一、ConcurrentHashMap扩容过程
1、ConcurrentHashMap扩容时新建数组
1.1 每个线程负责的数据迁移区域的长度:stride
1.2 关于transferIndex的说明
2、ConcurrentHashMap扩容时获取迁移数据区域
2.1 总结
3、判断数据迁移是否结束
3.1 每个线程完成自己区域内的数据迁移的判断条件
3.2 如何判断整个旧数组中的数据有没有迁移完
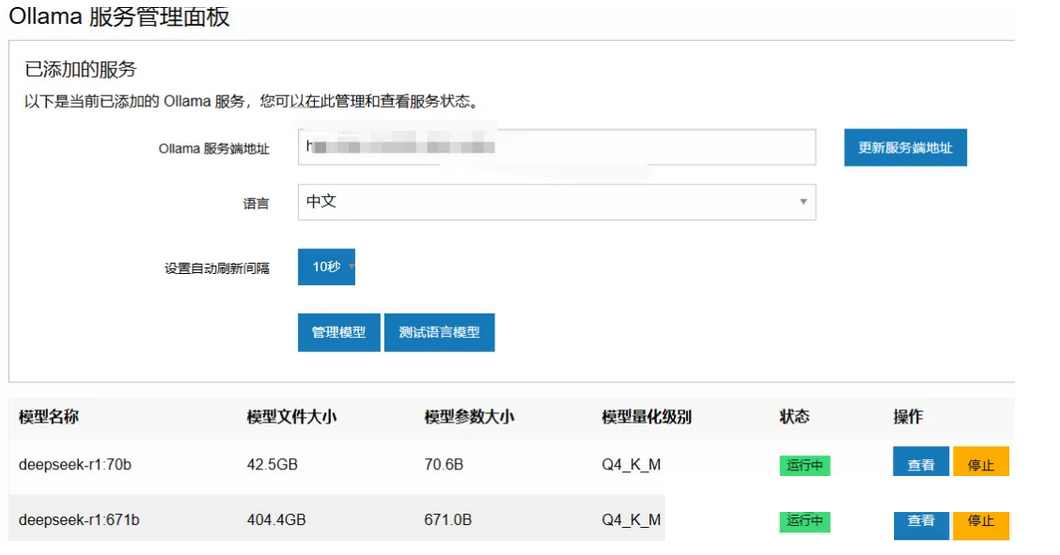
4、ConcurrentHashMap的数据迁移
4.1、ConcurrentHashMap数据迁移的原理
4.2、ConcurrentHashMap数据迁移的源码分析
-
4.2.1 Node链表迁移的源码分析
-
4.2.1.1 ConcurrentHashMap中如何确定节点在哪一条链表
-
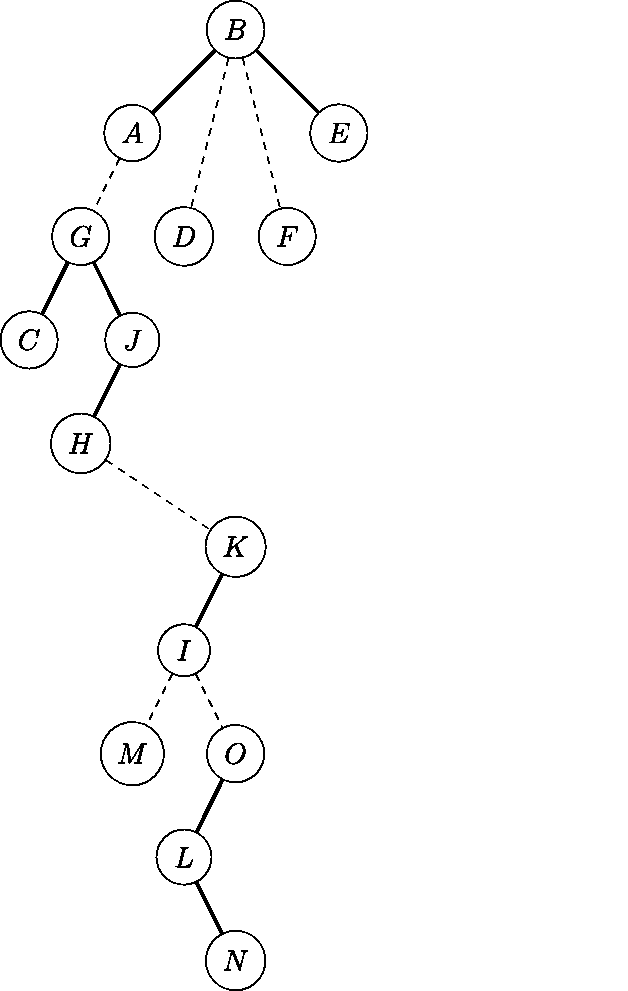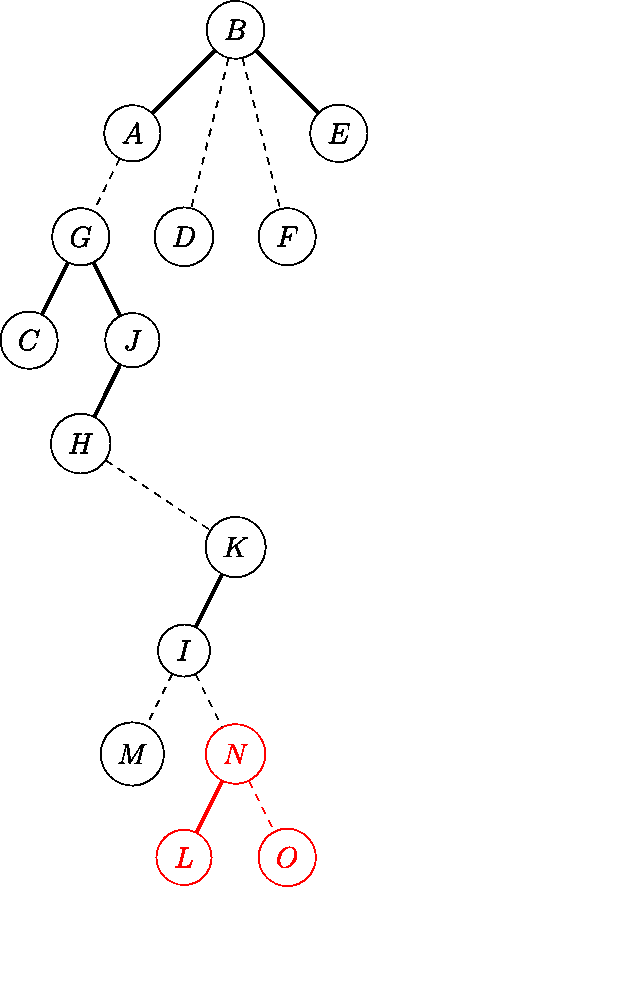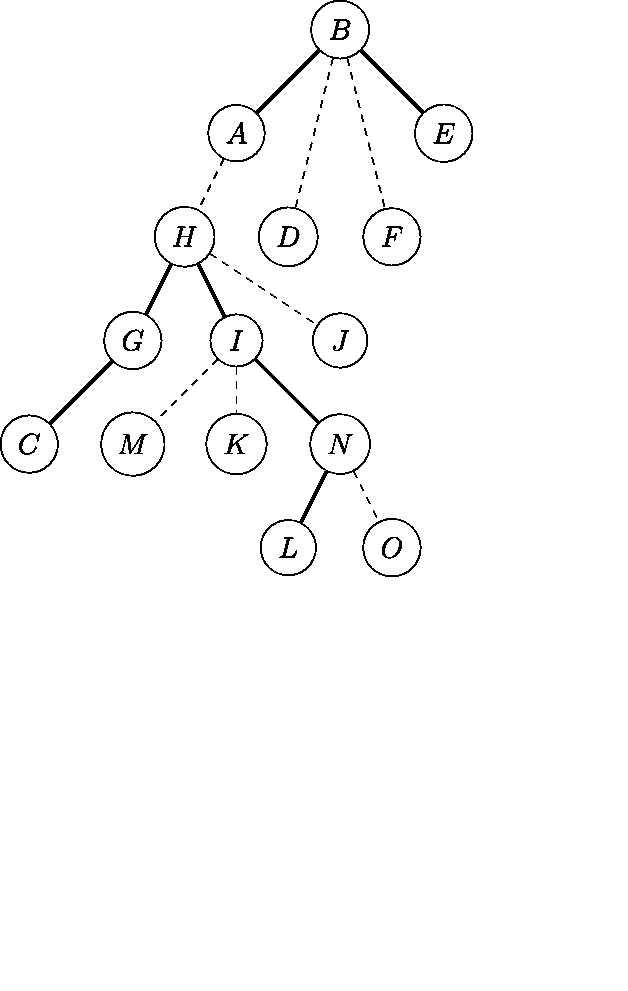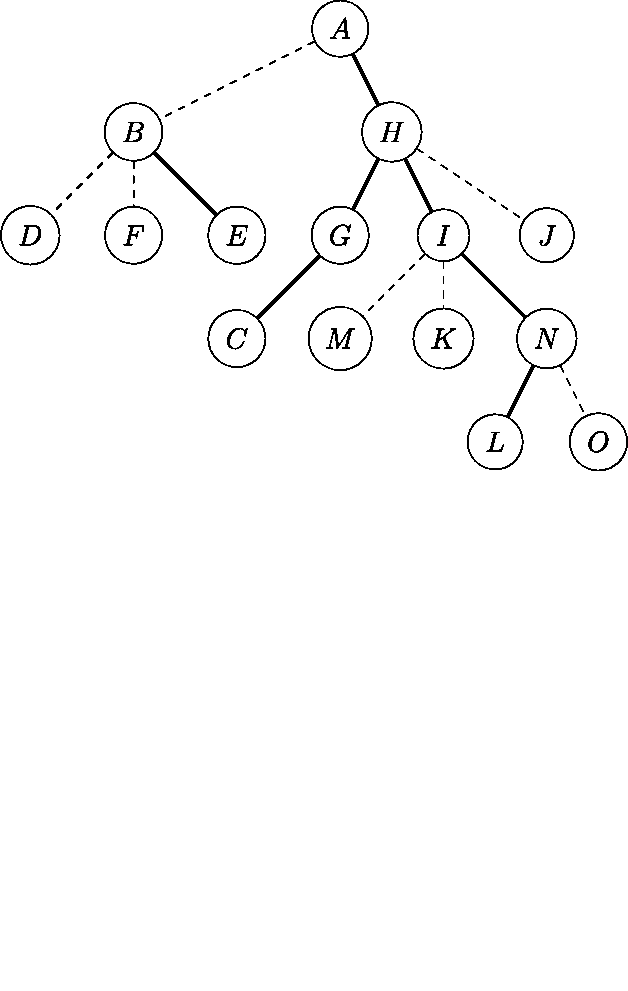
4.2.1.2 lastRun和链表数据的迁移流程
-
4.2.1.3 链表迁移的思考
-
-
4.2.2 红黑树迁移的源码分析
5、ConcurrentHashMap的数据迁移
5.1、ConcurrentHashMap扩容引起的数据丢失问题的原因及解决办法
二、多线程扩容问题
在put过程中,有2处地方会触发扩容的情况:
-
在put完成之后,更新元素个数时发现元素个数已经超过扩容阈值sizeCtrl,这个时候就会触发扩容(addCount方法);
-
在链表超过8,但是数组长度 小于 64时,不会将链表转换成红黑树,而是会选择扩容数组(tryPresize)
回到正文多线程环境下扩容与单线程环境的扩容有什么不同 ?
相同点:
-
1、首先都需要新建一个数组用于扩容后的新容器;
-
2、将现容器的数据迁移到新的容器中;
不相同点:
在单线程中所有的操作都是只有一个线程按顺序操作,而多线程则可能同时有多个线程操作同一件事;如果按照单线程的做法对扩容过程不加限制,会产生很多问题;比如在单线程中:创建新数组的操作,在多线程中旧可能出问题;如果多个线程同时扩容就可会创建多个数组;在迁移数据的同时又有新数据添加进来又该如何处理。。。因此在多线程环境下还必须要考虑到,数据迁移过程中可能出现对原数据的添加,删除,查询等问题。
回到正文多线程环境下扩容与单线程环境的扩容有什么不同 ?
-
多线程环境下触发扩容条件之后,如何保证只有一个线程去新建新数组 ?
-
在数据迁移过程中如果有数据的添加,删除,查询该怎么处理 ?
-
在ConcurrentHashMap中是多个线程同时扩容的,那么如何协调多个线程同时扩容;
-
如何确保数据全部迁移完成?
三、ConcurrentHashMap扩容过程
在ConcurrentHashMap中多个线程同时扩容时如何协同扩容呢 ?答案是:每个线程负责一部分固定的区域
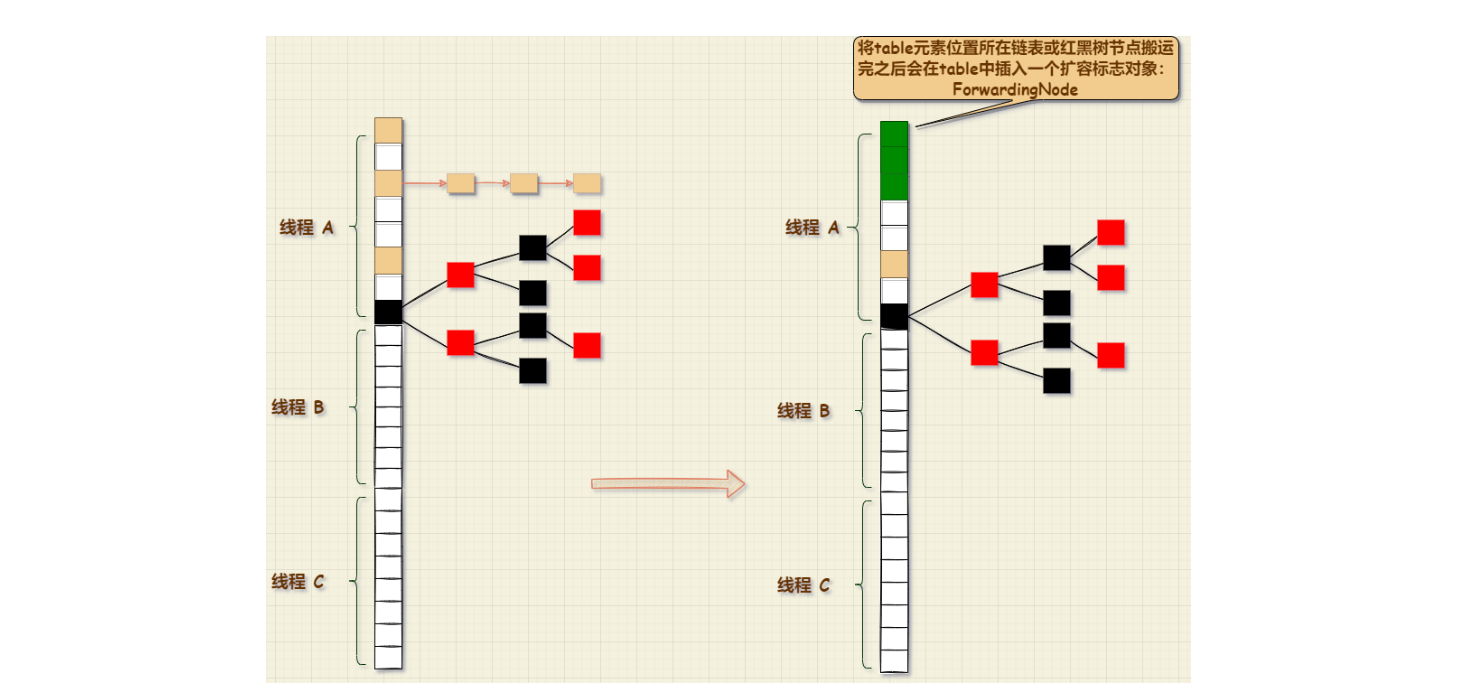
扩容的源码比较多,因此先对扩容流程有一个整体的印象;再读源码;
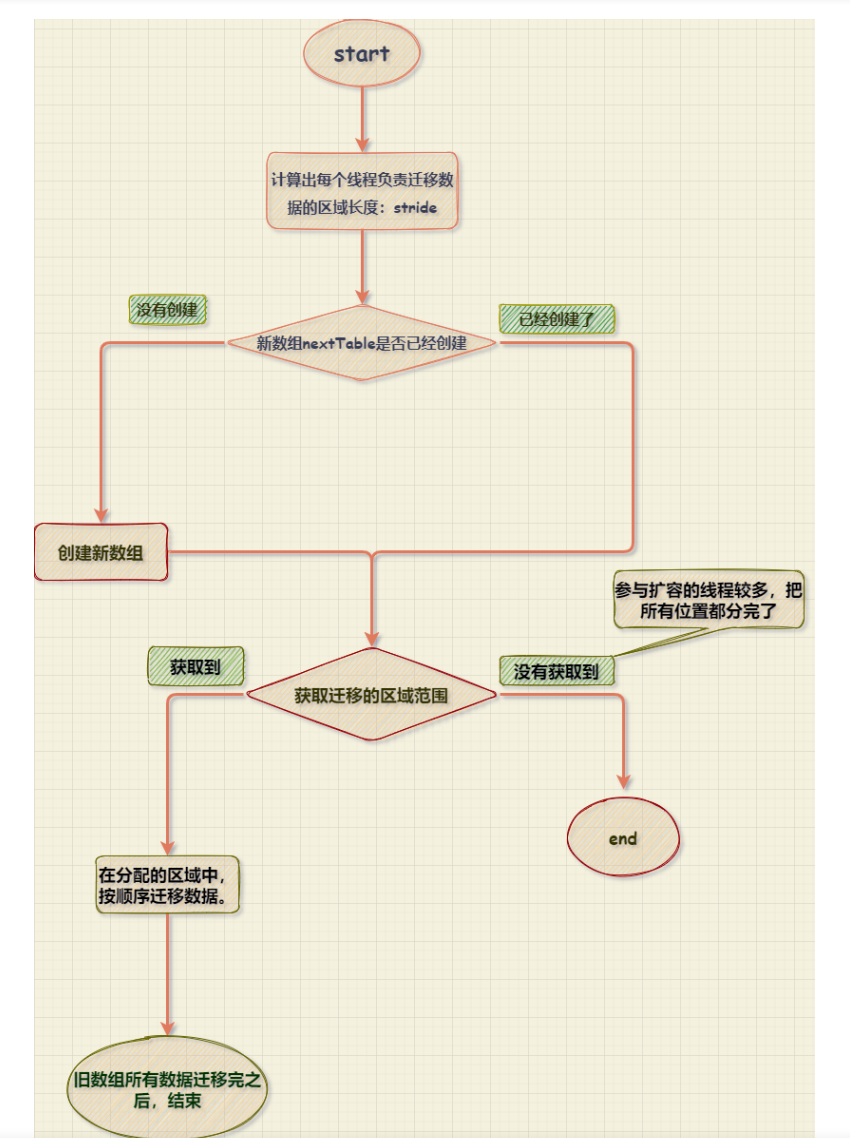
1、ConcurrentHashMap扩容时新建数组

1.1、每个线程负责的数据迁移区域的长度:stride
在ConcurrentHashMap中每个线程的数据迁移区域长度stride 不是一个固定值,stride 的值是根据:数组长度和cpu的个数决定的;

stride计算分2步:
-
(NCPU > 1) ? (n >>> 3) / NCPU : n ;计算出stride的值
-
与默认值比较;小于默认值使用默认值;大于默认值使用计算出的值;
1.2、关于transferIndex的说明
我们要确定一个线程的数据迁移区域,一个长度是不行的;还必须要知道一个数据迁移的起始的位置,这样才能通过:起始位置+长度;来确定迁移的范围;而transferIndex 就是确定线程迁移的起始位置;每个线程的起始位肯定都不同,因此这个变量会随着协助扩容的线程增加而不断的变化;
在ConcurrentHashMap中,分配区域是从数组的末端开始,从后往前配分区域,
-
第一个线程起始迁移数据的下标:transferIndex -1(数组最大下标),分配区域:[transfer-1,transfer-stride],
-
第二线程的起始位置:(transferIndex - stride-1),分配区域:[transferIndex - stride-1,transferIndex - 2 * stride],依次类推

2、ConcurrentHashMap扩容时获取迁移数据区域
当有新线程协助扩容时首先要获取到一个起始位置才能确定负责迁移数据的范围。ConcurrentHashMap是如何处理的?因为需要考虑到多个线程同时竞争同一个起始位置,因此要使用CAS竞争让线程抢位置,竞争失败的线程则进入循环下一次继续尝试获取一个起始位置;【在ConcurrentHashMap中大量的使用了CAS来修改变量值,如果关于CAS还有疑惑,可以看这篇文章中关于CAS的部分:关于CAS】

CAS 竞争位置,竞争成功之后由变量 i,bound 记录当前线程负责迁移数据的区域
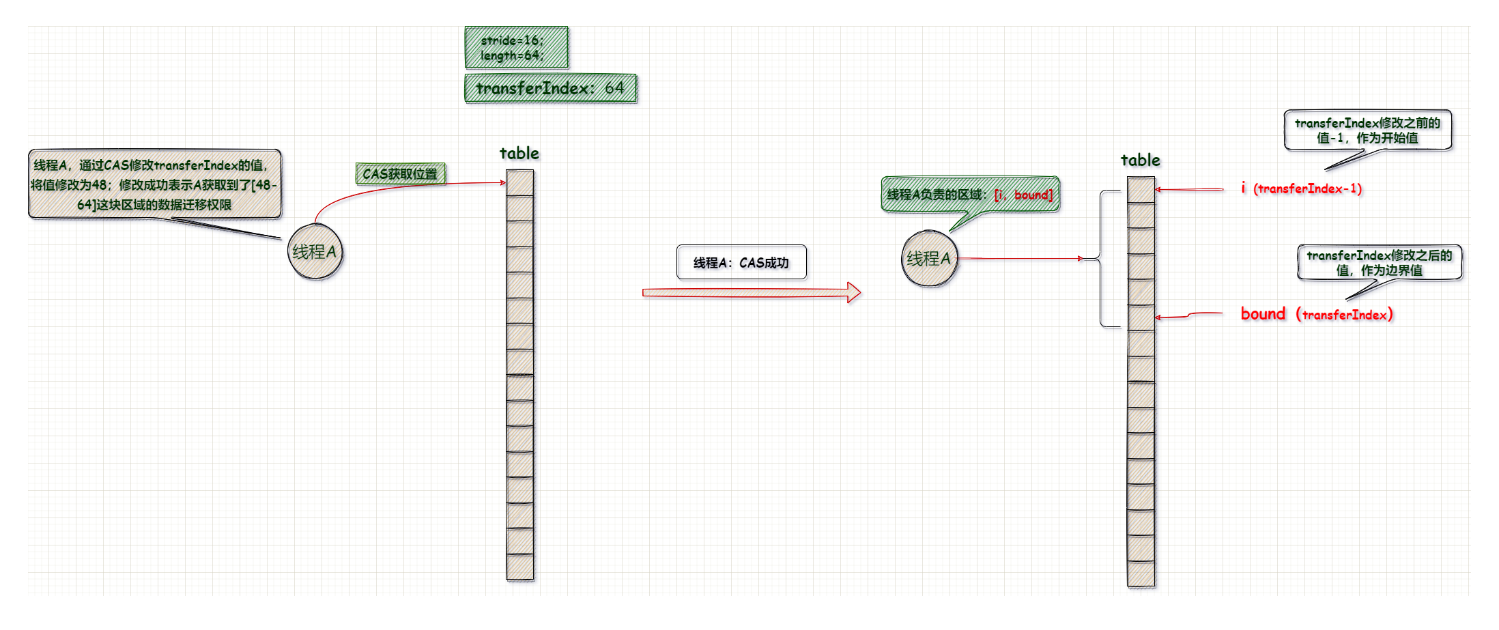
2.1、总结
每个线程迁移数据时只能迁移获取到区域的数据:按顺序遍历的将获取到的区域: [i,bound]上每一个位置的数据完全迁移;但这里要注意下:i > bound ,迁移时顺序是 : i -> bound;
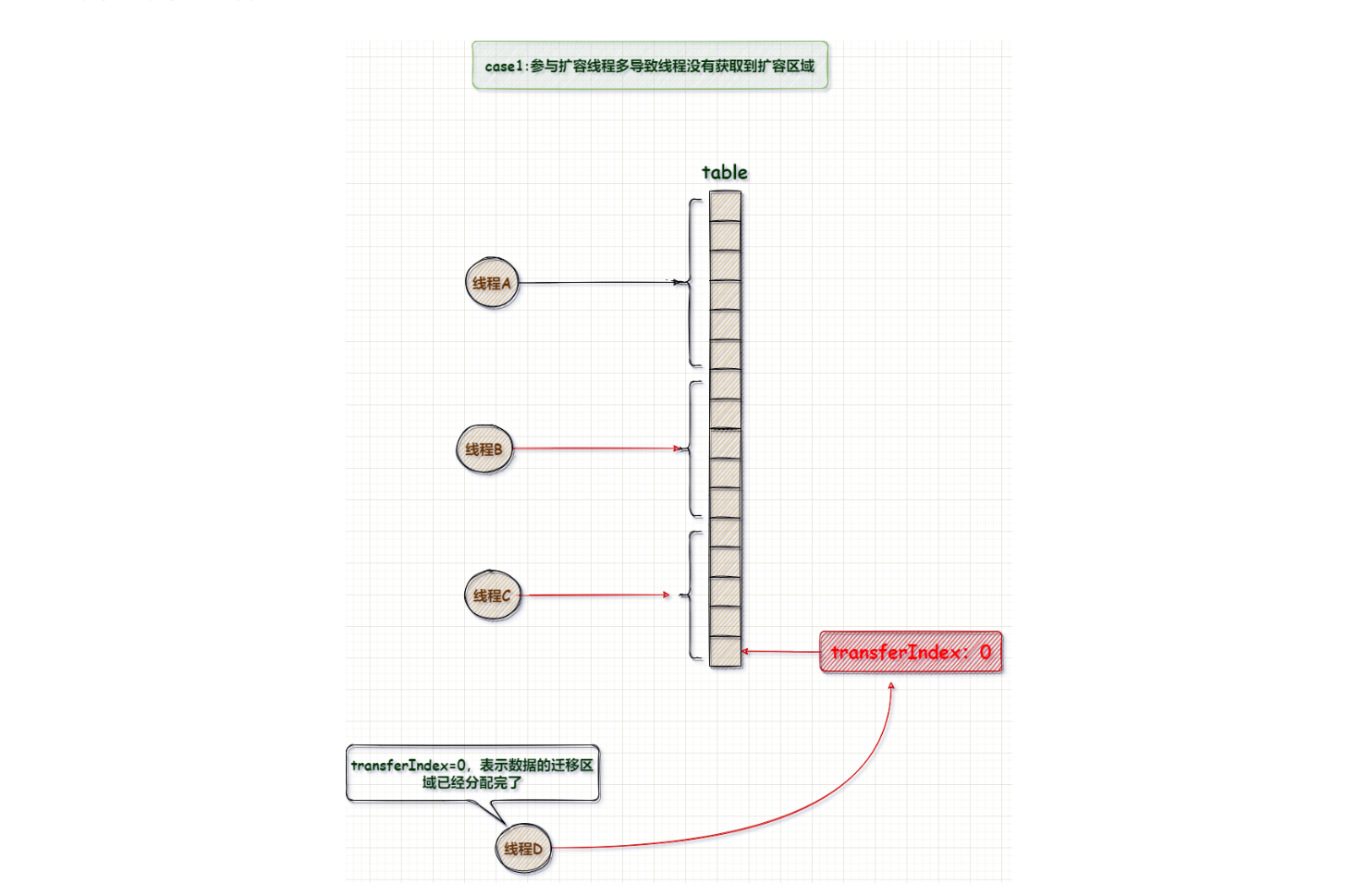
通过transferIndex 判断还有没有空闲的区域;transferIndex = 0 ;表示没有空闲区域了,所有区域都有线程负责迁移数据;
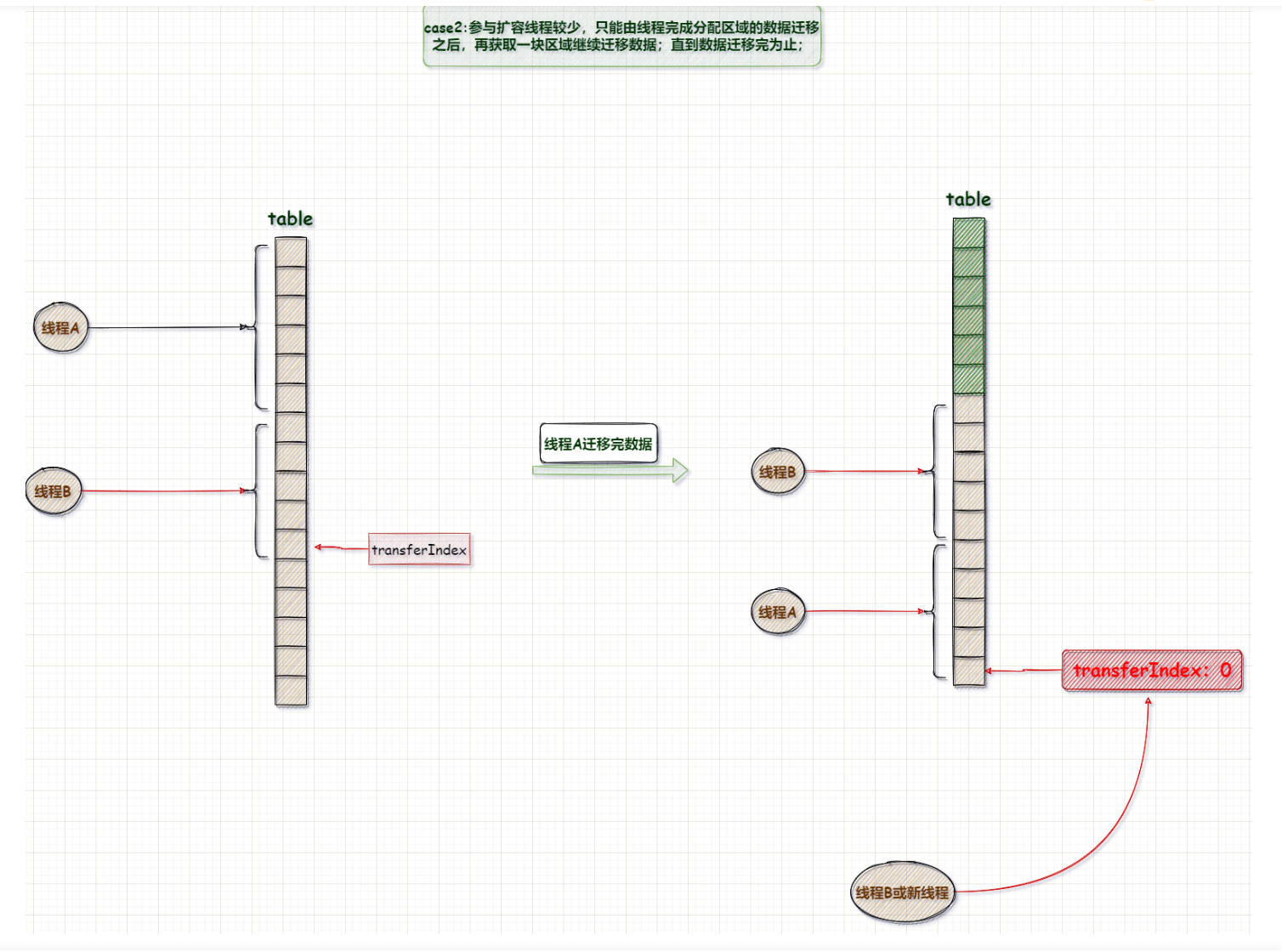
如果参与参与扩容的线程较多,那么可以将不同区域分配给不同线程;但如果参与扩容线程较少,那么线程完成了分配区域的数据迁移之后,获取下一块区域继续迁移数据,直到数据迁移完为止(为了保证在参与扩容线程很少时,也能将数据完全迁移);
A、有较多线程参与扩容时:
B、参与扩容线程较少:


![LGP11261 [COTS 2018] 直方图 学习笔记](https://s21.ax1x.com/2025/02/16/pEKIfvn.md.png)