如何保证 Redis 缓存和数据库的一致性?
1. 问题出现场景
-
先修改数据库,再删除缓存
删除数据库数据成功了,但是删除缓存却失败了,缓存中仍保留的是旧数据
-
先删除缓存,再删除数据库
如果 Redis 缓存删除成功后,假如数据库数据还没来得及更新,用户又请求数据,这时就会从数据库中读取旧的值,存入到 Redis 中,用户查到的数据依旧是旧的数据。
2. 解决方案
2.1 双写事务
原理:利用 Redis 的事务特性,或是数据库的事务特性,把 Redis 操作和数据库操作放到同一个事务中去执行,同时提交或回滚,最大程度上保证 Redis 缓存和数据库的一致。
-
优点:实现简单、不复杂,能够保证一定的一致性
-
缺点:
Redis 和数据库本质不是同一种数据库,所以无法通过事务来保证它们之间完全的一致性
适合小型系统的简单读写,不适合高并发系统。
2.2 延迟双删
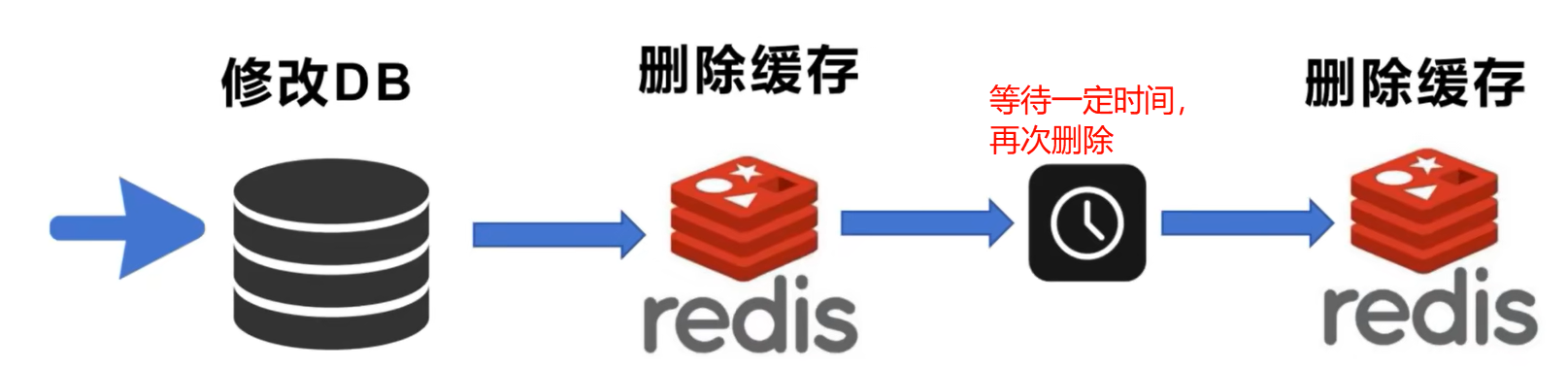
原理:当完成数据库的更新时,立即删除 Redis 缓存,为了确保数据更新的稳妥,延迟一定时间后(例如 1s、2s),再次对缓存进行删除。
目的:避免并发操作导致缓存脏数据的问题出现
- 优点:实现简单,能够解决大部分场景下短时间数据不一致的情况
- 缺点:延迟时间非常难以精确控制,如果操作量比较大,可能还会出现覆盖的风险
2.3 订阅更新机制
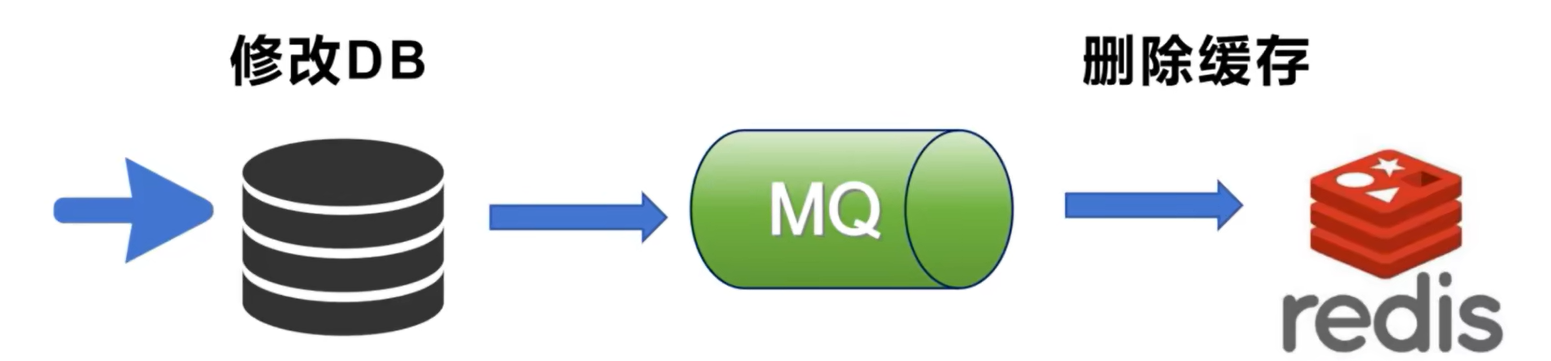
原理:当数据库更新,会向消息队列发送一条消息,Redis 通过订阅这个消息队列,来更新缓存数据,这样会让更新和缓存的清除变得非常及时。
- 优点:同步效果非常好
- 缺点:系统的复杂度会增加,消息队列本身需要一些可靠性,也是需要一些维护成本
2.4 读写分离架构
高并发场景应用非常广泛
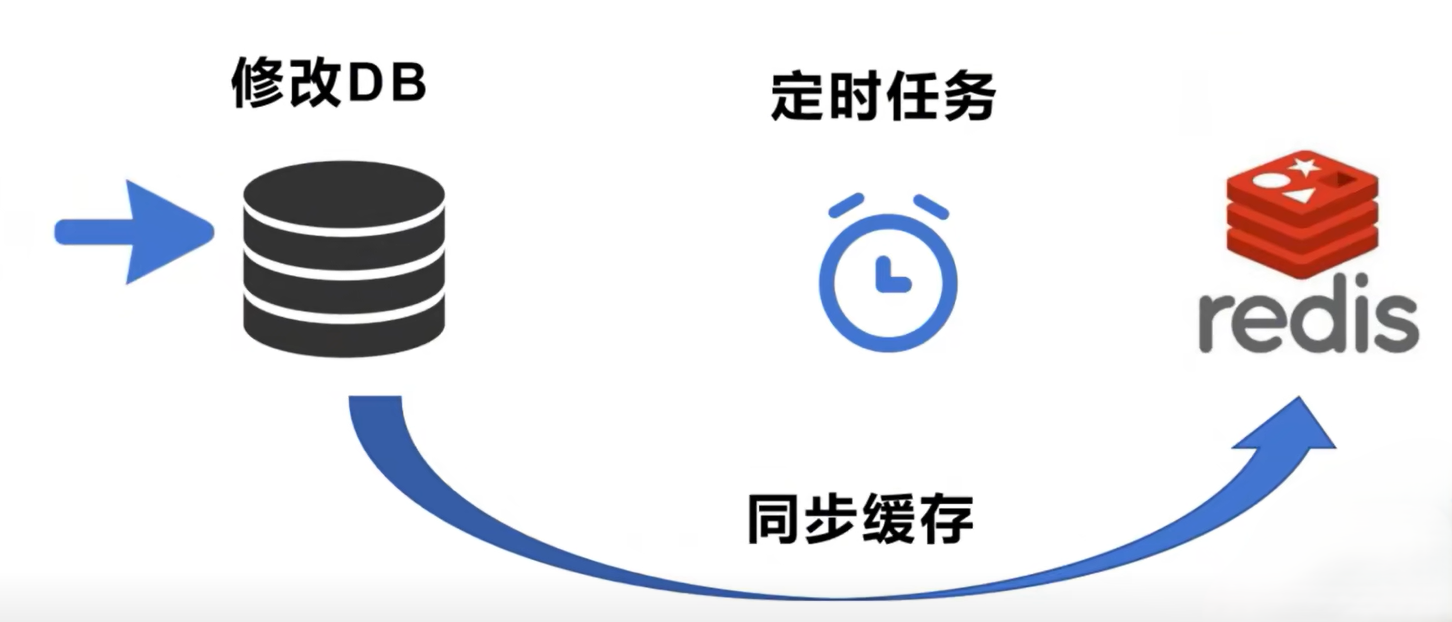
原理:把写操作全部直接操作数据库,然后通过一个异步线程、后台服务、定时任务,去更新 Redis 缓存,从而实现数据的一致性。
- 优点:缓存压力降低很多,特别适合大数据流量的系统
- 缺点:项目开发比较复杂,因为要做好这种异步的逻辑的处理
2.5 Canal 订阅 Binlog 同步 Redis
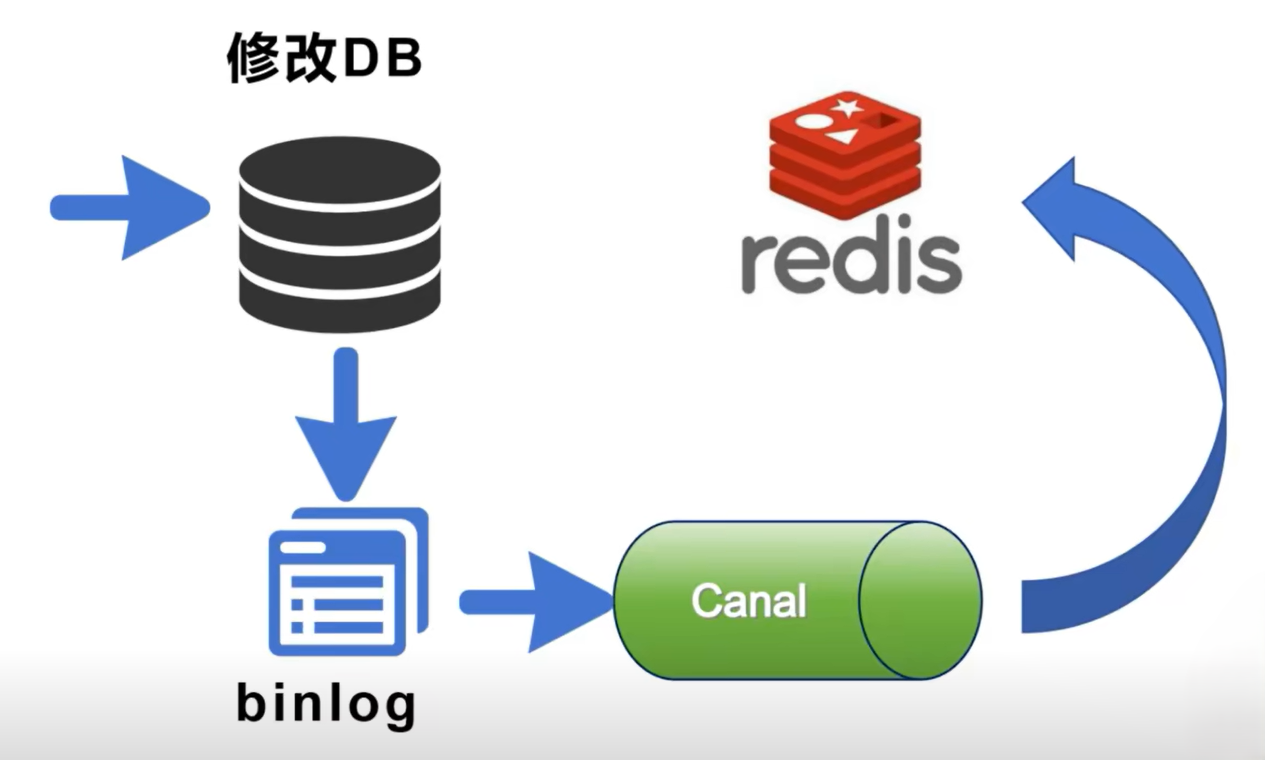
原理:修改数据库的同时,数据库的操作会同时写入到 Binlog 中,这时可以通过 Canal 中间键,来订阅 Binlog 的一些变化,如果监听到数据库变化之后,把更新的数据同步通知给 Redis,来更新 Redis 的缓存
3. 总结
3.1 哪儿种方案更好?
具体选择哪儿种解决方案,要根据具体业务场景、项目的需求,以及整体的架构等多种因素去综合考虑,比如是否是高并发、是否要考虑低延迟等等因素。
脱离业务谈技术,就是耍流氓。
3.2 归纳
虽然这几种解决方案,可以在一定程度上解决 Redis 和数据库不一致的情况,但是在实际情况种,还要结合业务,来判断项目中是否真的需要,或是项目中可以使用 Redis。如果业务需要强一致性,例如银行、股票等业务,其实不使用 Redis 其实也是一种很好的方案。