RTL 设计工程中遇到一种怪像:虽然可用的人手很多,但很难将任务拆分分配下去,导致人力出现紧张。将原因归因于下:
- RTL 代码可读性差 抛一个仓库让成员从源码中理解难度颇高。往往需要配合辅助的文档以及频繁对接,这极大分散顶层开发架构师的精力;
- 控制模块耦合性强 组合逻辑比如计算单元易于解耦,控制逻辑则复杂得多。各个模块负责的功能如果工作时间不重叠,大都可以用 ready-valid 接口解耦划分,但更多模块之间存在耦合关系,需要对顶层交互有认知,但这违背分工原则和第一点;
- 硬件持续开发困难 硬件工程周期较长,为了缩短工期往往采用一定程度的迭代开发,即各个阶段(创新点、算法研究、软件栈开发、原型验证、SPEC 架构、RTL 实现、验证)之间存在重叠,在某些时间点往往几条线在并行进行,之间互相反馈修正迭代。但当出现新需求进行变更时,由于系统的高度耦合,需要顶层架构师介入将需求变更描述细化到底层逻辑变化,使得架构师的工作时间被异步的消息交互打断,同时接口的逻辑的变更又给分工成员带来非常多纯工程的 dirty work ,又或者常常每个人分工下去最后发现根本无法拼在一起,需要重新划分模块。
最大的帮助是需要一个极具经验的架构师,在工程正式开始前花费相当多的时间整理从软硬件对整个架构进行规划描述,写好 SPEC 分工,但纯瀑布式分工不可能,持续开发问题或多或少影响。本文尝试建模解释为何硬件开发难以分工。
数据控制通路划分
我将处理器定义为 “在某些时间点,根据某些输入,让某些信号出现某种值”,即一个函数映射 \(F(x,t) \rightarrow y\),x 是接口输入,t 是时间,y 是电路中所有输出信号。
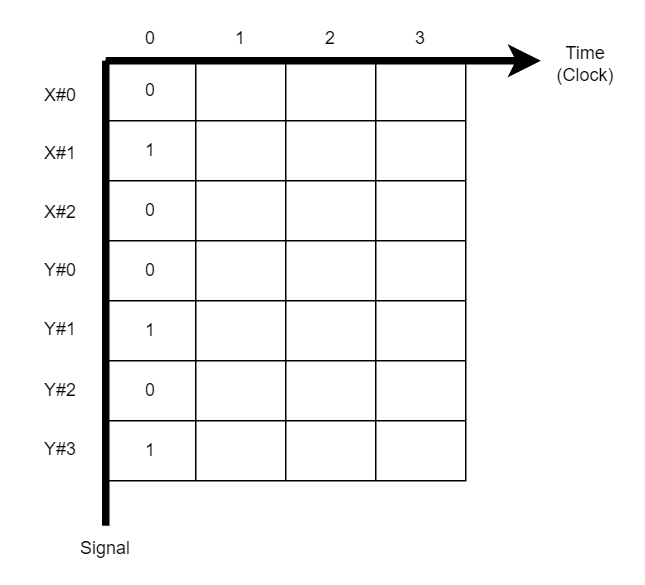
电路用寄存器捕捉时间,并且由于电路资源有限,无法处理任意长度和粒度的时间,将某些时间点聚类成为了状态,状态是由时间构成的集合 \(s=\{x \in T\}\) 。比如一个处理流程,\(t=\{0,1,2\}\) 是起始状态 IDLE,\(t=\{3,4,5,6,7\}\) 是运行状态 RUN,\(t=\{8,9\}\) 是结束恢复状态 END。同时状态之间的切换并非类似时间的单向序列,转换过程用图结构定义描述。此时便是 Mealy State Machine,包含输出方程 \(F(x,s) \rightarrow y\) 和状态转移方程 \(G(x,s) \rightarrow s\)。
状态信号和其他信号有本质不同,状态信号是由时间演变过来,时间在同一时刻只有一个(什么废话),所以在同一时刻只有一个状态,而控制信号在同一时刻可以有多个存在。可电路中不是往往有很多状态机吗?可以同时存在状态 A 和状态 B ?这种情况应将状态 A 和状态 B 拼接(Concat)视为整体的状态。
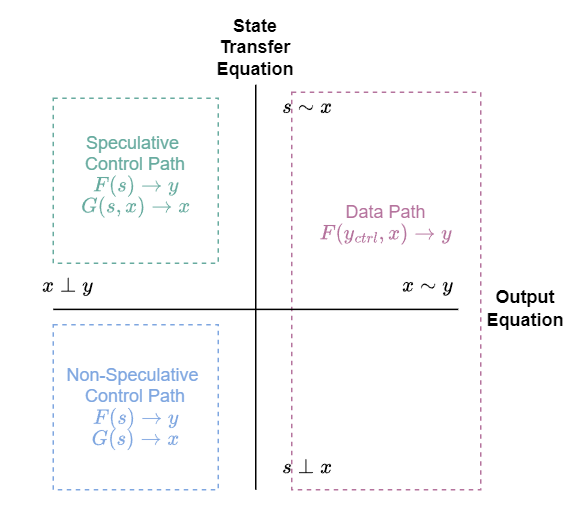
对输出方程进一步进行划分,如果输出方程仅和状态 \(s\) 有关即 \(F(s) \rightarrow y\) ,这样的输出信号 \(y\) 称作控制信号,输出控制信号的电路称作控制模块,控制模块组成的电路连接是控制通路;否则称作数据通路,即 \(F(x,s) \rightarrow y\)。
将电路进一步解耦,将数据通路状态的表征完全使用控制通路的输出 \(y_{ctrl}\) 表示,解耦状态到数据通路的直接控制。这只是工程上的划分,数学和前面公式等价:
经过这样划分,数据通路的实现和状态完全无关,仅在控制通路中包含状态机。
对控制通路转移方程进行考虑,如果转移方程和 \(x\) 有关 \(G(x,s) \rightarrow s\) ,称作 Speculative 或者动态控制,反之 \(G(s) \rightarrow s\) 则是静态控制。
耦合的控制模块
经过上述划分,形成了 (State) -> Ctrl Path -> (Ctrl Signal) -> Data Path 的结构,把控制通路和数据通路去耦合。但这种分析单纯划分为了数据通路和控制通路,还需要对每种模块进一步层层细分(垂直的parent-children节点,以及平行的peer节点),每次细分的接口用什么逻辑划分?
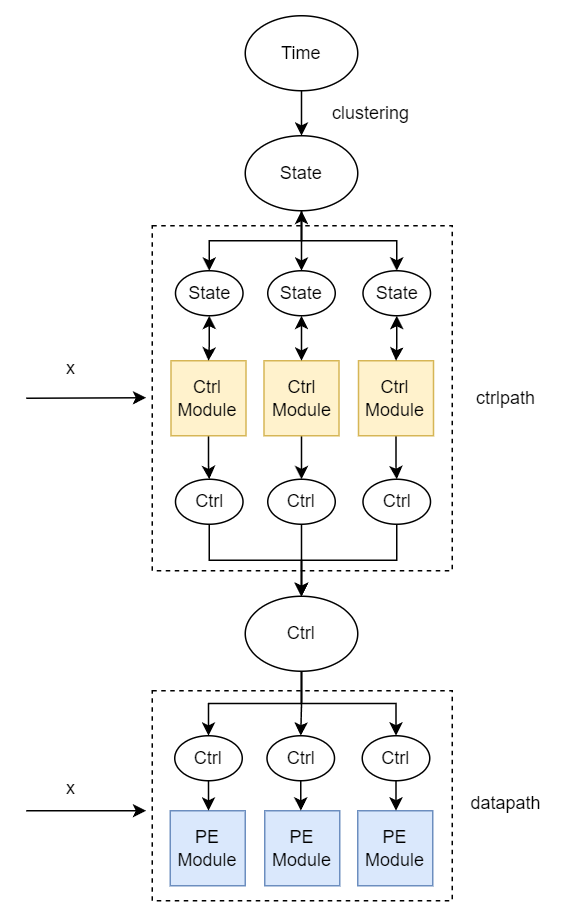
控制通路由于连接 State 和 Ctrl Signal 两种接口,往往耦合关系最为复杂。控制通路的输出方程表示如下图:
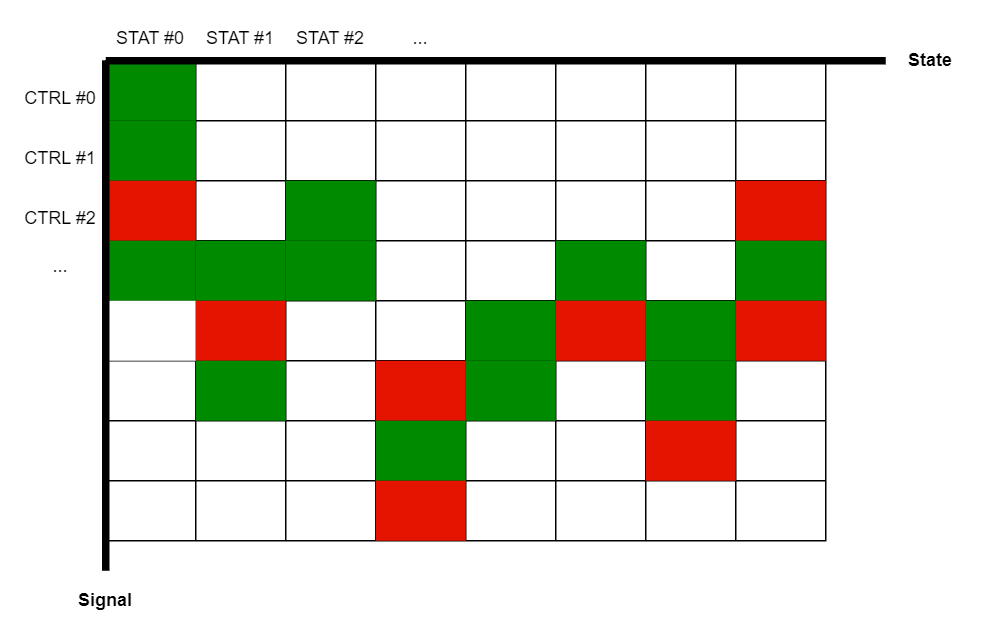
这是一个二维的查找表,划分模块的过程就是将这个表格切割为子表,也就是从 状态-控制信号 两个维度分别做切分。状态维度的逻辑是状态转移图,而控制信号逻辑是受控单元。
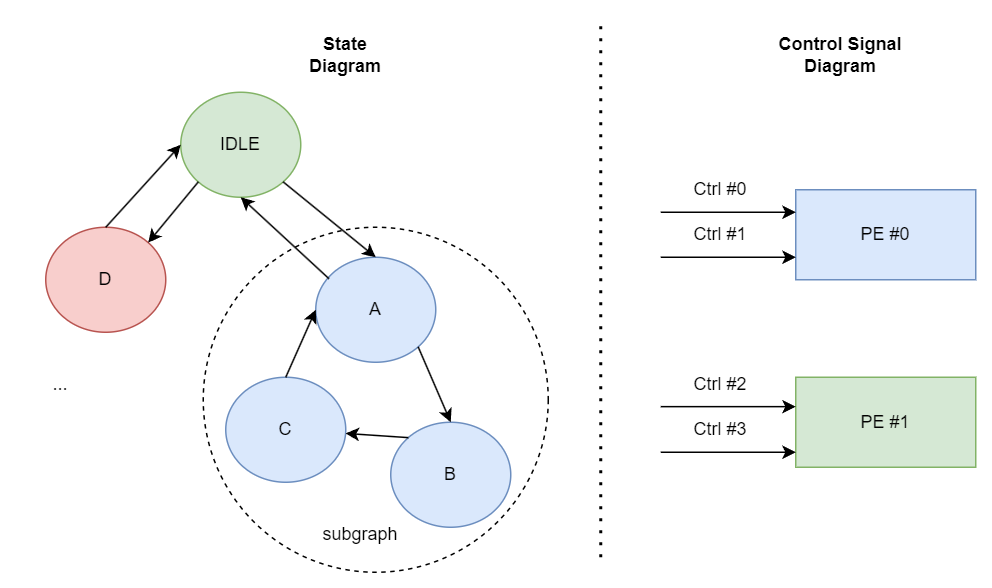
从整体的输出方程到划分后的过程还不是很明晰。举个例子,假设系统中有:
- 两个数据通路模块,计算模块和存储模块,每次工作,都需要经过待机(00)-启动(10)-工作(11)-启动(10)-待机(00)这一串控制信号,他们的控制信号分别是 \(y_{com}, y_{ram}\),各为 2 bit;
- 这两个模块分别有两个控制模块:计算控制和存储控制,他们的状态分别是 \(s_{com},s_{ram}\),也同样各为 2 bit,为了简化,状态到控制信号之间的映射是恒等映射,也存在待机(00)、启动(10)、工作(11)三种状态,以及一个非法状态 01;
- 系统需要有这些功能:
- 计算:计算和存储模块都工作,假设两个模块的启动、工作信号需要同步给出;
- 数据传输:存储模块工作,计算模块不工作;
- 待机:计算和存储都不工作;
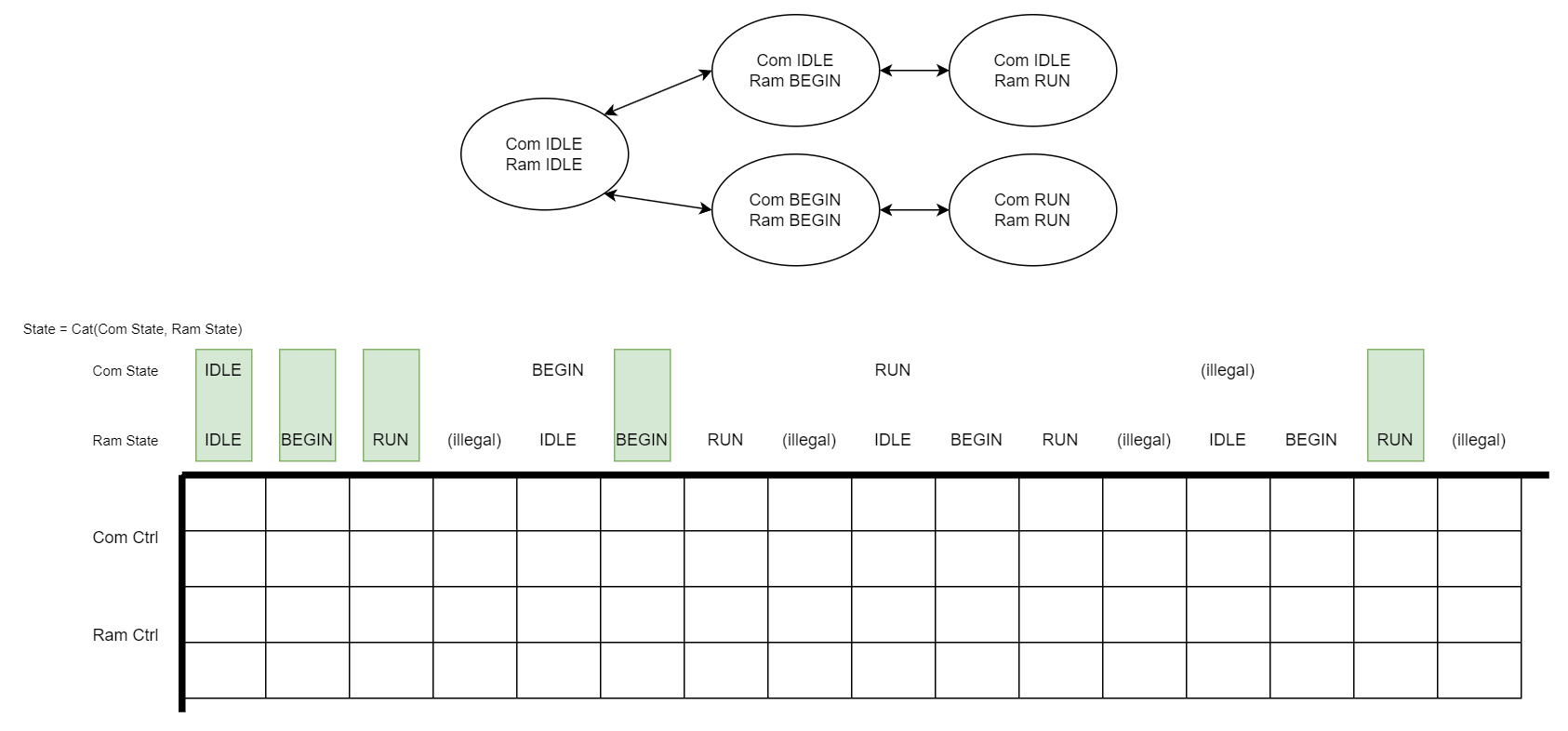
系统的输出方程以及状态转移方程如图所示,实际系统 16 个状态中只有 5 个合法。从建立系统的过程中知道可以将总控制模块划分为一个计算控制和一个存储控制,然后再产生一个顶层控制用额外的控制信号控制这两个控制模块,形成 (State) -> Top Ctrl -> (Ctrl) -> Sub Ctrl -> (Ctrl) -> Data Path 的层次结构。但假如我们一开始就拿到这个总的状态机,该如何判断推导出可以划分系统模块呢?也就是如何从 4 bit 中找到划分后 2 个 2 bit 的状态?
划分的依据是状态bit之间的不相关:
- 状态转移方程前后继和其余状态bit无关 [1]:对于状态变量中的某几个bit \(s_{sub}\),其前继后继状态和其余bit \(s_{complement}\) 无关。即对于任意 \(s_{sub}\) 的一个取值,任取 \(s_{complement}\) 的一个状态,其状态方程变化后的状态 \(s'_{sub}\) 相等;
- 输出方程和其余状态bit无关:对于控制信号中某几个bit \(y_{sub}\),存在状态变量中某几个 bit \(s_{sub}\) ,其控制信号的结果与其余bit \(s_{complement}\) 无关。即对于任意 \(s_{complement}\) 的一个状态,控制信号 \(y_{sub}\) 相等。
以上两个不相关性判据可以用数学描述,进而被系统自动化寻找。每次根据两个方程验证,得到一对状态-控制划分对 \(\{s_{sub}, y_{sub}\}\) 。最后得到一个这样的划分对集合,从集合中取任意数量的状态-控制对出来,若他们之间的 \(s_{sub}\) 和 \(y_{sub}\) 互相没有交集,即可以顺利剥离成子模块;否则还要引入额外的 MUX 和相应额外的控制信号,这种划分并不自然。
通过划分会改变系统复杂度,比如这个例子中由于本身系统较简单,划分成两个控制反而要处理的状态变多了,可见如何划分能够极大影响整个系统工程量。但划分是 NP 问题,所以模块划分完全靠架构师的经验能力。本身控制通路通过状态、控制信号两个维度划分,两个维度划分逻辑并不完全一致,设计中往往是根据具体情况由架构师将两个维度耦合关系找出来,减低系统复杂度。
假设每个模块由某几个人负责,接口变更(状态、控制变量)不仅仅会导致单纯接口添加减少,进而会导致模块划分发生变动,所以考虑持续开发控制模块很难提前固定好细粒度地划分模块,只能根据经验在粗粒度层面进行划分模块保证不会发生变动,但粗粒度导致工程量增大,需要负责人较长时间的投入,也就是在项目早期就要固定几个成员负责某些模块,若考虑哪里变动去哪里救火分工则会非常难办。
这可能是个必要条件而非充分。 ↩︎