大模型的商业化落地挑战
更好地控制大模型生成:
- 生成
- 优点:内容的多样性、创造性
- 缺点:存在不可控制的问题
- 检索
- 优点:可控
- 缺点:内容具有局限性
结合两者:检索增强生成(Retrieval-Augmented Generation, RAG)
案例:金融智能客服系统的几种思路
- 专家系统
- 生成式模型
- 大模型检索增强
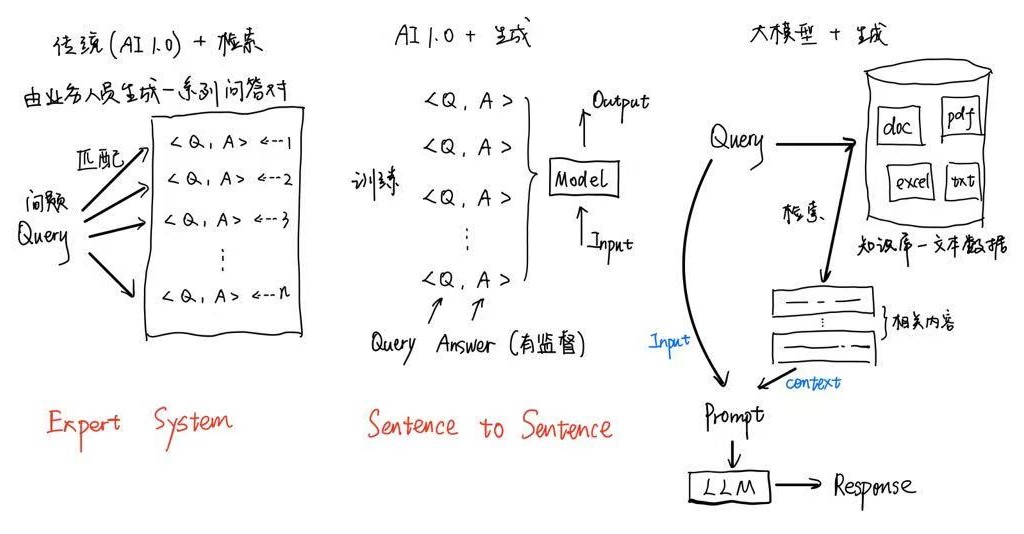
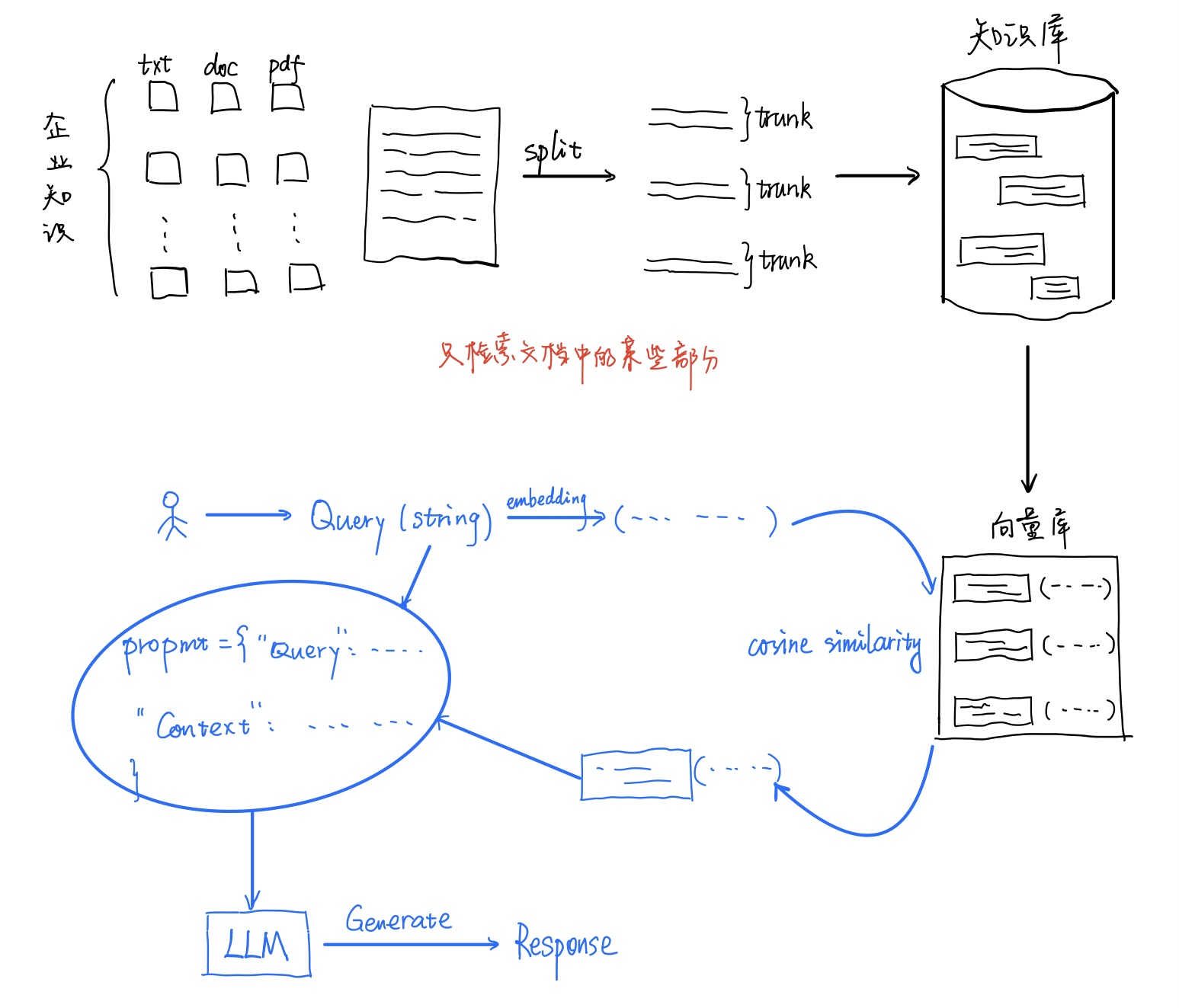
基于文档的LLM回复系统搭建思路
目前,RAG不能完全解决hallucination(幻觉,一个很fancy但是逼气很重的名词)问题:
- 检索准确率受限
- LLM理解能力有限
- 问题的复杂度
- 错位在以上步骤中累积
文档分割
- 根据句子来切分
- 按照字符数来切分
- 按固定字符数,但结合
overlapping window - 递归方法:
RecursiveCharacterTextSplitter - 根据语义来分割
英文情形
Split by Sentence
import nltk
from nltk.tokenize import sent_tokenizetext = ("The Earth's atmosphere is composed of layers, including the troposphere, ""stratosphere, mesosphere, thermosphere, and exosphere. The troposphere is ""the lowest layer where all weather takes place and contains 75% of the atmosphere's mass. ""Above this, the stratosphere contains the ozone layer, which protects the Earth ""from harmful ultraviolet radiation.")# Split the text into sentences
chunks = sent_tokenize(text)for i, chunk in enumerate(chunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 127: The Earth's atmosphere is composed of layers, including the troposphere, stratosphere, mesosphere, thermosphere, and exosphere.
块 2: 108: The troposphere is the lowest layer where all weather takes place and contains 75% of the atmosphere's mass.
块 3: 115: Above this, the stratosphere contains the ozone layer, which protects the Earth from harmful ultraviolet radiation.
这里使用
nltk_data是手动下载的。
Fixed_length_chunks
def fixed_length_chunks(text, chunk_size):return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]chunks = fixed_length_chunks(text, 100) # 假设我们想要100个字符的块for i, chunk in enumerate(chunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 100: The Earth's atmosphere is composed of layers, including the troposphere, stratosphere, mesosphere, t
块 2: 100: hermosphere, and exosphere. The troposphere is the lowest layer where all weather takes place and co
块 3: 100: ntains 75% of the atmosphere's mass. Above this, the stratosphere contains the ozone layer, which pr
块 4: 52: otects the Earth from harmful ultraviolet radiation.
Chunks with overlapping window
def sliding_window_chunks(text, chunk_size, stride):return [text[i:i+chunk_size] for i in range(0, len(text), stride)]chunks = sliding_window_chunks(text, 100, 50) # 100个字符的块,步长为50for i, chunk in enumerate(chunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 100: The Earth's atmosphere is composed of layers, including the troposphere, stratosphere, mesosphere, t
块 2: 100: uding the troposphere, stratosphere, mesosphere, thermosphere, and exosphere. The troposphere is the
块 3: 100: hermosphere, and exosphere. The troposphere is the lowest layer where all weather takes place and co
块 4: 100: lowest layer where all weather takes place and contains 75% of the atmosphere's mass. Above this, t
块 5: 100: ntains 75% of the atmosphere's mass. Above this, the stratosphere contains the ozone layer, which pr
块 6: 100: he stratosphere contains the ozone layer, which protects the Earth from harmful ultraviolet radiatio
块 7: 52: otects the Earth from harmful ultraviolet radiation.
块 8: 2: n.
RecursiveCharacterTextSplitter from langchain
from langchain.text_splitter import RecursiveCharacterTextSplittertext = '''The Earth's atmosphere is a layer of gases surrounding the planet Earth and retained by Earth's gravity.
It contains roughly 78% nitrogen and 21% oxygen, with trace amounts of other gases.
The atmosphere protects life on Earth by absorbing ultraviolet solar radiation and reducing temperature extremes between day and night.
'''splitter = RecursiveCharacterTextSplitter(chunk_size = 150,chunk_overlap = 20,length_function = len,
)
trunks = splitter.split_text(text)
for i, chunk in enumerate(trunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 104: The Earth's atmosphere is a layer of gases surrounding the planet Earth and retained by Earth's gravity.
块 2: 83: It contains roughly 78% nitrogen and 21% oxygen, with trace amounts of other gases.
块 3: 135: The atmosphere protects life on Earth by absorbing ultraviolet solar radiation and reducing temperature extremes between day and night.
中文情形
按照sentence来切分
通过正则表达式,将句子末尾的标点符号识别并划分开来。
import retext = "在这里,我们有一段超过200字的中文文本作为输入例子。这段文本是关于自然语言处理的简介。自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,它旨在让计算机能够理解和处理人类语言。在这一领域中,机器学习技术扮演着核心角色。通过使用各种算法,计算机可以解析、理解、甚至生成人类可以理解的语言。这一技术已广泛应用于机器翻译、情感分析、自动摘要、实体识别等多个方面。随着深度学习技术的发展,自然语言处理的准确性和效率都得到了显著提升。当前,一些高级的NLP系统已经能够完成复杂的语言理解任务,例如问答系统、语音识别和对话系统等。自然语言处理的研究不仅有助于改善人机交互,而且对于提高机器的自主性和智能化水平也具有重要意义。"
# 正则表达式匹配中文句子结束的标点符号
sentences = re.split(r'(。|?|!|\…\…)', text)
# 重新组合句子和结尾的标点符号
chunks = [sentence + (punctuation if punctuation else '') for sentence, punctuation in zip(sentences[::2], sentences[1::2])]
for i, chunk in enumerate(chunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 27: 在这里,我们有一段超过200字的中文文本作为输入例子。
块 2: 17: 这段文本是关于自然语言处理的简介。
块 3: 51: 自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,它旨在让计算机能够理解和处理人类语言。
块 4: 21: 在这一领域中,机器学习技术扮演着核心角色。
块 5: 34: 通过使用各种算法,计算机可以解析、理解、甚至生成人类可以理解的语言。
块 6: 35: 这一技术已广泛应用于机器翻译、情感分析、自动摘要、实体识别等多个方面。
块 7: 34: 随着深度学习技术的发展,自然语言处理的准确性和效率都得到了显著提升。
块 8: 47: 当前,一些高级的NLP系统已经能够完成复杂的语言理解任务,例如问答系统、语音识别和对话系统等。
块 9: 47: 自然语言处理的研究不仅有助于改善人机交互,而且对于提高机器的自主性和智能化水平也具有重要意义。
按照固定字符数切分
def split_by_fixed_char_count(text, count):return [text[i:i+count] for i in range(0, len(text), count)]# 假设我们按照每100个字符来切分文本
chunks = split_by_fixed_char_count(text, 100)
for i, chunk in enumerate(chunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 100: 在这里,我们有一段超过200字的中文文本作为输入例子。这段文本是关于自然语言处理的简介。自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,它旨在让计算机能够理解和处理人类语言。在这一领域
块 2: 100: 中,机器学习技术扮演着核心角色。通过使用各种算法,计算机可以解析、理解、甚至生成人类可以理解的语言。这一技术已广泛应用于机器翻译、情感分析、自动摘要、实体识别等多个方面。随着深度学习技术的发展,自然语
块 3: 100: 言处理的准确性和效率都得到了显著提升。当前,一些高级的NLP系统已经能够完成复杂的语言理解任务,例如问答系统、语音识别和对话系统等。自然语言处理的研究不仅有助于改善人机交互,而且对于提高机器的自主性和
块 4: 13: 智能化水平也具有重要意义。
按照固定sentence数切分
def split_by_fixed_sentence_count(sentences, count):return [sentences[i:i+count] for i in range(0, len(sentences), count)]# 假设我们按照每5个句子来切分文本
chunks = split_by_fixed_sentence_count(sentences, 5)for i, chunk in enumerate(chunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 5: ['在这里,我们有一段超过200字的中文文本作为输入例子', '。', '这段文本是关于自然语言处理的简介', '。', '自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,它旨在让计算机能够理解和处理人类语言']
块 2: 5: ['。', '在这一领域中,机器学习技术扮演着核心角色', '。', '通过使用各种算法,计算机可以解析、理解、甚至生成人类可以理解的语言', '。']
块 3: 5: ['这一技术已广泛应用于机器翻译、情感分析、自动摘要、实体识别等多个方面', '。', '随着深度学习技术的发展,自然语言处理的准确性和效率都得到了显著提升', '。', '当前,一些高级的NLP系统已经能够完成复杂的语言理解任务,例如问答系统、语音识别和对话系统等']
块 4: 4: ['。', '自然语言处理的研究不仅有助于改善人机交互,而且对于提高机器的自主性和智能化水平也具有重要意义', '。', '']
使用RecursiveCharacterTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplittertext = """
在这里,我们有一段超过200字的中文文本作为输入例子。这段文本是关于自然语言处理的简介。
自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,它旨在让计算机能够理解和处理人类语言。
在这一领域中,机器学习技术扮演着核心角色。通过使用各种算法,计算机可以解析、理解、甚至生成人类可以理解的语言。
这一技术已广泛应用于机器翻译、情感分析、自动摘要、实体识别等多个方面。随着深度学习技术的发展,自然语言处理的准确性和效率都得到了显著提升。
当前,一些高级的NLP系统已经能够完成复杂的语言理解任务,例如问答系统、语音识别和对话系统等。自然语言处理的研究不仅有助于改善人机交互,而且对于提高机器的自主性和智能化水平也具有重要意义。
"""splitter = RecursiveCharacterTextSplitter(chunk_size = 150,chunk_overlap = 0,length_function = len,
)trunks = splitter.split_text(text)
for i, chunk in enumerate(trunks):print(f"块 {i+1}: {len(chunk)}: {chunk}")
块 1: 149: 在这里,我们有一段超过200字的中文文本作为输入例子。这段文本是关于自然语言处理的简介。自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉领域,它旨在让计算机能够理解和处理人类语言。在这一领域中,机器学习技术扮演着核心角色。通过使用各种算法,计算机可以解析、理解、甚至生成人类可以理解的语言
块 2: 150: 。这一技术已广泛应用于机器翻译、情感分析、自动摘要、实体识别等多个方面。随着深度学习技术的发展,自然语言处理的准确性和效率都得到了显著提升。当前,一些高级的NLP系统已经能够完成复杂的语言理解任务,例如问答系统、语音识别和对话系统等。自然语言处理的研究不仅有助于改善人机交互,而且对于提高机器的自主性
块 3: 14: 和智能化水平也具有重要意义。
文本向量化
简史:word2vec->Bert->Transformer
在RAG业务中,我们的目的就是将trunk转换为vector。vector之间可以计算“相似度”,而最流行的相似度衡量方式就是余弦相似度。
接着,将问题也转为vector,就可以实现问题与语料之间的匹配。
def get_embedding(text, model="text-embedding-ada-002"):text = text.replace("\n", " ")return client.embeddings.create(input = [text], model=model).data[0].embedding
这里使用OpenAI的text-embedding-ada作为encoding model。
import numpy as npdef cosine_similarity(A, B):dot_product = np.dot(A, B)norm_A = np.linalg.norm(A)norm_B = np.linalg.norm(B)return dot_product / (norm_A * norm_B)
emb1 = get_embedding("大模型的应用场景很多")
emb2 = get_embedding("大模型")
emb3 = get_embedding("大模型有很多应用场景")
emb4 = get_embedding("Java开发")
cosine_similarity(emb1, emb2)
0.9227828346114963
cosine_similarity(emb1, emb4)
0.796131924008725
向量数据库
上面说到,问题与语料的匹配是实现RAG的关键。假设现已有一个问题vector,以及语料经过切分、向量化之后的一大堆向量,接下来的难点就是如何快速找到与问题vector最相似的语料vector。向量数据库就是为了有效储存语料向量,使得检索更高效而诞生的。