ROCm技术小结与回顾
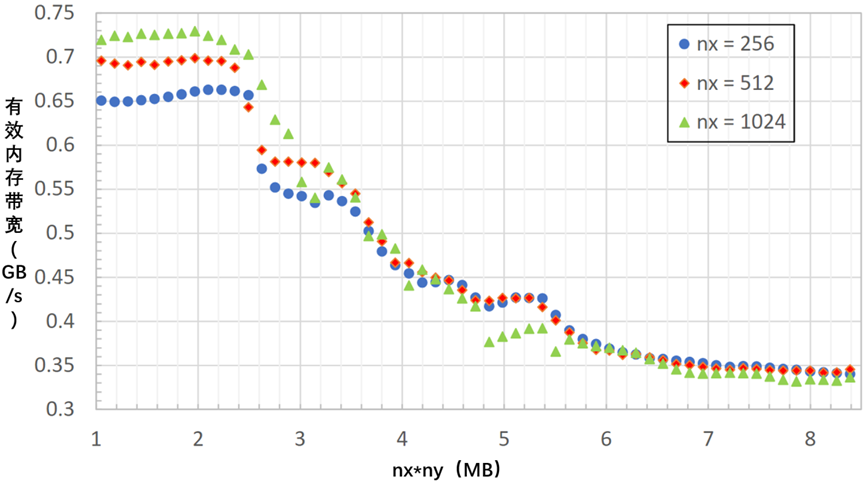
在这一部分中,首先检查了Kernel 5在各种AMD GPU和问题大小上的性能,并注意到当网格超过一定大小阈值时,性能似乎会急剧下降。通过实验确定,LLC的大小是大型xy平面问题性能的限制因素。提出了两种不同的解决方法来规避缓存大小的问题,这两种方法都只需要修改几行代码。
在有限差分法拉普拉斯级数的整个过程中,从HIP内核的简单实现开始,逐步应用了几种不同的优化,以显著提高内核的性能。现在将快速回顾一下这项工作中进行的所有不1. 同优化
循环平铺(第2部分):如果已知内核加载了多个可重用的值,请考虑添加循环平铺,即循环展开。重构代码需要几个步骤,但这最终会减少启动的线程块的数量,并增加每个线程计算的模板数量。使用这种方法可以大大降低FETCH_SIZE。
重新排序的访问模式(第2部分):在内存地址中向前和向后频繁访问设备的元素可能会过早地从缓存中驱逐可重用的数据。内核应重新排序内核中的所有加载指令,以单向访问数据,即通过升序地址访问内存。为了正确利用循环平铺优化,需要进行这种优化。
启动边界(第3部分):如果内核的寄存器使用率非常高,应用启动边界可能会使编译器在寄存器分配方面做出更适当的决定,从而改善寄存器压力。默认值是1024个线程,但强烈建议将其设置为内核将使用的线程数。
非时间负载(第3部分):输出数组f的元素不被任何其他线程或内核共享,因此内置的内部函数允许将有限差分模板计算写回设备内存,并提高从缓存中驱逐的优先级,从而为输入数组u释放更多缓存。
网格块配置(第4部分):规避溢出L2缓存问题的一种快速方法是配置线程块或网格索引配置。这使得xy平面的较小部分首先填充缓存,允许一些线程执行计算,而无需多次从全局内存中获取。
拆分为子域(第4部分):如果整个问题都受到LLC大小的限制,可以考虑将问题拆分为几个子域,并启动HIP内核来顺序处理每个子域。这种方法是稳健的,可以根据需要为任何LLC或问题规模量身定制。
结构化网格上拉普拉斯算子的有限差分模板在HIP中实现相对简单。将考虑其他偏微分方程,如声波方程,这将需要比这里显示的更高阶的模板。这很可能需要优化策略。尽管如此,认为应该利用拉普拉斯级数中概述的所有优化策略来从模板内核中获得最佳性能。
2. AMD矩阵内核
矩阵乘法是线性代数的一个基本方面,它是高性能计算(HPC)应用程序中无处不在的计算。自从引入AMD的CDNA架构以来,广义矩阵乘法(GEMM)计算现在通过矩阵核心处理单元进行硬件加速。Matrix Core加速的GEMM内核是像rocBLAS这样的BLAS库的核心,但它们也可以由开发人员直接编程。受GEMM计算吞吐量限制的应用程序可以通过利用矩阵核来实现额外的加速。
AMD的Matrix Core技术支持全方位的混合精度操作,使能够处理大型模型,并提高人工智能和机器学习工作负载的任何组合的内存限制操作性能。各种数字格式在不同的应用中都有用途。示例包括用于ML推理的8位整数(INT8)、用于ML训练和HPC应用程序的32位浮点(FP32)数据、用于图形工作负载的16位浮点(FPC6)数据和用于ML训练的16位脑浮点(BF16)数据,收敛问题较少。
要了解与SIMD向量单元相比,使用矩阵核可实现的理论加速的更多信息,可参表4-18。这些表格列出了前一代(MI100)和当前一代(MIX50X)CDNA加速器的向量(即融合乘加或FMA)和矩阵核心单元的性能。
MI100和MI250X的矩阵核心性能,见表4-18。
表4-18 MI100和MI250X的矩阵核心性能
|
数据格式 |
MI100 Flops/Clock/CU |
MI250X Flops/Clock/CU |
|
FP64 |
N/A |
256 |
|
FP32 |
256 |
256 |
|
FP16 |
1024 |
1024 |
|
BF16 |
512 |
1024 |
|
INT8 |
1024 |
1024 |
MI100和MI250X的向量(FMA)单元性能,见表4-19。
表4-19 MI100和MI250X的向量(FMA)单元性能
|
数据格式 |
MI100 Flops/Clock/CU |
MI250X Flops/Clock/CU |
|
FP64 |
64 |
128 |
|
FP32 |
128 |
128 |
与MI100和MI250X的向量单元性能相比,矩阵核心加速。注意,MI250X还支持打包的FP32指令,这也使FP32吞吐量翻倍,见表4-20。
表4-20 MI250X支持打包的FP32指令,使FP32吞吐量翻倍
|
数据格式 |
MI100矩阵/向量加速 |
MI250X矩阵/向量加速 |
|
FP64 |
N/A |
2x |
|
FP32 |
2x |
2x |
3. 使用AMD矩阵内核
AMD CDNA GPU中的矩阵融合乘加(MFMA)指令基于每个波阵面运行,而不是基于每个通道(线程)运行:输入和输出矩阵的条目分布在波阵面向量寄存器的通道上。
AMD矩阵核可以通过多种方式加以利用。在较高层次上,可以使用rocBLAS或rocWMMA等库在GPU上执行矩阵运算。例如,如果对手头的计算有利,rocBLAS可能会选择使用MFMA指令。对于更接近金属的方法,可以选择
1)完全用汇编语言编写GPU内核(这可能有点挑战性和不切实际)
2)在HIP内核中添加内联汇编(不建议,因为编译器不考虑内联指令的语义,也可能不考虑数据风险,例如在使用MFMA指令的结果之前的强制循环次数)
3)使用编译器内部函数:这些函数以编译器知道语义和要求的方式表示汇编
指令。
编码示例使用了MFMA指令的一些可用编译器内部函数,并展示了如何将输入和输出矩阵的条目映射到波前向量寄存器的通道。所有示例都使用单个波前来计算小矩阵乘法。 这些示例并非旨在展示如何在MFMA操作中实现高性能。
4. MFMA编译器固有语法
考虑以下乘法MFMA运算,其中所有操作数A,B,C和D是矩阵:
D=AB+C
为了在AMD GPU上执行MFMA操作,LLVM内置了内部函数。回想一下,这些内在函数是在波阵面范围内执行的,输入和输出矩阵的片段被加载到波阵面中每个通道的寄存器中。MFMA编译器内部的语法如下所示。
d=__builtin_amdgcn_mfma_CDFmt_MxNxKABFmt(a,b,c,cbsz,abid,blgp)
其中,
CDfmt是C&D矩阵的数据格式
ABfmt是A&B矩阵的数据格式
M、 N和K是矩阵维数:
mA[M][K]源A矩阵
mB[K][N]源B矩阵
mC[M][N]累积输入矩阵C
mD[M][N]累积结果矩阵D
a是存储来自源矩阵a的值的向量寄存器集
b是存储源矩阵b值的向量寄存器集
c是存储来自累加输入矩阵c的值的向量寄存器集合
d是存储累加结果矩阵d的值的向量寄存器的集合
cbsz A中的其他相邻块。为广播选择的输入块由abid参数确定。默认值0不会导致值的广播。例如,对于16块a矩阵,设置cbsz=1将导致块0和1接收相同的输入值,块2和3接收相同的输出值,块4和5接收相同的接收值,以此类推。
abid,即A矩阵广播标识符,由具有A矩阵多个输入块的指令支持。它与cbsz一起使用,指示选择哪个输入块向A矩阵中的其他相邻块广播。例如,对于16块A矩阵,设置cbsz=2和abid=1将导致块1的值广播到块0-3,块5的值广播给块4-7,块9的值广播向块8-11等。
blgp是B矩阵车道组模式修改器,允许在车道之间对B矩阵数据进行一组受约束的切换操作。对于支持此修饰符的说明,支持以下值:
blgp=0 B的正常矩阵布局
blgp=1,来自通道0-31的B矩阵数据也被广播到通道32-63中
blgp=2,来自通道32-63的B矩阵数据被广播到通道0-31
blgp=3,所有车道的B矩阵数据向下旋转16(例如,车道0的数据被放入车道48,车道16的数据被置于车道0)
blgp=4,来自通道0-15的B矩阵数据被广播到通道16-31、32-47和48-63
blgp=5,来自通道16-31的B矩阵数据被广播到通道0-15、32-47和48-63
blgp=6,来自通道32-47的B矩阵数据被广播到通道0-15、16-31和48-63
blgp=7,来自通道48-63的B矩阵数据被广播到通道0-15、16-31和32-47
CDNA2 GPU支持的矩阵尺寸和块数,见表4-21。
表4-21 CDNA2 GPU支持的矩阵尺寸和块数
|
A/B数据格式 |
C/D 数据格式 |
M |
N |
K |
块 |
周期 |
Flops/cycle/CU |
|
FP32 |
FP32 |
|
|
|
|
|
|
|
|
|
32 |
32 |
2 |
1 |
64 |
256 |
|
|
|
32 |
32 |
1 |
2 |
64 |
256 |
|
|
|
16 |
16 |
4 |
1 |
32 |
256 |
|
|
|
16 |
16 |
1 |
4 |
32 |
256 |
|
|
|
4 |
4 |
1 |
16 |
8 |
256 |
|
FP16 |
FP32 |
|
|
|
|
|
|
|
|
|
32 |
32 |
8 |
1 |
64 |
1024 |
|
|
|
32 |
32 |
4 |
2 |
64 |
1024 |
|
|
|
16 |
16 |
16 |
1 |
32 |
1024 |
|
|
|
16 |
16 |
4 |
4 |
32 |
1024 |
|
|
|
4 |
4 |
4 |
16 |
8 |
1024 |
|
INT8 |
INT32 |
|
|
|
|
|
|
|
|
|
32 |
32 |
8 |
1 |
64 |
1024 |
|
|
|
32 |
32 |
4 |
2 |
64 |
1024 |
|
|
|
16 |
16 |
16 |
1 |
32 |
1024 |
|
|
|
16 |
16 |
4 |
4 |
32 |
1024 |
|
|
|
4 |
4 |
4 |
16 |
8 |
1024 |
|
BF16 |
FP32 |
|
|
|
|
|
|
|
|
|
32 |
32 |
8 |
1 |
64 |
1024 |
|
|
|
32 |
32 |
4 |
2 |
64 |
1024 |
|
|
|
16 |
16 |
16 |
1 |
32 |
1024 |
|
|
|
16 |
16 |
4 |
4 |
32 |
1024 |
|
|
|
4 |
4 |
4 |
16 |
8 |
1024 |
|
|
|
|
|
|
|
|
|
|
|
|
32 |
32 |
4 |
1 |
64 |
512 |
|
|
|
32 |
32 |
2 |
2 |
64 |
512 |
|
|
|
16 |
16 |
8 |
1 |
32 |
512 |
|
|
|
16 |
16 |
2 |
4 |
32 |
512 |
|
|
|
4 |
4 |
2 |
16 |
8 |
512 |
|
FP64 |
FP64 |
|
|
|
|
|
|
|
|
|
16 |
16 |
4 |
1 |
32 |
256 |
|
|
|
4 |
4 |
4 |
4 |
16 |
128 |
CDNA2架构支持的所有指令的完整列表可以在《AMD Instinct MI200指令集架构参考指南》中找到。AMD的矩阵指令计算器工具允许生成更多信息,如计算吞吐量和AMD Radeon™和AMD Instinct™加速器上MFMA指令的寄存器使用情况。
示例1–V_MFMA_F32_16x16x4F32考虑矩阵乘法运算D=AB,其中M=N=16,K=4,元素类型为FP32。为了简单起见,假设输入C矩阵包含零。将演示内部函数__builtin_amdgcn_mfma_f32_16x16x4f32的使用,该函数在一次调用中计算四个外积之和。此函数对单个矩阵块进行操作。
输入矩阵A和B分别具有16×4和4×16的维数,矩阵C和D具有16×16的元素。将16×4线程块映射到两个输入矩阵的元素很方便。这里,线程块具有一个
波阵面,在x维度上有16个线程,在y维度上有4个线程。以行主格式表示矩阵:A[i][j]=j+i*N,其中i是行,j是列。使用这种表示法,块中x,y位置的线程将加载条目a[x][y]和B[y][x]。输出矩阵有16×16个元素,因此每个线程将有4个元素要存储。
以下两幅图显示了
1)A和B输入的形状和大小,如图4-12所示。
2)A和B的元素如何映射到波阵面所拥有的寄存器中的通道,如图4-13所示。
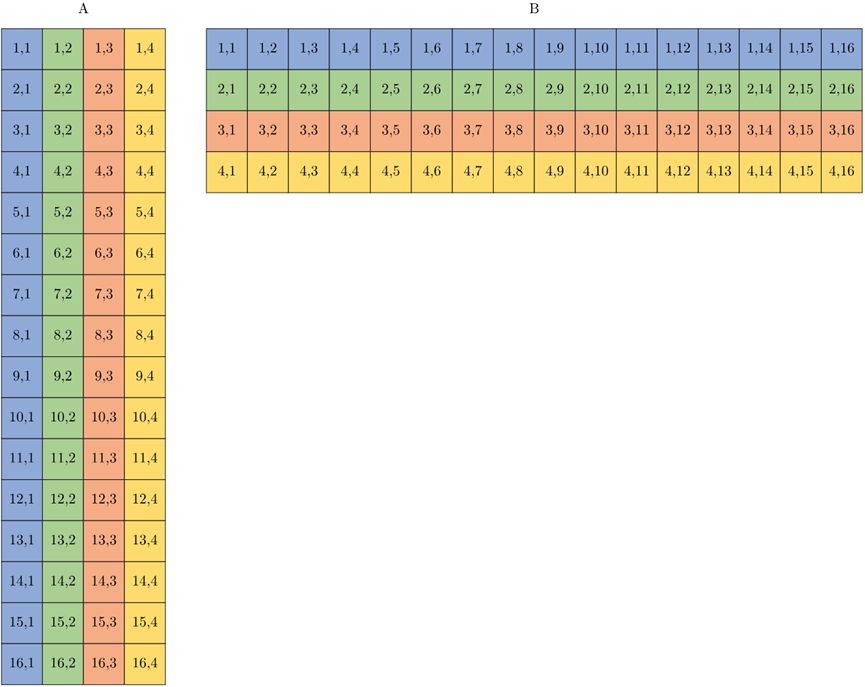
图4-12 A和B输入的形状和大小

图4-13 A和B的元素如何映射到波阵面所拥有的寄存器中的车道
以下两幅图显示了
1)输出矩阵D的形状和大小,如图4-14所示。
2)D的元素如何映射到波阵面所拥有的寄存器中的通道,如图4-15所示。

图4-14 输出矩阵D的形状和大小

图4-15 D的元素如何映射到波阵面所拥有的寄存器中的通道
下面给出了执行此MFMA操作的示例内核。
#define M 16
#define N 16
#define K 4
__global__ void sgemm_16x16x4(const float *A, const float *B, float *D)
{
using float4 = __attribute__( (__vector_size__(K * sizeof(float)) )) float;
float4 dmn = {0};
int mk = threadIdx.y + K * threadIdx.x;
int kn = threadIdx.x + N * threadIdx.y;
float amk = A[mk];
float bkn = B[kn];
dmn = __builtin_amdgcn_mfma_f32_16x16x4f32(amk, bkn, dmn, 0, 0, 0);
for (int i = 0; i < 4; ++i) {
const int idx = threadIdx.x + i * N + threadIdx.y * 4 * N;
D[idx] = dmn[i];
}
}
此内核按如下方式启动。
dim3 grid (1, 1, 1);
dim3 block(16, 4, 1);
sgemm_16x16x4 <<< grid, block >>> (d_A, d_B, d_D);
如前所述,假设输入C矩阵包含零。
示例2–V_MFMA_F32_16x16x1F32考虑使用编译器内部__builtin_amdgcn_MFMA_F32_16x16x1F32将维度M=N=16和K=1的矩阵相乘的情况。在这种情况下,输入值可以仅由波阵面的16个通道保持。事实上,该指令可以同时将4个这样的矩阵相乘,从而使每个通道保持来自这4个矩阵之一的值。
可以重复使用前面示例中的图形来说明此操作的数据布局。在这种情况下,输入A不是16×4矩阵,而是四个16×1矩阵。但它们的布局方式以及波阵面中每个通道所拥有的元素是相同的,如图4-16所示。A的列是不同的16×1矩阵,输入B类似,如图4-17所示。
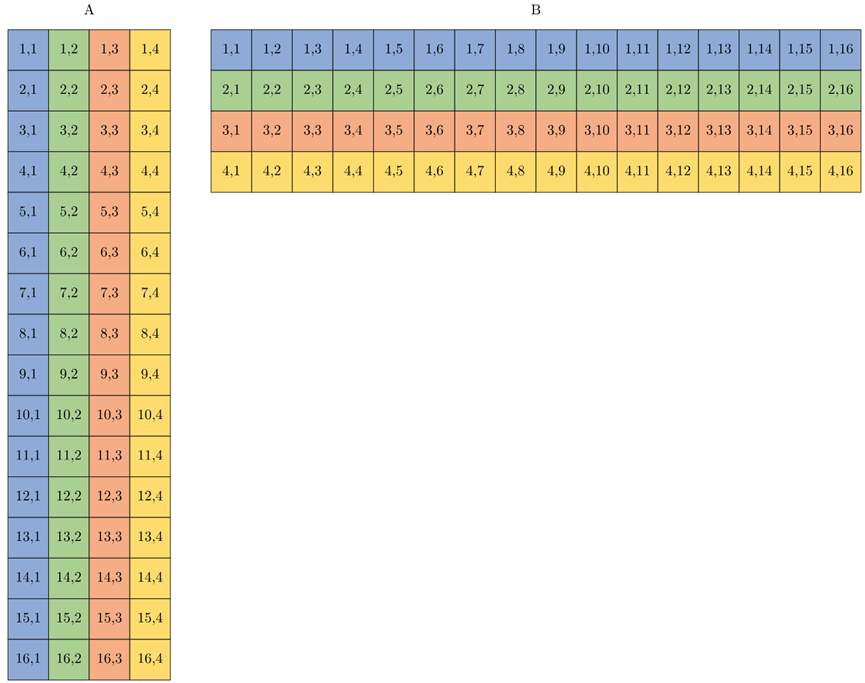
图4-16 输入A不是16×4矩阵,而是四个16×1矩阵,输入B类似
 图4-17 A的列是不同的16×1矩阵,输入B类似
图4-17 A的列是不同的16×1矩阵,输入B类似给定矩阵乘法的输出具有与前一个示例完全相同的数据布局。不同的是,现在有四个单独的输出,每个乘法一个。
下面的内核显示一个由4个大小为M=N=16和K=1的矩阵组成的压缩批的乘法示例。
#define M 16
#define N 16
#define K 1
__global__ void sgemm_16x16x1(const float *A, const float *B, float *D)
{
using float16 = __attribute__( (__vector_size__(16 * sizeof(float)) )) float;
float16 dmnl = {0};
int mkl = K * threadIdx.x + M * K * threadIdx.y;
int knl = threadIdx.x + N * K * threadIdx.y;
float amkl = A[mkl];
float bknl = B[knl];
dmnl = __builtin_amdgcn_mfma_f32_16x16x1f32(amkl, bknl, dnml, 0, 0, 0);
for (int l = 0; l < 4; ++l) {
for (int i = 0; i < 4; ++i) {
const int idx = threadIdx.x + i * N + threadIdx.y * 4 * N + l * M * N;
D[idx] = dmnl[i];
}
}
}
此内核通过以下方式启动:
dim3 grid (1, 1, 1);
dim3 block(16, 4, 1);
sgemm_16x16x1 <<< grid, block >>> (d_A, d_B, d_D);