抢占。但在某些场景下,用户希望Volcano Job不通过抢占触发资源回收,而是等待集群资源自动释放,从而整体保障业务稳定性,Volcano在新版本支持了Job级别的PreemptionPolicy,配置了PreemptionPolicy为Never的Volcano Job不会抢占其他Pod。
Volcano Job和Job内的task同时支持配置PriorityClass,关于两个PriorityClass的配合关系以及配置样例请参考: how to configure priorityclass for job[13]。
由衷感谢社区开发者: @JesseStutler 对该特性的贡献!
▍性能优化:大规模场景下的高效调度
在Volcano中,Queue是最基本且最重要的资源之一。Queue的 status 字段记录了其中状态为 Unknown、Pending、Running、Inqueue、Completed的PodGroup。然而,在大规模场景下,当队列中的PodGroup频繁发生变化时(例如,队列中循环提交大量运行时间较短的任务),会导致大量PodGroup状态从 Running 变为 Completed。这种情况下,Volcano Controller需要频繁刷新Queue的 status 字段,给APIServer带来较大压力。此外,Volcano Scheduler在Job调度完成后会更新Queue的 status.allocated 字段,这在大规模场景下可能导致Queue更新冲突,进一步影响系统性能。
为了彻底解决大规模场景下Queue频繁刷新和更新冲突的问题,Volcano v1.11 对Queue的管理机制进行了优化,将Queue中PodGroup的统计数据迁移到指标(Metrics)中,不再进行持久化存储。这一优化显著降低了APIServer的压力,同时提升了系统的整体性能和稳定性。
优化后的核心改进
PodGroup统计数据迁移到指标Queue中的PodGroup状态数据(如Unknown、Pending、Running等)不再存储在Queue的 status 字段中,而是通过指标系统进行记录和展示。用户可以通过以下命令查看Queue中PodGroup的统计数据:
-
查看指定队列的统计数据:
vcctl queue get -n [name]
-
查看所有队列的统计数据:
vcctl queue list
减少APIServer压力通过将PodGroup统计数据迁移到指标中,避免了频繁更新Queue的status字段,显著降低了APIServer的负载,提升系统吞吐。
解决Queue更新冲突在大规模场景下,Queue的更新冲突问题得到了有效缓解,确保了调度器的高效运行。
关于Queue中PodGroup的状态统计数据迁移到指标的详细设计以及指标名称,请参考: Queue podgroup statistics[14]。
由衷感谢社区开发者: @JesseStutler 对该特性的贡献!
总结:Volcano v1.11,云原生批量计算的新标杆
Volcano v1.11不仅是技术的飞跃,更是云原生批量计算领域的全新标杆。无论是AI大模型训练、大数据调度,还是资源利用率的提升,Volcano v1.11都提供了强大的功能和灵活的解决方案。我们相信,Volcano v1.11将帮助用户在云原生批量计算领域走得更远、更稳,开启AI与大数据的云原生调度新纪元!
立即体验Volcano v1.11.0,开启高效计算新时代!
v1.11.0 release: https://github.com/volcano-sh/volcano/releases/tag/v1.11.0
致谢贡献者
Volcano v1.11.0 版本包含了来自39位社区贡献者的上百次代码提交,在此对各位贡献者表示由衷的感谢,贡献者GitHub ID:
参考资料
[1] Volcano v1.11.0 release: https://github.com/volcano-sh/volcano/releases/tag/v1.11.0
[2] Network Topology Aware Scheduling: https://volcano.sh/en/docs/network_topology_aware_scheduling/
[3] Network Topology Aware Scheduling | Volcano: https://volcano.sh/en/docs/network_topology_aware_scheduling/
[4] hierarchical-queue-on-capacity-plugin: https://github.com/volcano-sh/volcano/blob/master/docs/design/hierarchical-queue-on-capacity-plugin.md
[5] Hierarchica Queue | Volcano: https://volcano.sh/zh/docs/hierarchical_queue/
[6] Karmada: https://karmada.io/
[7] Volcano Global: https://github.com/volcano-sh/volcano-globa
[8] Multi-Cluster AI Job Scheduling | Volcano: https://volcano.sh/en/docs/multi_cluster_scheduling/
[9] Cloud Native Colocation | Volcano: https://volcano.sh/en/docs/colocation/
[10] Load-aware Descheduling | Volcano: https://volcano.sh/en/docs/descheduler/
[11] How to use job policy: https://github.com/volcano-sh/volcano/blob/master/docs/user-guide/how_to_use_job_policy.md
[12] adapt-k8s-todo: https://github.com/volcano-sh/volcano/blob/master/docs/design/adapt-k8s-todo.md
[13] how to configure priorityclass for job: https://github.com/volcano-sh/volcano/blob/master/docs/user-guide/how_to_configure_priorityclass_for_job.md
[14] Queue podgroup statistics: https://github.com/volcano-sh/volcano/blob/master/docs/design/podgroup-statistics.md
点击关注,第一时间了解华为云新鲜技术~