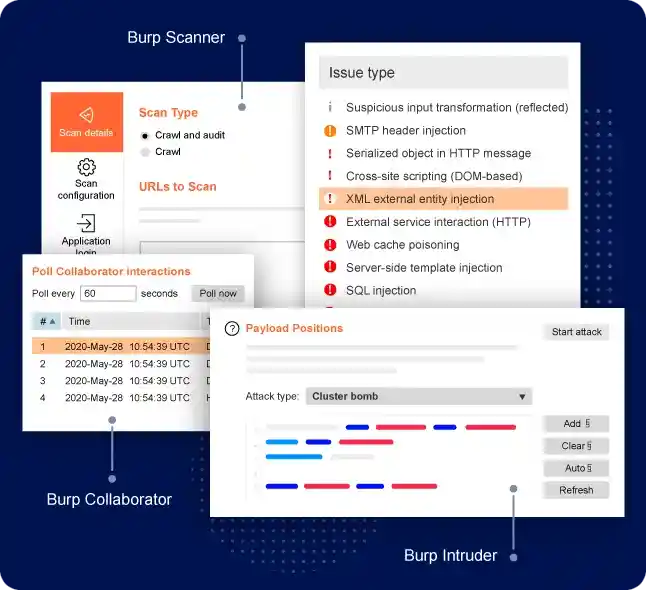
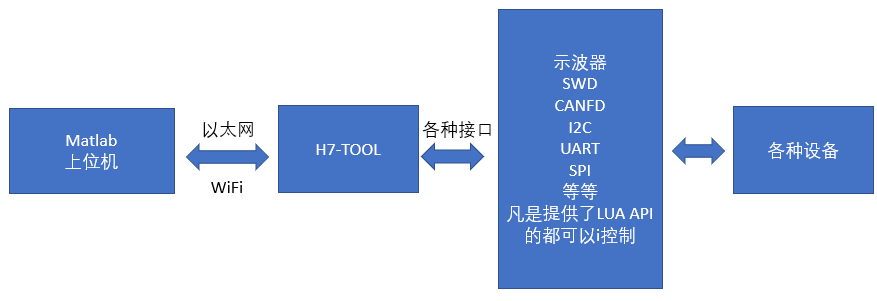
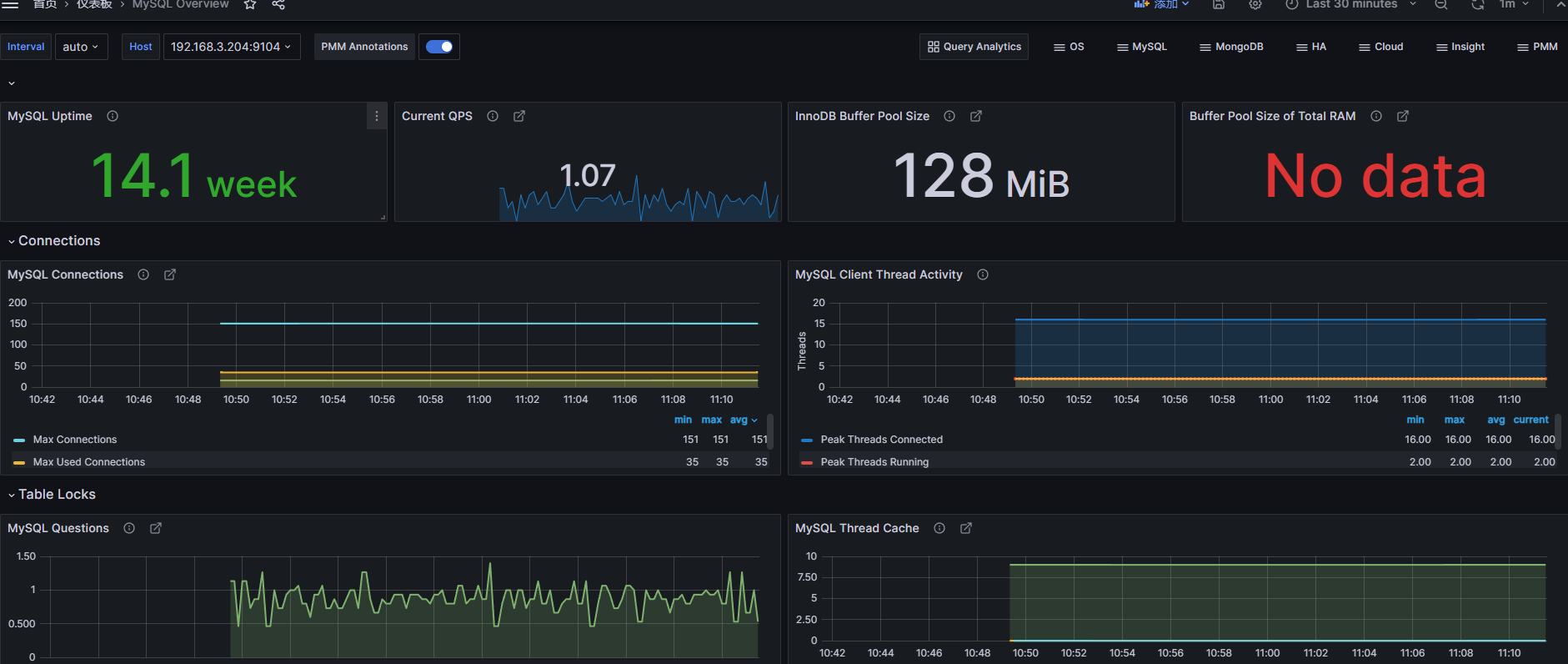
当然!这张图片清晰地展示了 GPT Assistant (如 ChatGPT, Claude 等) 的训练流程,我们来深入理解一下其中的知识点:
1. 训练阶段 (Training Stages)
-
预训练 (Pretraining):
- 数据集: 使用从互联网上收集的大量原始文本数据 (数万亿字),包括各种主题、风格和语言。这些数据通常质量参差不齐,但数量庞大。
- 算法: 采用语言模型 (Language Modeling) 算法,核心目标是预测下一个词 (predict the next token)。
- 模型: 训练出一个基础模型 (Base Model),如 GPT, LLAMA, PaLM 等。这个模型拥有强大的语言理解和生成能力,但可能不够“听话”,需要后续的微调。
- 资源: 预训练需要大量的计算资源 (数千个 GPU) 和时间 (数月)。
-
监督微调 (Supervised Finetuning, SFT):
- 数据集: 使用高质量的prompt-response对,即“理想的助手回复” (Ideal Assistant responses)。这些数据通常由人工编写,数量较少 (数万到数十万),但质量很高。
- 算法: 仍然是语言模型算法,但目标是让模型学习人类偏好的回复方式。
- 模型: 在预训练模型的基础上进行微调,得到一个监督微调模型 (SFT Model)。这个模型在生成回复时会更符合人类的期望。
- 资源: 微调所需的计算资源和时间比预训练少得多 (数十到数百个 GPU,数天)。
-
奖励建模 (Reward Modeling, RM):
- 数据集: 使用人类对模型回复的偏好数据,即“比较” (Comparisons)。这些数据通常由人工标注,数量在数十万到数百万之间。
- 算法: 使用二元分类 (Binary classification) 算法,训练一个奖励模型 (RM Model)。这个模型能够预测哪个回复更符合人类的偏好。
- 模型: 奖励模型用于指导后续的强化学习过程。
- 资源: 训练奖励模型所需的计算资源和时间与监督微调类似。
-
强化学习 (Reinforcement Learning, RL):
- 数据集: 使用大量的prompt,让模型生成回复,并用奖励模型对回复进行评分。
- 算法: 使用强化学习算法,如 PPO (Proximal Policy Optimization),训练一个强化学习模型 (RL Model)。这个模型的目标是生成能够最大化奖励的回复。
- 模型: 强化学习模型是最终部署的模型,如 ChatGPT, Claude 等。
- 资源: 强化学习所需的计算资源和时间也相对较少。
2. 关键概念
- Prompt: 用户输入的指令或问题。
- Token: 文本的基本单位,可以是词、子词或字符。
- 语言模型: 一种预测下一个词的算法,是 GPT Assistant 的核心。
- 二元分类: 一种判断两个选项哪个更优的算法。
- 强化学习: 一种通过试错来学习的算法。
3. 总结
这张图片清晰地展示了 GPT Assistant 的训练流程,从原始文本到最终部署的模型,经历了多个阶段的微调和优化。每个阶段都使用了不同的数据集、算法和模型,最终使得 GPT Assistant 能够生成高质量、符合人类偏好的回复。
希望以上分析能帮助您更深入地理解这张图片,以及 GPT Assistant 的训练过程。如果您有任何疑问,欢迎继续提问!