Alberto Romero

I. GPT-4.5 就是起跳前的助跑那一步
OpenAI 推出了 GPT-4.5(官方博客、系统卡片、演示视频),这是他们最新也是目前最大的一款 AI 模型。他们其实一年多前就开始放风,说它叫 Orion,结果很多人还以为是 GPT-5。现在终于来了……但感觉吧,有点拉胯。至少看起来是这样。今天我们就聊聊这个“是”和“看起来是”之间的微妙区别,到底咋回事。
你可能一堆问号:
为什么 GPT-4.5 的测试分数还不如几个月前的那些模型?
OpenAI 为什么憋了一年多,最后搞出来个不是最强的?
为啥比之前的 OpenAI 模型和竞争对手的都贵这么多?
为啥做得这么大,按理说预训练规模效应不是早就到瓶颈了吗?
不是说一直要冲数学和编程能力吗,怎么突然又搞起创意、直觉和情商这一套了?
幸好,我这儿都有答案。
也幸好,OpenAI 不透明的操作——加上他们浪费了这么好的营销机会——给了我这篇文章的存在意义。
不啰嗦,我们马上过一遍 GPT-4.5 的规格和测试成绩。我会把 OpenAI 演示里说的,系统卡片里写的(包括后来被骂后偷偷改掉的),还有那些提前用上 GPT-4.5 的早期用户的体验,都给你们汇报一下。(目前 GPT-4.5 只开放给 Pro 用户,下周才轮到 Plus 用户。)
然后我们再回到刚才那几个问题上,好好捋捋这个看似拉胯的模型到底图啥——最后也会告诉你,为什么我觉得即使有 Sonnet 3.7、DeepSeek-R1 和 Grok 3,OpenAI 还是稳稳的。
别着急,先给个小提示:今天的 GPT-4.5 只是个麻烦,明天它就是 OpenAI 最大的底牌。
这次发布,不是那种公司要放鞭炮庆祝的发布会。OpenAI 自己都不怎么兴奋,他们更想赶紧把这个东西甩出去,然后专心搞接下来的大活儿(就这几周或几个月的事儿)。
GPT-4.5 简单说就是起跳前的那个蹬地助跑。
后面才是起飞。
II. 失望是正常的:贵、慢、还过时
系统卡片开头就这样写的(官方博客差不多意思):
我们推出了 OpenAI GPT-4.5 的研究预览版,这是我们迄今为止最大、最博学的模型。它建立在 GPT-4o 的基础上,把预训练规模拉满,目标是比那些专注理科推理的模型更通用。
然后还补了一句:
GPT-4.5 不是前沿模型,但它是 OpenAI 最大的 LLM,比 GPT-4 的计算效率提升了 10 倍。虽然 GPT-4.5 的世界知识更多,写作水平更高,个性也更细腻,但它并没有带来真正“全新”的前沿能力……
这段基本定下了基调。
GPT-4.5 又大又贵,就算计算效率提升 10 倍,跑起来还是很烧钱。偏偏能力又不是最强,测试成绩我马上给你看。这不就是“花钱买气受”吗?
(顺便说句,“10倍效率提升”和“不是前沿模型”这两句,其实是他们后来从系统卡片里悄悄删掉的。我猜是后知后觉发现,这样宣传简直是自砸招牌:啥意思啊,10倍效率还比以前贵10到25倍?还给我们个更烂的模型?知识截止还停在2023年10月?)
这里插句关于 GPT-4.5 体积的八卦。10倍效率却10倍成本,这说明它是真的大。大概率又是 Mixture of Experts(专家混合)那一套,跟之前 OpenAI 和 DeepSeek 那些路线一样。有人猜它是 1 万亿个激活参数,总参数可能 10-15 万亿,这不正好印证我去年对 GPT-5 体积的预测吗?(OpenAI 乱改名字咱就不管了。)
当然,这都是猜测,猜测才好玩嘛。真实参数我们永远都不会知道,等 Semianalysis、EpochAI 那些硬核机构来细抠吧。
除了又大又贵,GPT-4.5 也不是推理模型(不是冲着理科和逻辑去的),而是个基础通用模型,偏软技能方向(比如普通聊天机器人)。如果你拿 GPT-4.5 去跟那些专门搞推理的(比如 o1/o3)比 GPQA、数学竞赛、代码竞赛、SWE-bench 这种测试,肯定拉胯。
作为一个写字的,我反而觉得是好事。我早就盼着有个对审美和文笔更讲究的模型了。对大部分普通 ChatGPT 用户来说也不错啊,反正价格不变(200块一个月或20块一个月),你还能换个写得更顺、更像人的模型。
但那些习惯了最近那波又便宜又能推理的理科模型(o1/o3、Sonnet 3.7、DeepSeek-R1、Grok 3)的开发者,估计要骂街了。OpenAI 自己也没打算藏着掖着,但光靠诚实是安抚不了这些人的。GPT-4.5 每百万输出 token 要150刀,比 DeepSeek V3 贵150到300倍。
所以 OpenAI 在博客最后才说,他们还在考虑要不要长期开放 GPT-4.5 的 API 服务。供着它不但拖慢训练下一代模型,还太烧资源。再说,这么大个东西,速度还慢。谁会花300倍的价钱用这只乌龟,尤其是竞品早就把同类功能卷成白菜价了?
其实我也不懂为啥他们非要上 GPT-4.5(不光 API,连 ChatGPT 里也上了)。按照我之前写 GPT-5 那篇文章的思路,OpenAI 最该做的是把这种超级大基础模型关起来自己用,压榨出又强又便宜的小模型。这样你那4亿周活用户——他们永远是优先快和便宜的——和你钱包都能轻松点。
反正 GPT-4.5 从 API 下架也没啥大不了的。OpenAI 服务的几千万用户里,关心演示视频、盯着 Sam Altman 推文的,根本是极少数。真在乎的里头,愿意掏钱买 API 的又是极少数。(而且他们很多还更喜欢用 Anthropic 的。)
Sam Altman 心里有数,OpenAI 完全可以暂时让科学家、程序员、研究员们失望一下,反正 ChatGPT 订阅费是稳的。GPT-4.5 只是个临时的小麻烦,他扛得住。
III. 有时候你不是要把天花板抬高,而是把地板垫高
系统卡片里最重要的一句话是这句:
GPT-4.5 是我们在无监督学习范式上迈出的下一步。
这句话估计大部分人都会忽略。那些喜欢瞎解读的 AI 圈大V,肯定会自由发挥,想怎么编怎么编,时间线上的人也懒得较真儿。OpenAI 其实是想把这个点传递出去,但我觉得大概率没人听进去。
所以如果你只记住这篇文章的一件事儿,就记住这句:
他们训练 GPT-4.5 不是为了把天花板抬高,而是为了把地板垫高。
“无监督学习的扩展”,说白了就是“预训练的扩展”——就是模型刚开始的时候,直接往里倒一堆互联网数据,让它先学会最基本的语言能力和世界常识的那个阶段。这个阶段垫得越高,后面才越好发力。
自从 OpenAI 在2024年9月推 o1-preview 之后,整个圈子的关注点就转向“推理能力扩展定律”(或者说推理能力依赖的推理计算)。大家都跟风,重点都不在底子有多好,而是后期训练能不能让它变聪明。
GPT-4.5 就是一次对“预训练规模定律”的回访。虽然大家都说“预训练”进入瓶颈期,但瓶颈期不是“彻底没用”,只是“效益递减”。所以,AI 公司隔段时间还是得回头,重新做一轮大规模预训练。就算表面上看,像 GPT-4.5 这种“垫底”型模型,好像退步了,但这是必须的步骤。
之前我在 DeepSeek 的文章里画过一张图,专门讲为什么公司需要更强的基础模型,才能把整体技术水平往上拉:

很多人评价 AI 模型的时候犯的最大错误就是:
只看数据点(GPT-4.5 测试成绩一般般),不看轨迹(OpenAI 要 GPT-4.5 干啥)。
他们觉得预训练和后训练是对立的(GPT-4.5 是预训练路线的死路),其实它们是互补的(好底子才能炼出好推理)。
(AI 圈有个共识,就是语言推理模型能在去年爆发,不是因为突然哪儿开了窍,而是因为基础模型的尺寸和训练数据量终于堆到及格线以上了。之前很多类似思路都失败了,就是因为底子不行。GPT-4.5 的预训练量是 GPT-4 的10倍,说不定它就是下一代推理模型的发射台。)
要是还不太清楚 GPT-4.5 和其他模型啥关系,我给你举个简单的人类类比:
GPT-4.5 就是个天赋逆天的婴儿,爸妈都是顶级学霸;而 o1/R1 是个普通但靠谱的成年人,大学数学课学得还不错。
要是你现在找个员工干活儿,肯定选后者。可那娃还会长大啊——GPT-4.5 会变成 GPT-5、o4 之类的老大哥。
大家还会继续说 GPT-4.5 让人失望,继续唱衰预训练。但失望是对啥?预训练对拿数学竞赛金牌的确没啥用。但谁在乎呢?现在已经有一堆数学和编程天才模型了,但它们连最简单的脑筋急转弯都解不了。
所以,你必须把地板垫高。没有点基本常识的 AGI,根本不值钱。
如果 GPT-4.5 硬核智商不算高,但蠢得少,那我举双手支持。
更何况,它还可以当成未来模型的垫脚石,真香。
所以,训练 GPT-4.5 对 OpenAI 来说是战略级关键动作,哪怕它本身有点拉胯,产品层面慢又贵,都是值得的。
IV. 但说真的,你们把 GPT-4.5 最强的点藏得太深了
话说回来,OpenAI 完全可以宣传得更好点。因为虽然 GPT-4.5 不爱思考,但它有别的优点啊。
我们来看看图表,顺便告诉你,为什么我先提前打个预防针:
你真用起来,可能比预期还要失望。

SimpleQA 这个测试是看 LLM 对简单但***钻的知识问题答得准不准。
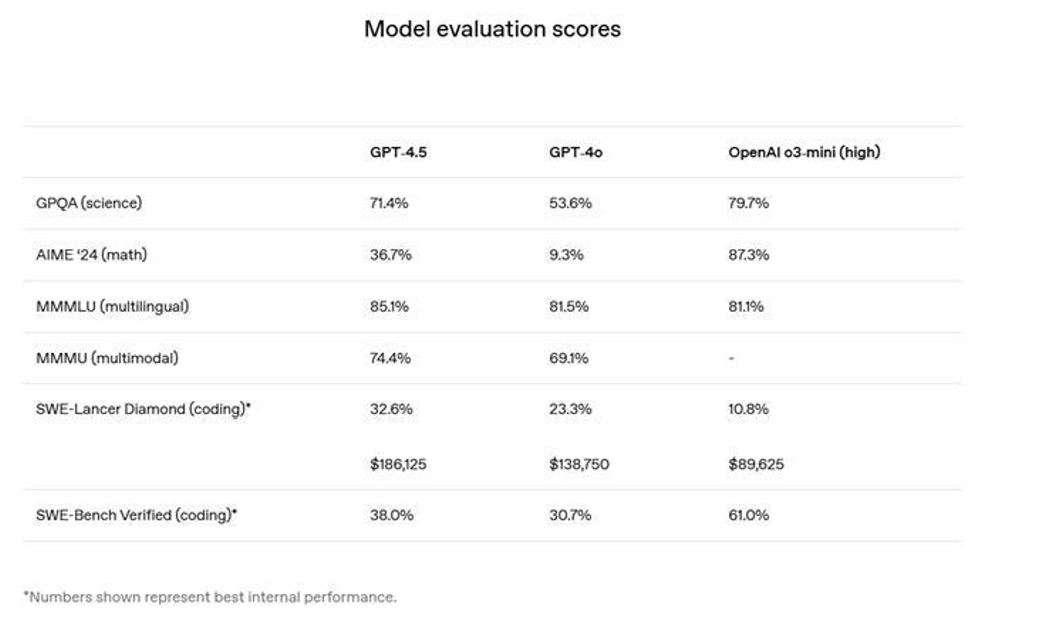
STEM/agentic 评测成绩
SimpleQA 里 GPT-4.5 知识面比以前广,瞎编率也比以前低(注意,OpenAI 只跟自己家模型比,没拿其他公司的比)。GPQA、AIME 2024、SWE-Lancer Diamond 和 SWE-bench Verified 这些理科和任务型评测,GPT-4.5 比 GPT-4o 的确强点儿。看起来还行。
但问题来了:GPT-4.5 还是比不过 DeepSeek V3,在所有同时测试的项目上(GPQA、AIME 2024、SWE-bench Verified)全输了。
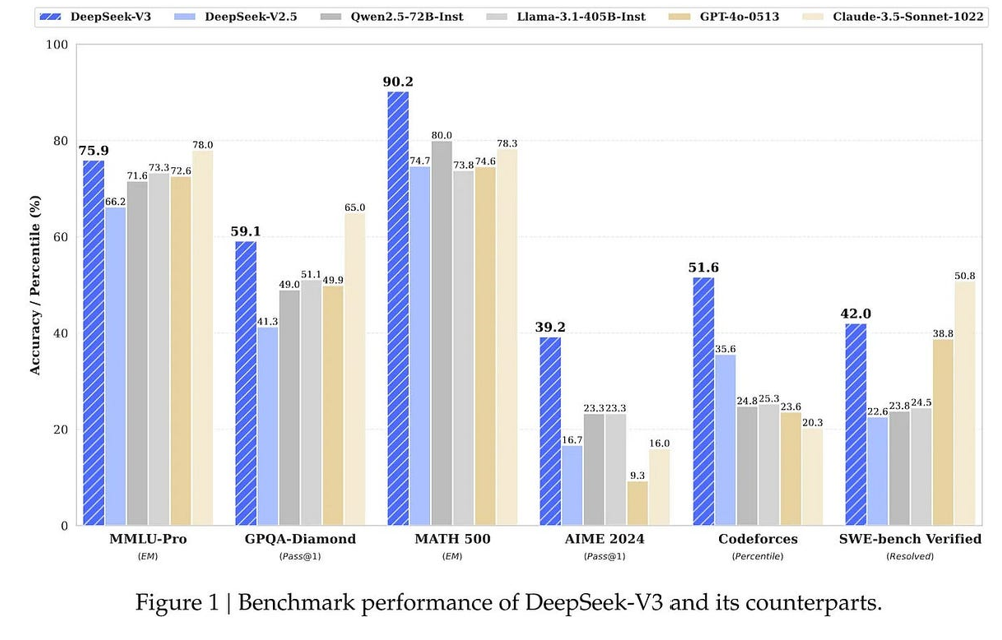
所以,总结一下:比 GPT-4o 强点儿,但比最强的非推理模型差一截——还贵2到3个数量级。OpenAI 这回真是尴尬了。
(顺便说一句,DeepSeek V3 虽然不算纯推理模型,但它后期加了强化学习,而 GPT-4.5 估计就是普通微调+RLHF,主打一个听话和乖巧。)
OpenAI 在系统卡片里列了其他评测分数,结论都差不多:这是个不差,但完全不惊艳的模型。
但我纳闷儿:既然 GPT-4.5 主打创意、直觉、情感,你们为啥还要硬拿 STEM/agentic 那套去比?为啥不搞一套更贴合 GPT-4.5 特点的测试,比如创意写作、情感理解啥的?Ethan Mollick 教授不是一直说,这些东西其实是可以量化测出来的吗?
可能 OpenAI 自己也觉得这种东西不好量化,或者他们故意留一手,怕 GPT-4.5 太出彩,抢了 GPT-5 的风头。搞不好他们本来就想“先挨顿骂,等 GPT-5 一鸣惊人”,结果诚实过头,自己先给自己上了一课。
但无论如何,我都不觉得 GPT-4.5 会在榜首挂太久。再说一次,我的判断是:OpenAI 早就知道 GPT-4.5 会被喷,但它是个过渡,撑到 GPT-5 上线就好。
V. 低品味测试者的暴政:大家还是更喜欢 GPT-4
我必须特别提一下 Andrej Karpathy 关于 GPT-4.5 的几条帖子。
他发了一条超长推文,说他从 GPT-1 一路用到现在,对 GPT 系列的进化有啥感受。然后,就用一句话点破了 GPT-4.5 和那些推理模型的最大区别:
……这次发布其实就是在质感上给大家展示,纯粹靠堆预训练算力,能把底子垫到什么程度。
不过他也补了一句:说实话,跟 GPT-4 比起来,GPT-4.5 的提升非常微妙,非常细腻,甚至大多数情况下根本分不出来。
但他还是做了个实验。他搞了个投票,让大家盲测两组模型 A 和 B,在五个不同的对话场景里比一比,看哪边的感觉更好(重点看创意、幽默感、文字风格这些,也就是 GPT-4.5 主打的那些软实力)。我也参加了。老实说,真挺难区分的。我隐约觉得其中一个更像现在的 GPT-4o,风格更新、更活泼一点,我就选了那个。
但其他人完全不这么看。Karpathy 后来公开了投票结果,大部分人其实还是更喜欢 GPT-4:
• 问题 1:GPT-4.5 是 A;56% 的人选了它。
• 问题 2:GPT-4.5 是 B;43% 的人选了它。
• 问题 3:GPT-4.5 是 A;35% 的人选了它。
• 问题 4:GPT-4.5 是 A;35% 的人选了它。
• 问题 5:GPT-4.5 是 B;36% 的人选了它。
他自己也说,这挺尴尬的。
最后 Karpathy 总结说:
可能是高品味的测试者能感受到 GPT-4.5 那种微妙的新质感,但被低品味的大众给淹没了。也可能是大家都在瞎猜。也可能是这几组测试题本身选得就不太行。也可能是两者本来就差不多。或者这些原因全加一块。所以最后他说,还是等更大规模、更专业的 LM Arena 测试结果吧。但至少他自己玩了两天之后的感受是:GPT-4.5 确实有点新东西,创意和文笔上确实多了点灵气,讲段子、说相声、搞吐槽都更有意思了。
我其实一点都不惊讶,如果大部分人最后还是更喜欢 GPT-4 或 GPT-4o。这反而说明 GPT-4.5 确实做对了。毕竟,大家平时更爱看的是 AI 屎诗,而不是人类写的好诗。我们不能指望所有人都是高品味测试员,对吧?
VI. 不能给作者惊喜,就别指望给读者惊喜
我一直在想,AI 写作到底还能变多好?
这个东西我们怎么量化?为啥 AI 聊天机器人到现在还是蠢萌蠢萌的,尤其是在唯一真正重要的“人味儿”评测里——这个评测我们早就忘了:是不是更像个有血有肉的人?这不就是 Moravec 悖论再现吗?最难的,永远是我们觉得最简单的事儿。写点好东西,可真没那么容易。
说实话,这么多年大家太快就冲着 STEM 去了,数学、代码这堆硬指标卷疯了,但其实模型在“写东西、聊天、搞笑、创意”这些事上,远远没练到家。从这个角度看,GPT-4.5 其实是一次亡羊补牢式的回归。(不过,说实话,我也不觉得 GPT-4.5 在写作上真的有多炸裂,只是比以前稍微顺点而已,这真不咋地。)
最后,我想用一段话收尾,顺便解释下为什么我一直觉得:写作这事儿,永远是语言模型最难啃的骨头。
AI 写出来的东西,没有人类手笔指导的话,总感觉是平的。为啥?因为语言模型天生缺一样东西——惊喜感。它们的训练目标,正好就是别给你惊喜,它们的任务是预测最可能的词儿,而不是偶尔突然灵光一闪,冒出个让你拍大腿的词儿。但最好的写作,恰恰是靠惊喜活着的。
诗人罗伯特·弗罗斯特说过:“作者自己没有惊喜,读者更别想有。”
你要是写出来的东西自己都觉得无聊,那读的人更是打哈欠。
最可惜的是,大语言模型的训练目标,恰好是:选最可能的词,而不是——哪怕偶尔——选个不那么可能的。我说的不是选个完全胡说八道的词——人类好作者的本事,正是能精准地选出那种既不普通、也不离谱的词,像树枝一样,拐出个你意想不到但又特别顺的弯儿。这种感觉,非常难找,更难掌握。
AI 现在,还离这个境界远着呢。按照现在这套路,可能永远也到不了。