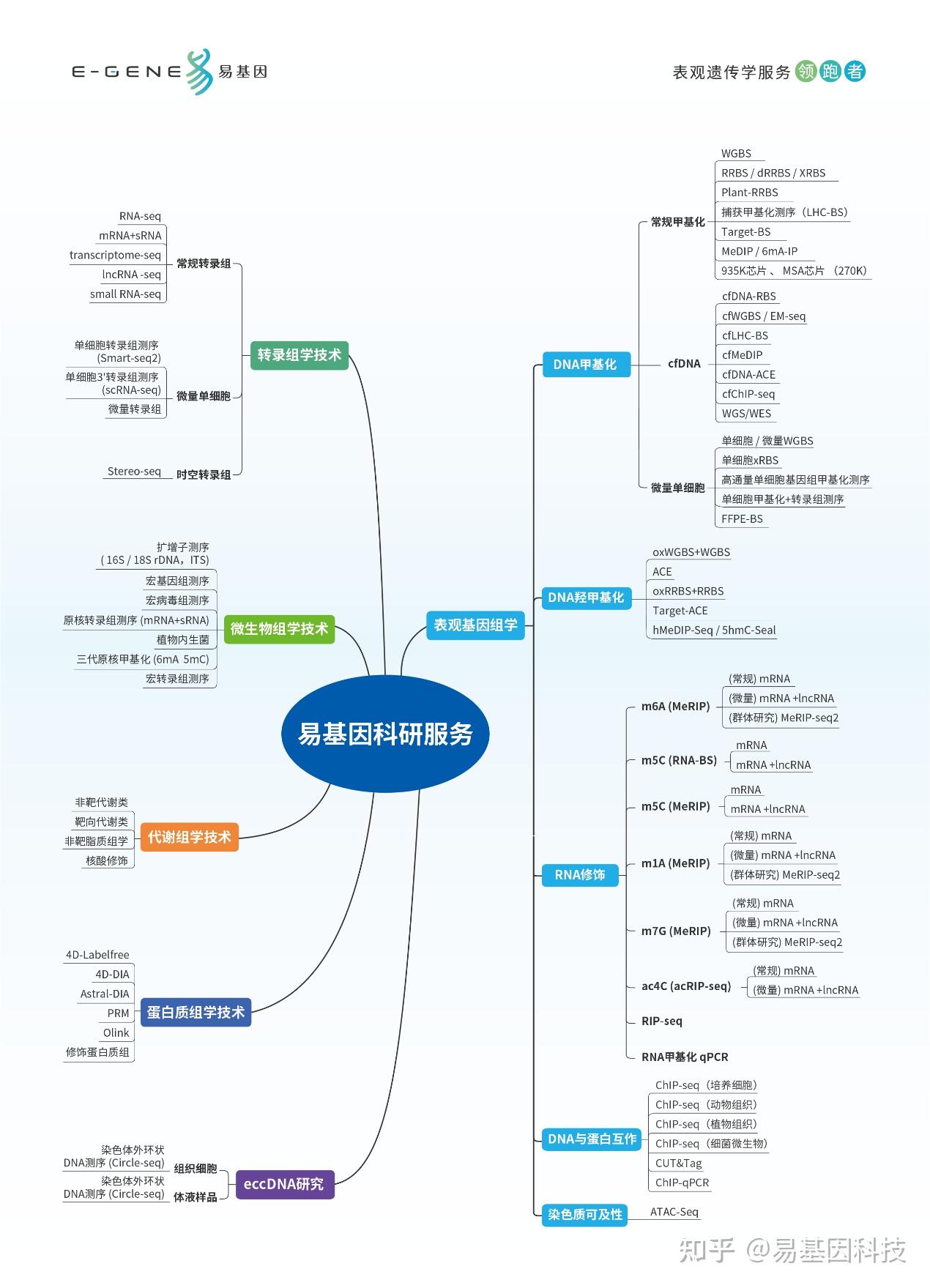
本文记录此次报告的key point(个人向)
llm时代的几点difficulity

Inference-time computation scalling
- OpenAI o1 利用RL来显式整合inference期间推理的step(inference-time computation) (从predicte next-token范式到RL解决问题范式)
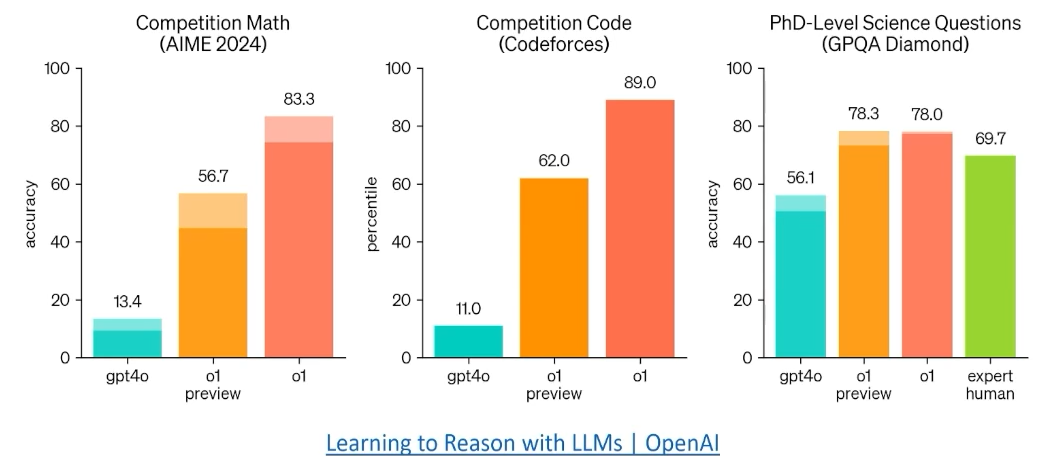
- predict next token是监督学习,受限于训练数据集水平。但可以将其用于理解规则,从而超出数据集水平。(将数据作为world model而不是拟合)
- 自回归LLM对某些问题决策计算量不够