Deep Learning for Sensor-based Human Activity Recognition
Deep Learning for Sensor-based Human Activity Recognition: Overview, Challenges, and Opportunities: ACM Computing Surveys: Vol 54, No 4
进入WHAR后一直苦于找不带一个明确的问题。经帅气师兄推荐看一下这一篇补充材料。先做出内容总结再设想一下以后可能可以着手的工作。
Abstract
sensor IoT发展的很快,很有希望。
但是存在一些难点。
dl在很多领域取得成功,所以可以试试~
本文对sota的dl方法进行survey。
首先,介绍感官数据multimod,提供公共数据集用以评估
其次,提出whar的分类。
最后,讨论一些悬而未决的方法并且提供一些insight
1. Intro
to intro...
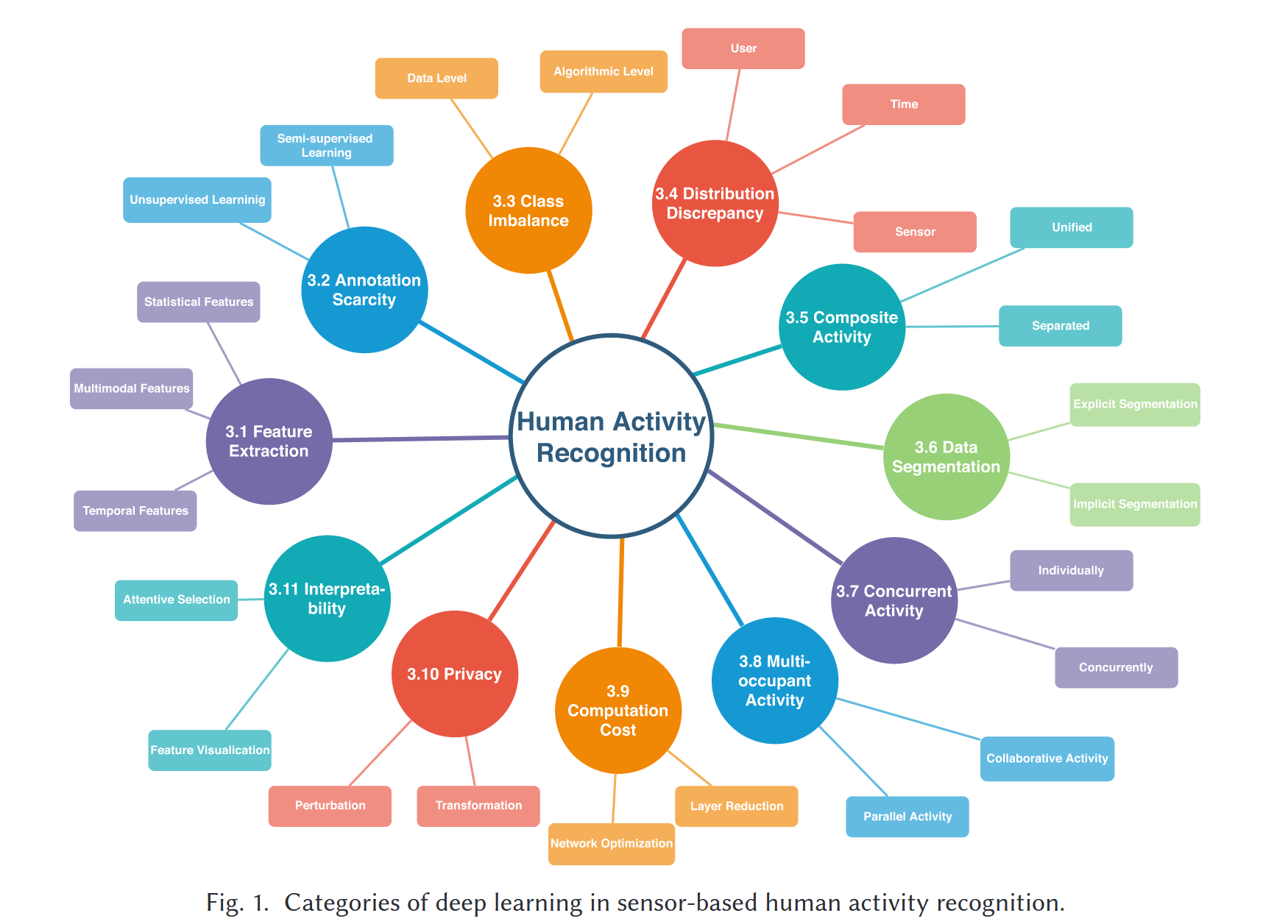
WHAR中的挑战
挑战也可以说是难点。
DL的应用
本文的contribution
2. Sensor Modality & Datasets
sensor mod
datasets
3. Challenges (难点
3.1 feature extraction

3.1.1 single-modal feature extraction methods
文章将特征抽取方法分类为:时序特征,多模态特征、统计学特征
最粗糙的特征有mean和variance。
高级一点的方法:
a) Time-Frequency-Spectral
将时间序列从时域转换到频域来利用频谱功率随时间的变化。
什么是时域什么是频域呢?
时域:数据以时间作为x轴(自变量)。时域数据表示主要关注数据在不同时间点上的值和变化。
频域:数据以频率作为x轴,关注信号在不同频率上的强度
要将时域数据转变到频域数据,可以使用快速傅里叶变换。
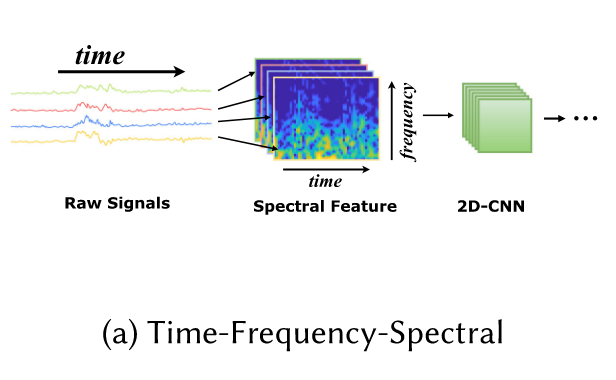
上图就是对该方法的一个简单展示。将sensor数据利用Short-time Discrete Fourier Transform (STDFT)转化成time-frequency-spectral image,再将频域图利用cnn进行特征抽取。
b) RNN
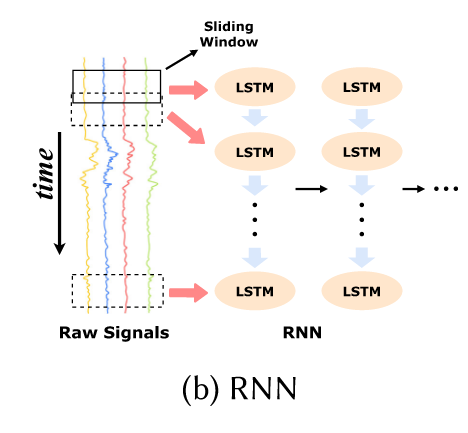
RNN的方法就比较好理解。先把原始数据用滑动窗口切分,再送进RNN抽取特征。
值得注意的是文中提到传统rnn会面临梯度爆炸和梯度消失的问题。但是LSTM将这种问题克服。
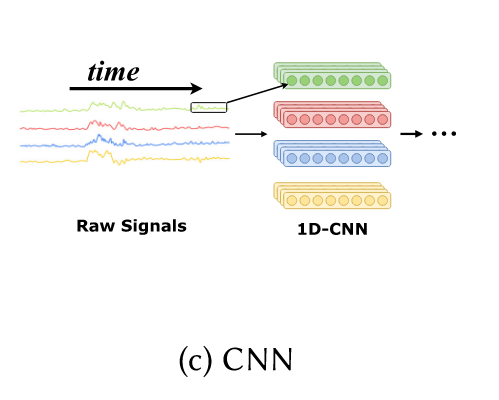
c)CNN
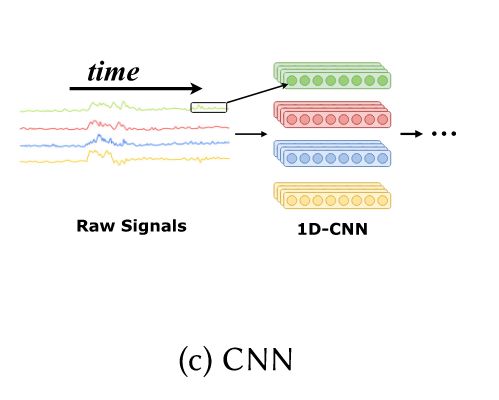
CNN的做法和图像领域的比较一致。在不同的信号上进行一个一维cnn的采样。
面对一维数据我们首先需要去思考如何进行特征的抽取。以上三种方法以及这三种的混搭可以大概的可以满足特征抽取的需要。那么,在WHAR中通常是一个多模态的情况:加速度计、陀螺仪等等。有研究表明多模态的数据可以获得更加好的效果。于是产生一个问题:如何进行多模态特征的提取?
文章给出两个方法:
3.1.2 multi-modal feature fusion methods
a)feature fusion
特征融合的大致思路是将不同模态的特征分别提取,再将他们作为输入给到一个特征融合网络。让该网络吐出一个特征向量进行分类。
那么这种feature fusion也是有很多的方法,作者对这些方法进行了分类:
a.1) Early Fusion
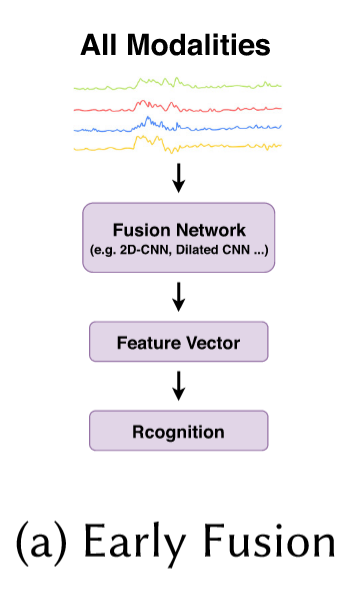
首先是early fusion,前期融合。就是说在数据处理的前期就试图把数据融合到一起。(p.s.对于融合这个词我一开始也不太理解,但是就是通过一些方法把不同的数据合在一起)
方法一:统计学方法描述数据
文中有这样一句话我看不懂:
A simple fusion approach in Reference [76] transformed the raw x, y, and z acceleration data into a magnitude vector by calculating the Euclidean norm of x, y, and z values.
啥是magnitude vector:描述一组数据的强度的一个度量。
啥是euclidean norm:换个名字就懂了:L2Norm
所以这个方法就明了了。就是将输入数据算出一个类似mean、var的统计学意义的数值进行描述。
方法二:concat
有人将多模态数据直接一个模态一个模态水平地接起来,然后再用一维的方法去抽特征。也有人将多模态数据竖直地堆起来变成一个二维的图,然后再用二维的方法去抽特征。还有人将数据reshape成3D的,再用3D-cnn去抽。
CNN懂得都懂,是用一个核把数据扫一遍,所以它是可以抽取到局部的一些信息(令人难受的就是我不知道这个“信息”到底是什么),但是对于视界稍大一些的情况它的效果可能没有那么好(也是想想的)。于是就有人搞了一种特殊的数据排列方式,可以让其中的序列信号都有机会和其他每个序列相邻,只要相邻了就可以被CNN抽特征。
a.2) sensor-based fusion
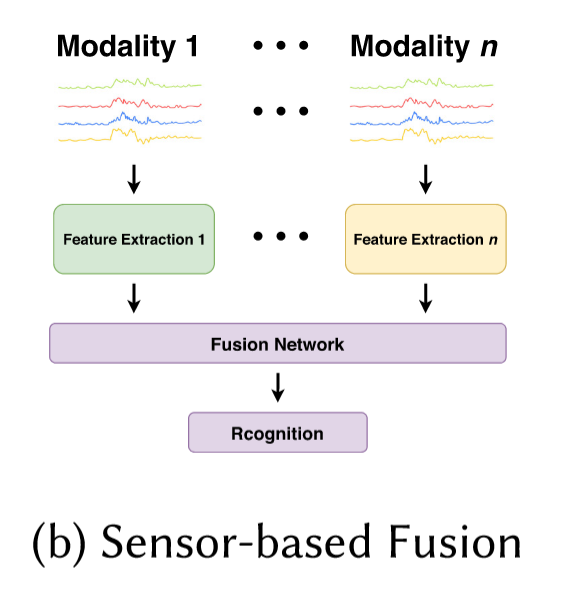
这种方法就是对不同的模态先去抽特征,然后再把特征进行融合。有一种方法是做一个confidence calculation net,让该net对不同modal的特征给出一个权重,然后进行加权求和。
a.3) axis-based fusion
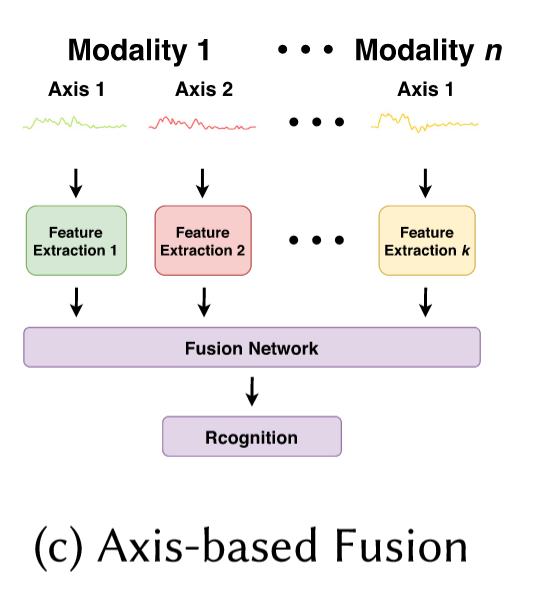
这种方法大意就是:对传感器收集的不同的数据(x、y、z等)都做一个网络去抽,抽完再去fuse。所以我们可以注意到上图种有n个modal,但是特征抽取器有k个。
a.4) shared-filter fusion
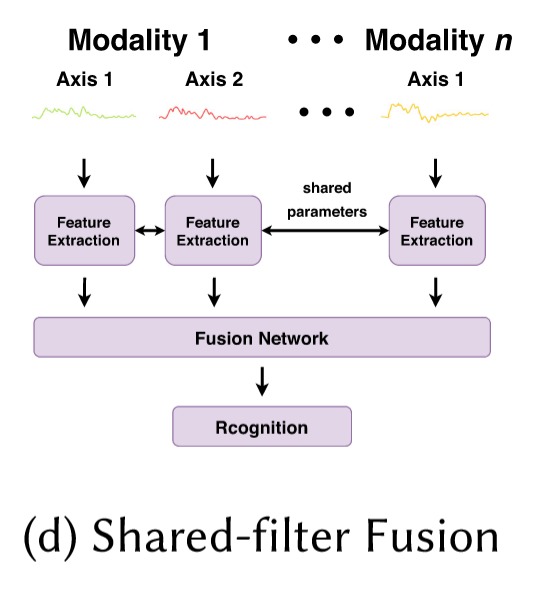
所谓shared-fliter,指的是对所有的axis都用同样的抽取器。你说这好吗?好不好我不知道,但是肯定快一点。
b)classifier ensemble
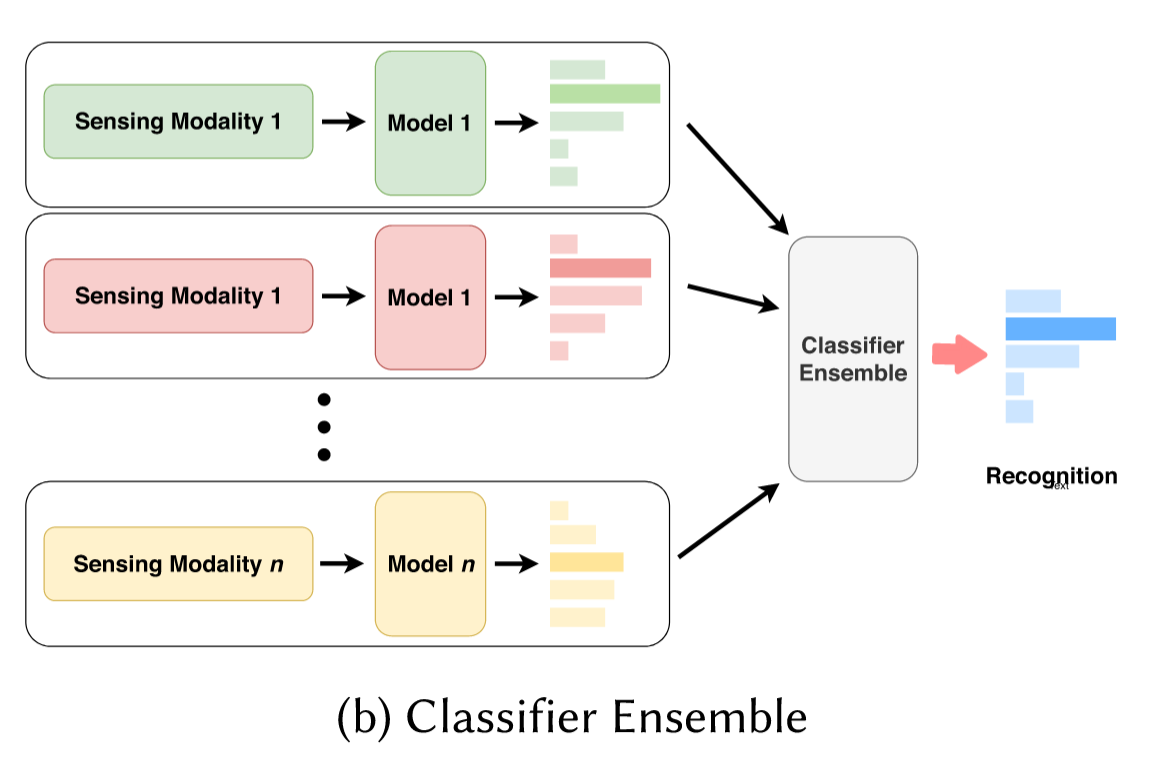
在不同模态进行特征抽取,之后在不同模态进行classify。对各个模态的分类结果进行ensemble。
有一种和前面a.2的confidence calculation类似的方法,即给每个分类器的结果分配一个权重。
这种方法相较于feature fusion,显然,更加具备延展性:当modal数量发生变化后,我们只需要修改分配给每个分类结果的权重即可。
当然,相较于feature fuison,这种方法在特征抽取方面要更加粗糙。
3.2 annotation scarcity
标注稀缺。就是说有标记的数据太少了,那咋办?解决方法有无监督学习和半监督学习。
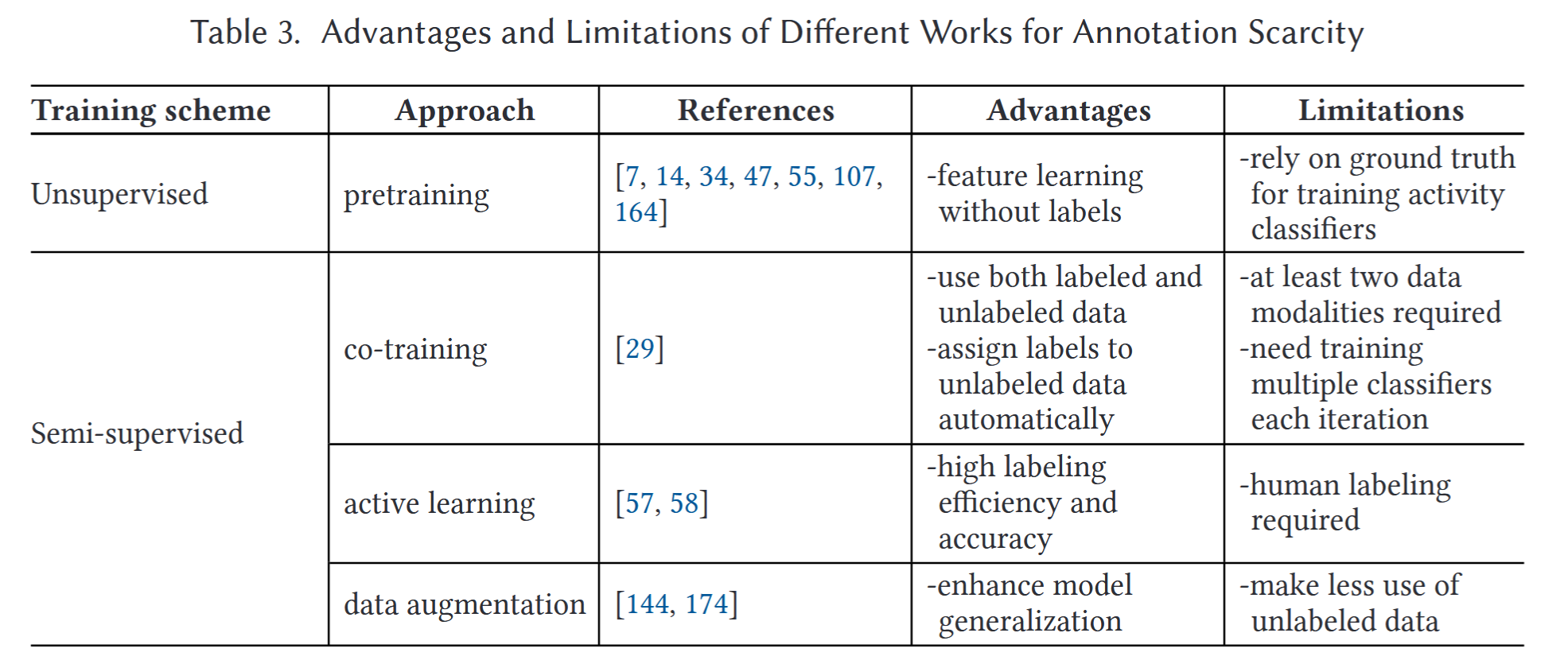
3.2.1 Unsupervised Learning无监督学习
一些深度生成式网络如Deep Belief Net,auto-encoder。
在DBN结构中,先用大量的无标签数据训练DBN的特征提取能力;再在DBN后接上一个分类器,用少量的有标签数据对整个模型架构进行微调。(虽然文中把这个方法列在无监督里,但是我觉得这个方法整体来说还是算半监督)
3.2.2 semi-supervised Learning半监督学习
半监督就是说无标签数据和有标签数据一起进行训练。

Co-training是一种半监督学习。在co-training中有一个view的概念,可以将其先简单理解成modality。co-training的方法大致可以描述为:用不同的模态内的少量有标签数据训练一个分类器。用该分类器对对应模态数据进行分类。把分类置信度较高的一些预测标签再投入到分类器训练中,以增加标签的方式实现数据增强。
当然,这里有一个概念是多数投票。由于WHAR数据是在同一时间对同一目标的多个模态进行采集的,所以同一时间段的数据所对应的标签是相同的(人只能有一个动作)。故,在对一段数据进行分类时,我们采用多个模态分类器投票的方式进行预测标签的确定。
但是,这种方法的错误点也显而易见:分类器可能给出错误的预测标签。这样的话就一步错步步错了。
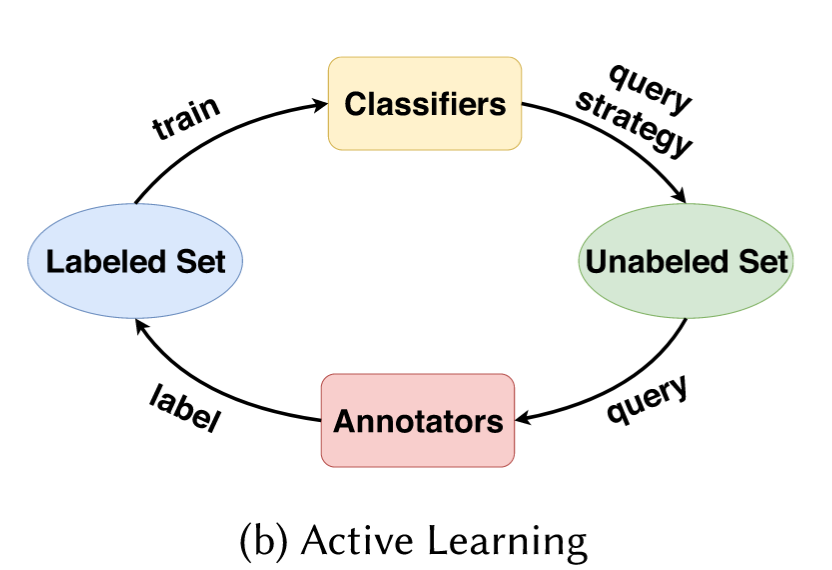
Active Learning也是一种半监督学习。简单来说,就是用一个小的有标签数据集训练一个分类器,让分类器去看一遍无标签的数据集(或者其中的一部分),找到一个对训练最有用的样本(最有用可以是高交叉熵、最不确定等度量方法)。把样本丢给人去标记,再投入数据集参与训练。
但是这种方法再WHAR里怎么实现呢?什么人可以对着一堆传感器数据看出来是什么运动啊?
Data augmentation通过合成数据进行数据增强意味着从少量真实数据中生成大量虚假数据,用虚假数据促进模型的训练。
这个豪哥的LRMDM就是这种方法。
3.3 class imbalance
这就是说,不同数据的获取概率自然的就是不一样的。而数据集的大小很大程度上影响了后续任务的效果。可以看出这个问题好像没什么解法,文章中这里的篇幅一页纸都不到。
Data level首先就从数据集角度上做一点平衡。要么把大的数据减少一点,要么用DA的方法把小数据集变大一点。这两种方法来说,后者比较好。
Algorithmic Level就是改进算法框架。比如说用F1-score而不是交叉熵来衡量损失。这是合理的,因为F1-score表示的是一种比例,管你数据集大小怎么样,比例的scale都是一样的。
3.4 distribution discrepancy
数据分布差异。很多的sota会把训练数据和测试数据当成独立同分布来看。但是这是有问题的。数据分布差异的原因可以分为:用户不同,时间不同,传感器状态不同。还有一种分类是同质差异和异质差异的区分。这种区分主要是看特征的维度是否有不同,若改变传感器导致特征空间维度发生变化,那就是异质的差异。
Transfer Learning迁移学习是一种解决数据分布差异的 方法,它的主要思想是:当从一个预定义的setting转移到其他setting中时,模型的分类能力还是可以有较好的表现。
3.4.1 User discrepancy
就是说,在测试集上可能会遇到训练集从来没有出现过的用户,这样的话其数据如何进行预测?
迁移学习方法:先用源域的数据进行训练,到测试阶段后用目标域的数据对模型的最后几层进行微调。这叫finetune。
GAN方法:用源域数据生成目标域数据进行DA。
3.4.2 Time discrepancy
没看
3.4.3 Sensor discrepancy
没看
3.5 composite activity
活动识别的目标很多是低语义的动作,走路、站立、跑步之类的。而高语义的一些活动往往是多个低语义活动的组合。高语义活动如工作、吃饭、煮咖啡等,这些高语义的标签含有更多的信息,可以更好的反应人的生活。但是,这样的高语义活动识别可能在只有传感器数据的情况下是不够的,还需要周围环境和上下文信息。所以没人做这个哈哈。
3.6 data segmentation
原始sensor信号是一种连续的流信号。直接滑动窗口切分太暴力。可能把多条运动切到一起也可能把一条运动切开。接下来给出分段的两种分类:
显式分割
a)层级缩小 hierarchical narrow-down
从一个大窗口逐步缩小到小窗口。缩小标准是两个连续的窗口具有不同的标签,或者分类置信度小于阈值。
b)时间步维度上的分类 timestep wise
这里的timestep指的是sensor数据流中的一个点。例如采样频率为Hz,则一个timestep就是在该0.02s中传感器返回的数据。
这种方法就是对每一个时间步骤预测一个label。可想而知这样的分类很细致,但是数据量太大。
隐式分割
Varamin这哥们搞了一个multi-label-architecture,可以直接predict正在进行的活动数量和每个活动的对应概率。
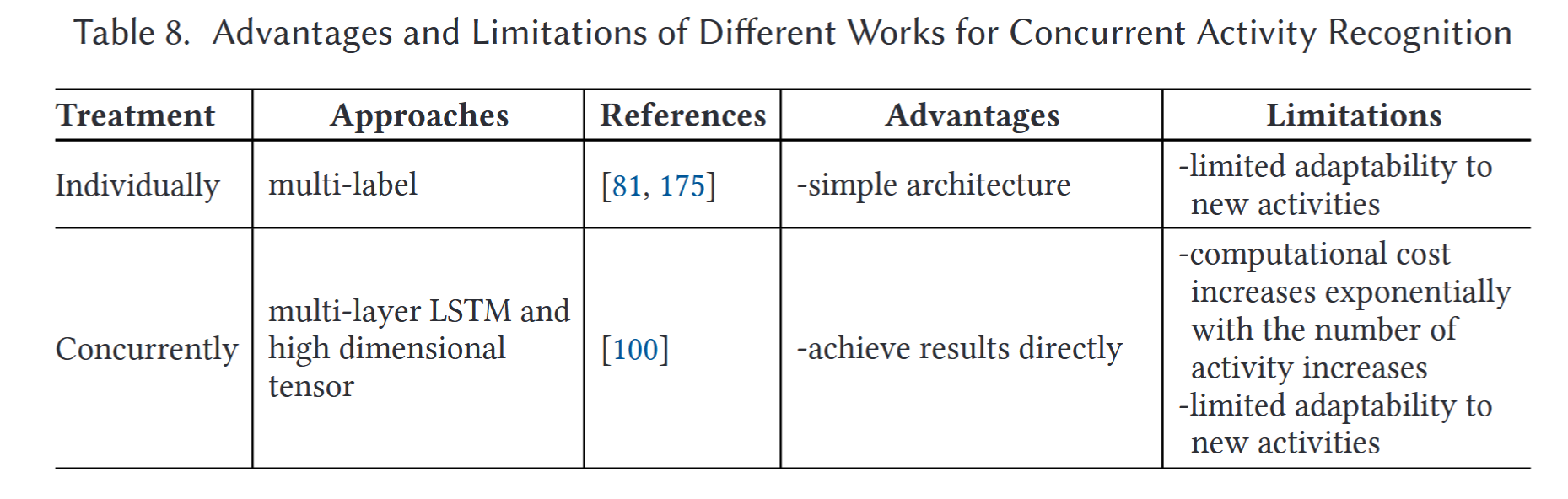
3.7 concurrent activity
concurrent activity就是说会有一些活动是同时发生的。但是文中对这部分的讲解非常少。给出两种方法:1)对所有活动都打标签,都识别一下。2)把所有的活动排列组合一下当作标签。(这么蠢的方法也能发??)
3.8 multi-occupant activity
多人运动。
有两种多人运动:自己管自己;两个人一起玩。这两种运动方式都需要有环境传感器(ambient sensor)来丰富语义信息。
3.9 computation cost
层数太多会算的很慢。
3.10 privacy
说是简单用cnn抽取的特征就能有将近90%的正确率在用户识别任务上。man!
3.11 interpretability
可解释性。
就是说,在多模态的数据流中,对于某个运动的检测任务,可能有一些模态的数据是没多大用的,而某一些数据是起到决定性作用的。
有团队使用可视化的方法将模型的输入展示出来。 Understanding and Improving Deep Neural Network for Activity Recognition
为了突出某部分数据对结果的影响力,有个很好的东西叫attention。
soft attention
In machine learning, “soft” means differentiable.这一段写的蛮清楚的就直接截图了。

用滑动窗口滑出来的数据块长得就像词向量一样,再用attention确定哪块是更加重要的。
hard attention
soft是分0到1的权重,hard就直接分0和1了所以这玩意是不可微的。然后文中讲的我就有点看不懂了。
文中说,hard attention输出的是一种随机的选择,是没有ground truth的。所以做不了loss。
但是,用结合强化学习的思路就可以让模型在选择策略的空间中进行梯度的反向传播。
Future Directions
好的,让我 康康有啥可以研究的。
文中说,chapt. 3里说的11个难点都可以研究。此外,还给出了一下一些问题:
- 无监督方法。无监督方法在抽特征方面用的多,但是不太能在标签预测上用,能不能想个办法用一下?
- 新活动的识别。这就是说的zeroshot吗?
- 未来运动预测。可以对一些时序相关性强的运动进行预测。
- 对sota的规范化。这应该就不是我可以做的工作了哈哈。