随着大数据和人工智能技术的快速发展,数据平台变得越来越复杂,给数据管理和分析带来了新的挑战。Alluxio,作为一个开源的分布式缓存系统,一直在努力解决这些问题。本文将探讨Alluxio 3.0在分布式大数据和AI缓存架构方面的技术革新和实践。
首先,我们来看看大数据/AI世界的现状。数据平台的多样性导致了数据获取的碎片化,存储与计算分离的架构创新也带来了分割的数据世界。此外,数据复制和同步的复杂性,以及技术变迁导致的多平台混合架构和迁移的复杂性,都是当前面临的主要问题。
为了解决这些问题,Alluxio应运而生。Alluxio提供了一个统一的数据访问层,支持多种计算框架和存储系统。它的主要功能包括多级缓存、动态多挂载点、多接口支持等,这些功能使得Alluxio能够在大数据分析、机器学习等场景中发挥重要作用。
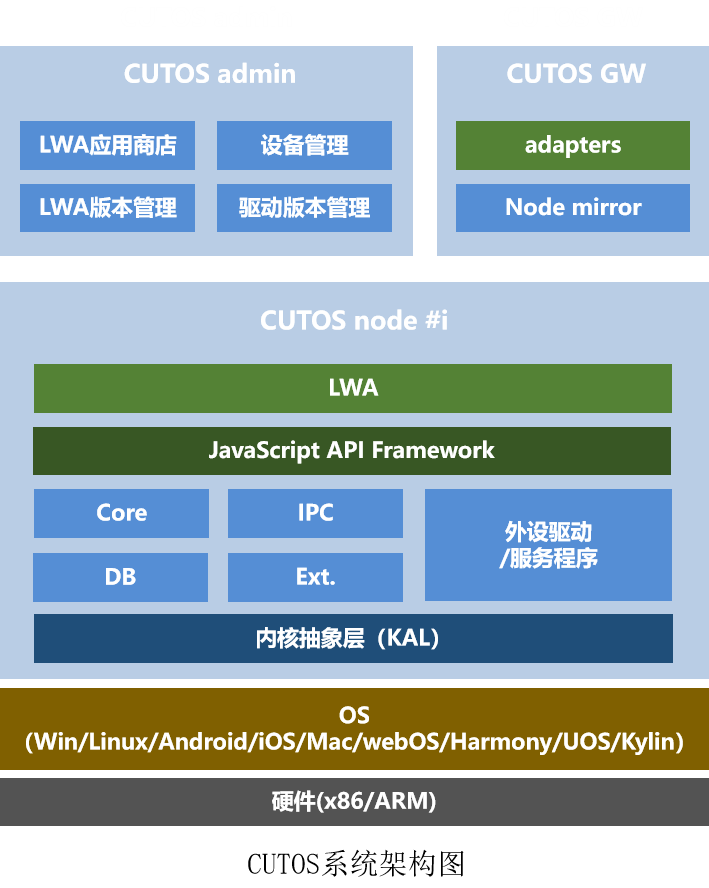
在Alluxio 3.0中,我们可以看到一些重要的技术革新。首先,Alluxio 3.0采用了分布式对象存储架构(DORA),这使得系统具有更好的可扩展性和高可用性。其次,Alluxio 3.0将元数据和数据的管理职责从Master转移到Worker,从而解决了单点瓶颈问题。此外,Alluxio 3.0还优化了缓存性能,提高了GPU利用率。
在实际应用中,Alluxio已经在许多公司得到了广泛应用,如Uber、Shopee等。这些公司通过使用Alluxio,显著提高了数据访问速度,降低了存储成本。
总的来说,Alluxio 3.0在分布式大数据和AI缓存架构方面取得了显著的进步。它的出现,为大数据和AI领域的未来发展提供了新的可能性。随着技术的不断进步,我们期待Alluxio能够在更多场景中发挥重要作用,推动大数据和AI技术的发展。