介绍一下\(\text{Skip-Gram}\)算法。非常简单的一个算法,训练集由\(\text{context}\)和\(\text{target}\)组成,前者是一个句子中的某一个单词,后者是这个句子中这个单词临近的某个词。举例如下

我们获得单词的嵌入向量后,就放入神经网络中去跑,再利用\(\text{Softmax}\)如下
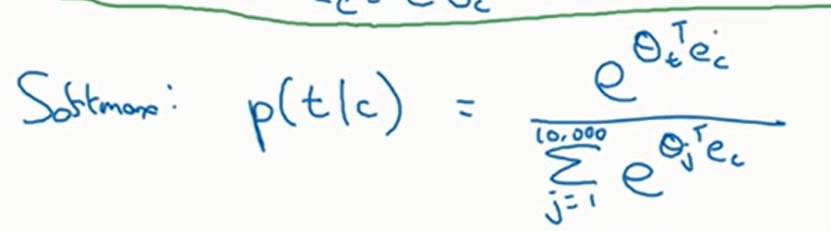
损失函数就是交叉熵损失函数
\(\text{context}\)的抽样方法:一般不采取均匀抽样,因为这个样子会让and,a,so等词出现很多次,所以一般会自己定义一个分布
上面的算法在训练嵌入矩阵这一块的效果非常好,但是存在一个问题,就是计算速度太慢,主要瓶颈是分母的求和计算
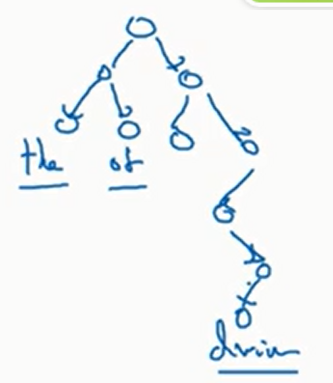
一个解决方法是不使用\(\text{Softmax}\),而是使用分层\(\text{Softmax}\).具体来说,建立一个二叉树,每个节点都是一个二元分类器,告诉我们预测词在每一个儿子中的概率,如下
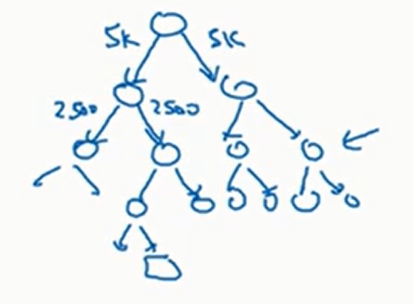
比如说现在要预测,根节点有一个二元分类器告诉我们输出的单词在前面五千个词和后面五千个词的概率,我们选择概率更大的节点,然后重复上述过程
注意分层\(\text{Softmax}\)使用的不是完美平衡树(上面的五千/五千只是随便列举的一个数字),一般使用的启发式方法是让出现频率很高的单词尽量出现在顶部,频率不高的单词尽量出现在底部(这样期望查找次数变少),于是树可能相当不平衡(因为频率出现低的单词种类远远多余频率出现高的单词种类),如下
再介绍一下负采样法。此时我们新定义训练集。我们像上面一样抽取\(\text{context}\),同时按照抽取\(\text{target}\)的方法抽取\(\text{word}\),就得到了一个单词对,然后将这个单词对的\(\text{target}\)标记为\(1\),同时我们再创造\(k\)(超参数,数据集越大\(k\)越小)个单词对,\(\text{context}\)不变,\(\text{word}\)从字典中随机抽取若干个,然后将这些单词对的\(\text{target}\)标记为\(0\)(这样子做就是想让模型努力区分单词对是来自一个句子还是随机抽取的).如下
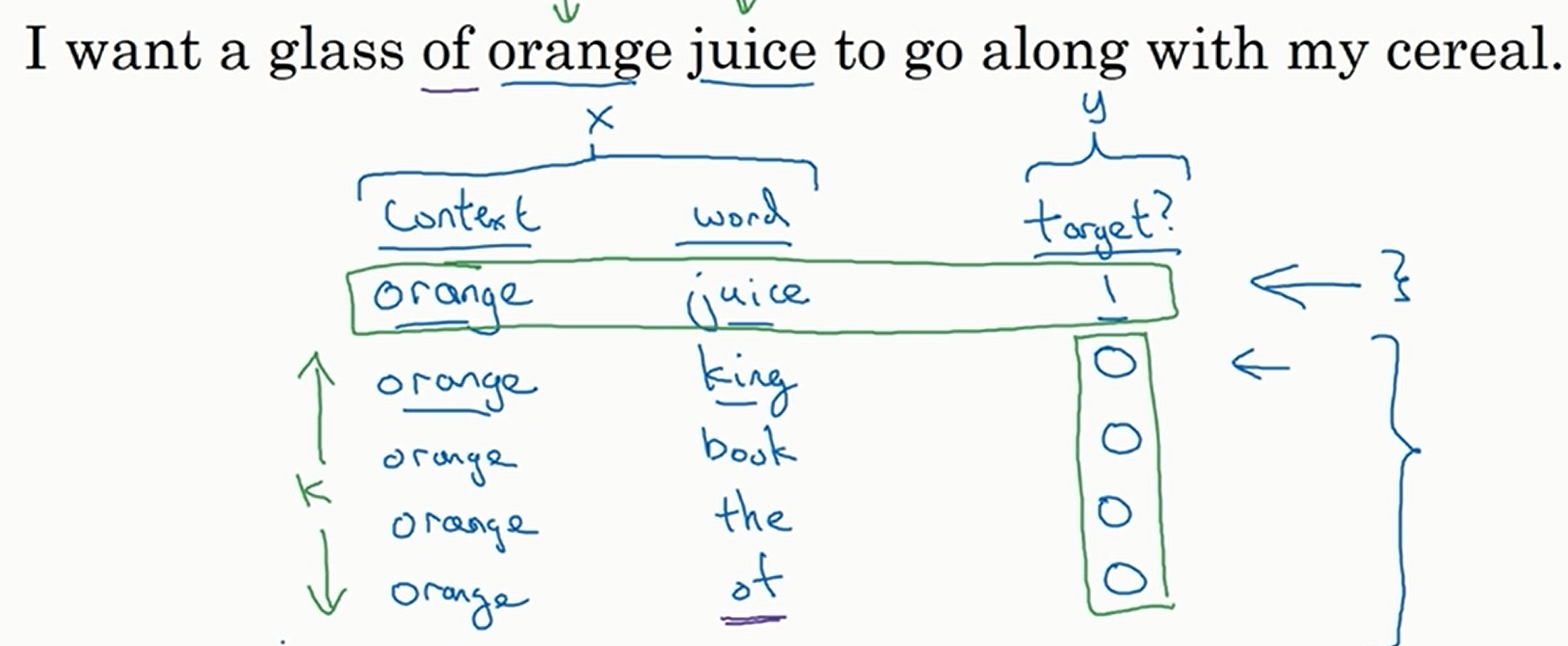
然后将\(\text{context}\)和\(\text{word}\)作为特征,\(\text{target}\)作为模型的标签。这个问题是一个二分类,我们使用逻辑斯蒂回归预测。见下
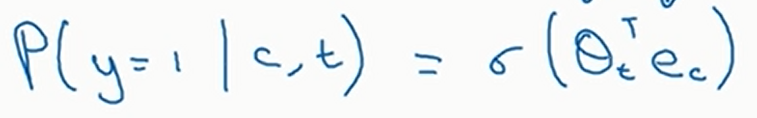
假设\(\text{context}\)定了,那么\(\text{word}\)的选择最多有词表大小这么多种,所以我们最多只需要训练词表大小这么多种二元分类器即可。总的训练成本很高,但是单个训练成本非常低
那么随机抽取应该如何抽取呢,也就是说应该以什么分布去抽取呢?均匀分布显然那不太好,但是如果按照出现频率来抽取,也会得到很多and,the等词。论文作者使用的是如下分布来做一个折中
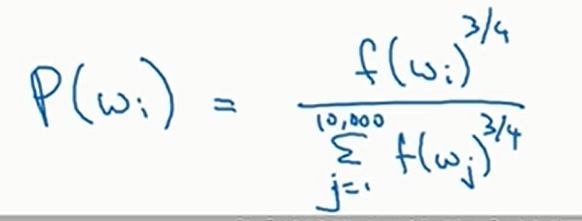
其中\(f\)是单词的频率。这种启发式方法效果还不错
嵌入矩阵其实有很多已经训练好了的开源的,可以直接下载




![[2025.2.10~16 鲜花] 仆は可怜な少女にはなれない](https://img2024.cnblogs.com/blog/2942935/202502/2942935-20250216193228959-113263946.png)