1、背景
项目有一张基础表查询量很大,开始了hibernate的二级缓存,使用外部服务器memcached单独存储。
中间件memcached服务需要做迁移。双主架构,一台迁移,另一台提供服务。迁移过程中有一个应用的一个节点连接不上memcached服务器。
2、经过
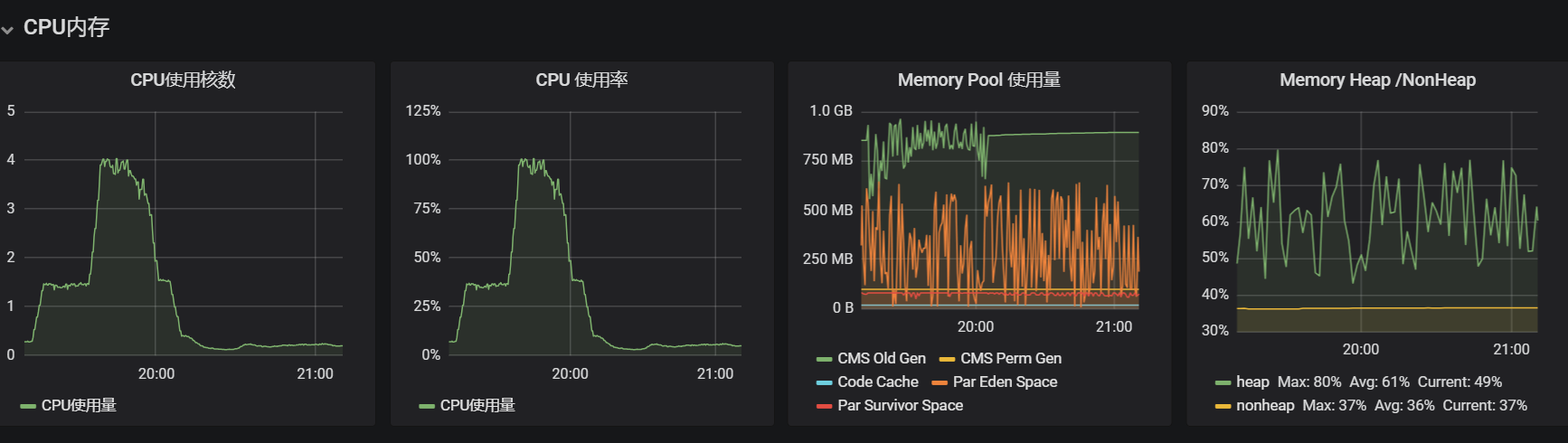
19:13-19:18,cpu使用率直线上升从7%-37%,数据库连接使用率从30%-65%,同时gc回收时间和次数也在直线飙升。
19:18-19:34,cpu使用率和gc情况保持不变,数据库连接使用率后期开始上升到85%。
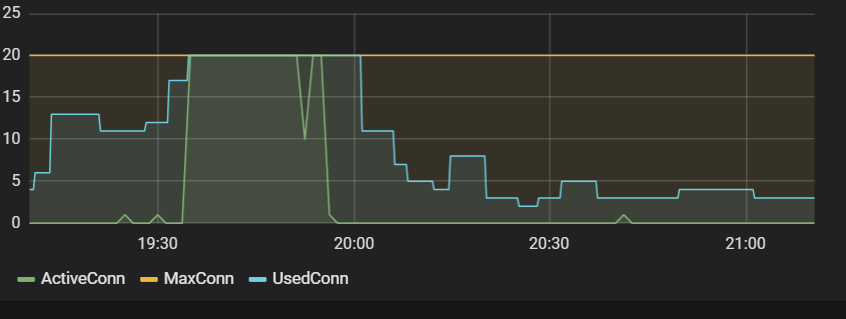
19:35-20:00,数据库连接使用率达到100%,cpu使用率快速上升到100%。
20:00之后开始逐渐恢复正常。

3、分析
第一阶段(Memcached 失效,GC 时间、CPU、数据库连接数同步上升)
memcached失效后,所有原本命中缓存的数据都需要去查询数据库,数据库连接池使用率从30%上升到85%,说明请求量增加,但数据库还能勉强支撑。
二级缓存失效,Hibernate 每次查询都要创建大量对象,这些 短生命周期对象 进入 Eden 区(新生代),导致 Young GC 频繁触发。
第二阶段(数据库连接池耗尽,CPU 迅速飙升到 100%)
所有可用连接都被占满。新来的查询请求无法获得连接,只能等待,导致请求堆积。应用线程不断增加,CPU 迅速上升到 100%,此时线程过多瞪大数据库连接,会导致大量上下文切换。
此时cpu消耗主要集中在:
线程上下文切换(大量线程等待数据库连接)。
GC 进一步加剧(更多对象堆积,Full GC 开始触发)。
Memcached 连接重试异常处理(如果每次查询都尝试连接 Memcached,会导致额外的 CPU 消耗)。
参数正常交易开始受影响,出现交易报错问题。
第三阶段(恢复正常)
由于 Hibernate 二级缓存重新生效,大量查询 重新走缓存,数据库负载骤降。数据库连接池开始 释放连接,线程不再大量等待数据库查询。



![[编程笔记] ant-design中ProLayout组件左侧菜单数据刷新问题](https://img2024.cnblogs.com/blog/784108/202503/784108-20250305164958071-1392682195.png)

