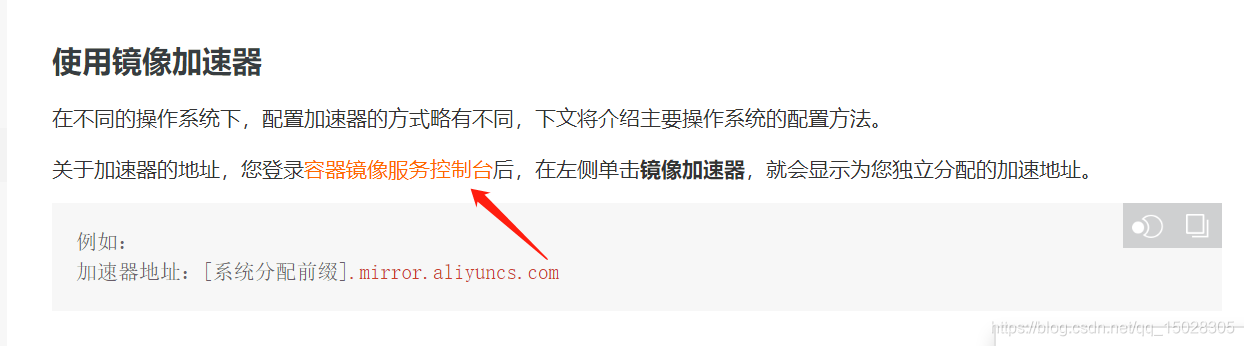
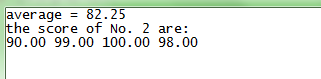
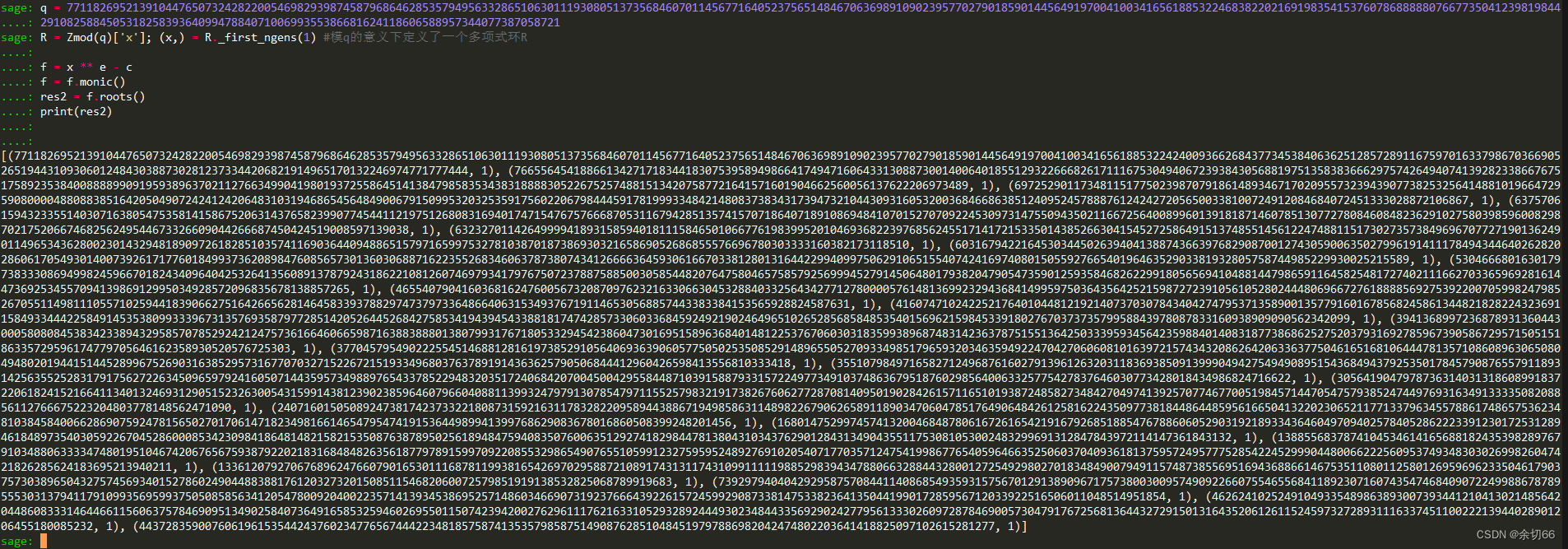
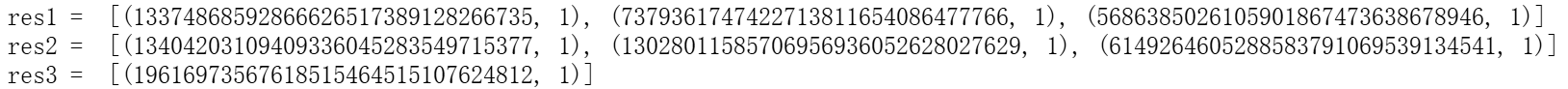\((3)\)
P116的说明,感觉就是矩阵的特征值与矩阵的乘积很相关,所以要控制梯度矩阵的特征值
\((4)\)
采用该方法的主要原因是通过动态调整每层的学习率来维持训练的稳定性,具体分析如下:
-
梯度与权重的平衡:
权重的范数((|w^l|))反映参数的当前幅值,梯度范数((|\nabla L(w^l)|))反映损失对参数的敏感度。二者的比值 (\frac{|w^l|}{|\nabla L(w^l)|}) 衡量了参数更新步长的合理范围。若梯度大(敏感度高),则降低学习率以避免更新过大;若梯度小(敏感度低),则提高学习率以加速收敛。 -
自适应学习率:
传统方法使用全局学习率,但不同层的梯度特性可能差异显著。通过逐层计算 (\lambda^l),可为每层分配与其状态匹配的学习率。例如,梯度爆炸的层自动降低学习率,梯度平缓的层适当增大学习率,从而缓解发散问题。 -
更新量控制:
公式隐含了参数更新量 (\Delta w^l \approx \lambda^l \cdot |\nabla L(w^l)|)。通过设计 (\lambda^l \propto \frac{|w^l|}{|\nabla L(w^l)|}),可使更新量 (\Delta w^l) 的幅值与当前权重幅值成比例((\Delta w^l \propto |w^l|)),避免因步长过大导致权重剧烈震荡。 -
信任系数的作用:
超参数 (\eta) 调节对上述比值的信任程度。较小的 (\eta) 会保守地限制学习率的变化范围,防止因梯度突然变化(如梯度消失)导致的学习率剧烈波动,增强鲁棒性。
综上,该方法通过权重的局部信息自适应调整学习率,平衡各层更新幅度,是预防训练发散的有效事后修正策略。