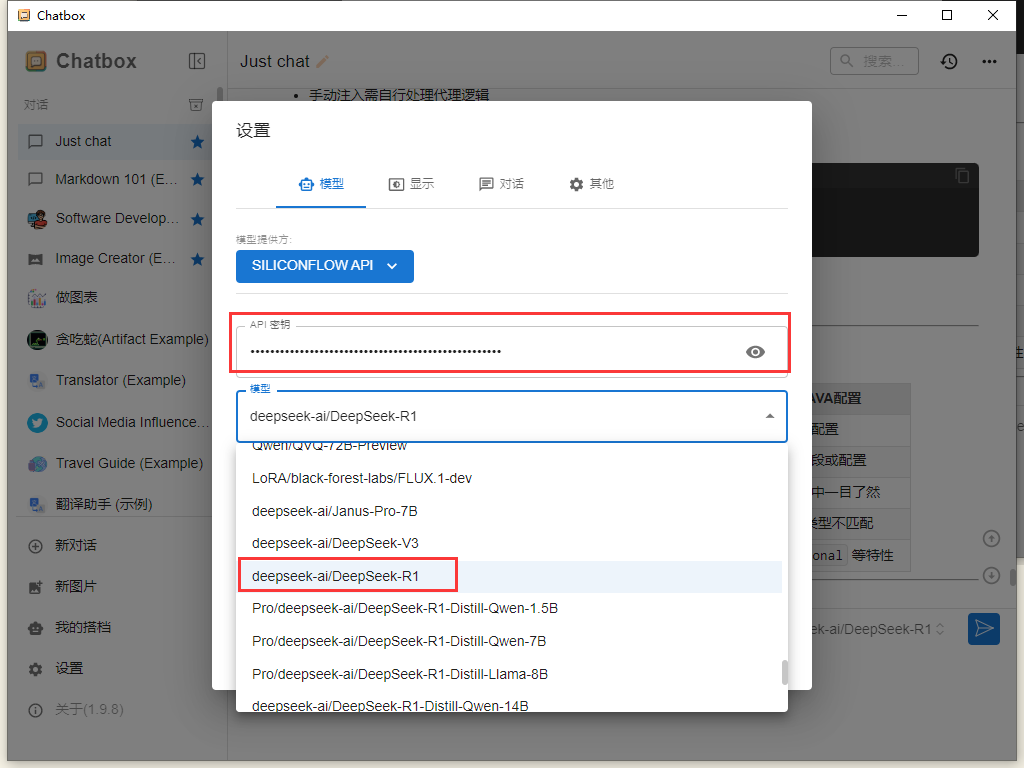
- 用docker,运行ollama镜像,然后进入ollama容器拉取deepseek模型。运行其他大模型也类似。如下是docker compose file
version: '3.3'
services:ollama:image: 'ollama:ollama'environment:- NVIDIA_VISIBLE_DEVICES=alldeploy:resources:reservations:devices:- driver: nvidiacapabilities: [gpu]container_name: ollamavolumes:- './data:/data'ports:- '11434:11434'
- 进入容器后可执行的命令。
# 拉模型速度取决于网速
ollama pull deepseek-r1:1.5b
# 运行模型,进入终端,退出终端命令:/exit
ollama run deepseek-r1:1.5b
# 列出模型
ollama list
- 用curl命令请求api获取解析结果
curl http://localhost:11434/api/generate -d'{ "model": "deepseek-r1:1.5b", "prompt": "给出一段文字描写春天", "stream": false }'
-
体验(只针对文字内容的处理)
本人在8核16G显卡的服务器上粗略测试了R1版本的1.5b、7b、8b、14b模型。如果只是对300字左右内容做分类或者提炼概述在几秒钟就可以得出结论。如果是在文字内容的基础上,询问逻辑问题,则可能需要10秒到大几十秒的时间而且可能不完全准确,而且模型越大越准确也越耗时间。 -
应用感想
其实deepseek的响应速度和逻辑推理已经满足很多不是特别复杂,实时性要求也不很高场景。比如:(1)内容分类或者内容鉴定;(2)一对一交流的场景。在实际应用中尽量让大模型判断具体的问题或者做具体的推理,避免做抽象的判断。比如给出一段需要文字需要判定的时候,提问“这段内容是否包含血腥暴力内容?”就会比提问“这段内容是否包含违规内容?”响应速度要快要准确。另外:我们在数据保存时,就应该对数据做大致分类,而不是完全交给大模型判断。比如我们或者很多商品评论的数据,如果知道单条评论是来自于食品、还是衣服还是化妆品那么再交给大模型分析时候,我们就可以让模型分析或者提取更具体的内容。


![P2375 [NOI2014] 动物园](https://cdn.luogu.com.cn/upload/image_hosting/foa3o5kv.png)