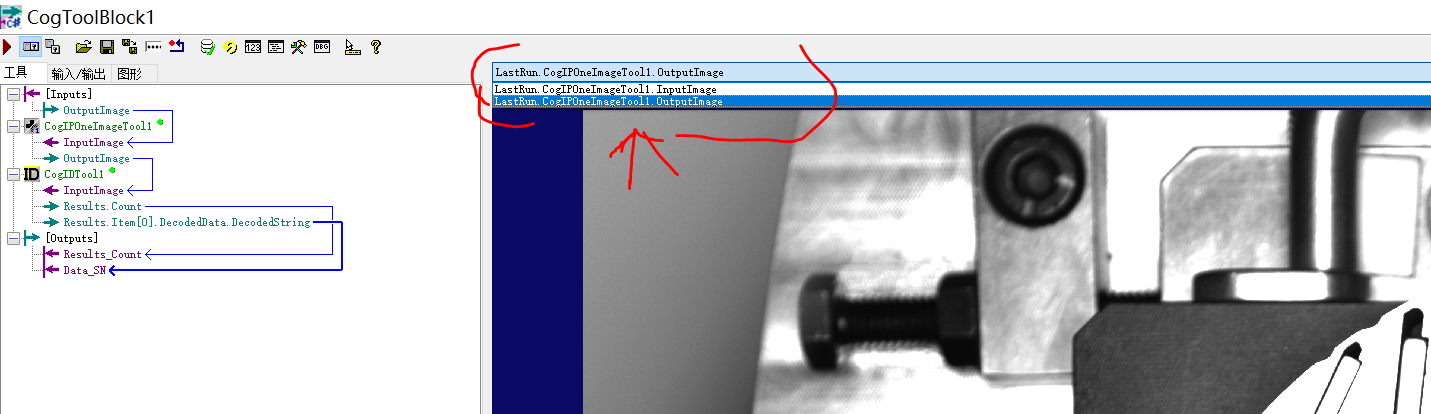
单击MySQL的演进
单机MySQL
在早期互联网时代,也就是90年代以前,一个基本的互联网的访问量不会太大,可以说很多国家和地区都还没有配备互联网,所以在这种情况下的互联网格局使用的数据存储格式就是简单的单机模式,即使用一个数据库的如MySQL库就可以满足日常的数据读写

如上图,APP通过数据访问层直接访问数据库中的数据,读写操作都是直接操作数据库,虽然MySQL的读写操作会很慢,但是访问量小,读写数据小,都是可以实现的
但是随着互联网的技术发展,单机MySQL的弊端很快暴露出来了:
- 数据量太大(大数据时代),单机的容量有限
- 太大的数据量使用B+ Tree结构所产生的索引文件也很大
- 读写混合,读写都在一个机器上,单机承受不住
Memcached(缓存)+MySQL+垂直拆分

垂直拆分对应的关键词就是读写分离:将原来的单机MySQL演变为多机,同时将写文件的操作有一部分机器完成,然后同步给其它的MySQL机器,读操作时就去读机器上查询
同时还映入了缓存机制,当在真实的业务中我们会发现,其实有80%的概率的数据库操作都是在进行读操作,所以大部分的压力还是读问题,频繁的I/O操作还是会压力到数据库,故而使用缓存机制,将已经查询出的记录先缓存在缓存中,等到有相同的查询操作时候会直接返回,避免多次相同的I/O操作
分库分表+水平拆分+MySQL集群
随着互联网的持续发展,尤其是在数据爆炸的时代,使用简单的缓存已经容纳不下数据的爆发式增长了,此时再将业务放在一个库或者一个表中检索起来会十分费劲,故而将数据库优化也迫在眉睫

数据库的水平拆分,也称为横向拆分或分区(Partitioning),是一种将单个数据库中的数据分布到多个数据库实例的技术。这种方法主要是为了解决单一数据库在面对大量数据和高并发访问时可能出现的性能瓶颈问题。通过水平拆分,可以提高系统的扩展性和性能。
其中最明显的操作的热词就是分库分表;原来 一个项目只是用一个数据库,如图书 管理系统,它的功能模块会包含登录,租赁,查询,购买等,像这样的业务都会从一个数据库拆分成几个数据库,而同样的分表操作会使用去耦合的操作将多个字段的数据表分为几个表,减小单表字段降低耦合
MySQL集群通常指的是通过一组互联的MySQL服务器共同工作,以提供高可用性、高性能和扩展性的数据库解决方案。
1. MySQL NDB Cluster
这是MySQL官方提供的一个真正的分布式数据库解决方案,基于NDB存储引擎(Network Database)。NDB Cluster支持自动分片和数据冗余,可以在多个节点之间自动复制数据,确保即使某个节点出现故障,整个系统仍然能够正常运行。它特别适合需要高可用性和可伸缩性的实时应用。
2. 主从复制(Master-Slave Replication)
在这种模式下,数据从一个主服务器复制到一个或多个从服务器。主服务器处理所有的写操作,而从服务器则可以处理读请求。这种方式主要用于提高读性能和数据备份,并不直接增加系统的写入能力。如果主服务器发生故障,可以选择其中一个从服务器提升为主服务器继续服务。
3. 主主复制(Master-Master Replication)
与主从复制不同的是,主主复制中所有节点都可以同时接受读写请求。这种方式可以提高写入性能,但需要解决并发控制和冲突解决的问题,设计复杂度较高。
4. 分库分表(Sharding)
当单个MySQL实例无法满足需求时,可以将数据水平拆分到多个数据库实例中。每个实例只管理部分数据,这样不仅提高了性能,还增强了系统的可扩展性。然而,这种方法增加了系统的复杂性,尤其是在跨库查询和事务管理方面。
如今的系统架构

如今的系统架构是错综复杂的,它不仅提升读写效率还从安全,容灾,负载,效率上各个方面都有所突破,但面临的就是技术不断走高,会出现大部分的投入都在技术和基础设施建设上了
NoSQL
什么是NoSQL?
NoSQL = Not Only SQL(不仅仅是SQL):泛指非关系型数据库
特点:
1.方便拓展(数据之间没有关系,很好拓展)
2.大数据量高性能(Redis一秒可以写8万次,读取11万次,NoSQL是缓存记录级,是一种细粒度的缓存,性能会比较高)
3.数据类型是多样型的(不需要事先设计数据库,如果数据量十分大的表,设计会很麻烦【关系型数据库】)
4.传统RDBMS和NoSQL
传统的RDBMS
- -- 结构化组织
- --SQL
- --数据和关系都在单独的表中
- --操作数据定义语言
- --严格的一致性
- --基础的事务
NoSQL
- --不仅仅是数据
- --没有固定的查询语言
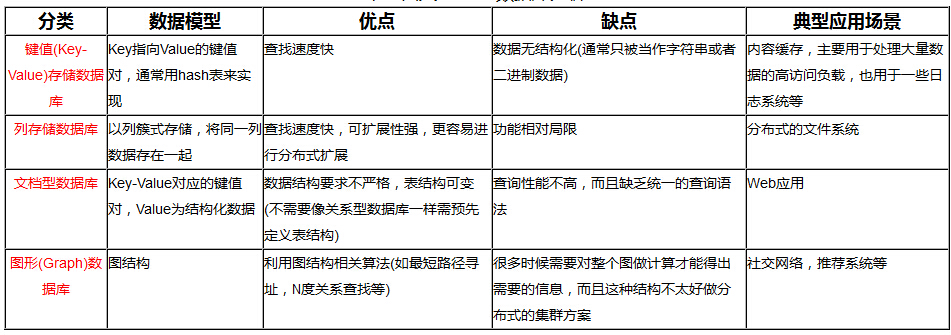
- --键值对存储,列存储,文档存储,图形化数据库
- --最终一致性
- --CAP和BASE (异地多活)
大数据时代的3V(主要是描述问题):海量(volume),多样(Varlety),实时(Velocity);大数据时代的3高(主要是对程序的要求):高并发,高可拓展,高性能
NoSQL的四大分类
KV键值对
- 新浪:Redis
- 美团:Redis+Tair
- 阿里,百度:Redis+memecache
文档数据库(bson格式和json一样)
- MongoDB是一个基于分布式文件系统存储的数据库,C++编写,主要用来处理大量的文档!
- MongoDB是一个介于关系型数据库和非关系型数据库中间的产品!MongoDB是非关系型数据库中功能最丰富的,最像关系型数据库的
列存储数据库
- HBase
- 分布式文件系统
图关系型数据库
使用图结构存储数据,一般用于存储关系网络
![[HDCTF 2023]double_code _wp](https://img2024.cnblogs.com/blog/3599043/202503/3599043-20250309170206785-1506186660.png)