近日,全球计算机视觉和模式识别领域的顶级会议CVPR (Conference on Computer Vision and Pattern Recognition)公布论文接收结果:网易伏羲人工智能实验室凭借其在前馈捏脸等领域的创新研究,成功入选3篇论文。

CVPR 是计算机视觉和模式识别领域最顶级的学术会议之一,至今已有40余年历史。在 Google Scholar 的学术会议 / 杂志排名中,CVPR 名列总榜第二,仅次于Nature。今年,共有 13008 份有效投稿并进入评审流程,其中 2878 篇被录用,最终录用率为22.1%。
以下为网易伏羲人工智能实验室此次入选的三篇论文概要:
《EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting 》
一种前馈式的通用捏脸框架
关键词:智能捏脸,多模态输入
涉及领域:Automatic Character Creation, Multimodal
论文链接:https://arxiv.org/pdf/2503.01158
捏脸是角色扮演游戏、虚拟现实等应用中基础且重要的任务。传统捏脸过程需要用户花费大量时间调整参数以创建理想的虚拟形象,如今,最新的AIGC技术已经能够从图像或者文本中自动化的获取捏脸参数。然而,现有的捏脸自动化方法仍存在以下问题:
风格一致性差:现有方法依赖于特定图像域,难以适配不同游戏引擎的风格(如写实、动漫、卡通等)。
输入多样性不足:面对多样化的输入(如真实照片、动漫图片、文本描述),现有方法表现不稳定。
效率低下:现有方法依赖迭代优化,生成速度慢,难以满足实时需求。
为了解决这些问题,网易伏羲人工智能实验室提出EasyCraft,一个创新的端到端框架,旨在通过统一的翻译器(Translator)实现基于图像和文本的自动捏脸。EasyCraft的核心是一个能够将任意风格的图像转换为游戏引擎捏脸参数的翻译器,支持多种输入类型,显著提升了捏脸的灵活性和准确性。

基于文字和图像的捏脸效果图
相比于已有的技术方案,EasyCraft 在以下几个方面展现了技术创新:
- 通用翻译器:摆脱了已有方法对神经渲染器的依赖,引入参数翻译器,能够将游戏风格的图像转为捏脸参数,从而实现前馈的端到端的捏脸。
- 多风格图像支持:通过自监督学习,网易伏羲人工智能实验室训练了一个通用的视觉Transformer(ViT)编码器,能够从不同风格的图像中提取统一的面部特征。这使得翻译器能够处理任意风格的输入图像,而不仅限于游戏引擎的特定风格。
- 游戏引擎适配:翻译器的训练仅依赖于游戏引擎生成的参数-图像对,无需额外的监督信号。通过将统一的面部特征映射到特定引擎的捏脸参数,EasyCraft能够轻松适配不同的游戏引擎。
- 文本驱动捏脸:结合Stable Diffusion(SD)模型,EasyCraft支持基于文本描述的捏脸。网易伏羲人工智能实验室通过微调SD模型,使其生成符合游戏引擎风格的图像,再通过翻译器转换为捏脸参数,实现了更精准的文本驱动捏脸。
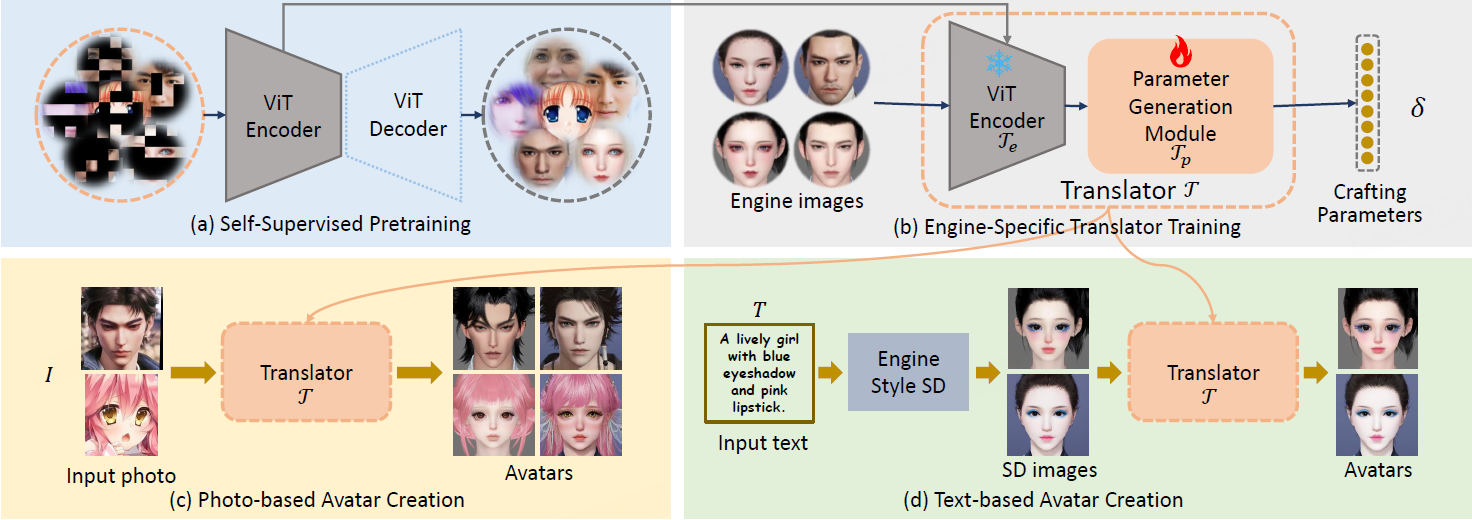
方法总图(a):视觉Transformer(ViT)编码器预训练 (b): 翻译器训练(c):图像驱动捏脸 (d):文字驱动捏脸
网易伏羲人工智能实验室在两款RPG游戏(永劫无间手游《Justice Mobile》和逆水寒手游《Naraka: Bladepoint Mobile》)上进行了大量实验,验证了EasyCraft的有效性:
- 图像输入:EasyCraft在处理不同风格的输入图像时,生成的捏脸结果在身份相似性和视觉质量上均优于现有方法。
- 文本输入:与现有文本驱动捏脸方法相比,EasyCraft生成的捏脸结果在多样性和语义一致性上表现更优。
- 用户研究:用户对EasyCraft生成的结果给予了更高的评分,认为其在逼真度和一致性上显著优于其他方法。

图像驱动捏脸与已有方法对比结果

文字驱动捏脸与已有方法对比结果
经过大量实验证明,网易伏羲人工智能实验室证实了其提出的EasyCraft捏脸框架具备以下优势:
- 通用性强:支持任意风格的图像输入,适配多种游戏引擎。
- 高效精准:通过端到端的框架,实现了快速且精准的捏脸生成。
- 灵活扩展:翻译器的训练仅依赖于游戏引擎数据,易于扩展到其他捏脸系统。
综上所述,EasyCraft为游戏捏脸系统提供了一种全新的自动化解决方案,并在线上AB测试中相比旧方案采纳率提升3倍。EasyCraft的推出,不仅提升了捏脸系统的自动化水平,也为玩家提供了更便捷、个性化的角色创建体验。网易伏羲人工智能实验室的这一技术为网易乃至整个游戏行业带来了更多创新可能。未来网易伏羲人工智能实验室将进一步优化模型,提升其在复杂场景下的表现,同时,积极探索更多潜在的应用场景,如虚拟偶像、元宇宙角色创建等,力求将这项技术应用于更广泛的领域,带来更多的价值和可能性。
《Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment》
通过声音引导的视觉聚合实现更鲁棒的视听分割
关键词:视听分割,视听对齐
涉及领域:Audio Visual Segmentation, Audio Visual learning
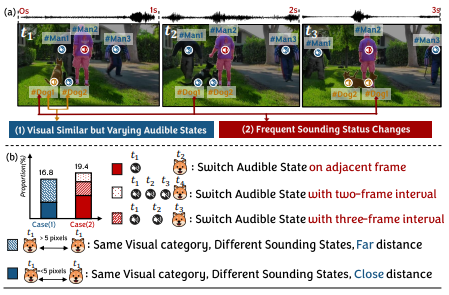
歧义性视听关联样本示意图
视听分割作为多模态学习任务的一环近年来广受关注。先前的工作大多强调从时空角度加强视听关联,而忽视了视听数据的独有特性带来的挑战。本研究重点关注带有歧义性的视听关联样本,即空间上属于同一视觉类别不同发声状态的物体与时序上物体发声状态频繁切换,引起的视听定位错误的问题。为此,本文提出了一个声音引导的模态对齐模块,将视听交互范围限制在语义密度相似的视觉区域,逐步对发声区域进行合并,以此来逐步加强真正发声区域与声音的关联。此外,我们在时序上引入不确定性评估模块,在时序上对物体发声的不确定性进行评估,缓解物体发声状态突变造成的过度分割问题。

声音引导的渐进式模态对齐方法

定位结果示意图
实验结果表明,本文研究方法在处理发声状态频繁切换及视觉类别相似但发声状态不同的复杂样本时,能够显著提高视听定位的准确性。这种方法不仅增强了模型对复杂视听场景的理解能力,同时也为未来相关领域的研究提供了新的视角和解决方案。
《Dynamic Derivation and Elimination: Audio Visual Segmentation with Enhanced Audio Semantics》
动态衍生和擦除:带有增强语义的视听分割
关键词:视听分割,视听对齐
涉及领域:Audio Visual Segmentation, Audio Visual learning
近年来,建立有效的视听关联已经成为多模态学习领域的重要目标之一。为了实现更强的视听关联,之前的方法主要集中在设计更先进的视听关联架构上,而忽视了声音特性所带来的视听关联挑战。本研究探索了声音的可加性及同一物体发声多样性导致的视听关联问题。
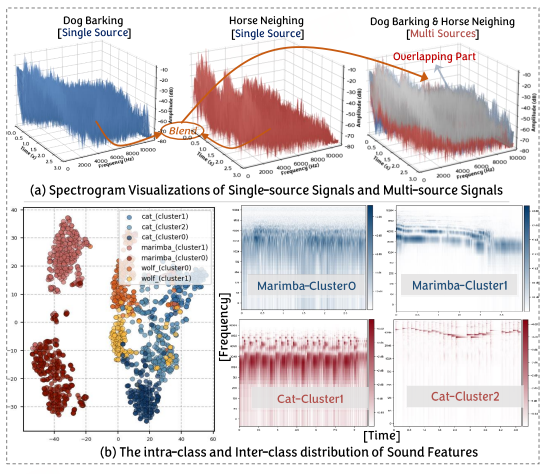
示意图:声音可加性和较大的类内差异带来的视听匹配困难
为了解决声音可加性对声音语义表达的削弱,本文提出了一种声音语义动态衍生方法,通过补充多声源数据的语义信息来增强单声源的语义表达。此外,我们通过学习细粒度的类内鉴别性语义,解决了声音类别内部差异较大所带来的视听关联困难。最后,我们提出了一种视觉语义引导的视觉无关声音语义擦除方法,旨在减少噪声和画外音对视听关联构建的干扰。
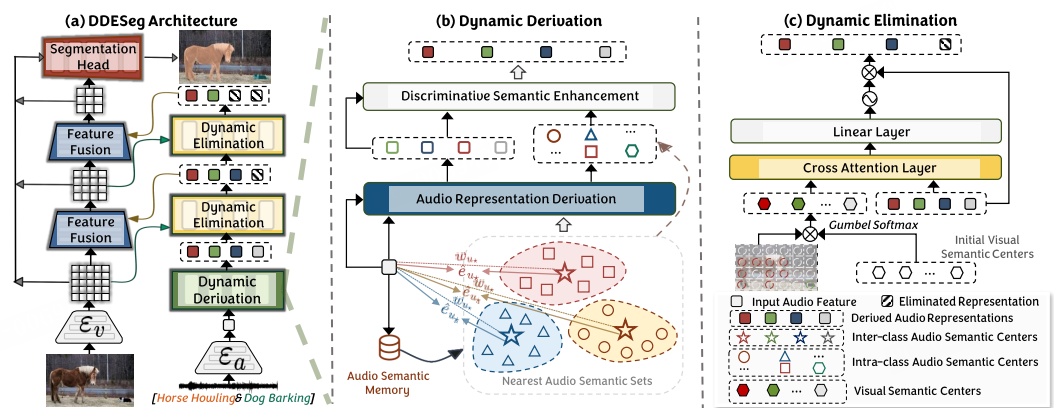
方法示意图

分割结果示意图
实验结果表明,我们的方法在视听分割数据集上展现出了显著的性能提升,证明了其在处理复杂音频-视觉关联任务方面的有效性。这一进展不仅推进了视听分割技术的发展,也为未来多模态学习的研究提供了新的视角和方法。
此次网易伏羲人工智能实验室多项研究成果入选CVPR 2025,不仅彰显了其在国际学术界的影响力与创新能力,也体现了通过尖端技术推动行业进步的坚定决心。作为科研和孵化的基石,网易伏羲人工智能实验室致力于前沿技术的研发;而网易伏羲则在此基础上,进一步推进这些技术的产品化和商业化探索。展望未来,网易伏羲将持续秉持开放合作的精神,深化AI技术及其应用的研究,促进人机协作的广泛应用,助力各行各业实现数字化转型,并共同探索人工智能带来的无限可能。