原文:一种基于错误的寻找重心方法的点分治的复杂度分析
LCA 还是太神了,研究半天才看明白。
所以这里提供一种说人话版本。
为什么法一是错的?
原文提出了这样一个 hack:
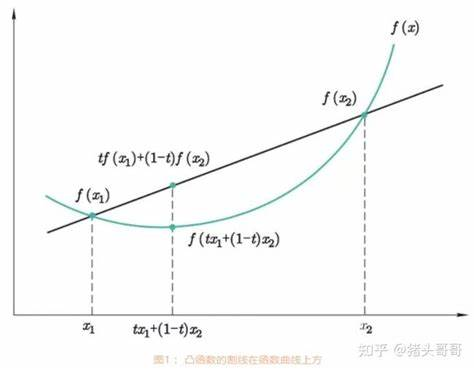
这是三个等长度的共端点的链,初始以红色箭头所指的点为根。
进行第一次分治:
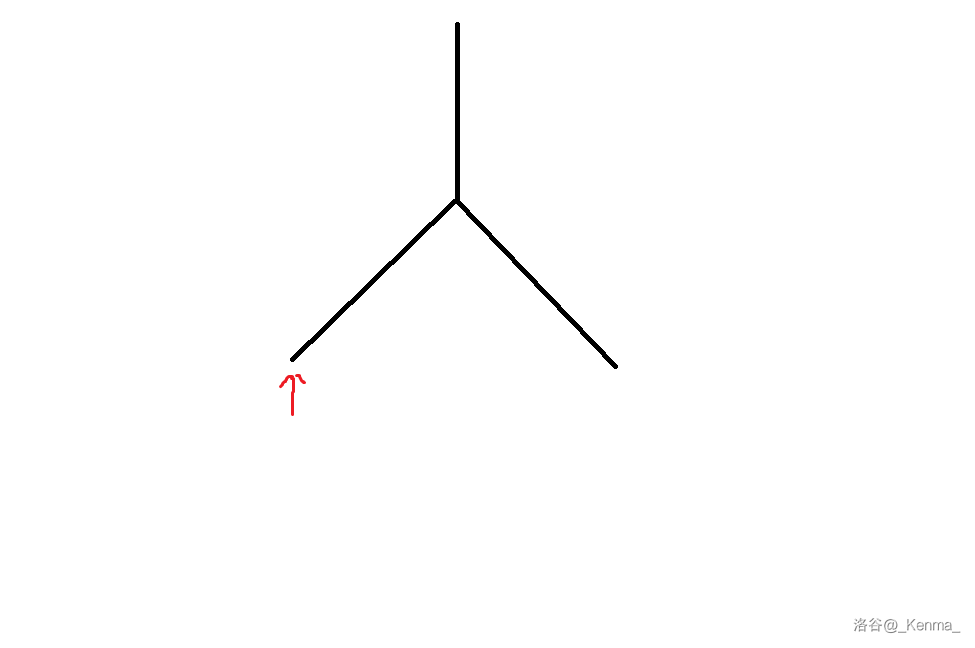
红色箭头所指的点是重心。
此时注意,初始根所在的链,也就是标红的链,我们寻找重心传入的点的总数是 \(\frac{2n}{3}\),也就是说,在进行下一次分治时,这条链上的点都符合条件。
进行第二次分治:

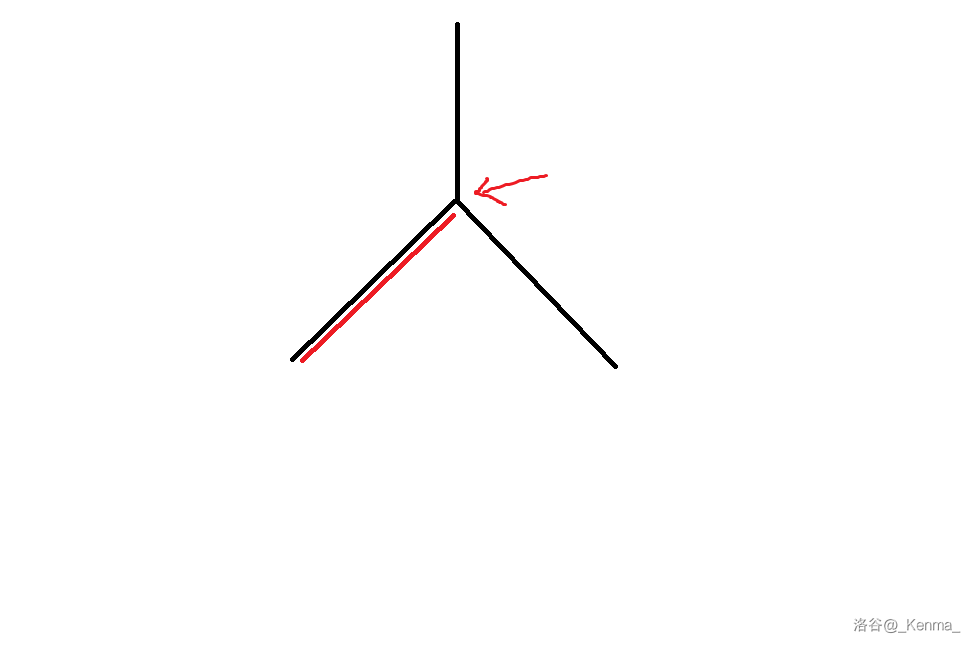
根据我们 dfs 的过程,虽然这条链上的点都符合条件,我们还是选择了深度最深的点作为重心,也就是红色箭头所指的点。
此时注意,我们下一次分治,传入的点的总数是这个点上方的点,也就是蓝色箭头所指的点,它的子树大小,也就是 \(2\)。
此时我们找不到合法的重心。
为什么法二是对的?
首先考虑,法二求重心时,只考虑连通块内点的相对子树大小关系,也就是无论如何一定能找到一个点,并认为这个点是重心。
所以这种做法一定有正确性,所以我们现在只需要考虑复杂度问题。
为了方便研究,我们来考虑一种情况:
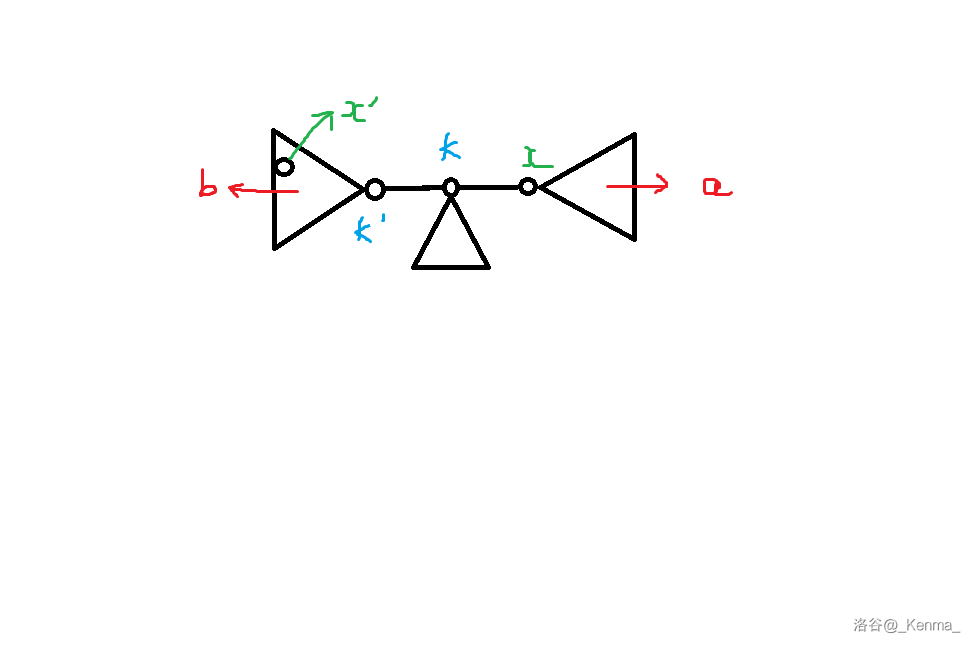
注意这里的变量名和原文有所不同。
其中,\(x\) 是上一层分治的选择的重心,\(x'\) 是上一次分治的根,\(k\) 是以 \(x\) 为根时,\(x'\) 所在的子树的根,\(k'\) 是以 \(k\) 为根时,\(x'\) 所在子树的根,\(a,b\) 分别是 \(x,k'\) 子树大小。
其实不需要对着定义抠字眼,直接看图就很明显。如果还是不明白,考虑分治重心的变化为:\(x' \to x \to k\) 子树内的点。
现在考虑的过程,是做完 \(x\),递归 \(k\) 子树(\(k\) 子树包括 \(k'\) 子树),寻找新的重心的过程。
考虑传入 \(k\) 子树的点数。
实际上,点数应当为:以 \(x\) 为根时,\(k\) 的子树大小,也就是 \(n-a\)。但是我们用的是:以 \(x'\) 为根时,\(k\) 的子树大小,也就是 \(n-b\)。
我们考虑这个过程会进行很多层,对于每一层都会得到对应的 \(a,b\),形成 \(a,b\) 序列。
记第 \(i\) 层递归时,正确的点数为 \(N_i\),则有:
注意原文中下标写混了,硬控我半小时。
关于序列 \(a,b\),我们有:
- \(b_i \le a_i\)
考虑使用归纳法证明。
-
\(i=1\) 时,\(a_i=b_i\);
-
下证 \(b_{i-1}\le a_{i-1}\) 时,\(b_i \le a_i\)。
因为 \(b_{i-1} \le a_{i-1}\),所以 \(N_{i-1} \le N‘_{i-1}\)。
考虑反证法,假设 \(b_i>a_i\)。
又因为 \(N_{i-1} \le N'_{i-1}\),所以对于 \(x\) 来说,它计算出的最大子树,一定是 \(k\) 子树,所以 \(x\) 最大子树的大小一定 \(\ge b_i\)。
进一步考虑,因为 \(b_i>a_i\),所以以 \(k\) 为根的最大子树一定严格小于以 \(x\) 为根的最大子树,也就是 \(k\) 而不是 \(x\) 应该是重心,这与条件矛盾,故假设不成立,原命题成立。
考虑感性理解,看图,如果 \(b_i>a_i\),那么 \(k\) 感觉上就比 \(x\) 更适合做重心。
- \(2a_i \ge N_i\)
属于上一个结论的引申。仿照上例,假设 \(a_i < N_i-a_i\),那么 \(a_i < N'_i-a_i\),那么 \(x\) 的最大子树又变成了 \(k\) 子树,而根据上面的证明,\(x\) 的最大子树为 \(k\) 时,会出现矛盾。
因此,假设不成立,原命题成立。
结合上面两个结论,得到:\(2N_i \le N_{i-1}\),也就是说每次递归,\(N\) 的大小至少减半,因此递归总层数为 \(O(\log n)\),每层递归访问了 \(O(n)\) 个节点,总复杂度仍然为 \(O(n \log n)\)。
但是听说这样写点分树,树高会出问题,不明白为什么。