探秘Transformer系列之(10)--- 自注意力
- 探秘Transformer系列之(10)--- 自注意力
- 0x00 概述
- 0x01 原理
- 1.1 设计思路
- 1.2 输入
- 1.3 QKV解析
- 心理学角度
- 数据库角度
- seq2seq角度
- 重构词向量角度
- 相互操作
- 提取特征
- 加权求和
- 1.4 小结
- 0x02 实现
- 2.1 权重矩阵
- 2.2 计算过程
- 2.3 点积注意力函数
- 方案选择
- 解读
- 2.4 softmax
- 定义
- 算法
- 必要性
- 缺点
- 改进
- Log-Softmax
- Hierarchical Softmax(H-Softmax)
- adaptive softmax
- 2.5 缩放
- 结论
- 问题推导
- 方差变大
- 元素间差值变大
- softmax退化
- 梯度消失
- 如何降低方差?
- 熵的作用
- 2.6 小结
- 0x03 实现
- 3.1 哈佛代码
- 输入&输出
- 图例&代码
- 再分析注意力
- 3.2 llama3
- 3.1 哈佛代码
- 0x04 优化
- 4.1 优化策略
- 从序列角度优化
- 从多头角度优化
- 从软硬件层面优化 MHA
- 从其它角度优化
- 4.2 案例
- 注意力权重细化
- 线性注意力
- PolaFormer
- 研究背景
- 思路
- MiniMax-01
- 模型架构
- Lightning Attention
- Hybrid-lightning
- Transformer²
- 研究背景
- 自适应性
- SVD
- 研究动机
- 思路
- 奇异值微调(SVF)
- 自适应性
- 研究背景
- Titans
- 研究背景和动机
- 核心创新
- Titans架构
- 长期记忆
- 融合记忆
- SANA
- 4.1 优化策略
- 0xFF 参考
0x00 概述
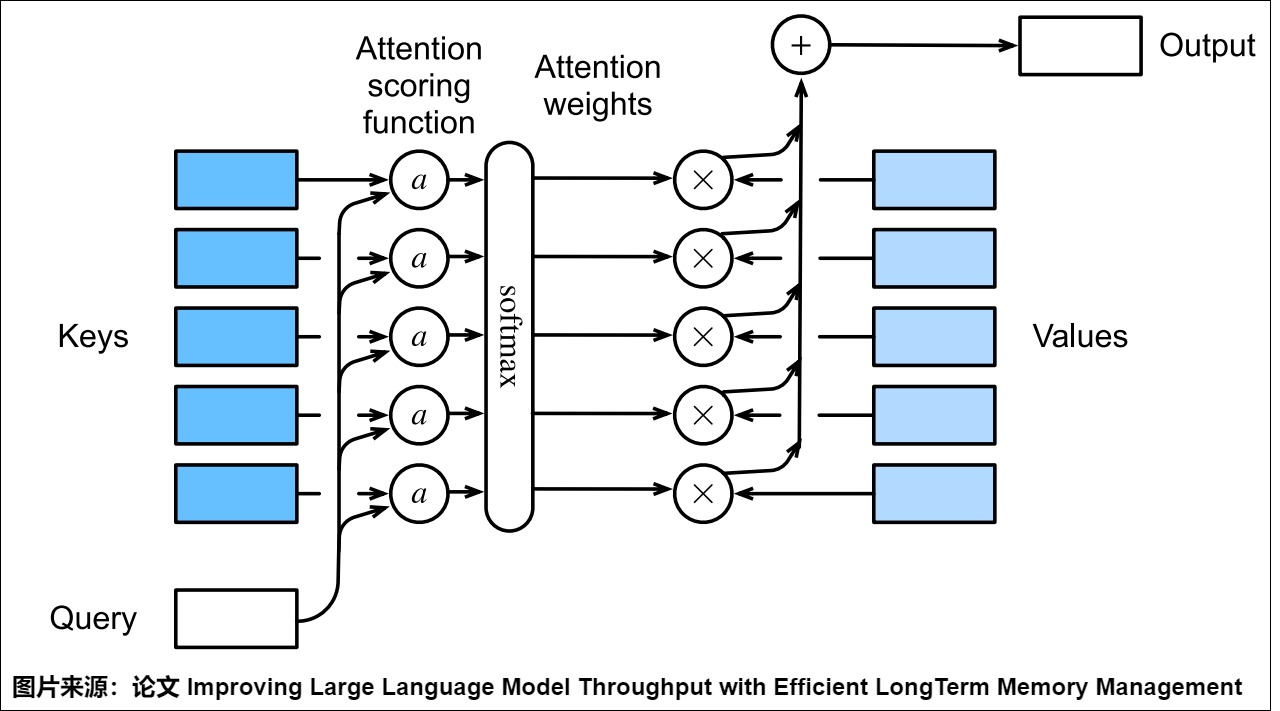
Transformer的核心所在或者说与其他架构的关键区别之处是自注意力机制,其允许模型在处理一个句子时,考虑句子中每个单词与其他所有单词的依赖关系,并使用这些信息来捕捉句子的内部结构和表示,最终计算单词之间的关联度(权重)。我们可以把自注意力机制分为三个阶段:
- 输入:从前文我们可以了解到,注意力机制接受查询(query)、键(key)和值(value)三个输入,但是对于自注意力来说,只有一个输入序列,Q、K、V都是来自于这个序列。这个输入序列是一个向量列表,且向量之间有一定的关系。以机器翻译为例,输入序列就是源语句或者目标语句,语句中每个token对应一个向量。
- 计算:自注意力机制会计算序列中每个向量与序列中其他向量的关系(也就是每个单词与句子中所有单词的关系),使得序列中的每个token都能感知其他token。针对当前向量,自注意力机制会接受计算查询(当前token)与所有键(感兴趣的token)的点积,应用Softmax函数在点积上以获取权重,并使用权重对所有与之关联的值进行加权平均。这样就可以把对其他单词的“理解”融入到当前处理的单词中。
- 输出:一个序列,比如一个向量列表,但是列表之中所有向量都考虑了其上下文关系,是蕴含了序列内部关系的全局特征表示。
具体如下图所示。
0x01 原理
1.1 设计思路
自注意力并非Transformer首创,但之前在其他模型上效果不甚理想。所以我们好奇为什么Transformer依然使用自注意力呢,论文是这样解释其设计思路:
Motivating our use of self-attention we consider three desiderata. One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required. The third is the path length between long-range dependencies in the network.
三个考虑因素我们具体解析如下。
- 每层的总计算复杂度。Transformer的自注意力使用了缩放点积注意力评分函数,相比于加性注意力减少了计算量,效果也是相似的。
- 并行计算。自注意力是可以并行化计算的,并行化计算量可以用所需的序列操作的最小数目来衡量。
- 网络中长距离依赖关系之间的路径长度。RNN捕捉词与词之间关系需要把句子从头看到尾,CNN需要层叠多个卷积层才能捕捉词与词之间关系,而自注意力是完全并行的,每个词可以直接关联。
虽然有若干优势,但是知易行难,Transformer如何做到?我们接下来一步一步进行分析。
1.2 输入
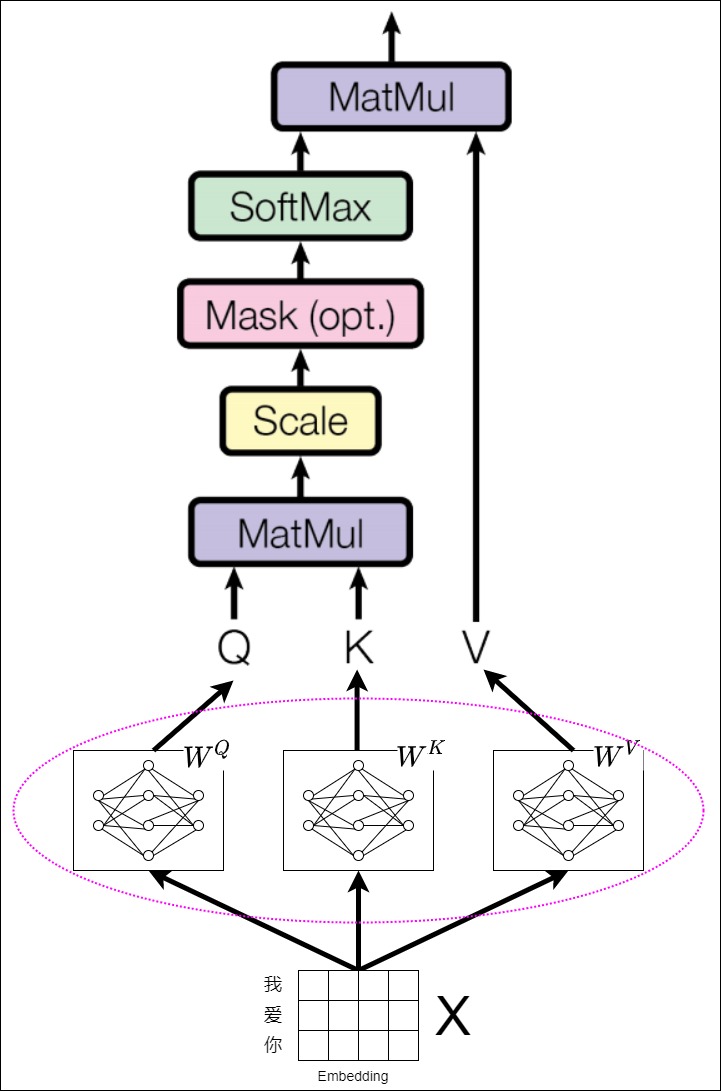
从宏观角度来说,Transformer只有一个输入序列,由这个序列派生出来Q、K和V。具体如下图所示。
从微观角度看,以编码器为例,自注意力的Q、K、V的来源有两种:
- 第一个编码器层的QKV由输向量x组成的矩阵X进行线性变化而来,线性变化就是用\(W^Q,W^K,W^V\)进行矩阵乘法。
- 后续编码器层的QKV由上一个编码器层的输出经过线性变化而来。
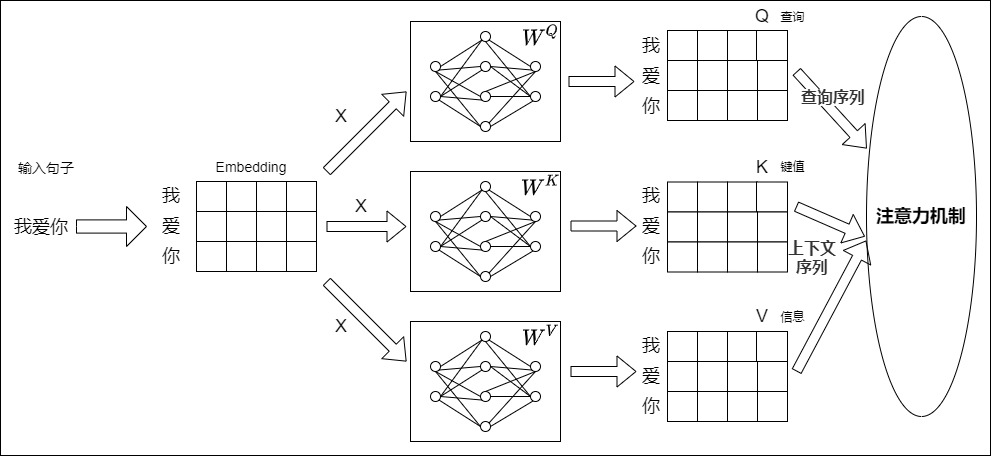
我们接下来以第一个编码器层为例,从源序列中的单个词开始来跟踪它们在 Transformer 中的路径。为了解释和可视化,我们暂时不用关心细节,只跟踪每个词对应的"行"。
假如我们进行英译中,输入中文:我爱你。假定模型维度为d,输入序列长度为L。源序列首先通过嵌入和位置编码层,该层为序列中的每个单词生成嵌入向量,这些嵌入向量构成的矩阵就是X。
输入序列接下来会通过三个矩阵\(\mathbf{W}^K \in \mathbb{R}^{d \times d_k}\),\(\mathbf{W}^Q \in \mathbb{R}^{d \times d_q}\),\(\mathbf{W}^V \in \mathbb{R}^{d \times d_v}\)进行转换。具体来说,输入序列的每一个元素\(x_i \in \mathbb{R}^{d}\)会分别乘以这三个矩阵,得到
把L个\(q_i\)对堆叠起来就得到矩阵\(\mathbf{Q} \in \mathbb{R}^{L \times d_q}\),类似可以得到矩阵\(\mathbf{K} \in \mathbb{R}^{L \times d_k}\),\(\mathbf{V} \in \mathbb{R}^{L \times d_v}\)。或者直接用矩阵形式表达:
这个三个独立的矩阵Q、K、V会被用来计算注意力得分。这些矩阵的每一 "行 "都是一个向量,对应于源序列中的一个词。每个这样的"行"都是通过一系列的诸如嵌入、位置编码和线性变换等转换,从其相应的源词中产生。而所有这些的转换都是可训练的操作。这意味着在这些操作中使用的权重不是预先确定的,而是利用反向传播机制进行学习得到的。
1.3 QKV解析
自注意力机制中第一步就是用Token来生成查询向量、键向量和值向量,也就是用到了query,key,value(各种相关论文、网址之中也缩写为q、k、v)这三个概念。Query向量代表当前正在处理的token或位置,它表示模型需要“查询”的信息。Key向量代表序列中每个token的唯一标识,用于与Query进行比较。Value向量包含序列中每个token的实际内容或特征,它对生成当前token的输出有贡献。
要理解LLM的底层实现原理,就必须要了解Transformers Block里面的QKV矩阵,因为前沿的大模型研究工作很大一部分就是着QKV矩阵去做的,比如注意力、量化、低秩压缩等等,目标是在保证效果不变坏的前提下,进行对性能和存储的极致压缩。其本质原因是因为QKV权重占比着大语言模型50%以上的权重比例,在推理过程中,QKV存储量还会随着上下文长度的增长而线性增长,计算量也平方增加。可以说,query,key,value对于Transformers 和自注意力机制至关重要。
相信大家一直都有个疑问,为什么要取QKV这些名字?这一套思想到底怎么去理解?之前篇幅中介绍过QKV,但是始终没有深入,本篇会进行详细分析。因为深度学习其实是带有实践性质的科学,尚未找到确切的理论分析。所以接下来我们从不同理解的角度来阐释,希望读者能够从其中对QKV有所理解。
心理学角度
有研究人员发现,注意力机制可以追溯到美国心理学之父威廉·詹姆斯在19世纪90年代提出的非自主性提示(nonvolitional cue)、自主性提示(volitional cue)和感官输入(Sensory inputs)这几个概念。而这三个概念就分别可以对应到Key张量,Query张量和与Key有对应关系的Value张量,然后由这三者构建了注意力机制。
我们用个通俗例子来分析下。本来你去买盐(带有目的性的关注度,即自主性提示),结果你到了商店,发现了变形金刚,你注意力都被变形金刚(下意识的关注度,即非自主性提示)吸引了。我们可以得到:
-
Key:一系列物品(盐和变形金刚)。
-
Value:这一系列物品对人下意识的吸引力(在你下意识中,变形金刚的吸引力肯定比盐要高)。
-
Query:你想要的物品(盐)。
注意力作用就是让盐(目标物品)所对应的权重值变高。这样使用该'权重向量’乘‘key’后,即使目标物品“下意识的吸引力(即key)”不够高,但是因为目标物品对应的权重高,其他物品对应的权重小,故选择到目标物品的可能性也会变大。
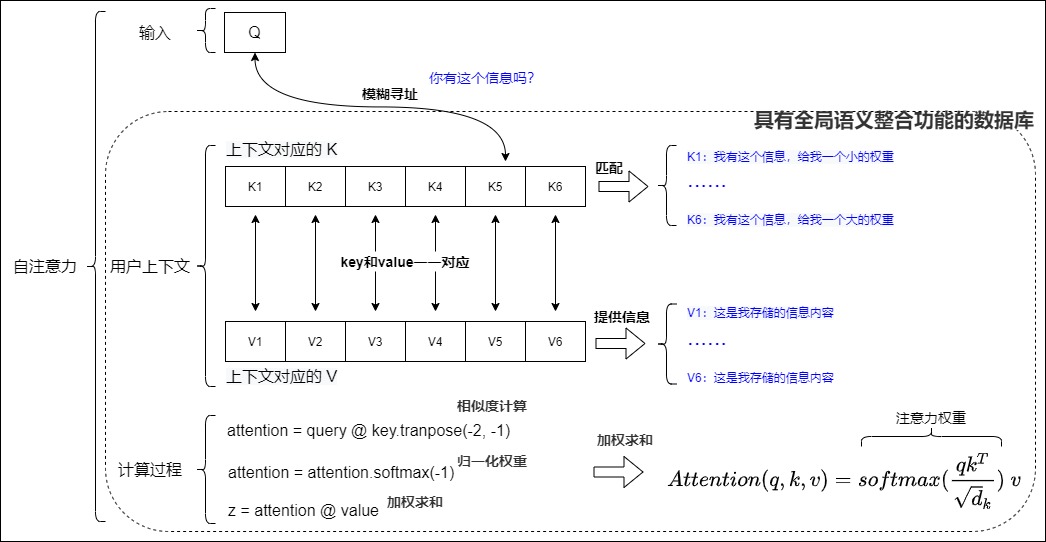
数据库角度
query,key,value的名称也暗示了整个注意力计算的思路,因此我们从搜索领域的业务来看Q、K、V可能更好理解。我们把注意力机制看作是一种模糊寻址,或者说是一个模糊的、可微分的、向量化的数据库(或者字典)查找机制。Q、K、V这三者的关系就是:找到与现有数据(Query)相似或者相关的数据(Key)所对应的内容(Value)。其具体特点如下:
- Key和Value是数据库的组件。
- 数据库中每个元素由地址Key和值Value组成(一个<Key,Value>数据对)。或者说,Key这个地址里面就存放了Value。
- Key是地址,就是要查找的位置。该地址总结了地址中Value的特征,或者说Key可以体现Value上的语义信息。
- Value是与地址Key相关联的值,是表征语义的真实数据,是对外提供的使用者所需的内容。
- Query是查询信息,是任务相关的变量。假设当前有个Key=Query的查询,该查询会通过Query和存储器内所有元素Key的地址进行相似性比较来寻址,其目的是取出数据库中对应的Value值。自注意力机制中这种Q和K一问一答的形式,问的就是Q和K两个词之间的紧密程度。直观地说,Key是Query(我们正在寻找什么)和Value(我们将实际获得什么)之间的桥梁。
- 普通的字典查找是精确匹配,即依据匹配的键来返回其对应的值,而且只从存储内容里面找出一条内容。而注意力机制是向量化+模糊匹配+合并的组合使用。其会根据Query和Key的相似性来计算每个Key的相似度或者匹配程度(即注意力权重)。然后从每个Key地址都会取出Value,并依据匹配程度对这些value做加权求和,这个相似度得分决定了相应Value在最终输出中的权重。
用通俗例子来讲解,假如我们在淘宝上进搜索”李宁鞋“,Query(Q)就是你在搜索栏输入的查询内容。Key(K)就是在页面上返回的商品描述、标题,其实就是数据库中与候选商品相关的关键字。Value(V)就是李宁商品本身。注意力机制就是这个查询过程,即注意力是把你要查询的Q与淘宝数据库中的K进行比较,计算出这些K与Q的相似度,最终返回相似度最高的若干商品V。流程如下:
- 用Query与数据库内所有Keys进行计算相似度(查询的相关性,即你有多大概率是我要查的东西)。
- 得到相似度之后,对结果进行排序。
- 基于相似度排序结果,得到需要获取的商品ID
- 依据商品ID来获取对应的Values。
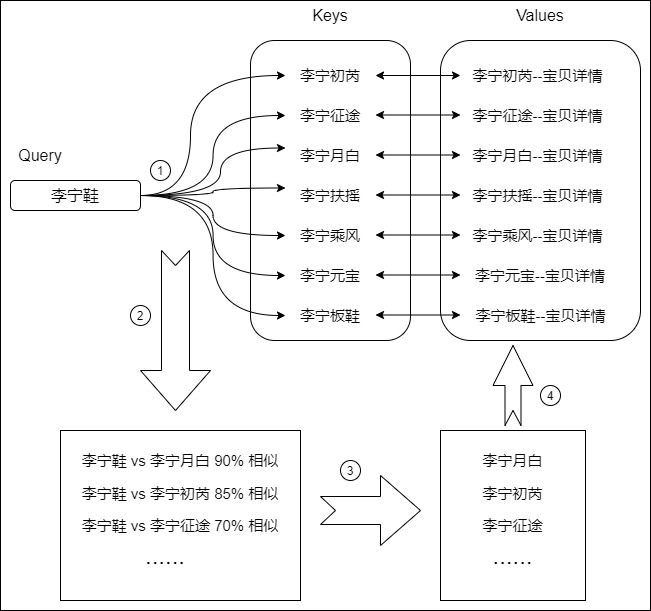
因此,自注意力机制中的QKV思想,本质是一个具有全局语义整合功能的数据库。<Key,Value>数据对就是数据库的元素,Q就是任务相关的查询向量。
下图从数据库角度展示了自注意力的细节。
seq2seq角度
让我们回到具体任务上来分析,可能会更加清晰一点。比如在机器翻译任务中,query可以定义成解码器中某一步的隐状态,即对上一个词的预测输出。key是编码器中每个时间步的隐状态,我们用每一个query对所有key都做一个对齐,于是解码器的每一步都会得到一个不一样的对齐向量。或者说,编码器的编码序列(Encoded sequence)提供key和value 。Hidden state of Decoder 提供query 。这就好比解码器要去编码器的编码序列那里查字典一样。
重构词向量角度
前面我们从数据库角度来看到如何寻址获取讯息,其最终目的是输出一个新向量。在新的向量中,每一个维度的数值都是由几个词向量在这一维度的数值加权求和得来的。因此,自注意力机制的核心是重构词向量(查询+聚合),每个输入单词的编码输出都会通过注意力机制引入其余单词的编码信息。
相互操作
人类在读一篇文章时,为了理解一句话的意思,你不仅会关注这句话本身,还会回看上下文中相关的其他句子或词语。我们还是以之前两个句子为例进行解释。
- Several distributor transformers had fallen from the poles, and secondary wires were down.
- Transformer models have emerged as the most widely used architecture in applications such as natural language processing and image classification.
如何才能对“Transformer”这个多义词进行语义区分?我们必须考虑单词的上下文才能更好的把单词的语义识别出来,即不仅仅要考虑到词本身,还要考虑其他词对这个词的影响,也就是语境的影响。比如第一个句子的“pole”、”fallen”和“wires”这几个邻近单词暗示了“Transformer”和物理环境相关。第二个句子的“model”和“natural language processing and image classification”则直接告诉我们此处的“Transformer”是深度学习相关概念。最终我们通过上下文语境(句子中的其他词)可以推断“Transformer”的准确含义。
原理我们知道,但是如何实践?如何通过句子中的其它词来推断?人类可以知道哪些词提供了上下文,但计算机却毫无头绪,因为计算机只处理数字。解决方案就是注意力机制在Transformer中所模拟的过程。
Transformer 通过点积这个提取特征的操作将输入序列中的每个词与其他词关联起来,也就是词之间进行互相操作。然后通过加权求和把这些词加起来,最终可以捕捉到某个特定的词和句子中其他每个词之间的一些互动。于是修改后的词如下:
-
transformer 1 = 0.7 transformer + 0.1 pole + 0.1 fallen + 0.1 wires
-
transformer 2 = 0.6 transformer + 0.1 language + 0.1 image + 0.2 model
最终两个transformer单词就通过和句子中其它单词的操作完成了对本身语义的重构。
我们接下来具体看看提取特征和加权求和这两个操作。
提取特征
K提取的特征是如何获得的呢?根据自注意力的思想和人脑的机制,我们需要先看过所有项才能准确地定义某一个项。因此,对于每一个查询语句Q,注意力机制会:
- 用这个Query和每个Key通过内积的方式来计算出相似度或者相关性,以此来决定哪个元素会对目标元素造成多少影响(即Key和Query会得出对齐系数)。Key与Query越相似或者说越相关,Value的影响力就越大,越应该承担更多的对输入的预测。
- 然后注意力机制会对点积结果进行一个softmax操作,使得所有value的权重总和为1。这是为了保证所有源元素贡献的特征总量保持一定。如果有多个key都与query高度相似,那么它们各自的通道都会只打开一部分(好像“注意力分散在这几个源元素上”)。从这个角度来看,可以理解为输出是在value之间根据key-query的相似度进行内插值的结果。很明显,这个输出表征携带了其它单词的信息。
- 最后得到的矩阵 Y ,就是输入矩阵 X 融合了上下文信息得到的在隐空间的语义矩阵,每一行代表一个token。
如果是训练过程,则在拿到Y之后,模型会通过损失函数进行计算,最终经过反向传播后,Q就能逐渐学习到V的特征。这个机制让模型可以基于相同的注意力机制学习到不同的行为,并且能够捕获序列内各种范围的依赖关系。
加权求和
让我们通过一个真实例子来理解加权求和操作。
我们希望了解郁达夫(Query),但是因为人的精力有限,所以需要把有限的精力集中在重点信息上,这样可以用更少的资源快速获取最有用的信息,效果更好。图书馆(Source)里面有很多书(Value),我们看书就相当于获取其书中的详细信息(Value)。为了提升效率,我们给每本书做了编号和信息摘要(Key)。于是我们可以通过Key搜索出来很多书,比如《薄奠》,《沉沦》,《迟桂花》,《春风沉醉的晚上》,《归航》等等,也能搜出来《大众文艺》(郁达夫曾任主编)。
通过将Query与Key中携带的信息摘要相比较,我们可以知道它们的相关程度有多高。相关性越高的书,其权重越大。前面几本书的权重就高,需要分配更多的注意力来重点看,《大众文艺》的权重就显然要略低,大致浏览即可。
假如我们一共要花费11小时在了解郁达夫上。我们会分别花费2小时在《薄奠》,《沉沦》,《迟桂花》,《春风沉醉的晚上》,《归航》,花费1小时在《大众文艺》上。我们把时间归一化成和为1的概率值,得到[0.18, 0.18, 0.18, 0.18, 0.18, 0.09],所以郁达夫 = 0.18《薄奠》+ 0.18《沉沦》+ 0.18《迟桂花》+ 0.18《春风沉醉的晚上》+0.18《归航》+0.09《大众文艺》。最终得到的信息是所有书籍内容按照权重综合起来的结果。这样当我们全部看完以上几本书后,就对郁达夫有一个全面的了解,就是加权求和。
注意力机制本质就是使用 Q 和 K 来计算出“注意力权重“,然后利用注意力权重对V进行加权求和。从机制上看,注意力机制聚焦的过程体现在权重系数上,权重越大表示投射更多的注意力在对应的值上,即权重代表了信息的重要性。注意力机制可以被解释为将多个局部信息源路由到一个局部表征的全局树结构中。在这个例子中,我们计算相关性就相当于注意力机制中的 \(QK^T\) ,归一化就是softmax操作,然后通过加权求和取得最后的阅读量/特征向量。
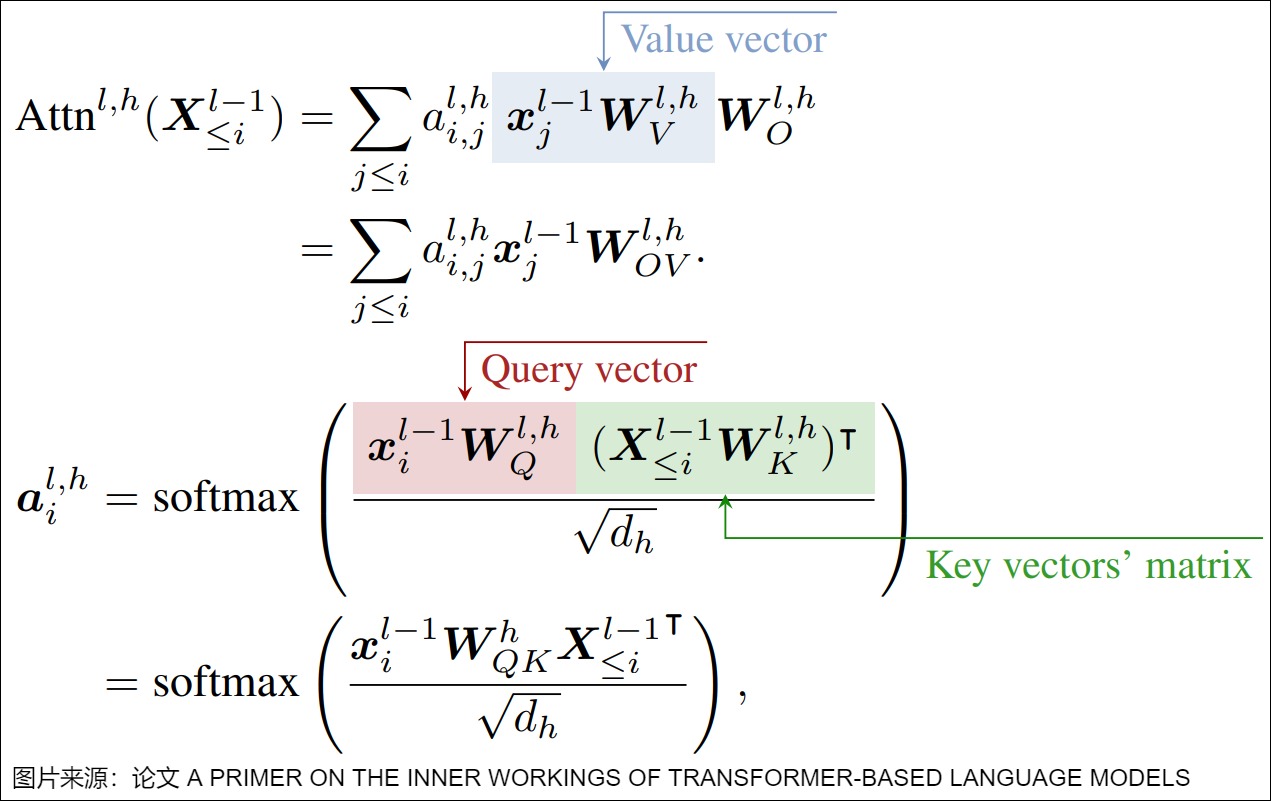
Elhage重构了注意力头的表达形式(仍然等价于vanilla Transformer的设计),重构的表示可以表达为如下公式,可以看出来相互操作、提取特征和加权求和的特点。

1.4 小结
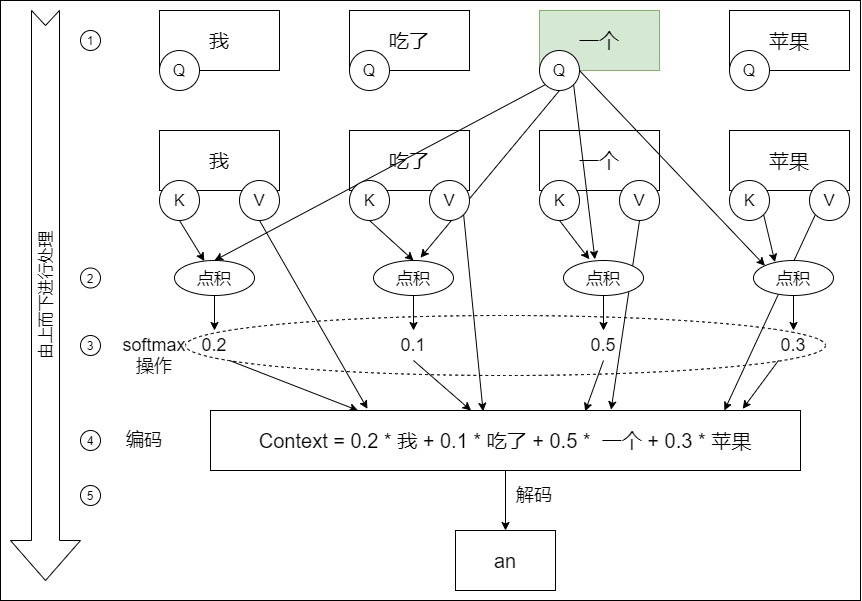
我们以”我吃了一个苹果“为例来看看自注意力的流程。
- 首先确定哪个目标token来作自注意力机制,这个目标token是”一个“,即让”一个“来判断它和其他三个词之间的关系
- ”一个“会对”我吃了一个苹果“这句话中所有token都做一遍点积,然后做softmax操作做归一化,生成权重。
- 用权重和V向量相乘,得到加权之后的向量,即”一个“可以用0.2 * 我 、0.1 * 吃了、 0.5 * 一个和 0.3 * 苹果 来组合表示。所以”一个“的带有词关联性的表示为:\(一个 = 0.2 \times 我 + 0.1 \times 吃了 + 0.5 \times 一个 + 0.3 \times 苹果\)。在新的向量中,每一个维度的数值都是由几个词向量在这一维度的数值加权求和得来的,这个新的向量就是"一个"词向量经过注意力机制加权求和之后的表示,该词具备词关联性。
- 解码输出”an“。
可以看出,“一个”在全句中,除了自己之外,与“苹果”关联度最大,其次是“我”。所以“一个”这个词也可以理解为“我-一个-苹果”。这便把“一个”在这句话中的本质通过“变形”给体现出来了。“一个”本身并没有变,而是通过“变形”展示出了另外一种变体状态“我-一个-苹果”。外在没变,灵魂变了。
可以看到,自注意力机制是一种动态的、数据驱动的变换,是对输入向量空间的一种动态变换。这种变换不是固定的,而是依赖于输入数据的内容来决定的。因此,注意力的本质思想可以改写为如下公式:通过计算相似性得出权重最后加权求和。
0x02 实现
2.1 权重矩阵
现在的神经网络很少有将 Word Embedding 直接参与一些网络结构的计算,一般都会先做一个线性变换。实际上,Transformer是把每个 token 的 Embedding 向量x分别乘以三个不同的权重矩阵\(W^T,W^Q,W^V\),作三次线性投影(或称为线性变换),派生出Q、K、V三个矩阵(注意,这里提到的“权重”,是指神经网络中的连接权重,与Attention中token之间的语义关联权重不是一个意思)。而且,每个Transformer block都有自己的\(W^T,W^Q,W^V\)。
这三个权重矩阵是在模型训练过程中通过反向传播训练出来的。在训练阶段,模型会对这三个权重矩阵进行随机初始化。在模型的执行阶段(预测阶段),这三个矩阵是固定的,即 Transformer 神经网络架构中固定的节点连接权重,是早就被预先训练好的了(Pre-Trained)。\(W^T,W^Q,W^V\)这三个矩阵实际上是模型学会的分配Q,K,V的逻辑。
为什么要引入权重矩阵?或者说,为什么不直接使用 X 而要对其进行线性变换?为何要从一个序列中的每一个 token 的 Embedding 派生出三个向量Q、K、V(即查询向量、键向量和值向量)呢?主要可以从如下方面进行思考。
首先看看直接使用embedding的缺点。
- 输入的 Embedding 其实只做了一次线性变换,特征提取能力或者表示学习的能力及其有限。
- 一个点积操作中没有什么可以学的参数。为了识别不一样的模式,我们希望有不一样的计算相似度的办法以及更多的参数。
- 如果直接对原始的embedding做自注意力操作,则计算的相似度结果是个对称矩阵,对角向上的值一定是最大的。因为每个字/词必定最关心自己,这样背离了自注意力操作的初衷。
- \(Q*K^T\)大概率会得到一个类似单位矩阵的attention矩阵,这样self-attention就退化成一个point-wise线性映射,捕捉注意力的能力就会受限,i,j 位置之间的前后向注意力就会变得一样。而我们一般期望两个token在一句话中先后顺序也能反映一定的不同信息。对于两个词语,A对于B的重要性,不一定等同于B对A的重要性。比如:”A爱B“和”B爱A“的程度不一定一样。
- 这个对称矩阵的对角线上的值大概率是本行最大的,这样 softmax 后对角线上的注意力一定是本行最大,也就是不论任何位置任何搭配,每个token的注意力几乎全在自己身上,这样违背了Transformer用自注意力机制捕捉上下文信息的初衷。
我们再看看使用权重矩阵的优势所在。
- 匹配。\(\alpha_{ij}\)要通过计算\(ℎ_i\)和\(s_j\)之间的关系得到,一个最简单的办法就是把这两个矩阵直接相乘。但是这样可能会有问题:两个矩阵可能形状不匹配,没法直接做矩阵乘法。而给这两个矩阵分别左乘一个矩阵\(W^K\)和\(W^Q\)就可以解决上述两个问题。
- 可学习。在注意力机制中,每一个单词的query, key, value应该不仅仅只和该单词本身有关,而应该是和对应任务相关。每个单词的query, key, value不应该是人工指定的,而应该是可学习的。因此,我们可以用可学习的参数来描述从词嵌入到query, key, value的变换过程。这样经过大量训练之后,每个元素都会找到完成各自任务所需的最合适的query、key和value。这些相关的训练参数就在三个权重矩阵中。
- 增加拟合能力。三个权重矩阵都是可训练的,这增加了模型可学习的参数量,扩展了特征空间,增加了模型的拟合能力。
- 信息交换。我们指定输入矩阵X的第 i 行表示第 i 个时刻的输入 \(x_i\)。对于此矩阵中的向量来说,权重矩阵\(W^T,W^Q,W^V\)在整体运行过程中是共享的。即,不同的\(x_i\) 共享了同一个\(W^T,W^Q,W^V\),通过这个操作,\(x_1\)和\(x_2\)已经发生了某种程度上的信息交换。也就是说,单词和单词通过共享权值已经相互发生了一定程度的信息交换。
另外,也许读者会问,既然K和Q都是一样维度,为什么不合用一个权重矩阵呢?或者说,为何要使用三个不同的权重矩阵?使用不同的权重矩阵生成的主要原因是:为了提供更灵活的模型表示能力和捕捉数据中的复杂依赖关系。其实,此处也回答了为何要区分Q、K和V。
- 增加表达能力。加入了不同的线性变换相当于对 x 做了不同的投影,将向量 x 投影到不同空间,这意味着Q和K可以在不同的语义空间中进行表达,有助于模型捕捉更丰富的语义信息和依赖关系。
- 区分不同角色或者说角色分离:在自注意力机制中,Q、K和V扮演着不同的角色。Q代表了我们要查询的信息或者说当前位置希望获得的信息,K代表了我们用来与Q匹配的键或者说序列中各位置能提供的信息,而V代表了一旦找到匹配,我们要提取的值或者说应该从各位置获取的实际内容。使用不同的权重矩阵能够更好地区分这些不同的角色,使用不同的权重矩阵为Q和K提供了能力去捕捉不同的依赖关系,增强了模型对输入数据的理解。提高模型的效果。
- 增加灵活性。如果Q和K使用相同的权重矩阵,则其结果和使用X自身进行点乘的结果相同,那么它们之间的关系会被严格限制在一个固定的模式中,这限制了模型的灵活性。而直接从Q得到V会忽略了通过K来确定相关性的重要性,也减少了模型处理信息的灵活性。
- 并行处理。Transformer模型的设计允许在处理序列时进行高效的并行计算。Q、K、V的独立使得模型可以同时计算整个序列中所有位置的注意力分数,这大大提高了计算效率。
总的来说,虽然在某些情况下使用相同的值进行自身的点乘(或者共享权重矩阵)可能也能工作得很好,但使用不同的权重矩阵为Q和K提供了更大的灵活性和表示能力,有助于提升模型性能和泛化能力。
我们再用三个权重矩阵来细化注意力公式如下。
2.2 计算过程
缩放点积注意力(Scaled Dot-Product Attention)模块的公式如下:
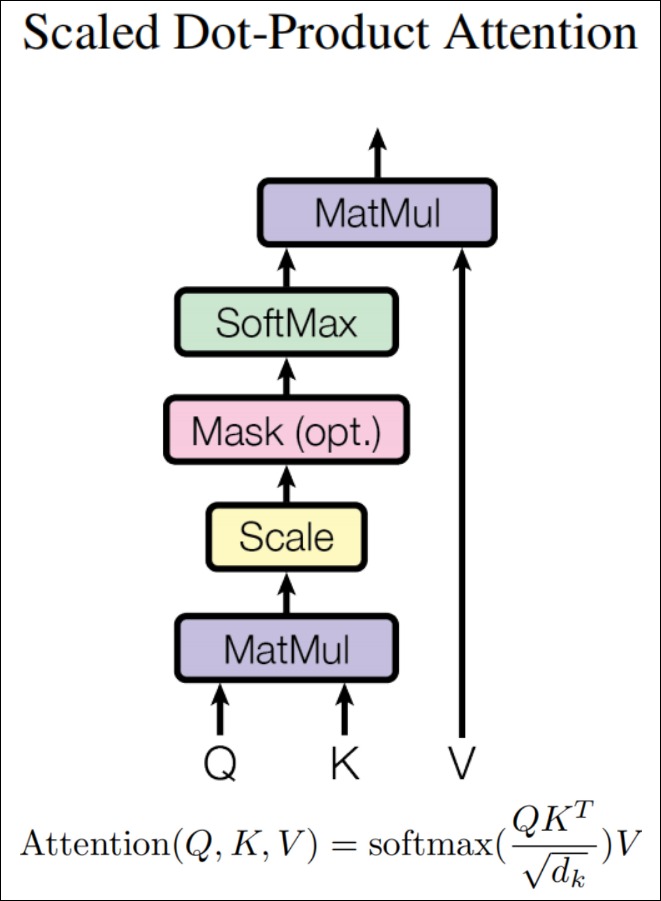
此公式中,\(d_k\)是向量的维度,且\(d_k=d_q=d_v\),如果只设置了一个头,\(d_k\)那就是模型的维度\(d_{model}\),如果设置了8个头,则\(d_k=d_{model}/8\),且如果模型的维度是512维,则 \(\sqrt{d_k}\) 即等于8。Q和K的维度均是\((L,d_k)\),V的维度是\((L,d_v)\),其中L是输入序列长度。\(softmax(QK^T)\)的维度是\((L,L)\),\(Attention(Q,K,V)\)的输出维度是\((L,d_v)\)。
我们梳理下计算过程如下(对应上图中从下到上的顺序):
- 输入。Q、K、V是把输入映射成高维空间的点,它们之间的关系通过后续的变换来捕捉。
- 计算分数(score function)。Query和所有的Key进行相似度计算,得到注意力分数(查询的相关性)。计算公式为\(s_i = a(q, k_i)\)。也就是Q 矩阵和 K矩阵的转置之间做矩阵乘法(即点积)。这一步是计算在高维空间中度量向量之间的相似性。
- 缩放。对得分矩阵scores进行缩放,即将其除以向量维度的平方根\(\sqrt{d_k}\)。
- 掩码。若存在掩码矩阵,则将掩码矩阵中值为True的位置对应的得分矩阵元素置为负无穷。这是由于在整个模型的运行过程中,可能需要根据实际情况来忽略掉一些输入。我们将在下一篇进行详细解释。
- 归一化(alignment function)。对点积结果进行归一化,即使用softmax操作将权值进行归一化,这样可以更加突出重要的权重。计算公式为\(a = softmax(s_i)\)。这一步是将实数域的分数映射到概率分布上。
- 生成结果(context vector function)。使用a对Value进行加权平均的线性变换,可以理解为输出y是在value之间根据key-query的相似度进行内插值。计算公式为\(Attention\ Value=\sum_ia_iv_i\)
从泛函分析的角度来看,Attention机制中的相关性计算和加权求和步骤可以看作是对输入向量空间的一种动态变换。这种变换不是固定的,而是依赖于输入数据的内容来决定的。
我们接下来对上面过程中的一些重点进行详细梳理。
2.3 点积注意力函数
Transformer论文使用了乘法函数或者说点积注意力函数来计算相似度。从抽象代数的角度来看,注意力机制更像是一个关系运算:用两个元素之间的关系(比如相似度)来决两个元素是否属于同一个类。分类之后才会基于输入元素之间的相似性进行加权组合。
方案选择
如下所示,常见的相似度计算有点积(相乘)和相加。
其中拼接相似度是将两个向量拼接起来,然后利用一个可以学习的权重 𝑤 求内积得到相似度,也称为Additive Attention,意思是指的 \(w^T[q;k]=w_1^Tq+w_2^Tk\)。
对应到V则是:
从公式中可以看到,加法方案优点是:
- 可以处理不同维度的key与query(而点积操作要求query和key具有相同的长度)。
- 计算更简单,但是外面套了tanh和v,相当于一个完整的隐层,因此整体复杂度其实和乘法方案接近。
- 虽然在大多数任务中,点乘注意力和加法注意力的性能差异不大,但是在某些长序列任务中,加法注意力可能会略优于点乘注意力。
而且,乘法方案还有一个劣势是:随着向量维度的增大,点乘结果的上限越来越高,点乘结果的差异越来越大,因此计算Attention权重需要加入scaled。
从表现效果来讲,论文”Massive Exploration of Neural Machine Translation Architectures“对此做了对比实验。
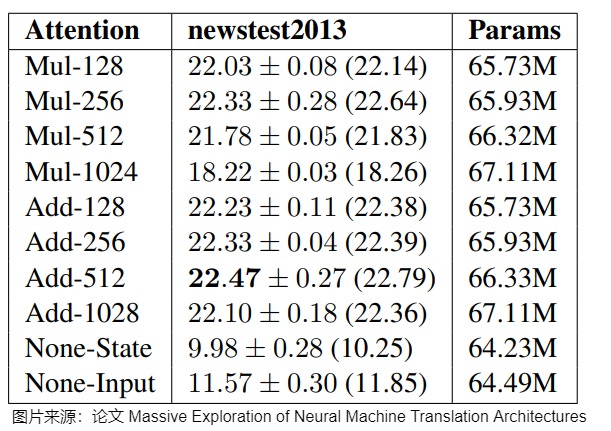
从结果上可以看得出,加法式注意机制略微但始终优于乘法式注意力机制。
那么为何Transformer为何选取点积注意力而非用加法注意力?网络上也有一些讨论,给出的一些思考点是:
- 点乘操作可以通过矩阵乘法高效地在硬件上并行化,从而实现快速计算。
- 点乘注意力能够捕捉查询和键之间的相似度,当查询和键相似时给予更高的权重,这有助于模型捕捉输入序列中的复杂依赖关系。
- 在将表示分割成不同个头进行运算时,使用点乘会更加灵活方便计算。
论文中给出的原因是基于效率和建模能力的考虑,具体如下:

解读
我们对公式作进一步的解读。点积是两个向量的夹角,表征一个向量在另一个向量上的投影。投影值越大,说明两个向量的相关性越高,如果两个向量的夹角为90度,则这两个向量线性无关,完全没有相关性。实际上,点积计算的是对齐后的长度的乘积。因为在机器翻译中,这个向量是词向量,是词在高维空间的数值映射,而词向量之间的高度相关性说明在一定程度上,在关注当前词A的基础上,也会给相似词B更多的关注。
我们再来看看苏剑林大神对公式的精彩解读,借此可以对公式有更加深深刻的理解。
将\(QK^T\)进行拆解,得到两个向量的乘积为:\(q_i⋅k_j=∥q_i∥∥k_j∥cos(q_i,k_j)\),即将两个向量的乘积分解为了两个向量各自模长与夹角余弦的乘积。其中:
- \(∥q_i∥\)只跟当前位置i有关,因此它不改变注意力的相对大小,而只改变稀疏程度。
- \(∥k_j∥\)是其它位置的的张量模长,有能力改变条件概率\(𝑝(𝑗|𝑖)\)的相对大小,但它不涉及到i,j的交互,只能用来表达一些绝对信号。
- \(cos(q_i,k_j)\)就是用来表达𝑖,𝑗的交互,是自由度最大的一项。
为了提高某个位置j的相对重要性,模型有两个选择:
- 增大模长\(∥k_j∥\)。
- 增大\(cos(q_i,k_j)\),即缩小\(q_i\),\(k_j\)的夹角大小。
然而,由于“维度灾难”的存在,在高维空间中显著地改变夹角大小相对来说没有那么容易,所以如果能靠增大模长\(∥k_j∥\)完成的,模型会优先选择通过增大模长\(∥k_j∥\)来完成,这导致的直接后果是:\(cos(q_i,k_j)\)的训练可能并不充分(指被训练过的夹角只是一个有限的集合,而进行长度外推时,它要面对一个更大的集合,从而无法进行正确的预测),这可能是Attention无法长度外推的主要原因。
2.4 softmax
定义
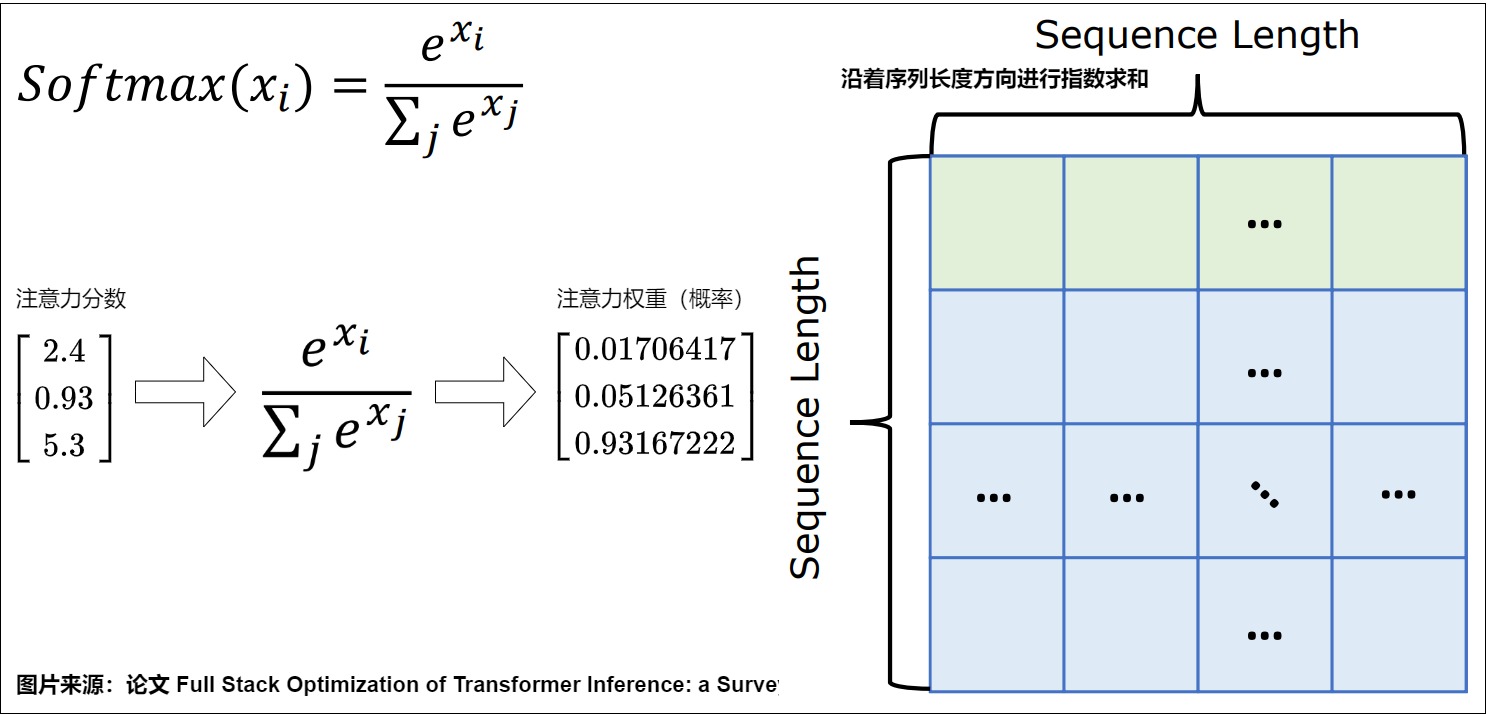
Softmax操作的意义是归一化。我们将没有做softmax归一化之前的结果称为注意力分数,将注意力分数经过softmax归一化后的结果称为注意力权重。给定一个包含 \(n\) 个实数的向量 \(\mathbf{x} = [x_1, x_2, \ldots, x_n]\),Softmax函数将其转换为一个概率分布 \(\mathbf{p} = [p_1, p_2, \ldots, p_n]\),其中每个 $ p_i $ 的计算公式为:
Softmax关键性质如下:
- 非负性:对于任意 \(i\), \(p_i \geq 0\)。
- 归一化:所有输出的和为1,即 \(\sum_{i=1}^n p_i = 1\)。
- 指数函数的使用:指数函数 \(e^{x_i}\) 确保了输出值为正,并且放大了较大的 \(x_i\) 值的差异。
算法
算法流程需要两个循环,首先需要迭代计算分母的和,然后再迭代计算向量中每一个值对应的softmax值,即缩放每一个元素。这个过程需要两次从内存读取和一次写回内存操作。具体算法如下,其中\(d_V\)就是分母。

具体图例如下。
必要性
softmax函数之所以在神经网络中得到广泛应用,是如下原因:
- softmax在推理时可以将输出层的原始输出(logits)转换为有效的概率分布,使得输出具有概率的物理意义,便于解释和计算损失函数,同时保持数值稳定性和对称性。这使得softmax成为多类分类问题中的首选激活函数。
- 在训练时指导模型学习。在神经网络的训练过程中,通常会使用交叉熵损失函数来配合softmax函数。交叉熵损失函数能够量化模型输出的概率分布与真实标签之间的差异,而softmax函数的输出提供了一个概率分布。这种机制使得模型能够在训练过程中更有效地调整权重,以提高对真实概率分布的估计准确性。
为何要在注意力机制中加入softmax?因为看起来softmax是有害无益,比如:
- 如果没有Softmax,则计算复杂度会大幅度降低。因为去除softmax之后,我们得到三个矩阵连乘\(QK^⊤V\),而矩阵乘法是满足结合率的,所以我们可以先算\(K^⊤V\),得到一个d×d的矩阵,然后再用Q左乘它,由于d≪n,所以这样算大致的复杂度只是O(n)。即,去掉Softmax的Attention的复杂度可以降到最理想的线性级别O(n)。
- 如果没有Softmax,则内存占用会大幅度降低。这里我们提前看看FlashAttention所要解决的困境。如果没有softmax的话,我们可以对矩阵采用分块(Tiling)计算。比如,我们可以把Q,K,V沿着N(seqence length维度)切成块,算完一块Q和一块\(K^T\)之后,立刻和一块V进行矩阵矩阵乘法运算(GEMM)。一方面,避免在HBM和SRAM中移动P矩阵,另一方面,P矩阵也不需要被显式分配出来,消除了HBM中$O(N^2) $级别的存储开销。
在注意力机制中加入softmax是因为其有如下优点或者功能。
Softmax操作实质上是在量化地衡量各个词的信息贡献度。因为在注意力机制中,我们在直觉上是希望关注语义上相关的单词,并弱化不相关的单词。这其实是一个多分类问题。在多分类问题中,我们希望神经网络的输出可以反映每个类别的概率,即每个输出节点的值代表了相应类别的概率。这要求输出值必须满足两个条件:首先,每个输出值都应该在0到1之间;其次,所有输出值的和应该等于1。这样,输出就可以被解释为概率分布。直接的线性归一化虽然可以满足第一个条件,但往往不能满足第二个条件,因为它没有考虑分值间的相对差异,不能反映出原始分值中的相对强度或置信度。而softmax函数恰好能够同时满足这两个条件。
Softmax函数通过对每个分值应用指数函数,然后对这些指数值进行归一化处理来转换为概率,这样既保证了每个输出值在0到1之间,又保证了所有输出值之和为1。更重要的是,指数函数的使用放大了分值之间的差异,更好的反映了原始分值中的相对置信度。
在给定一组数组成的向量,Softmax先将这组数的差距拉大(由于exp函数),然后归一化,它实质做的是一个soft版本的argmax操作,或者当作argmax的一种平滑近似。与argmax操作中暴力地选出一个最大值(产生一个one-hot向量)不同,softmax将这种输出作了一定的平滑,即将one-hot输出中最大值对应的1按输入元素值的大小分配给其他位置。因此得到的向量接近一个one-hot向量(接近程度根据这组数的数量级有所不同)。
另外,KQ 两个矩阵相乘,线性乘积下秩不会超过d,softmax后会有一定程度的增秩效果,如果不使用softmax,线性attention的秩更低,表达能力也更差。
缺点
Softmax也存在一些固有限制。比如论文" softmax is not enough (for sharp out-of-distribution)" 指出:softmax函数在输入规模增大时,其输出系数会趋于均匀分布(注意力分散)。即,即便这些token的注意力系数在分布内是尖锐的(even if they were sharp for in-distribution instances),输入更多的token会导致注意力更加分散(或者说注意力的熵变大),从而导致训练和预测的结果不一致。具体如下图所示。
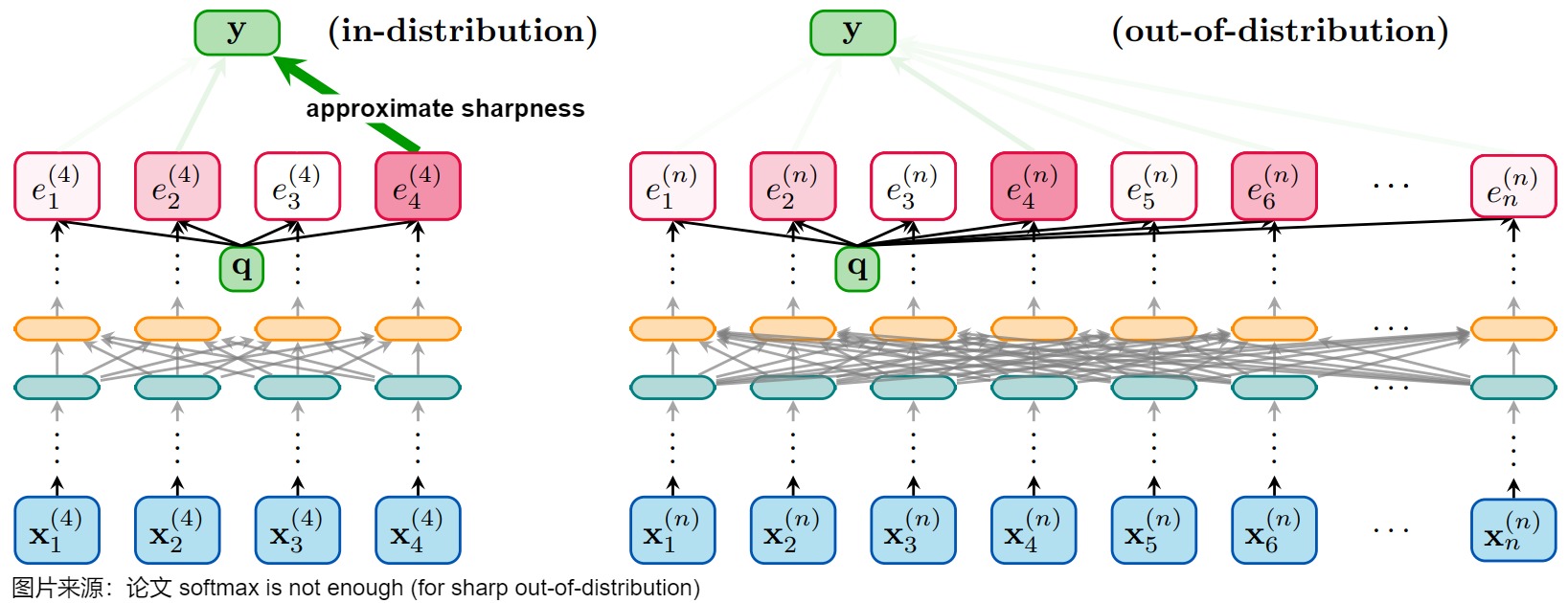
该论文提醒我们,即使是像softmax这样广泛使用的函数,也可能存在其适用范围的局限性,尤其是在处理超出训练分布的数据时。我们需要更加重视模型的泛化能力,并探索更鲁棒的模型架构。
改进
人们对softmax也有很多改进。
Log-Softmax
标准的softmax公式涉及到了很多的求幂和除法,导致计算成本较高,我们可以通过对数值取log,使得计算成本降低。具体如下:
这种方式叫作Log-Softmax。与Softmax 相比,使用 Log-Softmax 有许多优点,包括提高数值性能和梯度优化等。这些优势对于实现非常重要,尤其是当训练模型在计算上的成本很高时,其能带来很客观的收益。而且log 概率的使用,具有更好的信息理论可解释性,当用于分类器时,Log-Softmax 在模型无法预测正确的类别时会惩罚模型。
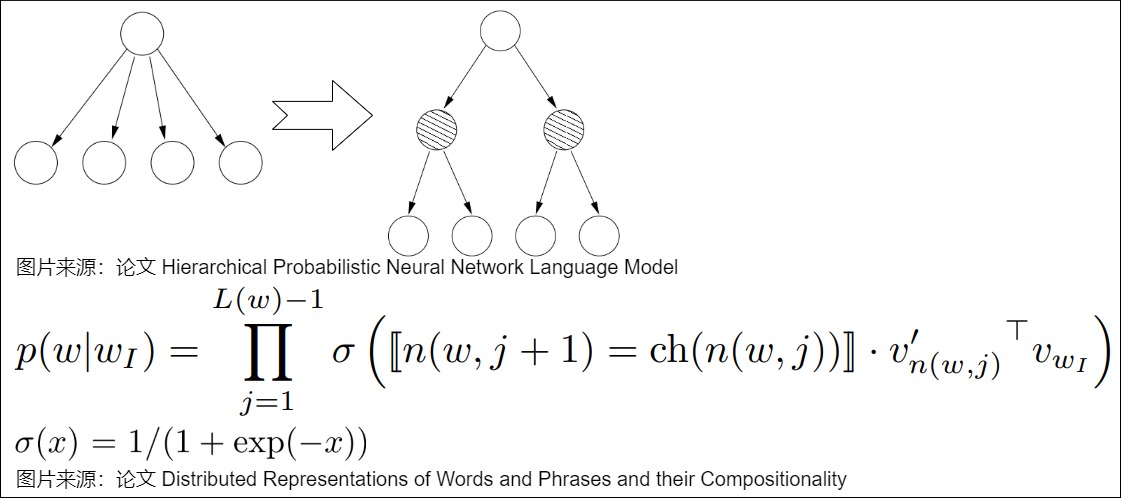
Hierarchical Softmax(H-Softmax)
标准softmax的时间复杂度都是 𝑂(𝑛) ,这在分类任务中可能影响不大,只需要在最后的一层后面进行一次 𝑂(𝑛) 计算就可以了。但是在NLP的生成任务中,我们需要对词表大小的向量进行Softmax,是为了把每个词的Softmax值用作似然,从而挑选出似然最大的那个词。一旦词表特别大,计算量将是一个严峻的问题,每次预测一个token都需要O(|V|)的时间复杂度。所以需要对Softmax进行一定的改造来适应实际任务,而H-Softmax就是用来解决这个问题的。
H-Softmax就是Word2vector中的Hierarchical Softmax。H-Softmax的解决方案是将Huffman Tree融入进来,将原先用 softmax 做多分类分解成多个sigmoid,然后使用Logistic Regression判断在哈夫曼树中走左子树还是右子树,最后其输出的值就是走某一条树分支的概率。
分层softmax使用输出层的二叉树表示,假设 𝑊 个词分别作为叶子节点,每个节点都表示其子节点的相对概率。词表中的每个词都有一条从二叉树根部到自身的路径。用 𝑛(𝑤,𝑗) 来表示从根节点到 𝑤 词这条路径上的第 𝑗 个节点,用 𝑐ℎ(𝑛) 来表示 𝑛 的任意一个子节点,设如果 𝑥 为真则 [𝑥]=1 ,否则 [𝑥]=−1,那么 Hierarchical Softmax 可以表示为下图。
adaptive softmax
常见的对softmax改进方法可以大致区分为两类:一是准确的模型产生近似概率分布,二是用近似模型产生准确的概率分布,这些都是从数理角度进行优化。但是从硬件的角度,应该如何配合GPU进行优化呢?
论文“Efficient softmax approximation for GPUs"提出的Adaptive Softmax就给出了一些思路。Adaptive Softmax借鉴的是Hierarchical Softmax和一些变型,与以往工作的不同在于,该方法结合了GPU的特点进行了计算加速,这样可以提高softmax函数的运算效率,适用于一些具有非常大词汇量的神经网络。
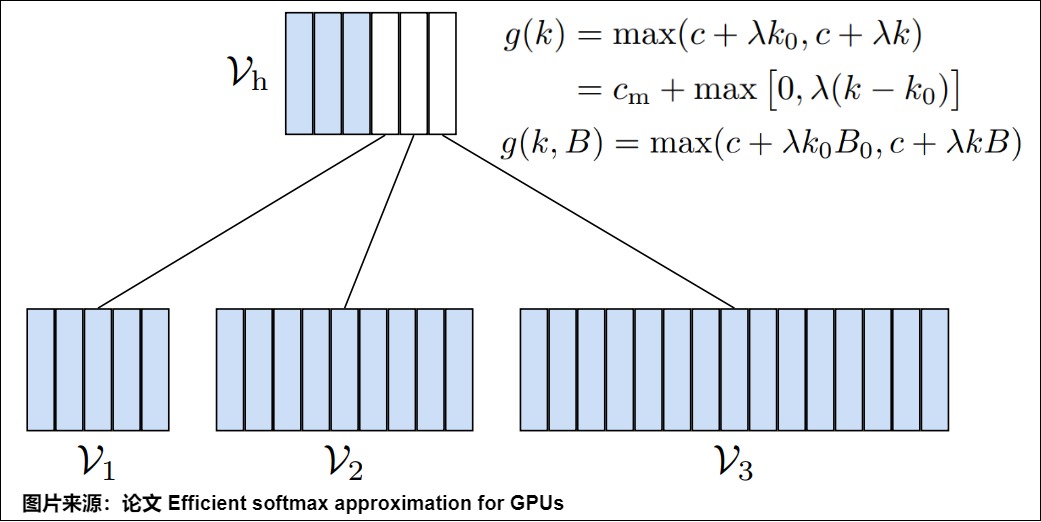
想法很简单,文章的大多数词都由词汇表里的少数词构成,即长尾理论或28原则。而语言模型在预测词的时候往往需要预测每个词的概率(通常是softmax),词汇表可能非常大,低频词非常多。那么就可以利用单词分布不均衡的特点,在训练时把词语分成高频词和低频次两类,先预测词属于哪一类,然后再预测具体是哪个词,这样简单的分类就使得softmax的计算量大大减少。原来是每个词都要计算一次, 现在是:V(高频) + P(低频) * V(低频),V(高频) 会大幅变小,V(低频)虽然大但是P(低频) 很小。另外,Adaptive Softmax也通过结合现代架构和矩阵乘积操作的特点,通过使其更适合GPU单元的方式进一步加速计算。
Adaptive Softmax的层次模型被组织为(i)第一层,包括最频繁的单词和表示聚类的向量.(ii)第二层上是与罕见单词相关的聚类,最大的聚类的与最不频繁的单词相关。具体如下图所示,蓝色表示高频词(总体分作一类),白色是表示低频词(这里有三个白色框,就代表三类低频词),每个time step中,先预测当前词是哪一类(高频词还是低频词分类),然后再在所得的分类中进行Softmax计算,从而得到最终的结果。
那么如何进行分类呢?论文也给了一个计算的模型,假设B是batch size,d是hidden layer 的size,k 是feature的大小,具体见下图上的公式。
2.5 缩放
缩放点积注意力(Scaled Dot-Product Attention)中的Scaled是缩放的意思,是在点乘之后除以一个分母。因此我们提出了一个问题,注意力的计算公式中 $\text{Attention}(Q,K,V) = \text{softmax}(\frac{QK^\top}{\sqrt{d}}) $为什么要除以 $\sqrt{d} $?
结论
我们细化原始论文的解释如下:当维度\(d_k\)较大时,\(q\)和\(k\)的的点积会容易出现较大数值(正比于维度),当这些大数值经过softmax函数时,点积结果的分布会趋近于陡峭(分布的方差大,分布集中在绝对值大的区域)。进而会把点积结果推向softmax函数的梯度平缓区,导致 softmax 函数的梯度将变得非常小,这意味着模型将难以收敛,加大学习难度。因此Transformer作者将乘法函数按照因子\(1/\sqrt{d_k}\)进行缩放,这样\(softmax(QK^T)\)分布的陡峭程度就和\(d_k\)解耦了。正好抵消了维度增加造成的点积尺度放大效应,可以保证无论维度\(d_k\)取什么值,点乘的结果都处在一个合理的范围内,从而有助于保持梯度的稳定性,加速模型的训练过程。
对于较大数值这部分,可以参见论文脚注。

\(\sqrt d\) 很像超参数 Temperature。Temperature 用于调整模型的 softmax 输出层中预测词的概率,控制生成文本的随机性和创造性。
问题推导
我们把上述问题点梳理如下:
- 如果 \(d_k\) 变大,$q \cdot k^\top $ 方差会变大。
- 方差变大会导致向量之间元素的差值变大。
- 元素的差值变大会导致 softmax 退化为 argmax, 即最大值为 1, 其他值则为0。
- 如果只有一个值为 1,其他都为 0 的话,反向传播的梯度会变为 0, 也就是所谓的梯度消失。
我们接下来逐一分析。
方差变大
从根本上说,当我们将两个矩阵相乘(例如 Q 和 \(K^T\))时,我们对它们各自的列向量进行多次点乘。例如,我们将第一个向量的第一个值与第二个向量的第一列相乘,以此类推,得到输出矩阵中的值。
当\(q\)和\(k_l\)中每个元素都是正态分布(其均值为零,方差为1)时,则\(q\)和\(k_l\)的的点积的方差为\(d_k\)。推导如下:
拿出Q矩阵中单独一列\(q_i\)和K矩阵单独一行\(k_i\)出来,假设\(q_i\)和\(k_i\)中每个元素均是均值为0,方差为1的独立同分布随机变量,则\(q_ik_i^T\)中每个元素也是均值为0,方差为1。也就是说,每个这样的qk对都会产生一个期望为0,方差为\(d_k\)的新向量。当\(d_k\)很大时,这个向量的方差就很大。即,点积方差正比于维度数量,当我们对低维向量进行点积时,输出的方差往往较小。当我们对高维向量进行点积运算时,输出的数字往往具有较高的方差。
而在现实世界中,表示复杂语义概念需要很高的query和key维度,高维度导致点积\(qk^T\)值变大。
元素间差值变大
方差变大会导致向量之间元素的差值变大。这是一个显而易见的结论,因为方差变大就是代表了数据之间的差异性变大。有些数字会非常大,而有些则会非常小。
softmax退化
softmax中每个分量\(softmax(x_i)\)如下:
将x的每个元素表达为最大元素\(x_{max}\)减去一个插值\(\Delta_i\),即\(x_i = x_{max} - \Delta_i\),则softmax重写为:
因为\(e^{x_{max}}\)是公因子,可以提出来约掉,则
如果\(x_i\)远小于\(x_{max}\)时,\(e^{-\Delta_i}\)会接近于0,因此除了\(\Delta_{max} = 0\)之外所有项都接近于0,即:
所以方差变大时,softmax 函数会退化为 argmax 函数。当数字较大时,退化的SoftMax 倾向于分配较高的概率;当数字较小时,SoftMax 倾向于分配较低的概率。最终,退化的softmax 函数会把大部分概率分布分配给最大的元素,这趋近于把最大的元素赋值为1,其它元素赋值为0。
即softmax将one-hot输出中最大值对应的1按输入元素值的大小分配给其他位置。而当喂入的数组内部数量级相差较大时,“1分出去的部分”就会越来越少,当数量级相差到一定程度,softmax将几乎全部的概率分布都分配给了最大值对应的标签,其效果也就被削减了。
梯度消失
假设我们的输入数量级很大,那么softmax将产生一个接近 one-hot 的向量。\(Y≈[0,...,1,⋯,0]^⊤\),求导如下
上面公式运算结果就接近于0,即几乎所有梯度都接近于0。所以,绝对值很大的点积在训练中会收到几乎为0的梯度,这对于基于梯度下降法的优化非常不利。在反向传播过程中,模型会不断调整和改变较大的数字,而概率较小的数值几乎不会得到更新。因此,由于并非所有参数都会更新,这会导致训练进展缓慢。
如何降低方差?
因此,在应用 SoftMax 之前,我们需要找到一种解决方案,帮助减少这些数字的方差。现在,我们的问题已经简化为降低包含初始注意力分数的乘积矩阵的方差。
vanilla Transformer提出的方案就是缩放矩阵以获得与之前相同的方差。因为除以维度的平方根意味着,即使增加维度(需要增加维度来捕捉更复杂的模式),我们也可以在增加维度的同时缩放矩阵以保持方差一致。
熵的作用
信息熵衡量的是不确定性。在注意力机制中,熵可以用来度量模型输出的不确定性,或者说,某个查询向量的注意力权重分布的熵可以用来衡量它对不同键向量的关注程度。
- 高熵表示模型的注意力分散,即这个查询向量在多个输入数据(键向量)上都有较高的注意力权重。模型在多个输入之间分配了注意力,因此模型只能从多个地方提取信息而没有明确的重点。因此,高熵分布可以捕捉更广泛的上下文信息,对于需要全局信息的场景更加合适。
- 低熵表示模型的注意力集中,即这个查询向量在少数几个输入数据(键向量)上有较高的注意力权重,模型对这些键向量的选择更加明确和确定。因此,低熵分布倾向于选择性地提取信息,对于需要聚焦于关键信息的场景更加合适。
为了使得模型结果能够更好地泛化到未知长度,Attention机制的设计应该使得\(a_{i,j}\)尽量具备熵不变性。
熵不变性是指,熵值𝐻𝑖应该对长度𝑛不敏感。更具体一点,就是如果在已有的token基础上,再补充几个token,那么新算出来各个\(𝑎_{𝑖,𝑗}\)自然也会有所改变,但我们希望𝐻𝑖不要有太大改变。
换个角度想,我们可以将不确定性视为注意力的“聚焦程度”:如果熵为0,那么注意力将聚焦到某一个token上,如果熵为logn,那么注意力均匀分布到所有token上。我们希望熵不变,是希望引入新的token后,已有的token依旧能同样地聚焦到原来的token上,而不希望新token的引入过多地“分摊”了原有的注意力,导致求和结果显著发生变化。使用\(log𝑛\)缩放注意力可以在一定程度上缓解这个问题,即将Attention从
修改为
其中𝑚是训练长度,𝑛是预测长度。经过这样修改,注意力的熵随着长度的变化更加平稳。
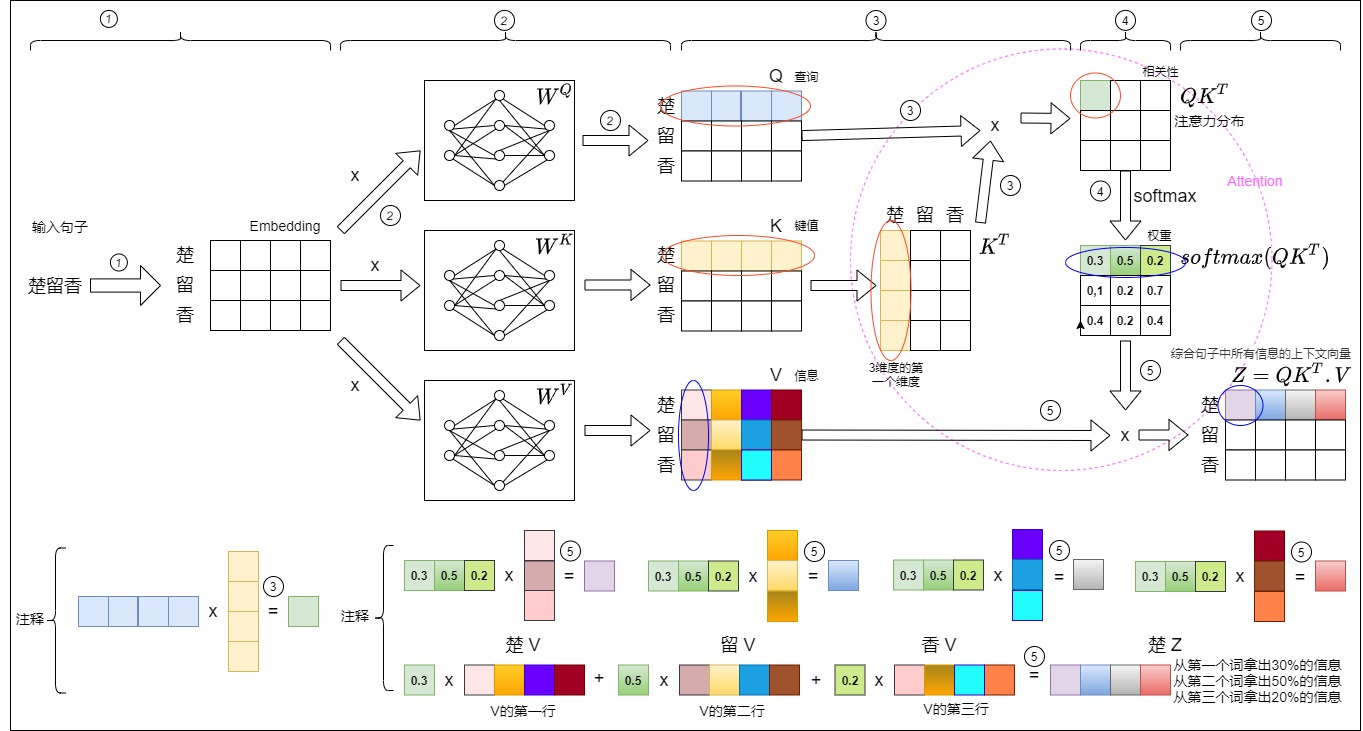
2.6 小结
最后,我们梳理自注意力机制的计算过程如下图所示。
0x03 实现
3.1 哈佛代码
attention()函数定义了标准注意力机制的操作过程,计算公式是:Attention(q,k,v) = softmax( \({q \times k^T}\over{\sqrt d_k}\) ) * v,这也是整个transformer的核心操作所在。
输入&输出
首先要说明的是,本小节下面行文和注释中的一些术语解释如下。
-
batch_size:样本有多少个句子。
-
seq_length是句子长度。
-
d_model是模型的维度。
-
head_num是注意力头数。
-
head_dim是单个头的注意力维度,大小是d_model / head_num。
-
embedding_size:词嵌入的大小。
其次,attention()函数的输入参数如下:
- query,key,value是输入的向量组,就是论文公式提到的,经过\(W^Q, W^K, W^V\)计算后的Q, K, V,计算过程位于MultiHeadedAttention类的forward()函数之中。query,key,value的形状有两种可能:
- 单注意力头,即自注意力调用到attention()函数,则形状是(batch size, seq_length,d_model)。
- 多注意力头,即多头注意力机制调用到attention()函数,则形状是(batch size, head_num,seq_length,head_dim)。Transformer中使用的是多头注意力机制,所以query,key,value的Shape只会是第二种。
- mask:用于遮掩某些位置,防止计算这些位置的注意力。mask有两种,一种是src_mask,另一种是tgt_mask。
- dropout:dropout率,用于添加随机性,有助于防止过拟合。
attention()函数的输出有两个:
- torch.matmul(p_attn, value):value 的加权平均,权重来自p_attn。
- p_attn:从 query 和 key 的计算结果得到的权重,后续没有用到。
这里要对mask做一下说明,mask有两种:
- src_mask:形状是(batch size, 1, 1, seq_length)。因为所有head的mask都一样,所以第二维是1,masked_fill 时使用 broadcasting 就可以了。这里是 self-attention 的mask,所以每个时刻都可以 attend 到所有其它时刻的第三维也是 1,也使用broadcasting。
- tgt_mask:形状是(batch size, 1, seq_length, seq_length)。
图例&代码
我们可以通过下图来和代码互相印证。
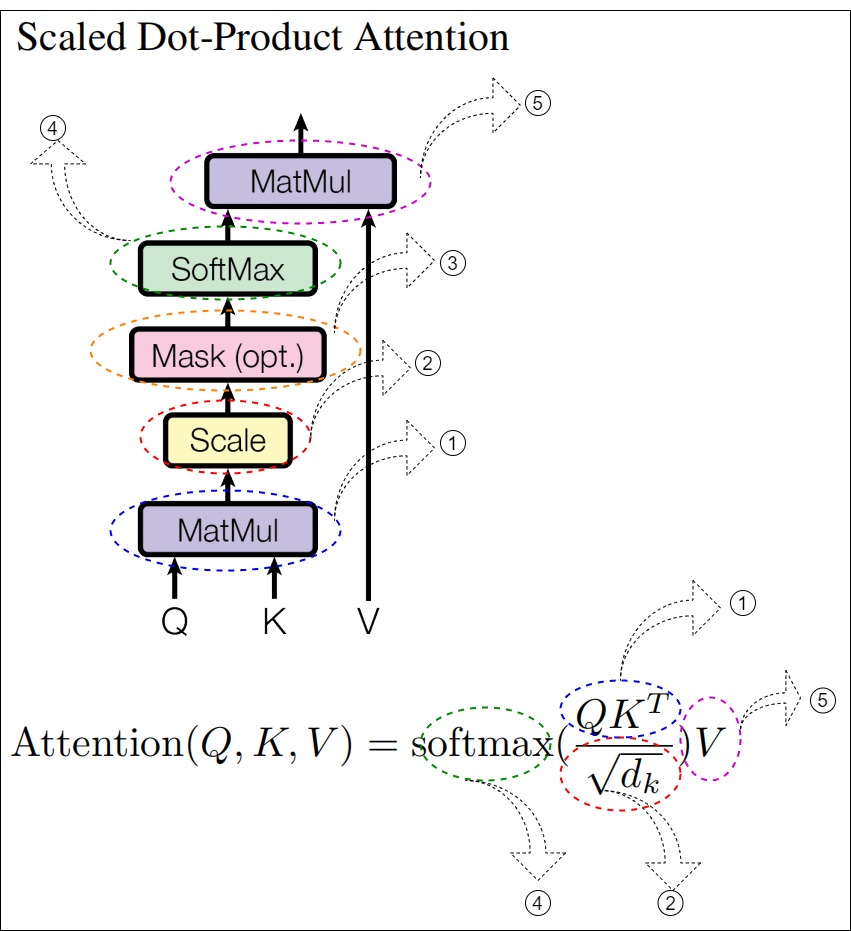
对应代码如下。
def attention(query, key, value, mask=None, dropout=None):"""本函数计算缩放点积注意力(Scaled Dot Product Attention)query, key, value:是经过权重矩阵线性转换过的Q,K,V矩阵,具体线性转换是在后续会介绍的 MultiHeadedAttention类中。query, key, value有两种可能的形状:1. 若注意力为单头自注意力,则形状为(batch size, 词数, d_model)。2. 若注意力为多头自注意力,则形状为(batch size, head数, 词数,d_model/head数)在哈佛代码中使用的是多头自注意力,所以query, key, value的形状只会是第二种。mask(掩码矩阵):有两种参数,一种是src_mask,另一种是tgt_mask。 """"""用query最后一个维度的大小来给d_model赋值。之所以这样可以获取,是因为query和输入的shape相同,若注意力为单头自注意力,则最后一维都是词向量的维度,也就是d_model的值。若注意力为多头自注意力,则最后一维是 d_model / h,h为head数 """d_k = query.size(-1) """执行QK^T/√d_k,得到注意力分数。1. key.transpose(-2, -1)将将最后两个维度进行转置,得到key的转置矩阵K^T。2. torch.matmul()函数做矩阵乘法,即将query矩阵的每一行与key的转置矩阵的每一列进行点积(对应元素相乘并求和),得到新矩阵的每个元素。此处操作对于上图的标号1。3. math.sqrt(d_k)操作会对矩阵相乘结果进行缩放。此处操作对于上图的标号2。scores是一个方阵, 形状为(batch_size, head数,词数,词数) """scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)# 判断是否使用掩码张量if mask is not None:# 如果使用掩码,则屏蔽不想要的元素# masked_fill()将掩码张量和scores张量每个位置一一比较, 如果掩码张量处为0,则把注意力分数中对应元素设置为-1e9,因为后续还要进行softmax操作,softmax会让负无穷变为0(是理论上还是用到了很少一点点未来的信息,因为毕竟还是有一个小小的数值)。此处对于上图的标号3。 scores = scores.masked_fill(mask == 0, -1e9)"""执行公式中的softmax,对scores的最后一维做归一化操作,得到注意力权重,这些权重值加起来的和为1。此处对于上图的标号4。 p_attn的形状如下:1. 若p_attn是自注意力,则形状为(batch size, seq_length, seq_length)2. 若p_attn是多头注意力,则形状为(batch size, head_num, seq_length,seq_length) # 这样获得最终的注意力张量 """p_attn = scores.softmax(dim=-1) # 得到注意力权重# 判断是否使用dropout进行随机置0 if dropout is not None:# 如果提供了dropout,则对p_attn进行dropout操作。p_attn = dropout(p_attn) """用注意力权重p_attn对value向量进行加权求和,得到最终的输出softmax(QK^T/√d_k)V,我们命名为Z。1. 对于自注意力,Z的形状为(batch size, seq_length, d_model),即最终结果。2. 对于多头注意力,Z的形状为(batch size, head_num, seq_length,d_model/head_num), 而并非最终结果,后续在MultiHeadAttention的forward()函数中还要将多头的结果进行合并,变为(batch size, seq_length, d_model)torch.matmul对应上图的标号5"""return torch.matmul(p_attn, value), p_attn # 返回Z和权重p_attn
再分析注意力
看过源码之后,我们再来对编码器和解码器中的注意力机制进行回顾和温习。
encoder使用自注意力的目的是:找到输入序列自身的关系。
- 源序列之中,每个token都搜集到本字和源序列之中其他哪几个字比较相关。得到相关权重矩阵score。
- 接下来对 score 求 softmax,把得分变成概率 p_attn.
- 利用p_attn,把源序列转换为源隐状态,具体操作是torch.matmul(p_attn, value),其中每个token都是综合了源序列之中所有token的相关信息。
- 最后返回的是 源隐状态torch.matmul(p_attn, value)和p_attn 。源隐状态会作为参数Memory传给解码器。
decoder使用两种注意力结构。
-
使用self-attention的目的是找到目标序列自身的关系。
- 让目标序列之中,每个token都搜集到本字和目标序列之中其他哪几个字比较相关。得到相关权重矩阵score。
- 接下来对 score 求 softmax,把得分变成概率 p_attn.
- 利用p_attn把目标序列转换为目标隐状态,具体操作是torch.matmul(p_attn, value),其中每个token都是综合了源序列之中所有token的相关信息。
- 最后返回的是目标隐状态torch.matmul(p_attn, value)和p_attn 。
-
使用cross-attention的目的是让源序列与目标序列对齐
- 用 目标隐状态作为 Q,源隐状态(参数Memory)作为 K, V。
- 找到 目标隐状态之中每个token与 源隐状态之中哪几个token比较相关。得到相关权重矩阵(就是score)。
- 接下来对 score 求 softmax,把得分变成概率 p_attn。
- 利用p_attn把目标隐状态转换成新的目标隐状态,具体操作是torch.matmul(p_attn, value),其中每个token都是综合了源隐状态之中所有token的相关信息。
- 最后返回的是目标隐状态torch.matmul(p_attn, value),p_attn。
3.2 llama3
我们再用工业界的代码来进行学习。首先我们给出Transformer总体代码如下。Transformer是整个模型的主体,它将词嵌入层、TransformerBlock层、归一化层和输出层串联起来。从下面代码中可以看到,Transformer中包含了很多层TransformerBlock。每层都有自己的注意力机制。每层注意力机制中都有自己的\(W^Q, W^K, W^V\)参数。所以也有一种说法是attention是基于图的一个信息传递机制,节点之间的边是学习到的。
class Transformer(nn.Module):def __init__(self, params: ModelArgs):super().__init__()self.params = paramsself.vocab_size = params.vocab_sizeself.n_layers = params.n_layers# 词嵌入层self.tok_embeddings = VocabParallelEmbedding(params.vocab_size, params.dim, init_method=lambda x: x)# 将32个TransformerBlock存于ModuleListself.layers = torch.nn.ModuleList()for layer_id in range(params.n_layers):self.layers.append(TransformerBlock(layer_id, params))# 归一化层self.norm = RMSNorm(params.dim, eps=params.norm_eps)# 输出层,输入特征数为词嵌入的维度,输出特征数为词表大小self.output = ColumnParallelLinear(params.dim, params.vocab_size, bias=False, init_method=lambda x: x)# 旋转位置编码中的旋转矩阵self.freqs_cis = precompute_freqs_cis(params.dim // params.n_heads,params.max_seq_len * 2,params.rope_theta,)@torch.inference_mode()def forward(self, tokens: torch.Tensor, start_pos: int):# 批次大小和序列长度_bsz, seqlen = tokens.shape# 应用词嵌入之后的输入h,大小为(bsz, seqlen, dim)h = self.tok_embeddings(tokens)# 确保旋转矩阵和输入h位于同一设备(GPU)self.freqs_cis = self.freqs_cis.to(h.device)# 从旋转矩阵中提取旋转角度(频率)freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]mask = Noneif seqlen > 1:# 创建大小为(seqlen, seqlen)的张量,并用“负无穷大”填充mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device)mask = torch.triu(mask, diagonal=1) # 上三角化# When performing key-value caching, we compute the attention scores# only for the new sequence. Thus, the matrix of scores is of size# (seqlen, cache_len + seqlen), and the only masked entries are (i, j) for# j > cache_len + i, since row i corresponds to token cache_len + i.# 将大小为(seqlen, start_pos)的全0张量和mask进行水平拼接,形成最终的maskmask = torch.hstack([torch.zeros((seqlen, start_pos), device=tokens.device), mask]).type_as(h)# 输入h被32个TransformerBlock逐个处理for layer in self.layers:h = layer(h, start_pos, freqs_cis, mask)# 将最后一个TransformerBlock的输出进行归一化h = self.norm(h)# 将归一化之后的结果经过输出层,进行线性计算output = self.output(h).float()return output # 大小为(bsz, seqlen, vocab_size)
接下来我们看看每个层的代码。
class TransformerBlock(nn.Module):def __init__(self, layer_id: int, args: ModelArgs):super().__init__()self.n_heads = args.n_headsself.dim = args.dimself.head_dim = args.dim // args.n_headsself.attention = Attention(args)self.feed_forward = FeedForward(dim=args.dim,hidden_dim=4 * args.dim,multiple_of=args.multiple_of,ffn_dim_multiplier=args.ffn_dim_multiplier,)self.layer_id = layer_idself.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],):h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)out = h + self.feed_forward(self.ffn_norm(h))return out
然后是Attention的代码如下。
class Attention(nn.Module):def __init__(self, args: ModelArgs):super().__init__()# 注意力中K(Key)和V(Value)的头数,n_kv_heads=n_heads时为多头注意力,n_kv_heads=1时为多查询注意力,否则为分组查询注意力self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads# 分布式训练的进程数,也就是模型训练的并行度或参与计算的设备(GPU)数量model_parallel_size = fs_init.get_model_parallel_world_size()# 将Q(Query)的头数,根据并行度进行拆分self.n_local_heads = args.n_heads // model_parallel_size# 将K(Key)和V(Value)的头数,根据并行度进行拆分self.n_local_kv_heads = self.n_kv_heads // model_parallel_size# 假如本地Q数为2,本地KV数为1,我们需要把本地KV复制为2份,以便矩阵相乘self.n_rep = self.n_local_heads // self.n_local_kv_heads# 每头(Q)的输出维度。每头的输出会concat,来生成注意力的最终输出self.head_dim = args.dim // args.n_heads# ColumnParallelLinear和RowParallelLinear是用于并行训练的两种并行线性层self.wq = ColumnParallelLinear(args.dim, # 输入的特征数args.n_heads * self.head_dim, # 输出的特征bias=False, # 注意力里面的线性计算一般不使用偏置单元gather_output=False,init_method=lambda x: x,)# 大小为(dim, n_kv_heads * head_dim)self.wk = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)# 大小为(dim, n_kv_heads * head_dim)self.wv = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)# 大小为(n_heads * head_dim, dim)self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,bias=False,input_is_parallel=True,init_method=lambda x: x,)self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()self.cache_v = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],):bsz, seqlen, _ = x.shape# 输入x分别和权重wq、wk和wv进行线性计算,得到xq、xk和xvxq, xk, xv = self.wq(x), self.wk(x), self.wv(x)# 改变xq、xk和xv的形状xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)# 对xq和xk应用旋转位置编码xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)self.cache_k = self.cache_k.to(xq) # 确保cache_k和xq位于同一设备(GPU)self.cache_v = self.cache_v.to(xq) # 确保cache_v和xq位于同一设备(GPU)# 将xk和xv加载进缓存self.cache_k[:bsz, start_pos : start_pos + seqlen] = xkself.cache_v[:bsz, start_pos : start_pos + seqlen] = xv# keys和values的取值从数组的最左边开始keys = self.cache_k[:bsz, : start_pos + seqlen]values = self.cache_v[:bsz, : start_pos + seqlen]# 将keys和values根据n_rep复制出相应的份数,以便矩阵相乘# repeat k/v heads if n_kv_heads < n_headskeys = repeat_kv(keys, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)values = repeat_kv(values, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)# 计算注意力得分scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)if mask is not None:scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)scores = F.softmax(scores.float(), dim=-1).type_as(xq)output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)# 改变output的形状为(bs, seqlen, n_local_heads * head_dim),n_local_heads * head_dim等同于将每头的head_dim进行concatoutput = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)# 将output和权重wo进行线性计算,得到注意力的最终输出return self.wo(output)
0x04 优化
4.1 优化策略
对于长序列的数据和高维度的模型,自注意力机制的计算量是非常大的,而且这种巨大的计算量也限制了模型扩展到训练数据以外的更长的序列,即存在长度外推问题。因此需要对自注意力机制进行优化。有各种优化的分类,本文选取几个典型的方面进行分析。
从序列角度优化
原始自注意力机制中,每个token都要和所有token作注意力计算。但是Transformer中的注意力分布其实是不均匀的。比如“How Do Language Models put Attention Weights over Long Context”就发现不同层的注意力分布有显著差异。起始层的注意力分布大致均匀。然而中间层的注意力模式变得更加复杂,大部分概率质量集中在初始标记(注意力汇聚)和最近的/最后标记(近期偏见)上。即Transformer的中间层大部分都是“V形”注意力分布。这意味着中间层很多的token其实作用不大,也许可以通过压缩token的方式减少context长度,从而达到加速推理或者支持更长context需求。
因此,人们提出了稀疏计算(或者说是限制注意力)的思想,即每个 token 只与一部分 token 做注意力计算(而非全部)。其中技巧在于当前token与哪一部分 token 做注意力计算。几个典型做法如下。
- Atrous self-attention(空洞自注意力):每个 token 等间隔的和其他 token 做注意力计算。
- Local self-attention(局部注意力):类似于 n-gram,每个 token 与附近的几个 token 做注意力计算。
- Sparse attention(稀疏注意力):结合了空洞注意力和局部注意力机制,根据规则(或者动态决定),每个 token 即有局部感受野,也有全局感受野。
几个经典模型如下:
- Longformer:是稀疏注意力的一种,参与注意力的包括局部注意力、空洞注意力和全局注意力。全局注意力就是对于一些特定位置的 token(例如 Bert 中的 CLS),做全部的注意力计算。
- Reformer:本方案基于这样的假设:经过 softmax 之后,一个 query 和其他所有的 token 计算的 attention score 主要是取决于高相似度的几个 tokens,所以可以采用最相似的token来近似计算得到最终的 attention score。因此,问题就转化成为了找最相似的 Top-N 问题。reformer 是通过 Locality sensitive hashing(LSH)方法将 attention score 相近的token分到一个 bucket 中。从而在低维空间中保留高维空间的相似性。这样可以大幅减少计算复杂度,特别是在处理大规模数据时。
- Linformer:证明了 Transformer 的 Attention 矩阵是低秩矩阵,这说明了矩阵的大部分的内容可以通过少部分最大的奇异值得到。层级越高,会有越多的信息集中在最大的奇异值上。Linformer 对 Self-Attention 的结构进行了一些修改(主要的区别在于增加了两个线性映射层),使复杂度降到线性。
- BigBird:使用了一种块稀疏的注意力模式,结合了局部(窗口)、全局(固定点)和随机的注意力。块式稀疏注意力:将注意力机制应用在连续的局部块上,而不是整个序列。全局注意力点:为了保持交互的全局性,添加了总是彼此进行注意力操作的标记,如 CLS 标记。随机注意力:在序列中随机引入额外的注意力连接,以确保任意两个位置之间总有一个路径(可能通过多个中间节点)使得彼此可以连接。
- DCA(Dual Chunk Attention):双块注意力(DCA)是一个无需训练的框架,用于推断LLMs的上下文窗口。DCA没有使用线性缩放位置索引或增加RoPE的基频。相反,它选择重用预训练模型中的原始位置索引及其嵌入,但重新设计了相对位置矩阵的构建,以尽可能准确地反映两个标记之间的相对位置。DCA的创新点也在于它与Flash Attention的兼容性,仅需要对推理代码进行修改,无需进行大量的重新训练。
另外,长度外推性是一个训练和预测的不一致问题,而解决这个不一致的主要思路是将注意力局部化,很多外推性好的改进某种意义上都是局部注意力的变体。局部化注意力就是通过限制注意力的感知范围,来赋予整个模型“平移不变性”。
窗口截断的方式也可以作为长度外推的一个不错的Baseline,但这是通过强行截断窗口外的注意力、牺牲远程依赖换来的,因此还不是最终的解决方案。
DCA
因为Qwen2.5-Turbo采用了DCA来通过分块处理长序列,减少了计算复杂度,提升了模型的推理速度,所以我们再重点介绍下DCA。
DCA由三个组件组成,这些各自的处理帮助模型有效捕捉序列中的长距离和短距离依赖。
- 块内注意力,针对同一块内的标记处理。
- 块间注意力,用于处理不同块之间的标记。
- 连续块注意力,用于处理连续的、不同的块中的标记。
下图是块内注意力。
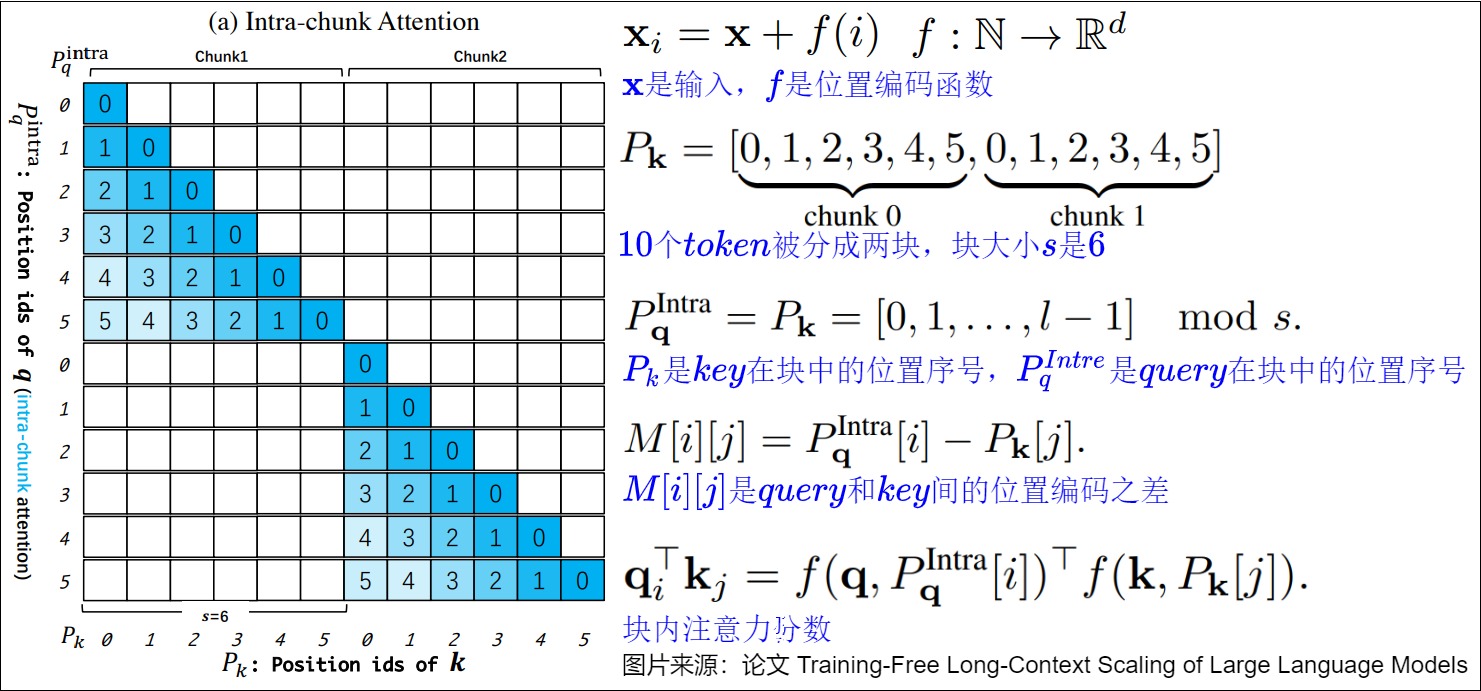
下图是块间注意力。
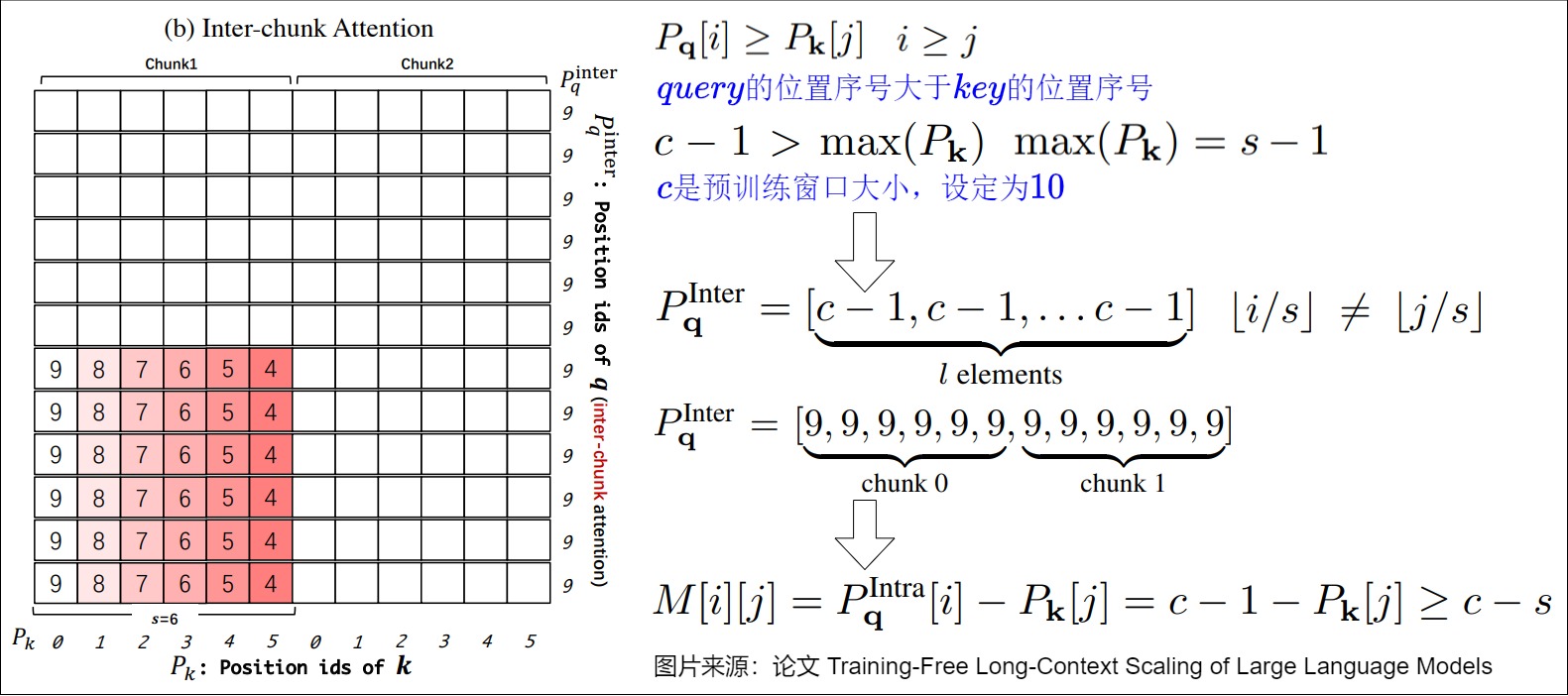
下图是连续块注意力,这是块间注意力的特殊case。连续块注意力用来保持LLM的局部性,局部性意味着LLM倾向于主要依赖相邻token来预测下一个token。
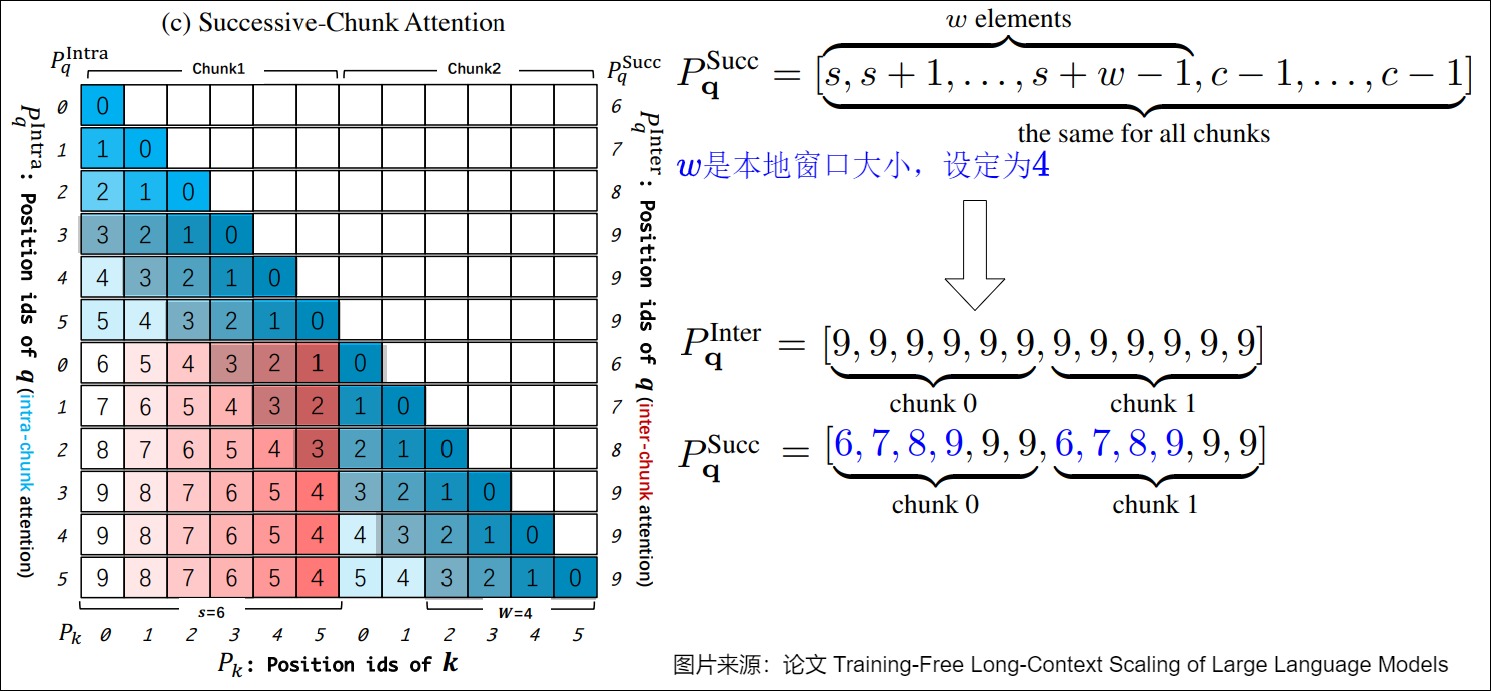
综合三种注意力之后,得到如下。

从多头角度优化
具体包括MHA、MQA、GQA,我们后续有专门篇幅介绍。
从软硬件层面优化 MHA
硬件层面上,比如现在已在使用的 HBM(高速带宽内存)提高读取速度,或者更彻底些,抛弃冯诺依曼架构,改变计算单元从内存读数据的方式,不再以计算单元为中心,而以存储为中心,做成计算和存储一体的“存内计算”。
软件层面上的话,最近的很多优化,比如 Flash Attention,Paged Attention。我们后续有专门篇幅介绍。
从其它角度优化
比如下面要介绍的\(Transformer^2\),其并不是对Transformer结构做了改变,而是在推理时分两次推理。
4.2 案例
我们接下来介绍几个特色案例。
注意力权重细化
传统的自注意力模型可能不足以捕获序列推荐场景中复杂的item依赖关系,这是因为缺乏对注意力权重的明确强调,而注意力权重在分配注意力和理解item间相关性方面起着关键作用。为更好发挥注意力权重的潜力并提高序列推荐在学习高阶依赖关系方面的能力,论文"Pay Attention to Attention for Sequential Recommendation“提出了注意力权重细化(AWRSR,Attention Weight Reffnement for Sequential Recommendation)方法, 通过额外关注注意力权重来增强自注意力机制的有效性,从而实现item间相关性更精细的注意力分布。
现有的注意力权重操作围绕计算item embedding或分布之间的相似性或距离,如下图右下角部分所示。这种方式并没有考虑注意力权重内的潜在相关性,而这些相关性可能会进一步揭示注意力权重本身内的高阶转换。如下图中右上角部分所示,注意力权重矩阵 A 源自序列中item的表示,它编码了序列中每个元素相对于所有其他元素的关系。例如,\(A_1\)表示从第一个item到序列中所有其他item的注意力或重要性的分配,这意味着细化这些权重(本质上捕捉权重/注意力之间的相关性)具有建模高阶转换的潜力。鉴于此,比较\(A_1\)和\(A_2\)可以有助于对序列中两个元素(位于第一和第二位置)之间依赖关系的理解。

论文共设计了4种细化机制来计算注意力权重之间的依赖关系,即:计算注意力权重之间的注意力权重(pay attention to attention)。
- Simple refinement。该机制只是将一组新的可训练矩阵应用于注意力权重矩阵 A,将其转换为新的查询和键,以计算更高级别的权重,形式如下图标号1。其中W是可训练的矩阵。接着对新的权重矩阵B使用softmax函数,softmax(B) 与item集合的乘积相当于对值进行求和,这意味着每个值都通过细化的高阶注意力权重进行缩放。
- Value-weighted refinement。通过attention进一步转化Simple refinement,得到新权重B,希望在更复杂的高阶空间中提炼并重新表达权重相关性,给出矩阵形式以简化计算,形式如下图标号2。
- Additive refinement。该机制的目的是合并/平衡不同级别的注意力权重,形式如下图标号3。
- Stochastic refinement。该机制针对 STOSA(STOchastic Self-Attention)进行了量身定制,尝试将 STOSA 原有的随机权重 A 转变为一种可能保持权重概率性质的新形式。对item k计算一个新的注意力分布。这里的\(W_\mu\)和\(W_\sum\)为两个随机矩阵,形式如下图标号4。

线性注意力
Transformer 核心的自注意力机制是其计算成本的重要来源。为了优化,研究社区提出了稀疏注意力、低秩分解和基于核的线性注意力(KERNEL-BASED LINEAR ATTENTION)等许多技术。
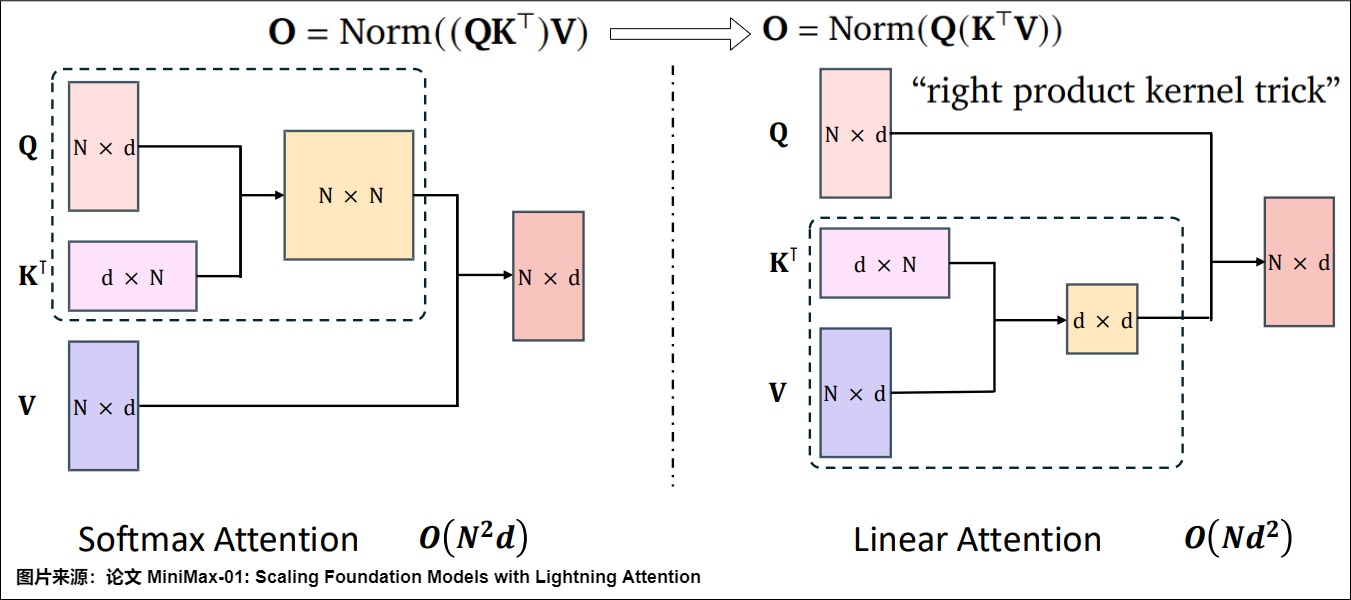
vanilla Transformer使用Softmax注意力,需要为此构建一个N×N 的全连接矩阵,对于超长序列,这个矩阵会非常庞大。它会让模型在处理长文本时复杂度成n的平方的增加,复杂度是\(O (N^2)\)。
为了缓解标准自注意力机制的效率瓶颈,在论文“Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention"中提出了基于核的线性注意力机制,该机制将相似度函数分解为特征映射的点积。按照 Linear Attention 工作里的符号,我们定义\(SM(q,k)=exp(q^Tk)\)为softmax 核函数。从数学上讲,线性注意力的目标是使用 $ϕ(q_i)ϕ(k_j)^T $来近似 SM (⋅,⋅)。
通过“右积核技巧(right product kernel trick)”可以将传统的二次计算复杂度转化为线性复杂度,显著降低了长序列处理的计算负担。,每个头的复杂度可以降低到 \(O (Nd’^2)\),其中 d’是特征映射后的维度,与序列长度成线性关系。具体来说,线性注意力通过递归更新键值矩阵的乘积,避免了重复计算整个注意力矩阵,从而在推理过程中保持了恒定的计算复杂度。

下图给出了 softmax注意力(左)和线性注意力(右)的计算说明。输入长度为N 特征维数为d,d≥N。同一框中的张量与计算相关联。线性化公式可以获得O(N)的时间和空间复杂性。
论文“The Devil in Linear Transformer”中的 TransNormer 就是线性注意力的体现,具体参见下图。为了保持整体架构线性复杂度,TransNormer 把靠底层的layer换成了local attention,然后后面的layer用去掉了分母的,normalize过后的线性attention。
PolaFormer
论文“PolaFormer: Polarity-aware Linear Attention for Vision Transformers”中,作者提出了一种极性感知线性注意力(PolaFormer)机制,旨在通过纳入被忽略的负交互作用来解决先前线性注意力模型的局限性。与此同时,为了解决线性注意力中常见的注意力权重分布信息熵过高的问题,他们提供了数学理论基础,表明如果一个逐元素计算的函数具有正的一阶和二阶导数,则可以重新缩放 q,k 响应以降低熵。这些增强功能共同提供了一个更稳健的解决方案,以缩小线性化和基于 Softmax 的注意力之间的差距。
研究背景
线性注意力,作为一种更具可行性的解决方案使用核化特征映射替换 q,k 点积中的 Softmax 操作,有效地将时间和空间复杂度从 O (N²d) 降低到 O (Nd²)。尽管线性注意力在计算效率上有所提升,但在表达能力方面仍不及基于 Softmax 的注意力,论文分析确定了造成这种不足的两个主要原因,它们都源于 Softmax 近似过程中的信息丢失:
- 负值丢失。依赖非负特征映射(如 ReLU)的线性注意力模型无法保持与原始 q,k 点积的一致性。这些特征映射仅保留了正 - 正交互作用,而关键的正 - 负和负 - 负交互作用则完全丢失。这种选择性表示限制了模型捕获全面关系范围的能力,导致注意力图(attention maps)的表达能力减弱和判别力降低。
- 注意力分布的高信息熵。没有 softmax 的指数缩放,线性注意力会导致权重分布更加均匀且熵更低。这种均匀性削弱了模型区分强弱 q,k 对的能力,损害了其对重要特征的关注,并在需要精细细节的任务中降低了性能。
思路
极性感知注意力背后的核心思想是为了解决现有线性注意力机制的局限性,这些机制通常会丢弃来自负成分的有价值信息。PolaFormer 在处理负成分时,极性感知注意力将 query 和 key 向量分解为它们的正部和负部。这种分解允许机制分别考虑正相似度和负相似度对注意力权重的影响。然后将这些分解代入 q 和 k 的内积中,得到如下图所示。

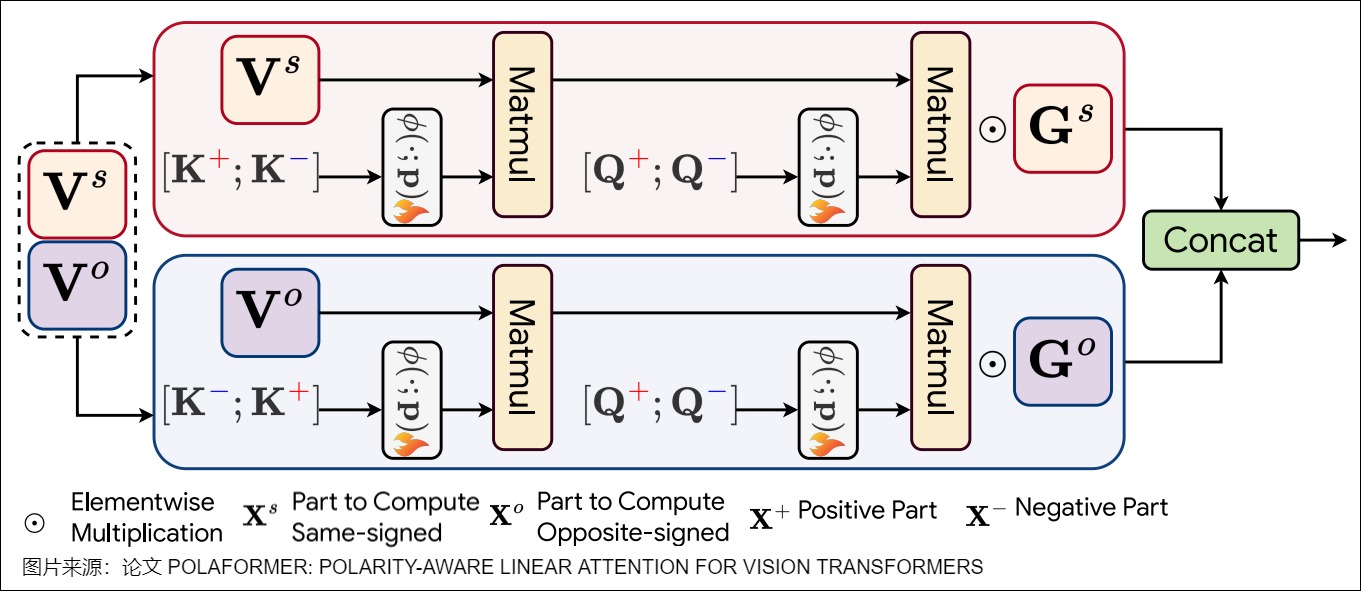
之前的线性注意力方法,如基于 ReLU 的特征映射,通过将负成分映射到零来消除它们,这在近似 q,k 点积时会导致显著的信息丢失。为了解决这个问题,极性感知注意力机制根据 q,k 的极性将它们分开,并独立计算它们之间的相互作用。注意力权重的计算方式如下图所示。

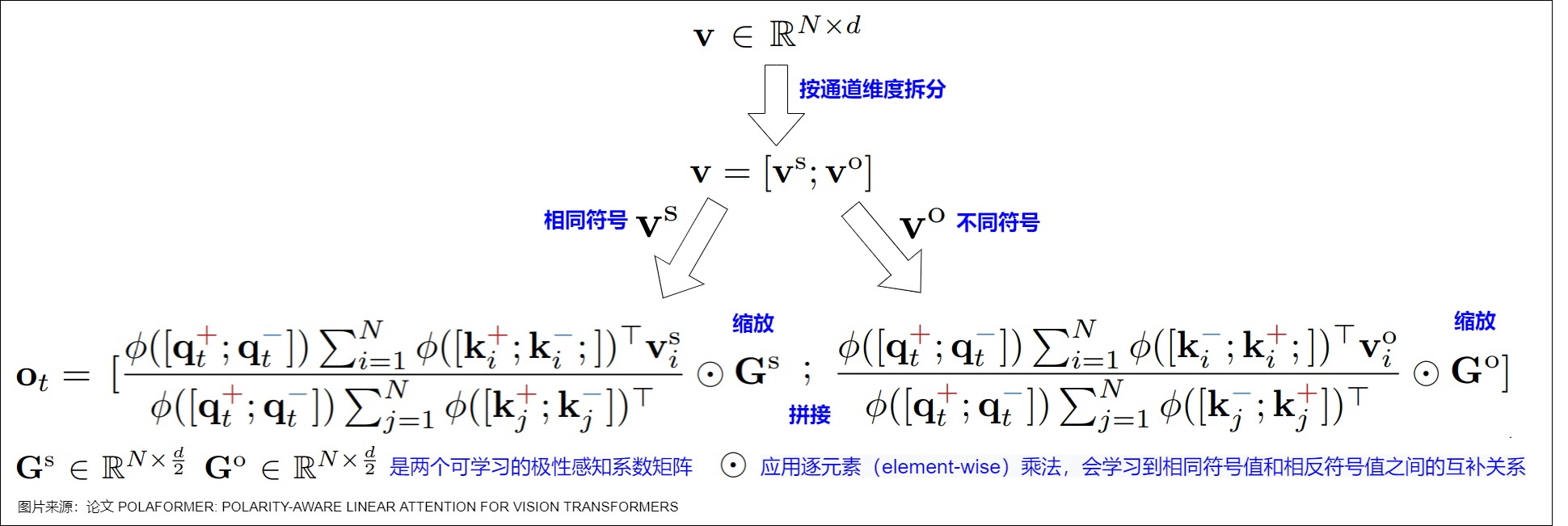
PolaFormer 根据极性明确地将 q,k 对分开,处理在内积计算过程中维度的同号和异号交互作用。这些交互作用在两个流中处理,从而能够更准确地重建原始的 softmax 注意力权重。为了避免不必要的复杂性,作者沿着通道维度拆分 v 向量,在不引入额外可学习参数的情况下处理这两种类型的交互作用。然后,将输出进行拼接,并通过\(G^S\)和\(G^O\)进行缩放,以确保准确重建 q,k 关系。\(G^S\)和\(G^O\)是两个可学习的极性感知系数矩阵,应用了逐元素(element-wise)乘法,会学习相同符号值和相反符号值之间的互补关系。
具体也可以参见下图。
为了解决线性注意力中常见的注意力权重分布信息熵过高的问题,作者提供了数学理论基础,表明如果一个逐元素计算的函数具有正的一阶和二阶导数,则可以重新缩放 q,k 响应以降低熵。这一理论有助于阐明为什么先前的特征映射会提高信息熵,从而导致注意力分布过于平滑。为了简化,作者采用通道级可学习的幂函数进行重新缩放,这保留了 Softmax 中固有的指数函数的尖锐性。这使得模型能够捕获尖锐的注意力峰值,提高了其区分强弱响应的能力。与此同时,为了区分开不同通道之间的主次关系,作者设计了可学习的幂次来捕捉每个维度的不同重要性。

MiniMax-01
MiniMax-01是第一个依赖线性注意力机制的大规模部署的模型。线性注意力则可以把复杂度控制在线性增加范围,但它基本是一种“实验”的状态。MiniMax-01在注意力机制层面做了大胆的创新,在业内首次实现了新的线性注意力机制,第一次把它放到了生产环境里。它的80层注意力层里,每一层softmax attention层前放置了7层线性注意力(lightning attention)层。
模型架构
MiniMax-01是基于线性注意力机制,采用混合架构 (Hybrid-Lightning),并集成了 MoE 架构。

Lightning Attention
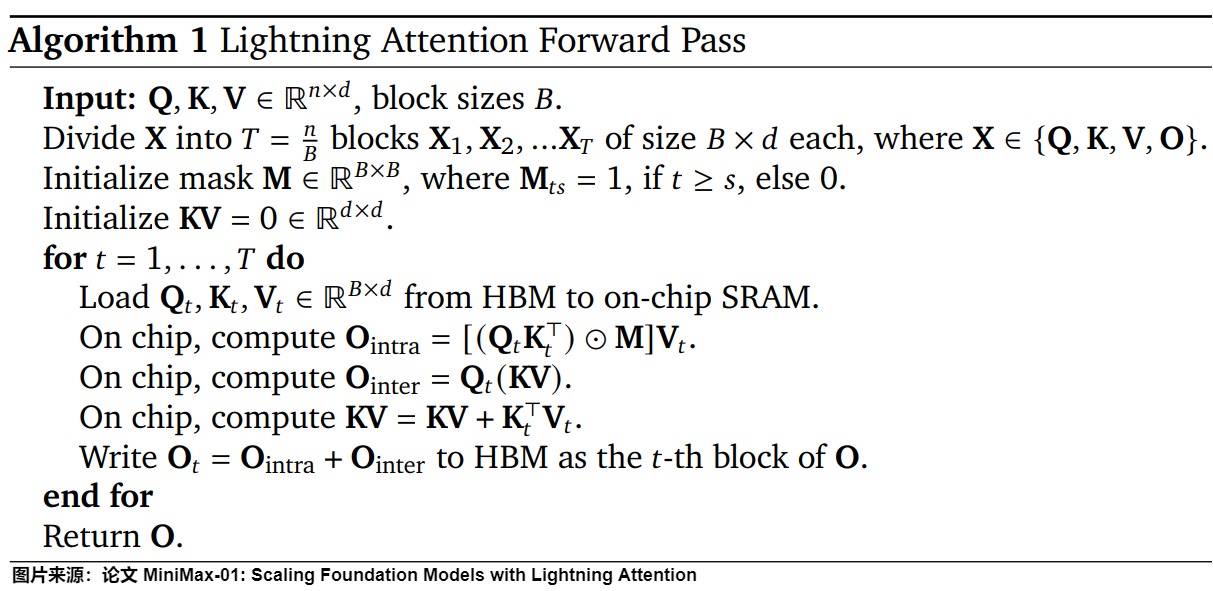
MiniMax 的 Lightning Attention 便是一种线性注意力,是基于 TransNormer 实现的一个 I/O 感知型优化版本。Lightning Attention 的线性注意力机制解决了因果模型在计算单向注意力时,需要进行累加求和操作导致无法矩阵运算的情况,实现了单向注意力先计算右乘,成功将复杂度降为 \(O(nd^2)\) 。具体而言,Lightning Attention是通过进行tiling(分块计算),避免了因果语言建模中的累积求和操作,从而实现了理论上的线性复杂度。具体来说,对于超长序列,Lightning Attention将Q、K和V矩阵沿行维度划分为多个块,每个块的大小固定。然后将注意力计算分为块内计算(使用左积)和块间计算(使用右积)两部分,先独立计算块内部的词之间的注意力分数(intra-block),接着再通过一种递归更新的方法,将块与块之间的信息逐步传递(inter-block),最终可以捕捉到全局语义关系。
这个过程类似于分组讨论:先解决每组内部的问题,再汇总所有组的结果,最终得到全局的答案。这种优化大大减少了计算和内存需求,也从传统 Softmax 注意力的平方复杂度降低为线性。或者也可以把模型想象成在翻阅一本巨大的书,即使每次只能看几页,但它能记住之前的内容,最终把整本书的知识都处理一遍。
以下是 Lightning Attention 前向传播的算法描述。
Hybrid-lightning
为了平衡效率与全局信息捕捉能力,MiniMax 还基于 Lightning Attention提出了一种 Hybrid-lightning,即在 Transformer 的每 8 层中,有 7 层使用 Lightning Attention,高效处理局部关系;而剩下 1 层保留传统的 Softmax 注意力,从而既解决了 softmax 注意力的效率问题,确保能够捕捉关键的全局上下文,也提升了 Lightning Attention 的 scaling 能力。和传统的机制相比,一个是看书时候每个字都看,另一个是挑重点看,然后偶尔看一下目录对照一下整体。效率自然不同。
此外,它还引入了Varlen Ring Attention,用来直接将整个文本拼接成一个连续的序列,从而让变长序列的数据在模型中按需分配资源;在预训练数据上使用数据打包(Data Packing),将不同长度的文本拼接成连续的长序列;在分布式计算时改进了 Linear Attention Sequence Parallelism (LASP+),使模型能够在多 GPU 之间高效协作,无需对文本进行窗口切分。
下表给出了根据层数 l、模型维度 d、批量大小 b 和序列长度 n 计算注意力架构参数量与 FLOPs 的公式。可以明显看出,模型规模越大,Lightning Attention 与 Hybrid-lightning 相对于 softmax 注意力的优势就越明显。

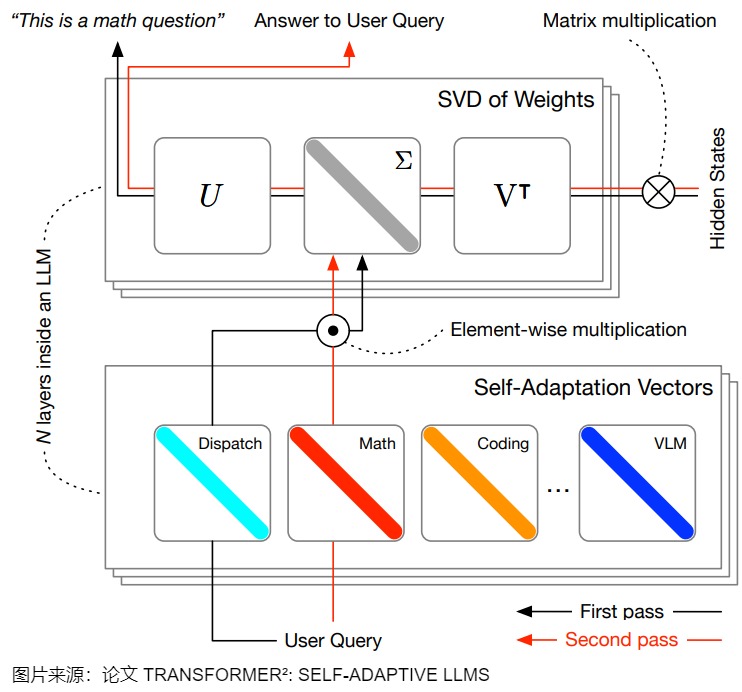
Transformer²
论文"Transformer² : SELF-ADAPTIVE LLMS" 中提出了一种可以根据不同任务动态调整模型权重的机器学习系统 ——Transformer²,其通过奇异值微调和权重自适应策略,实时选择性地调整权重矩阵中的单一组件,提高了LLM的泛化和自适应能力,使LLM能够适应未见过的任务。几个有趣的思路如下:
- 虽然论文题目叫\(Transformer^2\),但其实并不是对Transformer结构做了改变,而是在推理时分两次推理。
- 使用SVD分解训练,而非LoRA。
- 使用Reinforce方法,而非SFT。
研究背景
自适应性
在自然界,「适应」是一种非常普遍的现象。例如,章鱼能够迅速改变自身的肤色和纹理,以融入周围环境,从而躲避天敌和捕捉猎物;人脑在受伤后能够重新连接自身神经回路,使个体能够恢复失去的功能并适应新的思维方式或行动方式。生物体展现出的适应能力使得生命能够在不断变化的环境中蓬勃发展。这些无不体现着那句经典的名言——「物竞天择,适者生存」。
在人工智能领域,适应的概念同样具有巨大的吸引力。想象一个机器学习系统,它能够动态地调整自身的权重以在陌生的环境中不断学习、进化。与部署在环境中的静态 AI 模型相比,这种有自适应能力的模型明显学习效率更高,而且有望成为与现实世界动态本质始终保持一致的终生模型。
SVD
就像人类大脑通过互连的神经通路存储知识和处理信息一样,LLM 在其权重矩阵中存储知识。这些矩阵是 LLM 的「大脑」,保存着它从训练数据中学到的精髓。要理解这个「大脑」并确保它能够有效地适应新任务,需要仔细研究其内部结构。而奇异值分解(SVD)提供了宝贵的洞察力。
SVD通过识别LLM权重矩阵中的主成分来实现这一目标。SVD 将存储在 LLM 中庞大、复杂的知识分解成更小的、有意义的、独立的部分(例如数学、语言理解等不同的组件)。在研究中发现,增强某些成分的信号,同时抑制其他部分的信号,可以提高LLM在下游任务中的表现。
可以将SVD看作是一名外科医生,正在对LLM的大脑进行细致操作。这名外科医生将LLM中存储的庞大复杂的知识分解成更小、更有意义且独立的部分(例如,针对数学、语言理解等的不同路径或组件)。
或者说,预训练已经使模型充分具备了解答问题的能力,而微调实际上是将该能力涌现出来,因此可以通过构建子矩阵并仅调整奇异值矩阵部分主成分的方法来达到轻量微调的效果。且由于仅微调奇异值尺度本身,因此可以使用少量数据训练而不会导致大规模遗忘或崩溃。
研究动机
虽然组合性和可扩展性对于有效适应至关重要,但当前的 LLM 训练方法难以同时实现这两个特性。Sakana AI 的研究旨在提出一个开创性的解决方案来实现这一愿景并解决这些 gap。
传统上,LLM 后训练试图通过一次全面的训练来优化模型,使其具备广泛的能力。对于LLM来说,想要加入哪怕只是一句话的新知识,都必须要再训练一次。从简化的角度,这种「one shot(一次性)」微调框架从简单性的角度来看是理想的,但在实践中很难实现。例如,后训练仍然非常消耗资源,导致巨大的计算成本和超长的训练时间。此外,在引入更多样化的数据时,往往存在明显的性能权衡,这使得同时克服过拟合和任务干扰变得具有挑战性。另外,目前微调过程会产生灾难性遗忘和泛化性低的问题。使用某个数据集对某个模型进行微调训练,再进行评测,会发现大概率上,该模型其他任务的性能会全面下降,甚至本任务也有一定程度的下降(过拟合+遗忘)。这是因为微调的过程虽然简单,但是却破坏了模型原有的能力。
相比之下,自适应模型提供了更灵活和高效的方法。与其试图一次性训练 LLM 完成所有任务,不如开发专家模块,然后根据需求将其离线开发并增强到基础LLM中。专家模块可以离线开发并按需增强到基础 LLM 中。这使模型能够根据当前任务动态修改其行为,而无需不断重新调整。除了具有独立组件的好处外,这种模块化还支持持续学习,使模型能够随时间增加新技能而不会出现灾难性遗忘。此外,自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
原则上,实现自适应 LLM 的第一步可以通过开发专门的专家模块来实现,每个模块都通过 LoRA 等技术进行微调。然后这些专家模块可以根据任务需求在运行时动态组合,这个过程可以通过 MoE 类系统高效管理。然而,要使这种方法既可扩展又具有组合性,需要解决几个挑战。首先,微调 LLM 以创建多个专家模块显著增加了需要训练的参数数量。实际上,即使使用 LoRA 等参数高效的方法,这些模块的累积大小也会快速增加,导致存储和计算需求增加。其次,这些专家模块往往容易过拟合,这种现象在较小数据集或窄任务领域训练时尤为普遍。第三,这些专家模块的灵活组合也带来了目前尚未解决的挑战。
另外,多个LoRA也不具备可组合型。实际上LoRA在扩散模型算法的领域内是可以组合的,例如风格LoRA和人物LoRA可以同时在一个模型上应用起来分别生效,但是这个不是LoRA的特性,而是扩散算法本身的稳定性,而在大模型领域,多个LoRA联合使用是不具备数学意义的。因此奇异值微调的数学意义是具备了充分的可解释性(向量方向和尺度)和可组合型(例如插值),因此可以组合多个tuner共同使用。
思路
奇异值微调(SVF)
为了克服针对组合性和可扩展性的这些限制,Transformer² 作者首先提出了奇异值微调(SVF),这是一种使用强化学习(RL)来增强或抑制不同「大脑」组件的信号,也是一种新的参数高效微调(PEFT)方法,用于获得自适应的有效构建块。
SVF 使用SVD将LLM的「大脑」(即权重矩阵)分解为若干独立的组件,组件可能在多个任务中共享。比如,某些组件在语言理解和推理任务之间是共享的。在训练时,SVF利用RL训练这些组件的组合以应对不同任务。在推理时,SVF首先识别任务类型,然后动态调整组件的组合。
具体而言,在训练阶段,SVF学习一组z向量,其中每个下游任务对应一个z向量。每个z向量可以视作该任务的专家,它是一个紧凑的表示,指定了权重矩阵中每个组件的期望强度,充当「放大器」或「衰减器」,调节不同组件对模型行为的影响。例如,假设SVD将权重矩阵分解为五个组件[A,B,C,D,E]。对于数学任务,学习到的z向量可能是[1,0.8,0,0.3,0.5],这表明组件A对数学任务至关重要,而组件C几乎不影响其表现。对于语言理解任务,z向量可能是[0.1,0.3,1,0.7,0.5],表明尽管C组件对数学任务的贡献较小,但它对语言理解任务至关重要。SVF利用RL在预定义的下游任务集上学习这些z向量。学习到的z向量使Transformer²能够适应各种新的下游任务,同时仅引入最少量的附加参数(即z向量)。为何说这样参数量非常低?是因为U和V矩阵不参与训练,因此仅需要一个一维向量z,即可以表达某个具体dense矩阵的改变。
下图给出了SVF的概况。在训练时,Transformer² 使用SVF和RL来学习“专家”向量z,这些专家向量可以缩放权重矩阵的奇异值。在推理时,Transformer² 提出了三种不同的方法来自适应地选择/组合学习到的专家向量。

另外,Transformer²使用Reinforce方式而非SFT。作者给出的解释是RL对数据集的要求更低。由于RL是针对奖励值进行优化而非next-token的逻辑关联,因此可以忽视CoT带来的影响,使用较为一般的数据集进行训练。
自适应性
在推理阶段,Transformer²采用两阶段适应策略,以有效地组合任务特定的 z 向量集。Transformer²这个名称也反映了它的两步过程。其核心在于能够动态调整权重矩阵中的关键组件。
首先,模型分析传入的任务以了解其要求,然后应用特定于任务的调整来生成最佳结果。即,第一次推理分析任务类型,第二次推理则会根据任务类型来选择具体的tuner(或者类似MoE,进行专家间的组合推理)进行推理来解决具体问题。通过有选择地调整模型权重的关键组成部分,该框架允许 LLM 实时动态地适应新任务。
-
在第一次阶段,Transformer² 执行模型并观察其测试时行为,收集相关信息以理解解决当前问题所需的技能。对于给定任务或单个输入提示,Transformer²通过以下三种适配方法之一来识别任务的特征。
- 基于prompt的适配:专门设计的适配性提示,让LLM对输入prompt进行分类,并选择合适的 z 向量。
- 基于分类器的适配:使用依靠 SVF 训练的任务分类器,在推理过程中识别任务,并选择合适的 z 向量。
- 少样本适配:通过加权插值来组合多个预训练的 z 向量。
这三种方法共同确保了Transformer²能够实现强大且高效的任务适应,为其在多种场景下的出色表现奠定了基础。
-
在第二阶段,Transformer²框架通过组合 z 向量来相应地调制权重,从而生成最适合任务的最终响应。
下图给出了Transformer²的总体架构。
Titans
论文“Titans: Learning to Memorize at Test Time)”提出了一种新型的神经长期记忆模块,该模块能够在利用长远历史信息的同时,让注意力机制专注于当前上下文。该神经记忆的优势在于可以快速并行训练,并保持快速推理。论文指出,由于上下文有限但依赖关系建模精确,注意力机制可以作为短期记忆;而神经记忆由于其记忆数据的能力,可以作为长期、更持久的记忆。基于这两个模块,论文引入了一种新的架构——泰坦(Titans),并提出了三种变体来有效地将记忆融入架构中。
研究背景和动机
近年来,循环模型和注意力机制在深度学习领域得到了广泛应用。循环模型旨在将数据压缩成固定大小的记忆(隐藏状态),而注意力机制则允许模型关注整个上下文窗口,捕捉所有标记的直接依赖关系。然而,这种更精确的依赖关系建模带来了二次方的计算成本,限制了模型的上下文长度。
核心创新
这篇论文的核心创新在于提出了一个能够在测试时学习记忆的神经长期记忆模块(neural memory module)。它能够学习记忆历史上下文,并帮助注意力机制在利用过去已久信息的同时处理当前上下文。结果表明,这种神经记忆具有快速并行化训练的优势,同时还能保持快速推理。
这个模块的工作方式如下:
- 记忆的获取: 该模块将训练过程视为在线学习问题,旨在将过去的信息压缩到其参数中。受人类记忆启发,该模块将“违反预期”的事件(即令人惊讶的输入)视为更值得记忆的。它通过计算神经网络相对于输入的梯度来衡量输入的“惊讶程度”,并使用这一指标来更新记忆。
- 遗忘机制: 为了解决有限记忆的问题,该模块引入了一种自适应的遗忘机制,该机制考虑了记忆大小和数据惊讶程度,从而更好地管理记忆。
- 记忆的结构: 论文探索了不同的记忆结构,发现深度记忆模块(即使用多层感知机)比线性模型更有效。
- 记忆的检索: 该模块通过简单的正向传递(不更新权重)来检索与查询相对应的记忆。
Titans架构
基于长期神经记忆模块,论文提出了泰坦架构,该架构包含三个分支:
- 核心分支(Core): 使用注意力机制进行数据处理,关注有限的上下文窗口。
- 长期记忆分支(Long-term Memory): 使用神经长期记忆模块来存储和回忆历史信息。
- 持久记忆分支(Persistent Memory): 使用可学习但不依赖于数据的参数来编码任务相关知识。
论文提出了三种不同的泰坦变体来有效地将记忆融合到该系统架构中。
- 上下文记忆(Memory as a Context,MAC): 将长期记忆视为当前信息的上下文,使用注意力机制融合这些信息。
- 门控记忆(Memory as a Gate,MAG): 使用门控机制将长期记忆与核心分支的信息融合。
- 层式记忆(Memory as a Layer,MAL): 将长期记忆模块作为深度神经网络的一层。
长期记忆
为了设计一个长期神经记忆模块,我们需要模型能够将过去历史的抽象编码到其参数中。因此,一个简单的思路是训练神经网络并期望它能够记住自己的训练数据,然而记忆几乎一直是神经网络中令人头疼的现象,它限制了模型的泛化能力,还引发隐私问题,因此导致测试时性能不佳。
基于此,谷歌认为需要一个在线元模型来学习如何在测试时记忆或忘记数据。在这种设置下,模型学习一个能够记忆的函数,但不会过拟合训练数据,从而在测试时实现更好的泛化性能。
-
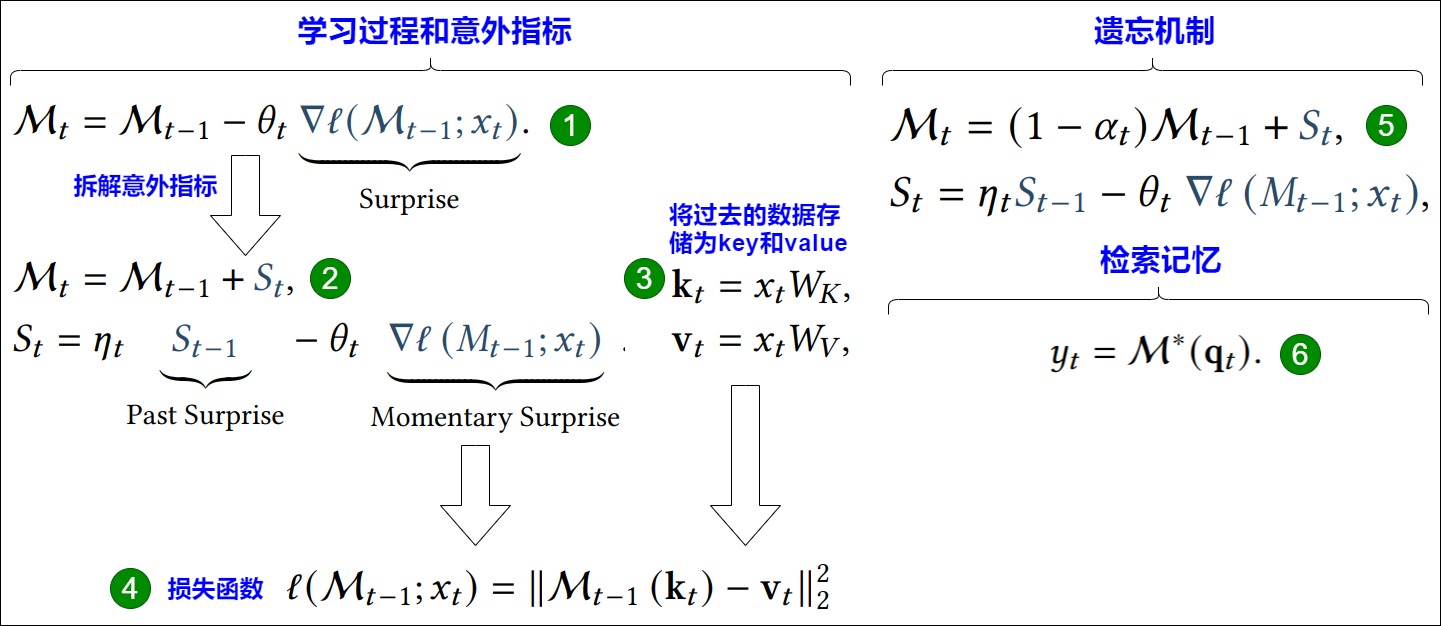
学习过程和意外指标(Learning Process and Surprise Metric)。训练长期记忆的关键思路是将训练视为在线学习问题,将过去信息压缩到长期神经记忆模块中。人类往往能够记住背离预期(令人惊讶)的事件,受此启发,模型意外可以简单定义为它相对于输入的梯度。梯度越大,输入数据与过去数据的偏差就越大。因此,使用这个意外分数,可以将记忆更新如下图标号1。
意外指标可以导致在重大意外时刻之后出现重要信息缺失。从人类记忆的角度来看,即使一个事件令人难忘,但它可能不会在长时间内持续让我们感到惊讶。为了改进这一现象,谷歌将意外指标分解称为(1)过去意外,它衡量最近过去的意外程度;(2)瞬时意外,它衡量传入数据的意外。具体如下图标号2。
-
上述的意外指标是基于一个损失函数 $ l(.;.)\(之上的,它就是记忆模块在测试时学习的目标。也就是说,记忆模块是一个元模型,它基于损失函数\)l(.;.)$来学习一个函数。谷歌则专注于关联(associative)记忆,目的是将过去的数据存储为键(keys)和值(values)对。类似于 Transformer,在给定 x_t 的情况下,谷歌使用两个线性层将 x_t 投影到键和值中。如下图标号3。谷歌希望记忆模块可以学习键和值之间的关联,为此将损失定义如下图标号4。
-
遗忘机制(Forgetting Mechanism)。在处理非常大的序列(比如百万 tokens)时,管理哪些过去信息应该被遗忘非常重要,即使使用深度或者非常大的矩阵值记忆时也是如此。因此,谷歌使用了一种自适应遗忘机制,允许记忆忘记不再需要的信息,从而更好地管理有限的记忆容量。也就是说,给定下一个 token x_t,遗忘机制如下图标号5:
-
检索记忆(Retrieving a Memory)。在探讨如何设计和训练一个可以在测试时学习记忆的长期记忆模块之后,剩下的关键问题便是如何从记忆中检索信息?谷歌仅仅使用了没有更新权重的前向传递(即推理)来检索与查询相对应的记忆。在形式上,给定一个输入 x_t,谷歌使用线性层 W_Q 来投影输入,即 q_t = x_tW_Q,并通过以下公式从记忆 y_t 中检索相应(或有用)的信息,对应下图标号6。
融合记忆
接下来需要解决的一个重要问题是:如何有效且高效地将神经记忆融合到深度学习架构中?
从记忆的角度来看,Transformer 中的 K 和 V 矩阵对可以解释为联想记忆块。由于它们对依赖关系的精确建模以及有限的上下文窗口,它们可以被用作短期记忆模块,以处理当前上下文窗口大小。另一方面,神经记忆能够不断从数据中学习并存储在其权重中,因而可以发挥长期记忆的作用。谷歌通过三个不同的 Titans 变体来回答以上问题。
如果把token看作是Instruction, Test Time ScalingLaw可能就是对token序列进行修改,让模型按照新的流程来执行。Titans可能就是这样一个自我验证纠错机制的雏形。注意力机制可以类比为片上指令缓存,神经记忆模型可以类比为代码段。
记忆作为上下文(Memory as a Context,MAC)
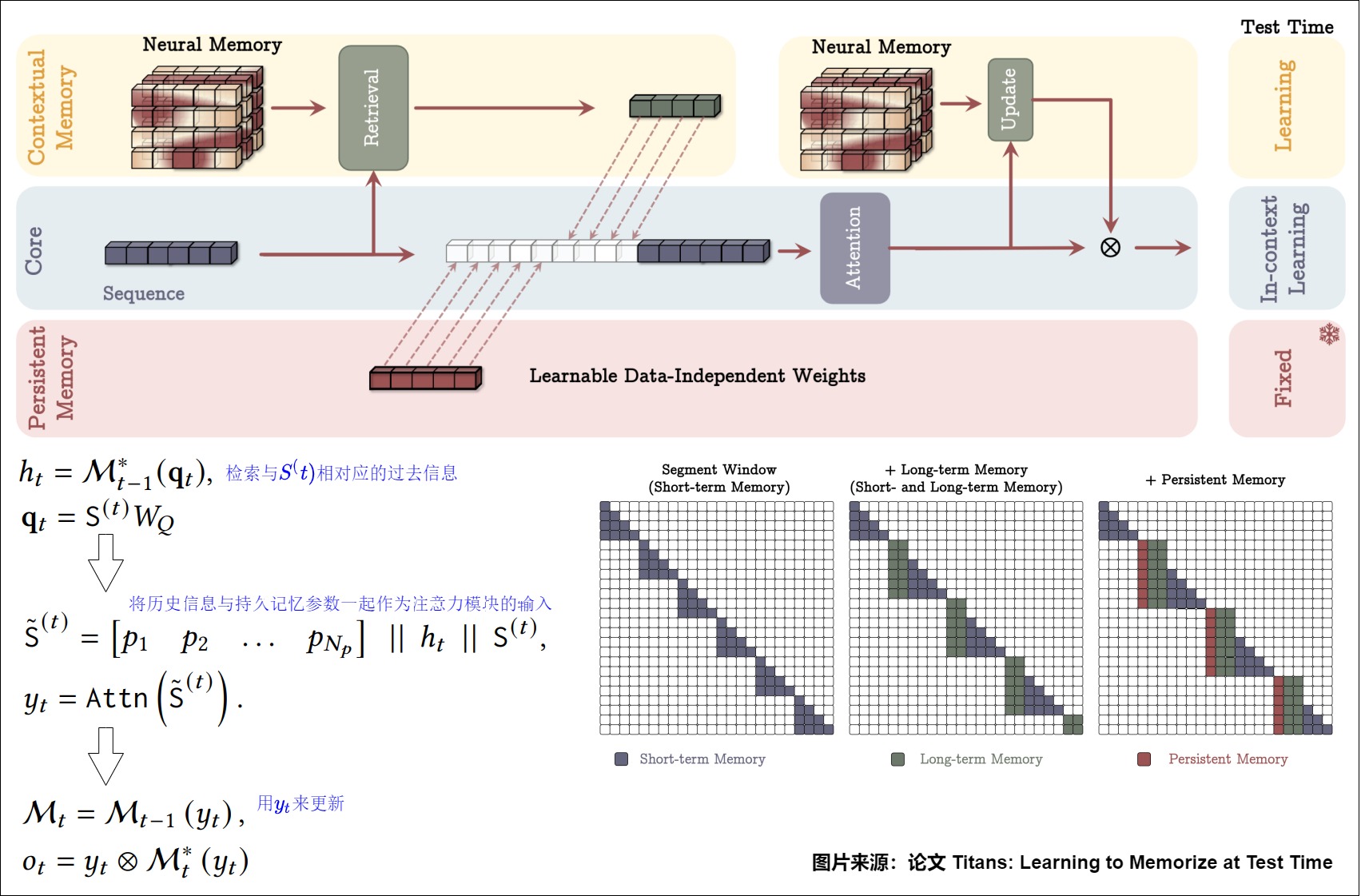
Titans 的第一个变体 MAC 的架构设计如上图所示,将记忆作为当前信息的上下文。
该架构具有两个关键优势:一是注意力模块同时具有历史和当前上下文,能够根据当前数据决定是否需要长期记忆信息,二是注意力模块帮助长期记忆只存储来自当前上下文的有用信息。这意味着,并非每个片段中的所有 token 都是有用的,记忆所有 token 可能会导致内存溢出。因此,注意力模块帮助记忆了解哪些信息是有用的,从而更好地管理内存容量。
记忆作为门(Memory as a Gate,MAG)
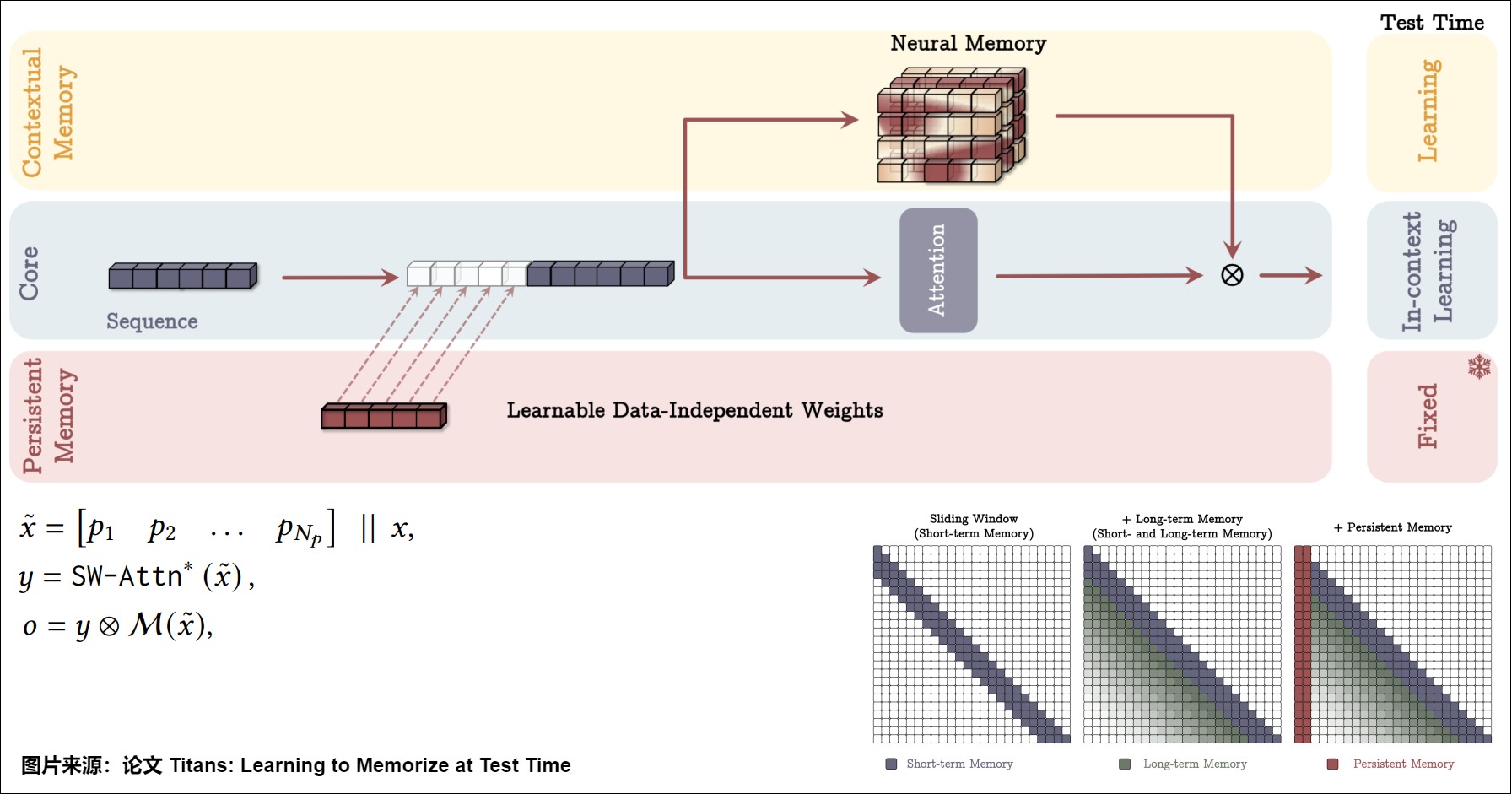
Titans 第二个变体 MAG 的架构设计如上图 所示:
在其中一个分支中,谷歌直接使用输入数据来更新长期记忆;在第二个分支中,谷歌使用了滑动窗口注意力(SWA)该架构的整体注意力掩码如上图所示,其中滑动窗口注意力(SWA)充当精确的短期记忆,而神经记忆模块充当模型的衰减记忆。该设计也可以看作是多头架构,其中各头的结构不同。
记忆作为层(Memory as a Layer,MAL)
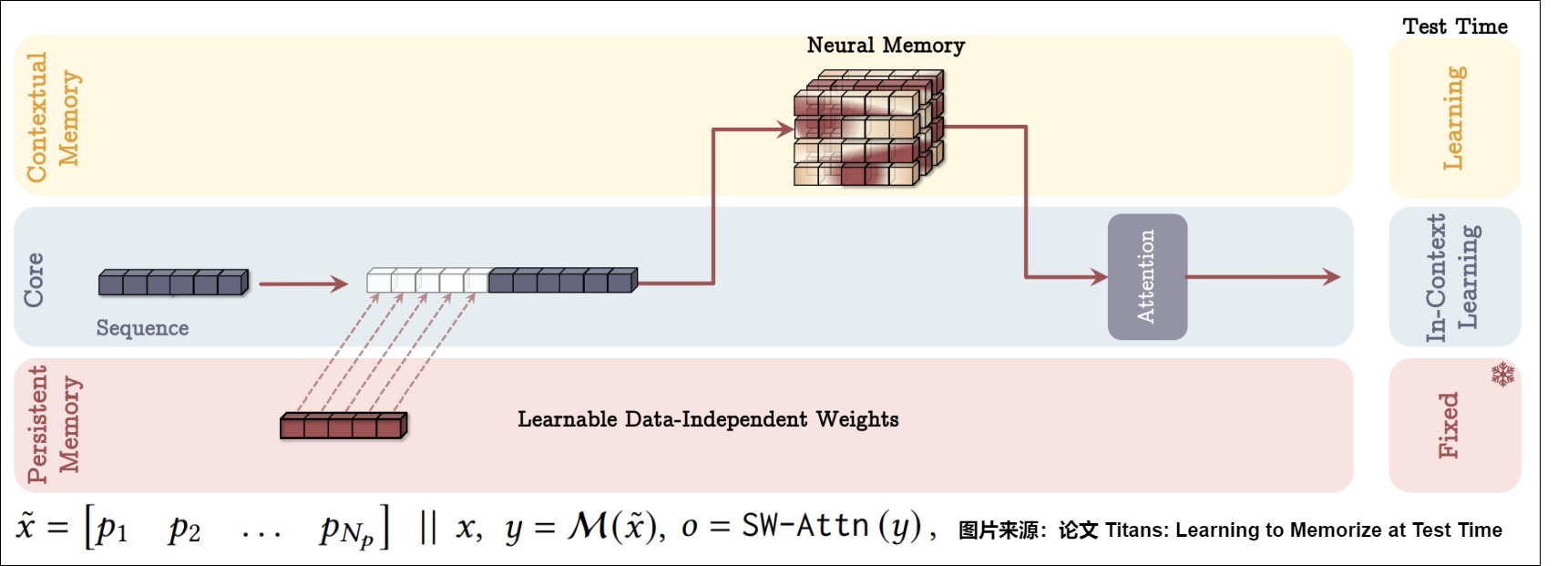
Titans 的第三个变体 MAL 使用了深度神经网络,这种架构设计在文献中更为常见,其中混合模型堆叠具有完整或滑动窗口注意力的循环模型。
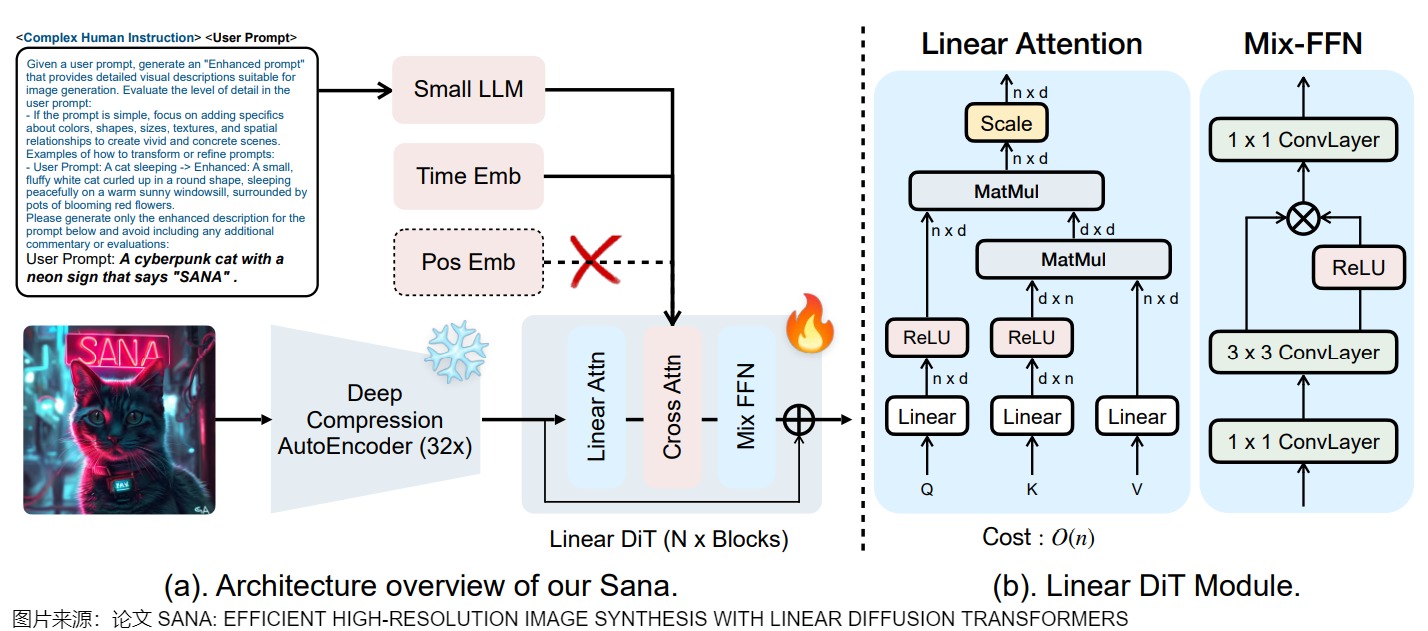
SANA
论文”SANA: EFFICIENT HIGH-RESOLUTION IMAGE SYNTHESIS WITH LINEAR DIFFUSION TRANSFORMERS“则如下定义线性注意力。
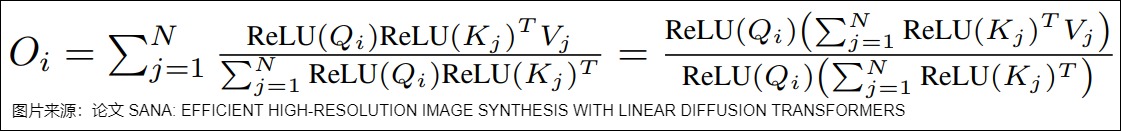
线性注意力会降低注意力运算的效果。为了弥补这一点,Sana 把FFN从 MLP (即 1x1 卷积网络)换成了 3x3 逐深度卷积的网络。这不仅提升了整个 Transformer 块的拟合能力,还省去了位置编码——由于卷积网络天然能够建模相对位置关系并打破 Transformer的对称性。
0xFF 参考
2024 || CorDA: 内容相关的大模型主成分微调 机器学习与大模型
2024 || MiLoRA: 保留主要成分的大模型微调 机器学习与大模型
[NDSS 2024]浙江大学提出动态注意力机制:提升Transformer模型鲁棒性,无需额外资源消耗 [为机器立心]
[NLP] Adaptive Softmax listenviolet
[细读经典+代码解析]Attention is not all you need [补更-2021.03.22] 迷途小书僮
A Mathematical Framework for Transformer Circuits Nelson Elhage∗†, Neel Nanda∗,
CorDA: Context-Oriented Decomposition Adaptation of Large Language Models
Efficient softmax approximation for GPUs
ICLR 2025 | 极性感知线性注意力!哈工深张正团队提出PolaFormer视觉基础模型 [机器之心]
MiLoRA: Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning
MiniMax-01中Lightning Attention的具体实现 Garfield大杂烩
More About Attention 李新春
Pay Attention to Attention for Sequential Recommendation
PolaFormer: Polarity-aware Linear Attention for Vision Transformers
RecSys'24 | 通过额外的注意力来增强自注意力机制用于序列推荐 [秋枫学习笔记]
softmax is not enough (for sharp out-of-distribution)
Softmax与其变种 DengBoCong
Synthesizer: Rethinking Self-Attention for Transformer Models
Titans: Learning to Memorize at Test Time
Transformer Circuits的数学框架 Hao Bai
Transformer Explainer: Interactive Learning of Text-Generative Models
Transformer 解释器:文本生成模型的交互式学习 无影寺 [AI帝国]
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Transformer² : SELF-ADAPTIVE LLMS
Transformer²要做「活」的AI模型,动态调整权重,像章鱼一样适应环境 机器之心
transformer中的attention为什么scaled? 看图学
Transformer为什么要引入MHA? 技术微佬 [丁师兄大模型]
Transformer作者初创重磅发布Transformer²!AI模型活了,动态调整自己权重 新智元
Transformer升级之路:15、Key归一化助力长度外推 苏剑林
Transformer多头自注意力机制的本质洞察 作者:Nikolas Adaloglou 编译:王庆法
Transformer多头自注意力机制的本质洞察 作者:Nikolas Adaloglou 编译:王庆法
【NLP】词表太大怎么办—Adaptive softmax模型和代码解析 南枫
什么是Scale Self Attention?为什么Transformer中计算注意力权重时需要做缩放? AI算法之道
从泛函分析的角度解释Attention机制和卷积神经网络的本质区别 OxAA55h [套码的汉子]
从熵不变性看Attention的Scale操作 苏剑林
余弦相似度可能没用?对于某些线性模型,相似度甚至不唯一 机器之心
十倍加速! adaptive softmax HaoC
图解 Transform
大脑如何在社会中“导航”?Nature子刊揭示社会层级结构的网格表征 集智科学家
大脑如何表征知识?我们能从中看到现实的本质吗? Patricia [集智俱乐部]
大语言模型背后的神经科学机制 雅牧
如何理解线性代数中的点积 (dot product) 金朝老师来上课 [数据分析学习与实践]
注意力机制 OnlyInfo
激进架构,400万上下文,彻底开源:MiniMax-01有点“Transformer时刻”的味道了 王兆洋 [硅星人Pro]
第六篇:LLM注意力Attention,Q、K、V矩阵通俗理解 原创 咚咚呛 [UP咚咚呛]
简单图解一下线性注意力机制 深海
论文速览 | Sana:用线性 Transformer 高效率生成 4K 图片 [天才程序员周弈帆]
谈谈大模型架构的演进之路, The Art of memory 渣B [zartbot]
近8年后,谷歌Transformer继任者「Titans」来了,上下文记忆瓶颈被打破 [机器之心]
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models: https://arxiv.org/abs/2401.04658
TransNormerLLM: A Faster and Better Large Language Model with Improved TransNormer: https://arxiv.org/abs/2307.14995
论文解读:Transformer^2: Self-adaptive LLMs 小狸愚
谈谈大模型架构的演进之路, The Art of memory 渣B [zartbot]
How Do Language Models put Attention Weights over Long Contexthttps://lyaofu.notion.site/How-Do-Language-Models-put-Attention-Weights-over-Long-Context-10250219d5ce42e8b465087c383a034e)
Llama 3架构及源码解析 [OnlyInfo]