有限差分法——拉普拉斯第4部分
提出了拉普拉斯算子有限差分法的HIP实现,并应用了四种不同的优化。在这些代码修改过程中,观察到由于全局内存的总取数减少,性能得到了逐步提高。然后,应用了进一步的优化,以在512×512×512上达到预期的性能目标MI250X GPU的单个GCD上的512个点网格。下面显示的是最终的HIP内核,称之为内核5:
//平铺因子
#define m 8
// 发布边界
#define LB 256
template <typename T>
__launch_bounds__(LB)
__global__ void laplacian_kernel(T * f, const T * u, int nx, int ny, int nz, T invhx2, T invhy2, T invhz2, T invhxyz2) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
int j = m*(threadIdx.y + blockIdx.y * blockDim.y);
int k = threadIdx.z + blockIdx.z * blockDim.z;
// 如果此线程位于xz边界上,则退出
if (i == 0 || i >= nx - 1 ||
k == 0 || k >= nz - 1)
return;
const int slice = nx * ny;
size_t pos = i + nx * j + slice * k;
// 每条线在y方向上累积m个模板
T Lu[m] = {0};
// 可重用数据的标量
T center;
// z - 1, 循环平铺
for (int n = 0; n < m; n++)
Lu[n] += u[pos - slice + n*nx] * invhz2;
// y - 1
Lu[0] += j > 0 ? u[pos - 1*nx] * invhy2: 0; // bound check
// x 方向, 循环平铺
for (int n = 0; n < m; n++) {
// x - 1
Lu[n] += u[pos - 1 + n*nx] * invhx2;
// x
center = u[pos + n*nx]; // 储存以供再次使用
Lu[n] += center * invhxyz2;
// x + 1
Lu[n] += u[pos + 1 + n*nx] * invhx2;
//重用:y+1用于前一个n
if (n > 0) Lu[n-1] += center * invhy2;
// 重用:y-1用于下一个n
if (n < m - 1) Lu[n+1] += center * invhy2;
}
// y + 1
Lu[m-1] += j < ny - m ? u[pos + m*nx] * invhy2: 0; // 边界检验
// z + 1, 循环平铺
for (int n = 0; n < m; n++)
Lu[n] += u[pos + slice + n*nx] * invhz2;
// 仅当线程在y边界内时存储
for (int n = 0; n < m; n++)
if (n + j > 0 && n + j < ny - 1)
__builtin_nontemporal_store(Lu[n],&f[pos + n*nx]);
}
}
第4部分的目的是探索此代码在各种AMD GPU和问题大小上的性能。作为本次调查的一部分,将总结拉普拉斯级数,从经验中吸取教训,并提供用户可以应用于类似问题的可能代码优化。的其余部分概述如下:
1)在多个AMD GPU上跨各种问题大小运行Kernel 5
2)检查二级缓存命中性能,并确定其降级背后的根本原因
3)提出规避二级缓存大小限制的技术
4)查看此拉普拉斯级数中进行的所有代码优化。
4.4.1 跨不同硬件和尺寸的性能
除了MI250X GPU,还考虑了以下AMD GPU:
1)RX 6900 XT
2)RX 7900 XTX
3)MI50
4)MI100
5)MI210
6)MI250
将从上述所有GPU上的问题大小nx,ny,nz=256256256开始,对Kernel 5进行缩放研究。每个维度都以256的倍数增加,直到达到全局问题大小nx,ny,nz=1024,1024。回想一下,品质因数(FOM)被定义为有效内存带宽:
theoretical_fetch_size = ((nx * ny * nz - 8 - 4 * (nx - 2) - 4 * (ny - 2) - 4 * (nz - 2) ) * sizeof(double);
theoretical_write_size = ((nx - 2) * (ny - 2) * (nz - 2)) * sizeof(double);
effective_memory_bandwidth = (theoretical_fetch_size + theoretical_write_size) / average_kernel_execution_time;
考虑到需要在整个内存子系统中移动的数据量最少,这是数据传输的平均速率。这里的目标是获得尽可能接近可实现设备HBM带宽的FOM。通过之前在各种线程块大小、启动边界和平铺因子上重新运行Kernel 5的实验,发现以下参数为512× 512× 512上的每个单独GPU提供了最高的FOM点网格,见表4-15。
表4-15 每个单独GPU提供了最高的FOM点网格
|
GPU |
线程块 |
发布边界 |
平铺因子 |
|
RX 6900 XT |
256 x 1 x 1 |
256 |
16 |
|
RX 7900 XTX |
256 x 1 x 1 |
256 |
8 |
|
MI50 |
256 x 1 x 1 |
256 |
4 |
|
MI100 |
128 x 1 x 1 |
128 |
4 |
|
MI210 |
256 x 1 x 1 |
256 |
8 |
|
MI250 |
256 x 1 x 1 |
256 |
8 |
|
MI250X |
256 x 1 x 1 |
256 |
8 |
从现在开始,MI250和MI250X GPU上的实验应在单个GCD上进行。描述了各种AMD GPU和问题大小的FOM,如图4-8所示。
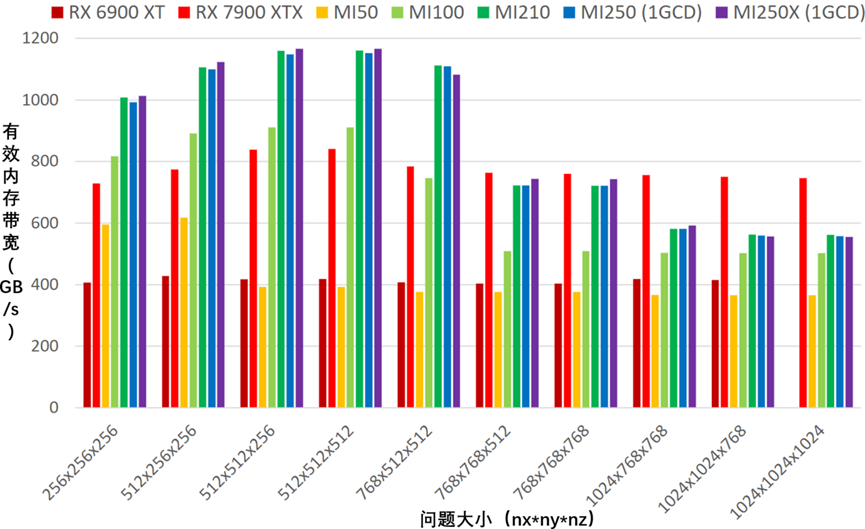
图4-8 内核5在各种AMD GPU和问题大小上的性能
RX 6900 XT GPU没有足够的内存来执行最大的示例nx,ny,nz=10241924,1024,因此,图4-8中没有显示。RX 6900 XT和RX 7900 XTX GPU上所有尺寸的性能似乎相对一致,而当问题尺寸超过一定阈值时,所有Instinct™GPU的性能都会下降。在接下来的部分中,将研究Instinct™GPU性能下降的原因。
4.4.2 性能下降的根本原因
把注意力重新集中在MI250X GPU上。为了了解性能下降的原因,需要收集rocprof统计数据。将首先收集FETCH_SIZE,并将其与nx、ny、nz的每个组合的theological_FETCH_SIZE进行比较。理想情况下,FETCH_SZIE应等于理论量,因为每个线程加载的元素可以被相邻线程重用多达六次。MI100、MI210、MI250和MI250X GPU都有8MB的L2缓存,每个GCD在计算单元(CU)之间共享,因此,收集L2CacheHit将有助于确定缓存数据的重用程度。说明了在相同问题规模范围内的发现,如图4-9所示。
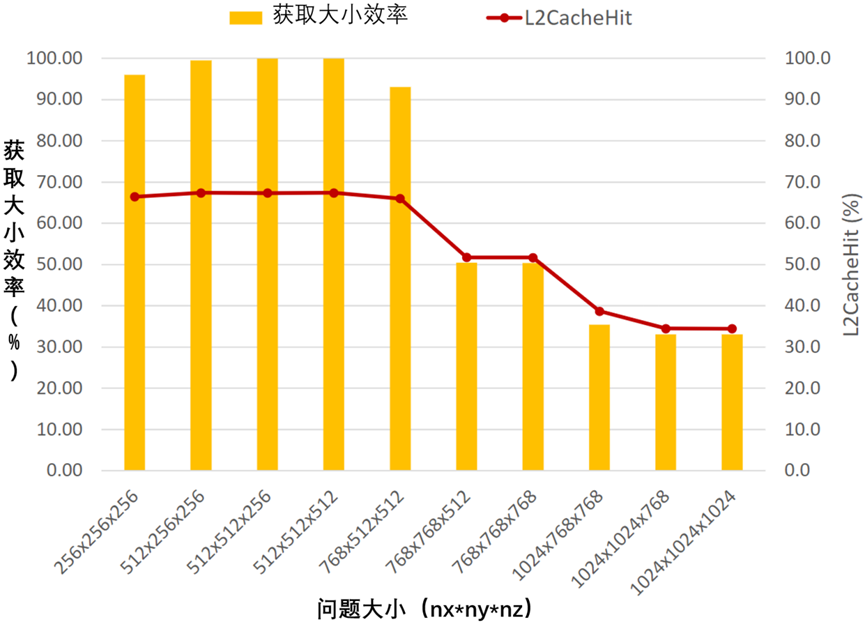
图4-9 在单个MI250X GCD上跨各种问题大小获取内核5的效率和L2缓存命中率
FOM、获取效率和L2缓存命中率之间存在明显的相关性。基线HIP内核表现出50%的获取效率,同时保持了65%的相对较高的L2缓存命中率。相信内核设计存在问题。在最后一个实验中,提取效率和二级缓存命中率都保持在33%左右,表明性能的限制因素是二级缓存的大小。
图4-9中另一个有趣的观察结果是,只有当nx或ny增加时,性能才会下降——nz的增加对性能几乎没有影响。从上面Kernel 5中的线程块配置和网格索引可以看出,在从下一个xy平面获取元素之前,将从全局内存中获取单个xy平面的所有元素。每个线程的模板计算具有-nx*ny、0和nx*ny的z方向步长,因此需要三个xy数据平面。如果三个xy平面太大,无法同时容纳在L2缓存中,那么每个线程都会循环缓存以从全局内存中获取额外的xy平面——例如,当只有一个xy平面适合(或部分适合)L2缓存时,线程需要从全局内存循环通过两个额外的xy面,因此获取效率降至33%。
进行第二个实验来进一步说明这一点。将检查nx和ny的各种值,以在性能开始下降之前确定最佳的z方向步幅。从约1 MB的起始z步长(相当于nx,
ny=512256)开始,nx固定为三个不同的大小,递增地增加ny,直到xy平面超过8 MB(nx*ny*sizeof(double))。如图4-10所示。
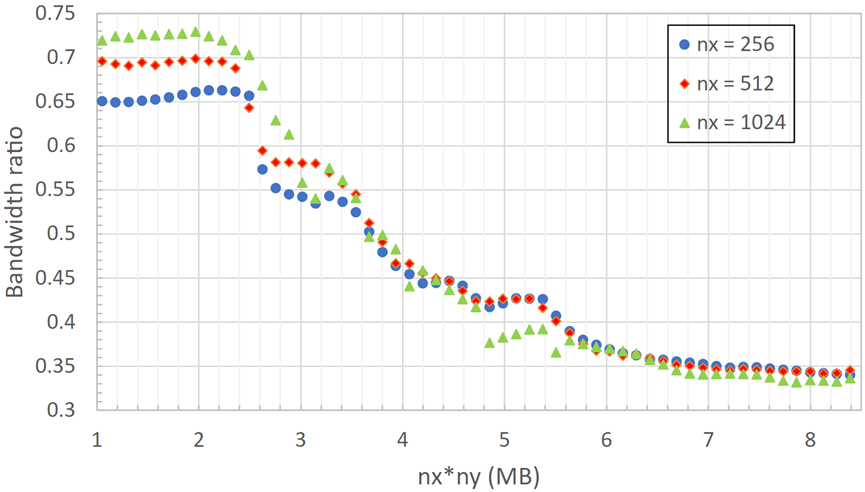
图4-10 单个MI250X GCD上不同固定nx值的nx*ny步幅增加对性能的影响
无论nx的大小如何,当单个xy平面在内存中超过约2.5 MB时,性能都会下降。事实证明,2.5 MB足够小,可以在8 MB的L2缓存中容纳三个连续的xy平面,这解释了为什么FOM的值更高。然而,步幅越大,缓存中的元素就越多,从而降低了L2CacheHit率,进而降低了FOM。nx*ny超过8 MB后性能水平下降,因为此时只有一个平面适合(或部分适合)缓存——这就是FETCH_SIZE比理论估计值大三倍的地方。
4.4.3关于Radeon™GPU性能的说明
RX 6900 XT和RX 7900 XTX GPU似乎都没有受到图1所示缩放研究的影响。与Instinct™GPU不同,L2缓存是所有CU共享的最后一个缓存,也称为最后一级缓存(LLC),Radeon™GPU具有额外的共享缓存级别:L3缓存也称为无限缓存。两个Radeon™GPU的L3缓存大小分别为128 MB和96 MB,这两个大小都足以容纳大小为nx,ny=10241024的多个xy平面。从这里开始,使用LLC来指代Radeon™GPU的L3缓存和Instinct™GPU的L2缓存。
快速进行一项新的缩放研究,以验证两个Radeon™GPU的LLC确实是更大尺寸性能的限制因素。为了确保不会用完内存,从nx,ny,nz=10241024,32开始,慢慢增加ny的值,如图4-11所示。
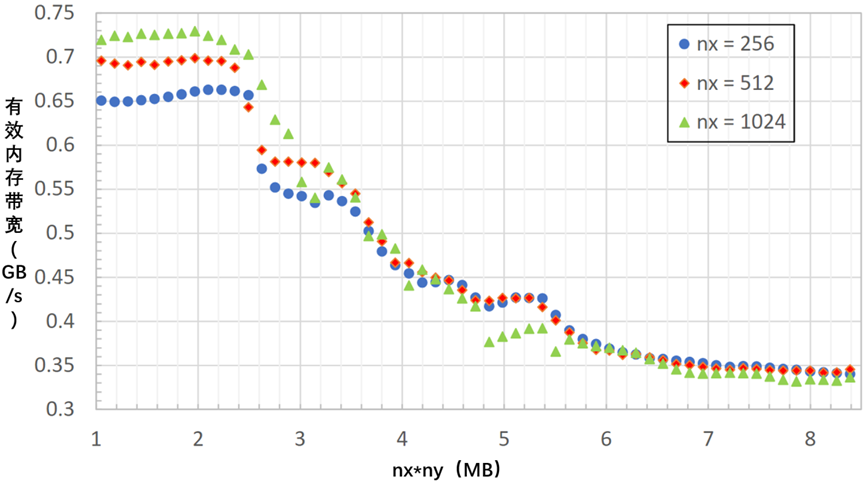
图4-11 RX 6900 XT和RX 7900 XTX GPU上nx*ny步幅增加对性能的影响
在图4-11中,当xy平面超过某些阈值时,有效存储器带宽仍然会恶化。当xy平面超过32MB时,RX 6900 XT性能会恶化,而当xy平面超出25MB时,RX 7900 XTX性能会恶化。RX 7900 XTX的LLC略小于RX 6900 XT,因此性能在较小的xy平面尺寸下开始下降。无论使用哪种AMD GPU,如果nx*ny太大,性能都会下降。
4.4.4解决缓存大小限制问题
如何解决这些较大问题的缓存大小问题呢?这在MI50等硬件上尤为重要,因为LLC只有4MB的L2缓存。即使nz很小,nx和ny的值很大,L2缓存也可能成为内存流量瓶颈。考虑在MI250X GCD上进行的接下来的几个实验中,nx,ny,nz=10241024102024的时间。以下是解决二级缓存瓶颈的两种可能策略:
|
|
FOM (GB/s) |
取数效率(%) |
L2 Cache命中率 |
|
内核5 – 基线 |
555.389 |
33.1 |
34.4 |
|
内核5 – 128x1x8 |
934.111 |
79.8 |
60.6 |
有一个显著的改进——FOM提高了68%,提取效率提高到近80%,L2缓存命中率提高到60%以上。修改线程块配置以包括z方向上的元素,使HIP内核能够显著提高其在这些较大问题规模上的性能。然而,提取效率仍有约20%的问题有待解决。
尝试的另一种修改是仍然使用原始的256×1×1,但配置HIP内核的网格启动和内核本身的索引。这需要在主机端和设备端修改代码。对于主机端,修改了网格启动配置:
1. 内核5(之前)
dim3 grid(
(nx - 1) / block.x + 1,
(ny - 1) / (block.y * m) + 1,
(nz - 1) / block.z + 1);
2. 内核6(之后)
dim3 grid(
(ny - 1) / (block.y * m) + 1,
(nz - 1) / block.z + 1,
(nx - 1) / block.x + 1);
第二个更改涉及在HIP内核内配置索引:
3. 内核5(之前)
int i = threadIdx.x + blockIdx.x * blockDim.x;
int j = m*(threadIdx.y + blockIdx.y * blockDim.y);
int k = threadIdx.z + blockIdx.z * blockDim.z;
4. 内核6(之后)
int i = threadIdx.x + blockIdx.z * blockDim.x;
int j = m*(threadIdx.y + blockIdx.x * blockDim.y);
int k = threadIdx.z + blockIdx.y * blockDim.z;
blockIdx.x和blockIdx.y索引分别在x和y方向上跨越pos,将大小为nx*ny的xy平面加载到缓存中。现在,它们分别在y和z方向上跨过pos,这将大小为
blockDim.x*ny的xy平面加载到缓存中。索引排序的洗牌使多个xy平面的较小部分能够填充L2缓存,从而增加了一些模板计算可以有效地重用其他线程块已经获取的所有数据的可能性。以下是性能数据,见表4-16。
表4-16 索引排序的洗牌后,性能数据
|
|
FOM (GB/s) |
提取效率(%) |
L2缓存命中率 |
|
内核5 – 基线 |
555.389 |
33.1 |
34.4 |
|
内核5 – 128x1x8 |
934.111 |
79.8 |
60.6 |
|
内核6 –网格索引 |
1070.04 |
95.4 |
66.2 |
这种修改后的网格索引实际上比之前修改的线程块大小表现更好。提取效率非常接近理论极限,L2缓存命中率略有提高。然而,这种解决方法也不完美——最后一个例子是在blockDim.x=256的情况下运行的,因此每个子xy平面大约占用2 MB的内存,从而仍然允许三个不同的子xy平面放入L2缓存。更大的nx*ny飞机将不可避免地面临与以前相同的问题。
4.4.5 选项2:拆分为子域
另一种更稳健地规避该问题的方法是将整个问题大小拆分为更小的域,以便三个xy平面可以放入L2缓存中并序列化内核启动。当前的xy平面大小nx,ny=10241024是之前考虑的xy平面尺寸nx,ny=512512的4倍,已知可以放入L2缓存三次,因此考虑将这个问题分解为4个子域。
先回到Kernel 5。首先修改主机端代码:
1. 内核5(之前)
dim3 grid(
(nx - 1) / block.x + 1,
(ny - 1) / (block.y * m) + 1,
(nz - 1) / block.z + 1);
...
laplacian_kernel<<<grid, block>>>(d_f, d_u, nx, ny, nz,
invhx2, invhy2, invhz2, invhxyz2);
2. 内核7(之后)
int bny = (ny - 1) / 4 + 1;
dim3 grid(
(nx - 1) / block.x + 1,
(bny - 1) / (block.y * m) + 1,
(nz - 1) / block.z + 1);
...
for (int i = 0; i < 4; i++)
laplacian_kernel<<<grid, block>>>(d_f, d_u, nx, ny, nz,
invhx2, invhy2, invhz2, invhxyz2, bny*i);
对代码进行了三处修改。首先,使用bny=(ny-1)/4+1而不是ny修改了grid.y值,以表明只在y方向上迭代了四分之一的域。接下来,添加一个for循环来启动四个HIP内核,以计算四个子域中的每一个模板。最后,通过添加y方向偏移来修改内核参数。设备内核需要修改如下:
3. 内核5(之前)
__global__ void laplacian_kernel(T * f,
const T * u, int nx, int ny, int nz,
T invhx2, T invhy2, T invhz2, T invhxyz2) {
...
int j = m*(threadIdx.y + blockIdx.y * blockDim.y);
4. 内核7(之后)
__global__ void laplacian_kernel(T * f,
const T * u, int nx, int ny, int nz,
T invhx2, T invhy2, T invhz2, T invhxyz2, int sy) {
...
int j = sy + m*(threadIdx.y + blockIdx.y * blockDim.y);
内核中的其他一切都可以保持不变。检查了以下性能,见表4-17。
表4-17 内核中的其他一切都可以保持不变,检查了一些性能
|
|
FOM (GB/s) |
取数效率 (%) |
L2 Cache命中率 |
|
内核5 – 基线 |
555.389 |
33.1 |
34.4 |
|
内核5 – 128x1x8 |
934.111 |
79.8 |
60.6 |
|
内核6 –网格索引 |
1070.04 |
95.4 |
66.2 |
|
内核7 –子域拆分 |
1175.54 |
99.6 |
67.7 |
FOM甚至比以前更高。提取效率也接近100%,表明已经优化了内存移动。与之前的解决方法不同,这种方法对于处理任何大小的xy平面都是稳健的——xy平面越大,用户可以将问题拆分为的子域就越多。如果内核将在Radeon™和Instinct™GPU上运行,则这种方法特别有用,因为不同的LLC大小会极大地影响性能的截止点。尽管选择在y方向上分割问题大小,但也可以很容易地将这种优化应用于x方向。