探秘Transformer系列之(15)--- 采样和输出
- 探秘Transformer系列之(15)--- 采样和输出
- 0x00 概述
- 0x01 Generator
- 1.1 Linear
- 1.2 softmax
- 1.3 实现
- 1.4 使用
- 推理
- 训练
- 0x02 采样
- 2.1 采样方法
- 确定性采样
- 概率性采样
- 2.2 贪心解码
- 2.3 Beam(束搜索)
- 问题
- 思路
- 效率
- 杂项
- 惩罚
- 停止
- 优化
- 2.4 top-k
- 2.5 top-p
- 2.6 性能
- 2.1 采样方法
- 0x03 采样参数
- 3.1 temperature
- 概念
- 动态温度系数
- KL-Divergence Guided Temperature Sampling
- Hot or Cold
- EDT
- 3.2 repetition_penalty
- 问题原因
- 参数原理
- 3.1 temperature
- 0x04 logits分析
- 4.1 压缩信息
- 示例
- 分析
- 4.2 变化
- 4.3 预处理logits
- 背景和动机
- 洞察
- 噪声区域
- 信息区域
- 核心思路
- 确定边界
- 算法
- 4.2 隐式思维链
- pause tokens/Filler Token
- CoT
- coconut
- 4.3 基于熵的采样
- SED
- entropix
- 相关信息
- 核心思路
- 4.1 压缩信息
- 0x05 权重共享
- 5.1 vanilla Transformer
- 5.2 共享词表权重
- 原理
- 历史基础
- 5.2 FC和embedding共享
- 0xFF 参考
0x00 概述
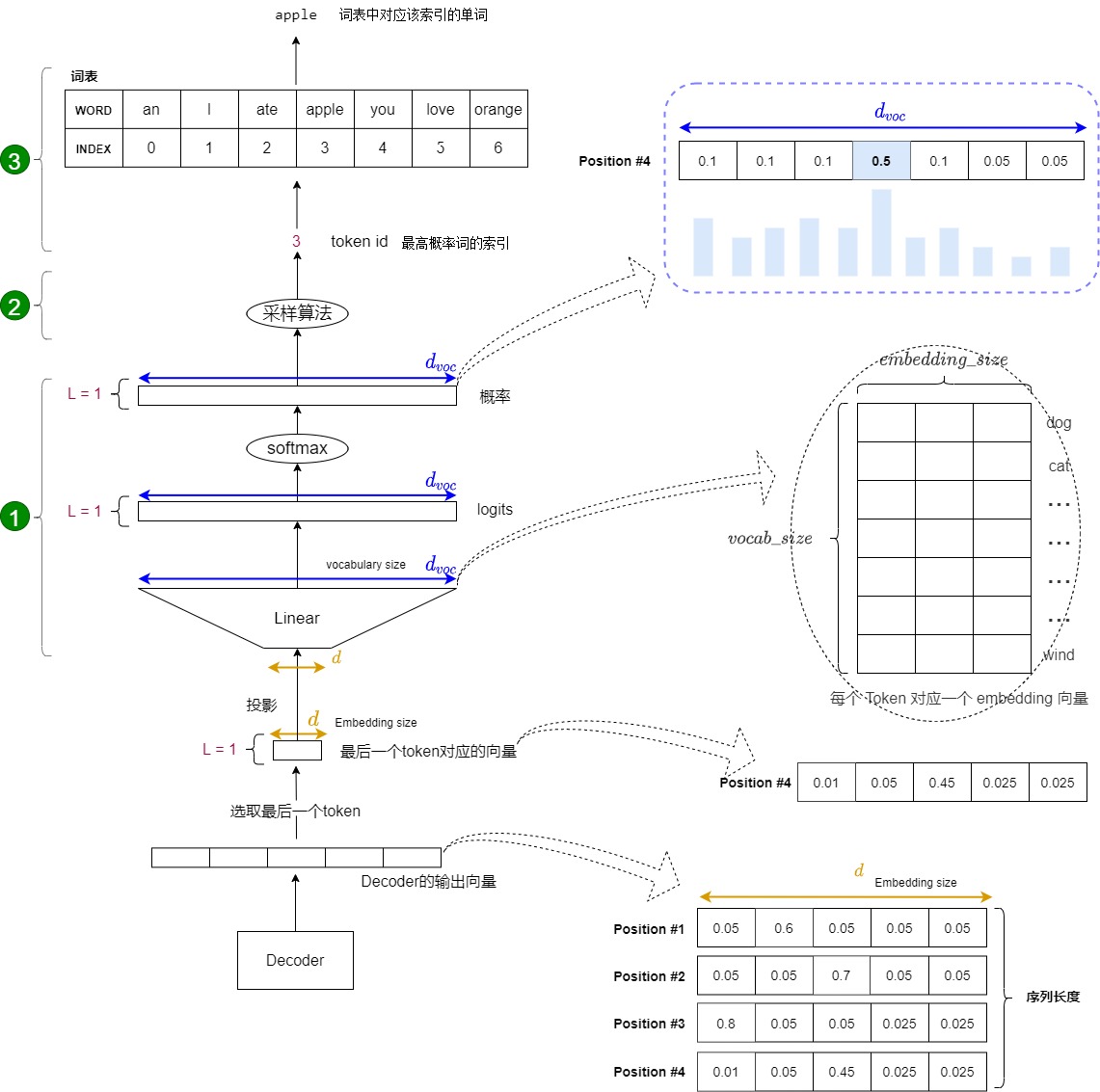
解码器包括很多Transformer层,每一层的最后部分是"Add & Norm",其实也就是说,编码器的最后一层的最后一个模块是一个"Add & Norm"。该模块的输出是一个代表语义的浮点型向量。我们目前遇到的问题是:如何把这个浮点向量转换成一个词?这就是采样和输出部分所做的工作。简要来说,在预测阶段,采样和输出部分会执行下面三步:
- 计算概率。在解码器层输出结果后,需要经过Generator线性层进行最后的预测,Generator线性层就是个标准的分类网络。Generator线性层会把最后一个token对应的特征向量通过一个线性层升维到词表维度,并且把升维后的新向量通过softmax进行归一化,最终输出一个概率分布(每个概率对应词汇表中的一个token)。该分布表示词表中每个词匹配这个特征向量的概率,或者说是表示词表中每个 token 作为下一个 token 的概率。该部分实际是一个分类网络。
- 采样。根据这个概率分布来指导采样,找出最大概率对应的词表index。
- 生词。依据index从词表中选择下一个 token 作为最终输出。
下图展示了上述流程:从底部以解码器组件产生的输出向量开始,最终转化出一个输出单词。
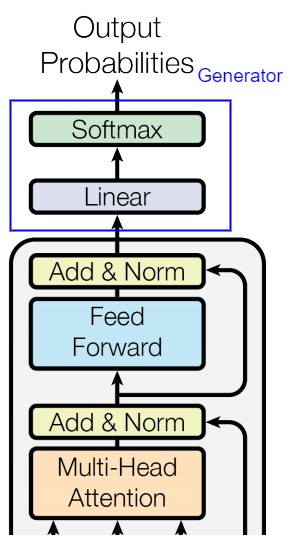
0x01 Generator
Transformer为代表的深度神经网络是万能函数逼近器,所做的事情是学习外部世界信息的概率分布,将其压缩或提取,构建内部概率模型。编码器-解码器处理之后的输出依然是一个实数向量,该向量是一个高维概率向量,其代表了Transformer视角下的编织起来的事物之间的各种复杂的关系。我们需要对此向量进行分类训练,才能从复杂关系中确认下一个token。
Generator就完成了此分类功能。Generator的输入是词向量序列,输出是每个位置上单词的概率分布。其主要包括两部分:
- Linear:将输出扩展至Vocabulary Size,或者说把词映射到词典。 Linear的输入是经过编码器-解码器处理后的词向量(在推理时,Generator使用的并不是解码器的所有输出token,而是最后一个token),输出是logits(对数几率/词表特征)。
- Softmax:Softmax将输入的logits转换为概率,输出就是最后一个token对应词表中单词的概率分布。后续会选取概率最高的作为预测结果。
1.1 Linear
线性层主要起到转换维度的作用,这一步的目的是将解码器生成的向量映射到预先定义的词典大小,从而准备进行词预测。其相关特点如下:
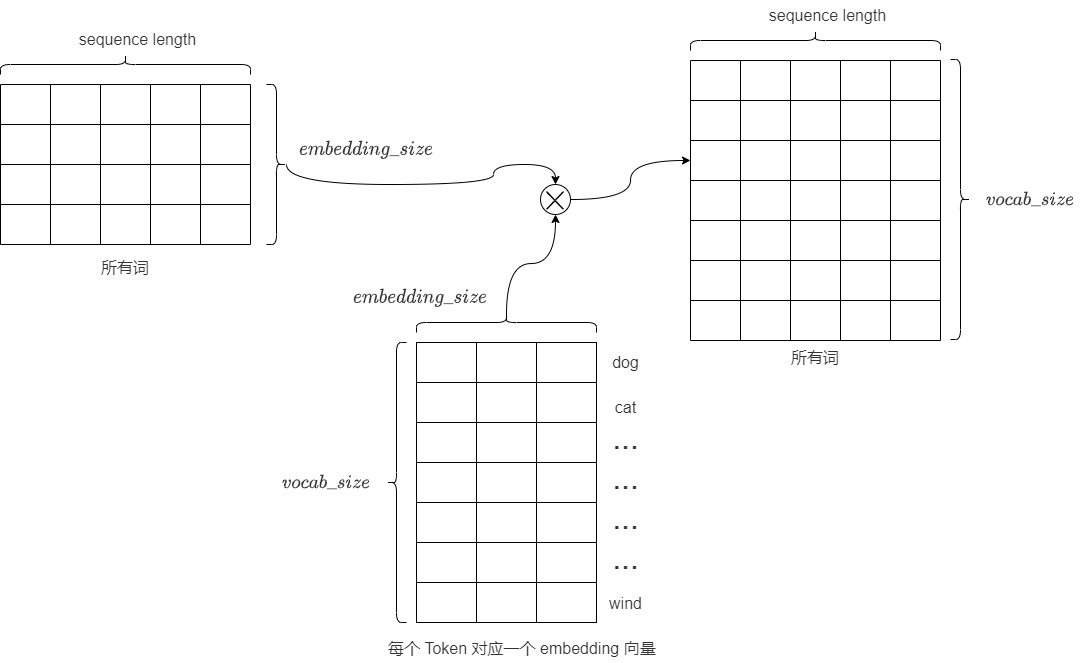
- 线性层(通常被称为 language model head 或 LM head)是一个简单的全连接神经网络,它可以把解码器产生的向量投射到一个比它大得多的,被称作logits的向量上。
- 也可以把线性层认为是 Token Embeddings 矩阵,其行数为模型词表中 Token 的个数,列数为 embedding 的维度,也就是每个 Token 对应一个 embedding 向量。解码器产生的向量和Token Embeddings 矩阵相乘(也就是和每个 Token 对应的 embedding 向量做内积),得到和词表中每个 Token 的相似性得分(logits),生成一个与模型词汇表中每个词作为下一词出现的可能性相关的数值列表(即logits)。
- logits的大小是
vocab_size,对应了词汇表的大小。假设我们的模型词汇表是10000个词,那logits向量维数也是10000,词表中每个词对应logits向量中的一个logit。如果编码器输出的形状是(batch size,100,512),则把其中每个序列最后一个token取出,经过大小为[512, 10000]的线性层后,就得到形状为(batch size, 1,10000)的logits列表。 - logits向量包含每个单词成为序列中下一个单词的概率,或者说是候选 Token 的得分向量。logits的每一个维度都代表目标语言单词库中的一个单词,具体对应这个单词的分数(Word Scores)或者是分数权重,表示某个特定词元是“正确”下一个词元的概率。logit值越高,表示相应词元是“正确”词元的可能性越大。具体而言,假设我们预测第i个位置的单词,目标词汇表中的每个单词在第i个位置都有一个分数值,分数值表示词汇表中的每个词在第i个位置出现的可能性分数。向量中某维度的值越大,代表此单词是第i个位置上单词的概率越大。因此线性层就充当了分类头(词表中的每一个词当作一个类别)的作用,只是这个分类头的类别比较大。
- 后续要从这些单词中找出最大概率生成的词是哪几个?为何要是几个单词?这是因为要通过类似top_k的采样算法来调整模型的表现力,否则,你对模型说我爱你,模型回复的答案永远是我也爱你。
比如针对上下文”I am sleepy. I start a pot of",下图给出了预测下一个token时,词表中每个词的概率分布(按降序排列)。

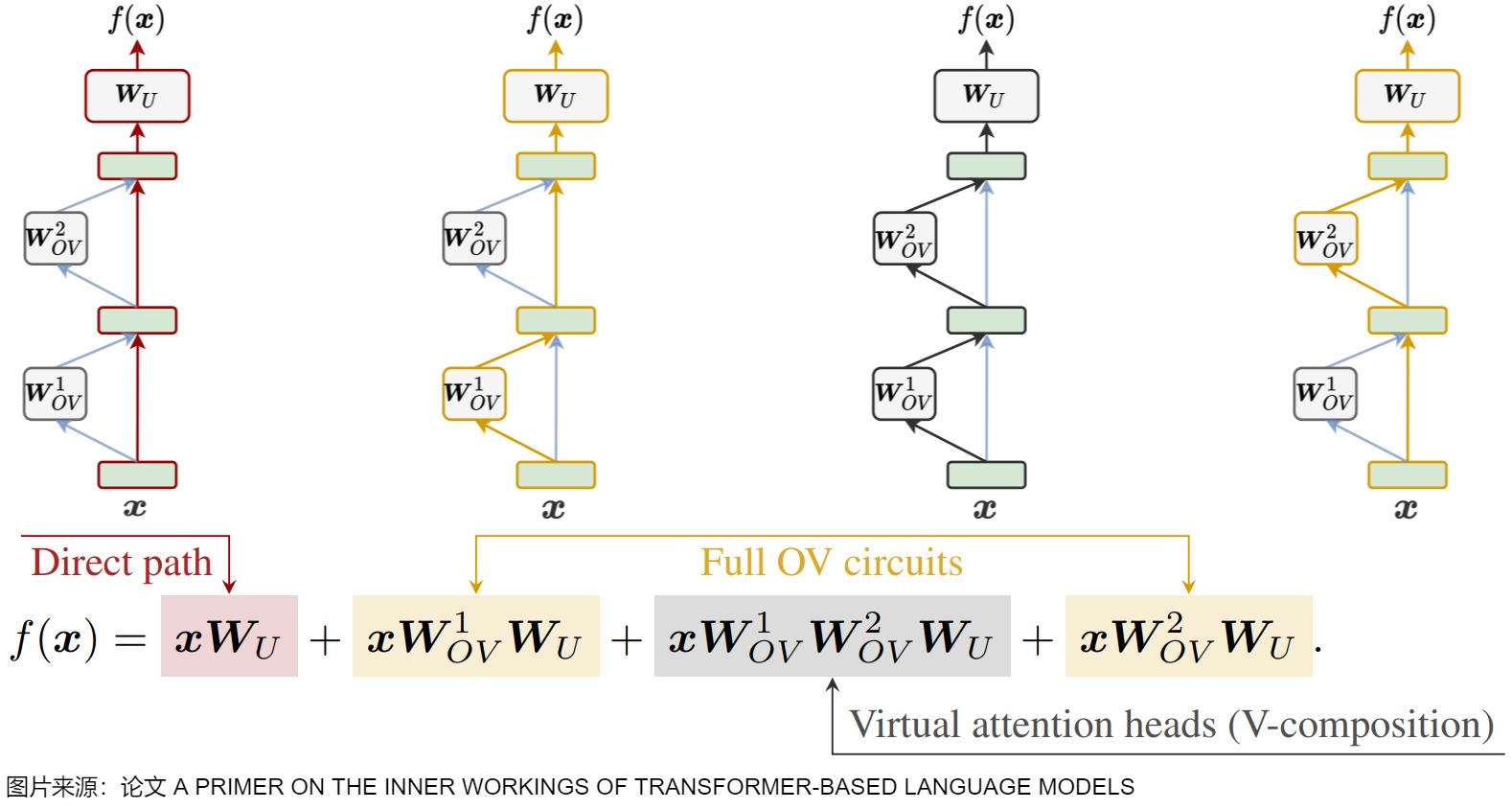
下图给出了预测头的数学表示,\(W_U\)就是线性层(unembedding matrix),有时还会有偏置。最后一个残差流状态通过该线性映射进行转换,将表示转换为基于logits的下一个token分布,该分布通过softmax函数转换为概率分布。

下图则对Transformer的前向传播过程进行分解,图中方程式的四项的特点如下:
- 第一项是direct path(直接路径),该路径把输入embedding和 unembedding matrix 连接起来,对应图中上方最左侧的红色路线。
- 第二项和第四项被称为full OV circuits,该路径流经单个OV矩阵,对应图中上方的黄色路线。
- 第三项被称为虚拟注意头(virtual attention heads)。因为该部分两个注意头的顺序读写,因此也被称为V-composition(虚拟组合)。
1.2 softmax
线性层输出的 logits难以解释,因此我们接下来会把logits经过 softmax 转换为概率,即把向量中最后一维的数字缩放到0-1的概率值域内,并确保这些数字的和为1。这在多分类问题中尤为重要,因为模型预测的结果可以解释为每个类别的概率(每个位置上单词的概率分布)。后续会按照概率分布采样。
注意:Generator 返回的是 softmax 的 log 值。这里使用的是log_softmax而非softmax。虽然其效果应该是一样的。但是log_softmax能够解决溢出问题,加快运算速度,提高数据稳定性。
1.3 实现
本章第一个图的蓝圈对应下面的Generator类。Generator类包括Linear层和Softmax层。从直观的角度看,
-
线性层的作用就是把词映射到词典。
-
Softmax层的作用就是选择概率最大的词。
Generator类的构建参数为:
- d_model:Decoder输出的大小,即词向量的维度。
- vocab:词典的大小。
具体代码如下。
# nn.functional工具包装载了网络层中那些只进行计算, 而没有参数的层
import torch.nn.functional as F# 定义一个基于 nn.Module 的生成器类,其将线性层和softmax计算层一起实现, 因为二者的共同目标是生成最后的结构,因此把此类的名字叫做Generator
class Generator(nn.Module):"Define standard linear + softmax generation step."# 初始化方法,接收模型维度(d_model)和词汇表大小(vocab)作为参数def __init__(self, d_model, vocab):"""初始化函数的输入参数有两个, d_model代表词嵌入维度, vocab_size代表词表大小."""super(Generator, self).__init__() # 调用 nn.Module 的初始化方法# 这个线性层的参数有两个, 就是初始化函数传进来的两个参数: d_model, vocab_sizeself.proj = nn.Linear(d_model, vocab) # 定义一个线性层,将向量从模型的输出维度映射到词汇表大小# 前向传播方法,输入x是Decoder的输出,x的形状是[1, d_model],因为x是序列中最后一个token对应的向量def forward(self, x):# 将输入 x 传入线性层,然后对输出应用 log-softmax 激活函数(在最后一个维度上)# 在函数中, 首先使用self.proj对x在最后一个维度上进行线性变化, # 然后使用F中已经实现的log_softmax进行的softmax处理. # log_softmax就是对softmax的结果又取了对数, 因为对数函数是单调递增函数, 因此对最终我们取最大的概率值没有影响. 最后返回结果即可 return log_softmax(self.proj(x), dim=-1)
1.4 使用
如何使用Generator类?以及如何使用生成的概率?
推理
在推理时,只需要拿Decoder输出的最后一个token对应的张量送给Generator,得到一个词的概率分布。以下是推理代码。
def inference_test():test_model = make_model(11, 11, 2)test_model.eval()src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])src_mask = torch.ones(1, 1, 10)memory = test_model.encode(src, src_mask)ys = torch.zeros(1, 1).type_as(src)for i in range(9):out = test_model.decode(memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data))prob = test_model.generator(out[:, -1])_, next_word = torch.max(prob, dim=1)next_word = next_word.data[0]ys = torch.cat([ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1)print("Example Untrained Model Prediction:", ys)
torch.max(prob, dim=1)实际上就是下面要学习的贪心解码。next_token = vocabulary[np.argmax(probs)] 便可以获取词表中的token。
训练
在训练时,需要将Decoder的所有输出送给Generator,然后对于输出的每个词,都会得到一个词的概率分布。在每个位置,我们先找到概率最高的单词索引(贪婪搜索),然后将该索引映射到词汇表中的相应单词。这些词就构成了 Transformer 的输出序列。
具体示例代码如下。
def example_simple_model():V = 11criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)model = make_model(V, V, N=2)optimizer = torch.optim.Adam(model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9)lr_scheduler = LambdaLR(optimizer=optimizer,lr_lambda=lambda step: rate(step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400),)batch_size = 80for epoch in range(20):model.train()run_epoch(data_gen(V, batch_size, 20),model,SimpleLossCompute(model.generator, criterion), # 调用Generator类的实例optimizer,lr_scheduler,mode="train",)model.eval()run_epoch(data_gen(V, batch_size, 5),model,SimpleLossCompute(model.generator, criterion), # 调用Generator类的实例DummyOptimizer(),DummyScheduler(),mode="eval",)[0]model.eval()src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])max_len = src.shape[1]src_mask = torch.ones(1, 1, max_len)print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))# execute_example(example_simple_model)
具体是在计算损失里面调用了model.generator进行预测。假设batch size是2,序列长度是100,代码中会对最后一个维度进行softmax操作,得到bx100个单词的概率分布,在训练过程中bx100个单词是知道真值的,故可以直接采用损失函数进行训练。
class SimpleLossCompute:"A simple loss compute and train function."def __init__(self, generator, criterion):self.generator = generatorself.criterion = criteriondef __call__(self, x, y, norm):x = self.generator(x)sloss = (self.criterion(x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1))/ norm)return sloss.data * norm, sloss
0x02 采样
拿到logits后,下一步是根据它来选择下一个词元。这个过程称为采样。通过 logits 生成的概率来提取 tokens 的过程是通过一种被称为采样方法、搜索策略(search strategy)、生成策略(generation strategy)或解码策略(decoding strategy)的启发式方法来完成的。由于语言的顺序结构,token不仅要在上下文中合适,而且要自然地流动以创建连贯的句子和段落。采样方法有助于选择遵循语言模式和结构的token。此外,采样方法有助于在确定性输出和创造性、多样化响应之间取得平衡。
所有采样方法的基本原理是设定一个概率阈值 \(𝑝^{(𝑡)}∈[0,1]\)。概率大于该阈值的token将形成采样的核心集(nucleus),其累积概率确定了nucleus的质量,具体参见下图。
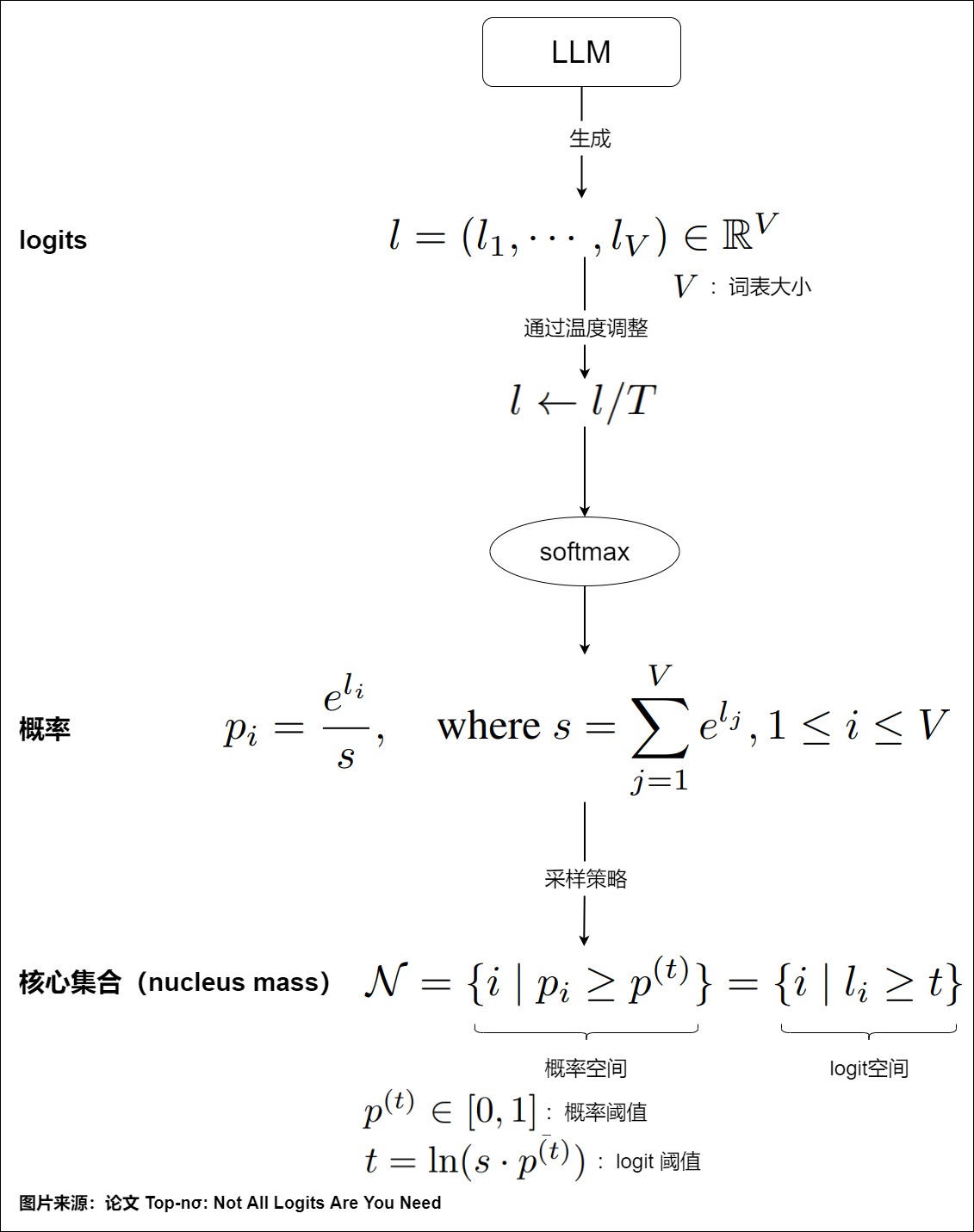
针对不同的使用场景,有多种采样方法可用。不论那种策略,最终解码的结果应该满足在给定输入文本的条件下,输出的文本在所有候选文本中得分最高,表现为输出文本每个位置上的单词的联合概率最大。上面推理示例中的torch.max(prob, dim=1)实际上就是贪心解码。每次都选择最可能的 token 称为贪婪解码。这并不总是最好的方法,因为它可能导致次优结果。我们接下来深入学习解码策略。
2.1 采样方法
LLM模型的输出是在词表上的概率分布,采样方法直接决定了我们会得到怎么样的输出效果。有时候我们希望得到完全确定的结果,有时候希望得到更加丰富有趣的结果。下面我们介绍两大类采样方法:确定性采样和概率性采样。
确定性采样
确定性采样顾名思义就是输出结果是确定性的,本质上是搜索过程。常见的如Greedy Search(贪心搜索)和Beam Search(集束搜索)。
- 贪心解码是一种高效获取预测序列的近似方法。它每次选择概率最大(与logit值最相似的)的下一个token,并且丢弃其他词,直到满足终止条件。
- beam-search是在当前步骤根据历史记录选择最好的几个(这个数字也被称为beam-width)作为候选,每次都根据历史信息选择最好的。Beam Search集束搜索是Greedy Search的改进版,它拓展了Greedy Search在每一步的搜索空间,每一步保留当前最优的K个候选,在一定程度上缓解了Greedy Search的问题。K就是Beam Size,代表了束宽。Beam Size是一个超参数,它决定搜索空间的大小,越大搜索结果越接近最优,但是搜索的复杂度也越高,当Beam Size等于1的时候,Beam Search退化为Greedy Search。
概率性采样
概率性采样会基于概率分布做采样,以条件概率随机挑选下一个词,因此有机会生成小概率的token。在这种采样中,模型的 logits 被看作是一个多项分布,然后基于该分布进行抽样。换句话说,概率性采样就是通过抽样从词汇表(vocabulary)中选择一个token,而我们可以先通过一些简单操作(如temperature scaling、top-k和top-p)来对这种抽样分布进行调整。
常见的概率性采样有以下3种:Multinomial采样(直接基于概率分布做纯随机采样,容易采到极低概率的词),Top-k采样和Top-p采样。top_p 和 top_k 都可以用于增加模型生成结果的多样性。top-p和top-K采样可以结合使用,在开放式语言生成上产生比Greedy Search和Beam Search更为流畅的文本。
2.2 贪心解码
贪心搜索是最简单的解码方法。它从词汇表 V 中选择具有最高条件概率的token。在每一步中,它选择概率最高的token并将其添加到序列中。它继续进行,直到遇到一个结束token或达到最大序列长度。
我们从数学角度来解释一下贪心解码。在sequence-to-sequence问题中,给定一个输入序列\(x = (x_1, . . . , x_n)\),我们希望预测相应的输出序列\(y = (y_1, . . . , y_m)\)。解决这个问题的一种常见方法是学习一个自回归评分模型(auto-regressive scoring model)\(p(y|x)\)。该模型从左到右逐个生成答案中的一部分(比如一个 Token)。
假设词表空间为 K(也就是所有可能的输出),那么每次预测都会有 K 种可能,整个答案将要有 \(K^m\) 种可能,这个计算代价太高。为了降低计算量,可以每次都只选择得分最高的输出 \(y_j\)作为当前步骤的生成结果,然后重复上述过程,直到获得最终的结果。这种方式就称为贪心解码,具体如下图所示。

贪心解码的好处是实现简单,可作为解码的快速实现。而且非常适合模型效果严格对齐的场合,即适合需要确定性输出的场景。因为在推理阶段,模型的权重是确定的,并且也不会有 dropout 等其他随机性(忽略不可抗的硬件计算误差,比如并行规约求和的累积误差等),因此对于同一个输入,在多次运行贪心解码后,模型的输出结果应该完全一致。
贪心解码的问题如下:
- 模型效果可能不是最优的。因为贪心解码只能保证每一步的局部最优(只管当前步骤的信息),不会关心输出序列的联合概率是否达到最大值(没有综合历史信息),这样达不到全局最优,忽视了潜在的长期利益。另外,如果在时刻 t 模型的最优输出并不是正确的结果,从 t+1 开始的每个时刻,模型都会受到这样一个错误输出的影响,具有错误的累加效果。最后导致模型“越走越偏”。
- 贪心搜索也会缺乏一定的多样性。贪心搜索总是选择最可能的词,倾向于偏爱经常使用的短语,导致可预测的结果和单调的输出。
- 需要m步来产生长度为m的输出,随着模型的增大,每一步的时延也会增大,整体时延也会放大至少 m 倍。
- 每次进行一个token生成的计算需要搬运全部的模型参数和激活张量,这使解码过程严重受限于内存带宽。
- 贪心搜索不能纠正其错误。一旦它做出了不理想的选择,每个随后的决策都会受到影响。
贪心解码的代码如下。
def greedy_decode(model, src, src_mask, max_len, start_symbol):""" 进行模型推理,推理出所有预测结果。 :param model: Transformer模型,即EncoderDecoder类对象 :param src: Encoder的输入inputs,Shape为(batch_size, 词数) ,例如:[[1, 2, 3, 4, 5, 6, 7, 8, 0, 0]]代表一个句子,该句子有10个词 :param src_mask: src的掩码,掩盖住非句子成分。 :param max_len: 一个句子的最大长度。 :param start_symbol: '<bos>' 对应的index,在本例中始终为0 :return: 预测结果,例如[[1, 2, 3, 4, 5, 6, 7, 8]] """ memory = model.encode(src, src_mask) # 将src送入Transformer的Encoder,输出memory ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data) # 初始化ys为[[0]],用于保存预测结果,其中0表示'<bos>'# 循环调用decoder,一个个的进行预测。例如:假设我们要将“I love you”翻译成“我爱你”,则第一次的`ys`为(<bos>),然后输出为“I”。第二次`ys`为(<bos>, I) ,输出为"love",依次类推,直到decoder输出“<eos>”或达到句子最大长度。for i in range(max_len - 1):# 将encoder的输出memory和之前Decoder的所有输出作为参数,让Decoder来预测下一个token out = model.decode(memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data))# 将Decoder的输出送给generator进行预测。这里只取最后一个词的输出进行预测。 # 因为传的tgt的词数是变化的,第一次是(<bos>),第二次是(<bos>, I) # 所以out的维度也是变化的,变化的就是(batch_size, 词数,词向量)中词数这个维度 prob = model.generator(out[:, -1]) # 只取出最后一个向量来预测,即 从 seq_len 维度选择最后一个词# 取出数值最大的那个,它的index在词典中对应的词就是预测结果_, next_word = torch.max(prob, dim=1)next_word = next_word.data[0] # 取出预测结果# ys就是Decoder之前的所有输出ys = torch.cat( # 将这一次的预测结果和之前的拼到一块,作为之后Decoder的输入[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1)return ys # 返回最终的预测结果
"""out torch.Size([1, 2, 512]) (batch_size, seq_len, dimension)out[:, -1] torch.Size([1, 512])prob torch.Size([1, 11]) (1, vocab_size)
"""
2.3 Beam(束搜索)
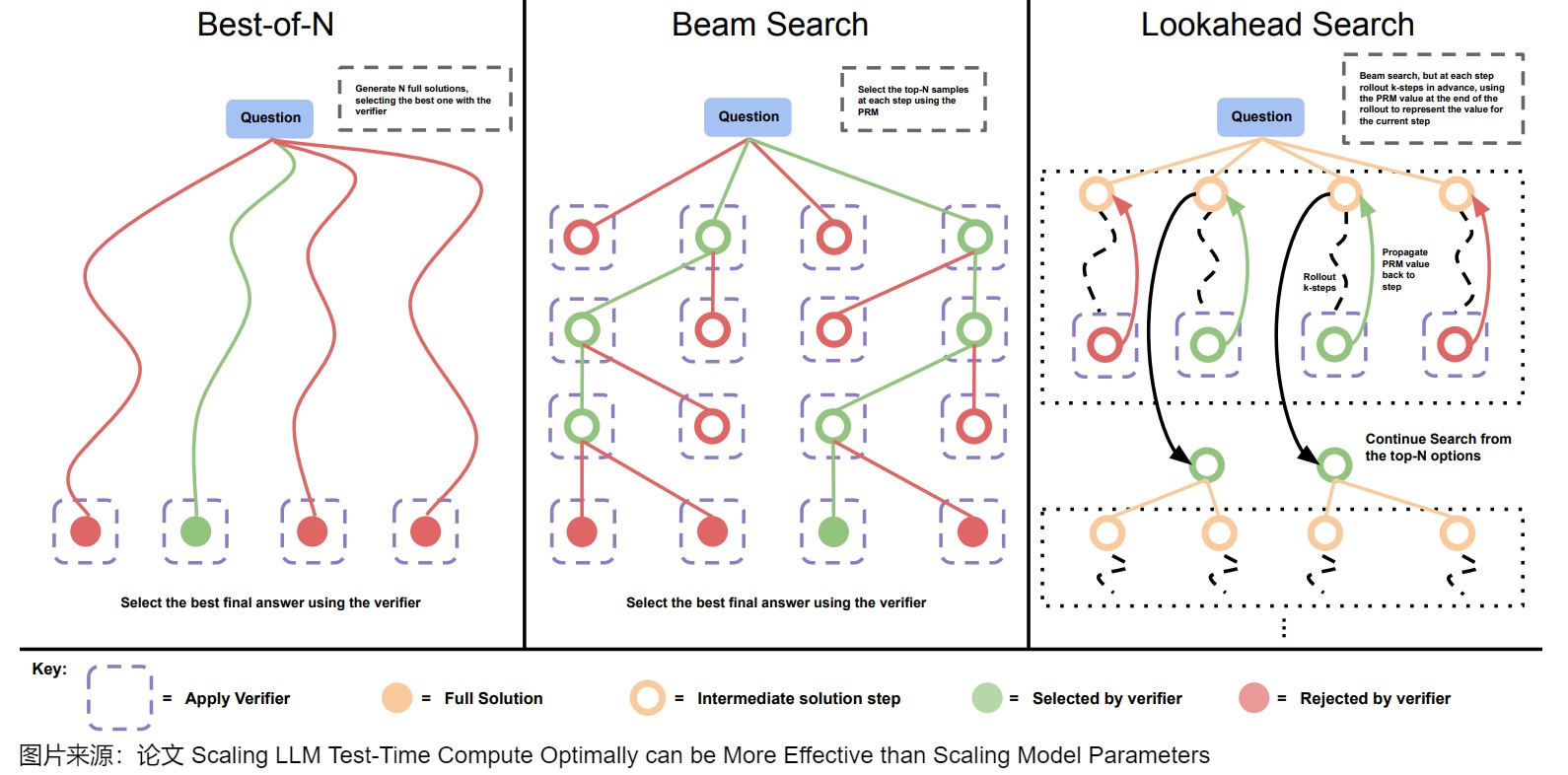
在LLM(大型语言模型)任务如机器翻译中,用户通常期望得到最合适的前𝑘个翻译结果。Beam Search就可以完成这个效果。Beam Search的核心思想是:虽然每一步贪心可能并不是最优解,但是接下来生成的若干个 tokens 连乘起来的概率最大。下图给出了Beam搜索和其它方案的比较。
问题
Beam Search是要解决在实际预测环节如何构造一个理想输出的问题。从概率的视角来看,全局最优输出序列就是指在整个词空间中,使得输出序列联合概率取得最大的词汇的组合。我们先来分析两种极端的着眼方式:
- “放眼全局”的穷举搜索(exhaustive search)。穷举搜索是遍历词序列的所有可能组成并在其中挑选概率最大者,因此可以得到全局最优输出。穷举搜索看的是联合分布表示的全局最优,可谓“不计一城一地之得失”。
- “只看眼前”的贪心搜索。贪心搜索在进行第 t 步预测时,以 t−1 步得到具有最大概率的预测词汇作为输入。
这两种方法都有严重的问题,穷举搜索计算量太大,无法实际使用,而贪心搜索“目光短浅”,容易产生误差的累积。既然两个极端方法都有问题,那么只能采取一些折中手段,集束搜索(beam search)就是其中的典型算法。
思路
Beam Search 是 Greedy Search 的改进版本,其不再是每次都取得分最大的 Token,而是始终保留 beam_size 个得分最大的序列。在第t 步的词预测中,beam search既不像穷举搜索那样用到全部词的组合,也不像贪心搜索那样只用到前面最大的那个预测词汇,而是用到上一步概率值排在前 k 个的词预测作为当前步骤的输入,这里的参数 k 被称为beam width(集束宽度)或者beam size,该参数决定每一步保留的最顶尖的候选序列数量。beam search就是在一个窗口长度的 scope 下使用贪心算法,优化的是每个分支从0到时间步t的log probability。vanilla Transformer使用的就是beam search,在Transformer中,对集束宽度的设置为4。
其实beam search和人类解决问题的思考方式类似。因为自然语言中充斥着模糊性,我们在时刻t无法得知足够的信息来做出选择。所以在日常交流的过程中我们的大脑就不做出选择,先保留时刻t的语言模糊性,等到积累了足够的上下文信息后,我们再返回来t时刻进行决择(进行去模糊化操作)。
与 greedy search 类似,虽然 beam search 保留了多个序列,但最终输出时还是返回的得分最大的序列,因此对于同一个输入,使用 beam search,多次运行模型最终的输出依然是固定不变的。

在Beam search中,解码器在 t 时刻因为对解码结果的不同解读产生不同的时间线分叉。在每个分叉中,我们使用不同的词向量作为 t+1 时刻的解码器输入。 然后我们可以将解码器继续“分叉”,在不同的假设上继续推理并在未来回溯至该时刻进行选择。当解码器所有的分支都结束输出以后,我们可以对每一个分支输出的序列进行评估并在其中选择最优的序列。
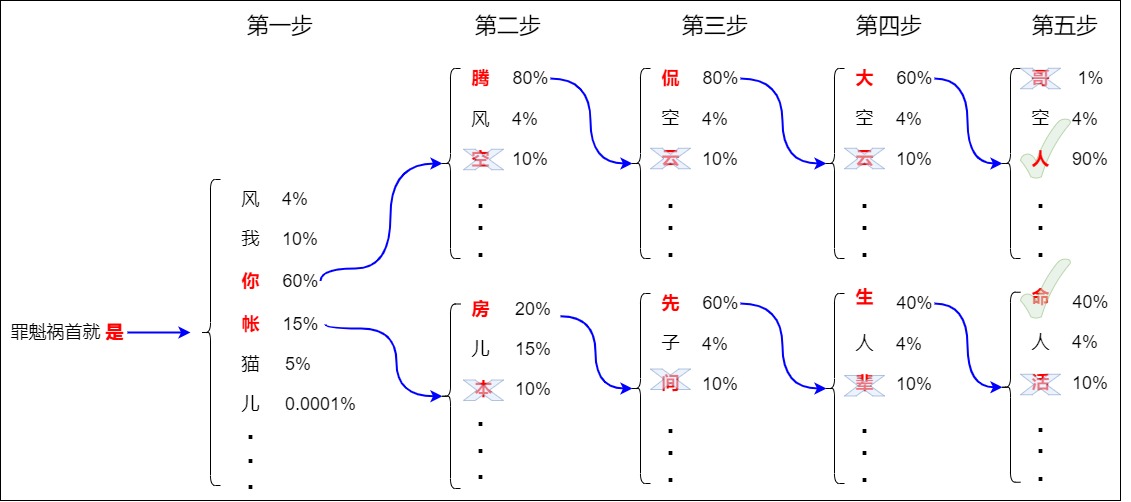
如下图所示,假设 beam_size 为 2,也就是始终保留两个得分最大的序列。在解码过程中,Beam search会在1 个时间步保留2个最高概率的输出词,然后先根据第一个词计算第2个位置的词的概率分布,再取出第2个位置上2个概率最高的词。对于第3个位置和第4个位置,我们也重复这个过程,但是后续步骤中,计算的是历史预测序列和下一个候选词的联合概率。比如第二步计算的是”你腾“,”你空“,”你风“,”账房“,”帐儿“,”账本“等的联合概率。以此类推,该步骤一直持续到解码到end或者超过最大解码步长为止,最终会形成2条完整候选序列,取其中的联合概率得分最大值即可得到最佳解码序列。另外,第一个 token 是从 V 中选择 k 个概率最大的 token ,剩下的都是从 kV 个候选 token 选择 k 个概率最大的。
最终得到4个序列。从以上 4 个序列中选出概率最高的 2 个保留,由于此时得分最高的 “罪魁祸首就是你腾侃大人” 因为已经生成终止符 Token “EOS”,不会有其他得分更高的序列,所以可以在此终止。
效率
由于 beam search 会同时保留多个序列,因此就更容易得到得分更高的序列,并且 beam_size 越大,获得更高得分的概率越高。
相较于穷举搜索和贪心搜索,Beam Search在计算量和准确性方面进行了平衡,通过限制每一步保留的候选数量来降低完全遍历样本空间的计算复杂度。特别地,当 k=|V| 时,集束搜索就变成了穷举搜索,其中 |V| 为词典大小,而当 k=1 时,集束搜索就退化为贪心搜索。从数据结构角度看,穷举搜索是 |V| 叉树结构,贪心搜索是链表,而集束搜索是 k 叉树结构。令解码步长为T,词表长度为N,束宽为K,则Beam Search的时间复杂度是O(K * N * T),因为在每一个步长T下都需要运算K次推理全部词表长度N,且对N进行排序。
因为每个 step 都需要进行 beam_size 次前向计算,beam search的计算量会比贪心搜索扩大 beam_size 倍。另一方面,LLM 推理中一般都会使用 Key、Value cache,这也就会进一步增大 Key、Value cache 的内存占用,同时增加了 Key、Value cache 管理的复杂度。另外,Beam Search也不能保证找到最可能的序列,特别是如果束宽度‘k’与词汇表的大小相比太小。这也就是在 LLM 推理中为什么比较少使用 beam search。
杂项
我们接下来针对Beam Search做进一步讨论。
惩罚
解码的目标是获得联合概率P最大的单词序列。该公式是一个概率累乘,数值是一个负数,序列越长联合概率越小,该数值就越接近0,因此为了方便计算避免出错,在具体操作中,会采用log将概率的累乘改为负数的累加。但是又有一个新问题:在采用对数似然作为得分函数时,Beam Search 通常会倾向于更短的序列。这是因为对数似然是负数,随着解码文本长度的增加,序列的得分也在不断变得越来越负,因此算法会给短文本结果更高的得分,导致一个更合理的翻译结果因为文本较长被一个不合理的短文本结果淘汰。
Beam Search可以采用基于文本长度的惩罚项来解决这个问题,目的是使得长文本的得分不要那么得负。比如可以使用基于“n-gram 惩罚”的技术。这种技术确保任何给定的 n-gram 只出现一次:一个 n-gram 序列会被生成放入序列中,如果该 n-gram 已经在序列中存在,则其概率被设置为零。
论文“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”提出把对数似然、length normalization(对长度进行归一化) 和 coverage penalty 结合在一起构建新的得分函数来解决这一问题,具体如下面的公式所示,其中 lp 是 length normalization,cp 是 coverage penalty。coverage penalty 主要用于使用 Attention 的场合,通过 coverage penalty 可以让 Decoder 均匀地关注于输入序列 x 的每一个 token,防止一些 token 获得过多的 Attention。
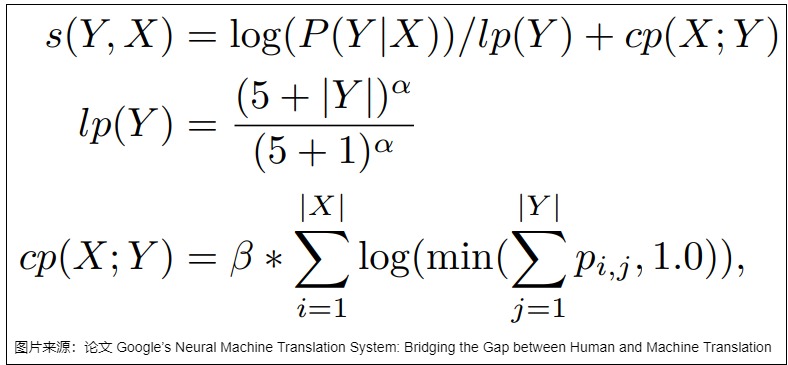
停止
Beam Search单条候选序列停止条件细分有两种情况,分别是
- 候选序列解码到
停止。具体而言是对于单条翻译文本的单个候选序列解码到 停止,此时若其他候选序列还没有解码到 ,则不影响其他候选序列继续寻找。 - 早停,候选序列得分已经低于已解码完的当前最优序列。由于解码长度越大,序列得分越小,如果都等到所有候选都解码到
,则最终的解码结果集合会很大。既然很多得分很小的结果是没有必要的,应该有这么一种情况当解码到某个单词的时候,已经可以断定不需要再继续以此为基础继续搜索了。Beam Search引入早停机制来实现这个效果。早停的机制是比较当前得分和已经全部解码完的序列的得分,如果当前得分远远小于最优路径得分,则执行早停,通过给最大得分乘以α倍来控制这个远远小于的程度。
至此讨论的都是某条候选序列停止条件,什么时候整个待翻译文本结束搜索呢?答案是当前一个步下可用的候选为0的时候,该样本的Beam Search结束。如果是一个批次下好多文本输入给Transformer,则所有样本并行构造自身的候选,待所有样本的都已经没有可用的候选时候,整个批次文本的Beam Search解码停止。
优化
针对Beam Search有很多优化方案,这里给出一个方案让大家学习下。论文"Best-First Beam Search"作者给出了一种通用的 Beam Search 伪代码,伪代码包括 4 种可替换的关键成分。传统的 Beam Search、Best-First Beam Search 和 A* Beam Search 都可以通过修改伪代码的可替换成分得到。

另外,在自回归模型的推理过程中,使用波束搜索时,TopK 操作通常跟随在 Softmax 之后,而 TopK 不需要计算所有 \(y_i\) 值。这使得性能可以获得更大的提升。
TopK 至少需要读取输入向量的每个元素一次。如果分别运行safe Softmax 和 TopK,则每个输入元素需要进行 5 次内存访问,如果使用online Softmax 而非safe Softmax(但仍然分别依次运行),则需要 4 次内存访问。我们可以通过 Softmax + TopK 融合运行,实现每个输入向量元素只进行一次内存访问。
即在softmax算法中,不仅在遍历输入向量时保持最大值 𝑚 和归一化项 𝑑 的运行,还保存 TopK 输入值 𝑢 和它们的索引 𝑝 的向量。

2.4 top-k
从上面的介绍可以看出,不管是 greedy search,还是 beam search,对于固定输入,模型的输出是固定不变的,这就显得比较单调,为了增加模型输出的多样性,人们提出了 top-k 采样策略。
top-k不像 greedy search 那样每次取分数最高的,而是选取概率前 TopK 的样本作为候选项,也就是每一步都保留有 K 个候选项,token从这个受限的池中选择,这样能在一定程度上保证全局最优。因为Top-K 采样用top-k个样本的分数作为权重进行随机采样来得到下一个 Token。这也就引入了随机性,允许概率较高但非最高的 token 也有机会被选择,所以也可解决模型生成多样性的问题,并且K越大多样性越丰富。
top-k的特点如下:
- 根据下一个token的输出概率分布,从大到小排序选出前k个。为了避免采样出过低概率token,采样候选数k始终保持不变。
- 将这k个token重新做概率归一化,按新的分布采样输出token。
- 如果 top_k = 1,则top k算法退化为贪心解码。
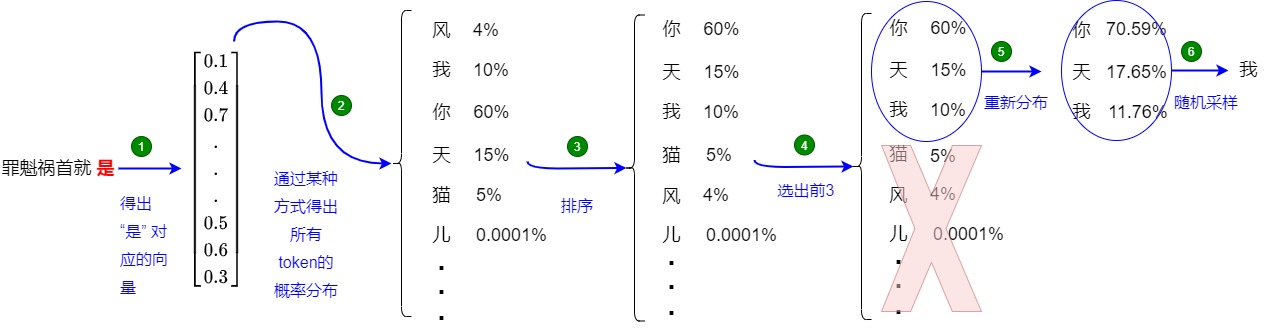
还是以上面的例子来介绍,如上图所示(假设 k = 3),top-k的每一步又可以分为两个步骤:
- 确定候选集:
- 使用最后一个 Token “是” 对应的新生成的 embedding 来计算相似性得分(logits)。
- 使用softmax对logits进行处理,得到概率,每个单词(或 token)都有一个概率。
- 选出概率最高的 3 个 Token:[“你”、“天”、“我”],对应的权重为:[0.6, 0.15, 0.1]。
- 从候选集中采样:使用该权重进行随机采样,获得新 Token “天”。
top-k 里面有一个比较难的问题就是如何选择K才能保证全局最优。对于概率分布比较均匀的分布来说(对于下一个词,有很多同样好的选项),比如每个数的概率都是1/n,这时候top-k 里面K应该选择比较大的数,因为这时候从准确度来说,每一个都是一样的,应该选择比较大的K来增加diversity。反之,如果概率分布极其不均匀,比如最大的概率是0.95,那这时候如果就需要选择比较小的K,因为除了概率最大的数能够保证准确度之外其它的都不行。而在其它上下文中,一些token主导了概率分布。一个小 k 可能会导致通用文本,一个大 k 可能包括不合适的词候选。
2.5 top-p
top-p 采样(也称为核采样,Nucleus Sampling),与 top-k 采样类似,但在候选 token 集的选择方式上有所不同。top-k采用的是选择概率最高的k个词汇,而top-p 采样不是限制为固定数量的 token(K),而是动态选择概率累积值超过预设阈值 P(例如 0.9)的 token 集。
论文”The Curious Case of Neural Text Generation“提出了 top-p 采样。在 top-k 中,每次都是从 k 个 Token 中采样,但是难免会出现一些特殊的 case,比如某一个 Token 的分数非常高,其他分数都很低,此时仍旧会有一定的概率采样到那些分数非常低的 Token,导致生成输出质量变差。此时,如果 k 是可变的,那么就可以过滤掉分数很低的 Token。为了平衡生成文本的多样性和质量,在top-p中,在每一步生成 next_token 时,都从累积概率超过阈值 p 的tokens 集合中进行随机采样,即算法不是选择最可能的 K 个词,而是选择组合概率超过阈值 p的最小词集。
top-p的特点如下:
- 对模型在当前时间步生成的所有词汇的概率进行降序排序。
- 在排序后的词汇中,以从概率最大的到概率最小的顺序进行选择(同时将概率从大到小累加),直到选择的数对应的概率和大于等于p就停止。然后选择这个最小token集合,记为 V_p。例如,若 p=0.9,则选择前几个词,使其概率之和至少为 0.9。
- 只从累积概率超过某个阈值p的token集合中进行随机采样,不考虑其它低概率的token。这样,每次候选的 Token 个数都会因为 Token 分数的分布不同而不一样。因为采样候选数动态变化,这样可以避免采样出过低概率token。
- 将这些token重新做概率归一化,按新的分布随机采样输出token。
- top-p 采样方法可以动态调整候选词的数量,避免了固定数量候选词可能带来的问题。
- top-p 越小,则过滤掉的小概率 token 越多,采样时的可选项目就越少,生成结果的多样性也就越小。
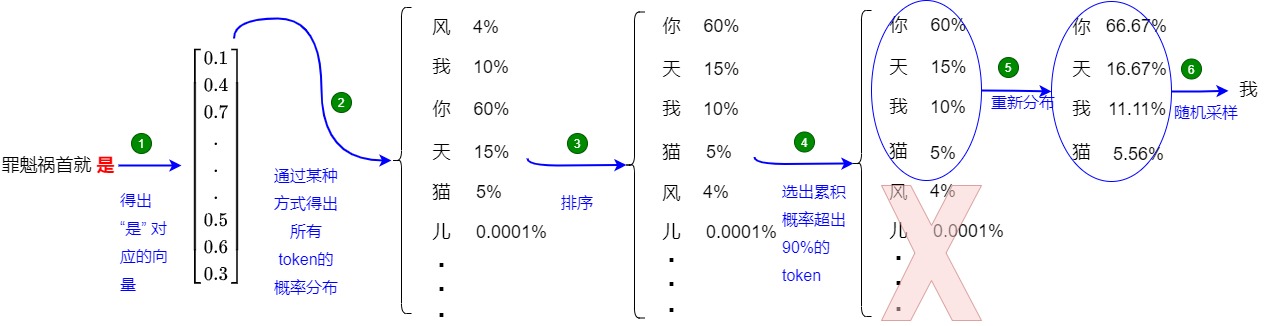
还是以上面的例子来介绍,如上图所示(假设 p = 0.85),top-p可以分为两个步骤:
- 确定候选集:
- 使用最后一个 Token “是” 对应的新生成的 embedding 来计算相似性得分(logits)。
- 使用softmax对logits进行处理,得到概率,每个单词(或 token)都有一个概率。
- 对概率降序排列,逐步累加概率,直到累积概率达到某个阈值,比如0.85。
- 选出累积得分超过 0.85 的 Token:[“我”、“你”、“天”],对应的概率为:[0.1, 0.6, 0.15]。
- 从候选集中采样:把候选集中的概率重新归一化,根据归一化后的概率进行随机采样,获得新 Token “天”。
我们选取Llama3的代码来学习。
top_p算法
def sample_top_p(probs, p):"""对概率分布进行 top-p (nucleus) 采样Args:probs (torch.Tensor): 概率分布张量,形状是(batch_size, vocab_size).p (float): 用于 top-p 采样的概率阈值Returns:torch.Tensor: 采样后的 token 索引,形状是 (batch_size, 1)Note:Top-p 采样首先获取累积概率超过阈值p的最小 token 集合。然后据选定的 token 重新规范化概率分布.该方法之所以可以控制生成的随机性, 是因为通过设置阈值p就可以控制采样得到的 token 集合中小权重 token 的数量.- 当 p 趋近 1 时, 采样的集合中会有更多小权重的 token, 生成的文本更加随机.- 当 p 趋近 0 时, 仅有权重较大的 token 被采样, 生成的文本更加确定. """# 对概率进行降序排序. 降序是因为要按概率从大到小选择 token 集合.# 假如probs是torch.tensor([0.1,0.2,0.3,0.25,0.15])# probs_sort里面是排序后的概率,形状和probs相同:[0.3000, 0.2500, 0.2000, 0.1500, 0.1000]# probs_idx是排序后的索引,用于映射回原始词汇表probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)# 计算累积概率. 这是为了后续快速做差分然后判断 token 是否在 top-p 集合中.# probs_sum里面是累积到当前的概率和[0.3000, 0.5500, 0.7500, 0.9000, 1.0000]probs_sum = torch.cumsum(probs_sort, dim=-1)# 创建一个掩码, 排除累积概率超过阈值 p 的部分, 所以需要减去当前概率判断是否已经超过阈值.# 假如p是0.8,mask是[False, False, False, False, True]mask = probs_sum - probs_sort > p# 使用掩码将超过阈值的 tokens 概率设置为 0.# probs_sorts是[0.3000, 0.2500, 0.2000, 0.1500, 0.0000]probs_sort[mask] = 0.0# 对筛选后的概率重新做归一化,确保总和为1。div_方法将规范化后的概率分布保存在 probs_sort 中.# probs_sort是[0.3333, 0.2778, 0.2222, 0.1667, 0.0000]probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))# 从规范化的后的概率分布中采样一个 token.# 用多项式采样,得到排序后的索引。probs_sort中概率大的元素被采样的几率就大# torch.multinomial基于输入的概率权重进行采样next_token = torch.multinomial(probs_sort, num_samples=1)# 根据采样的索引probs_idx映射回原始词汇表索引# torch.gather函数按照给定的索引张量index,从输入张量中收集 (获取) 数据,并返回一个与索引张量形状一致的张量next_token = torch.gather(probs_idx, -1, next_token)# 返回采样得到的 token 索引.return next_token
如何调用
torch.inference_mode()
ef generate(self,prompt_tokens: List[List[int]],max_gen_len: int,temperature: float = 0.6,top_p: float = 0.9,logprobs: bool = False,echo: bool = False,-> Tuple[List[List[int]], Optional[List[List[float]]]]:"""Generate text sequences based on provided prompts using the language generation model.Args:prompt_tokens (List[List[int]]): List of tokenized prompts, where each prompt is represented as a list of integers.max_gen_len (int): Maximum length of the generated text sequence.temperature (float, optional): Temperature value for controlling randomness in sampling. Defaults to 0.6.top_p (float, optional): Top-p probability threshold for nucleus sampling. Defaults to 0.9.logprobs (bool, optional): Flag indicating whether to compute token log probabilities. Defaults to False.echo (bool, optional): Flag indicating whether to include prompt tokens in the generated output. Defaults to False.Returns:Tuple[List[List[int]], Optional[List[List[float]]]]: A tuple containing generated token sequences and, if logprobs is True, corresponding token log probabilities.Note:This method uses the provided prompts as a basis for generating text. It employs nucleus sampling to produce text with controlled randomness.If logprobs is True, token log probabilities are computed for each generated token."""params = self.model.paramsbsz = len(prompt_tokens)min_prompt_len = min(len(t) for t in prompt_tokens)max_prompt_len = max(len(t) for t in prompt_tokens)total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)pad_id = self.tokenizer.pad_idtokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")for k, t in enumerate(prompt_tokens):tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")if logprobs:token_logprobs = torch.zeros_like(tokens, dtype=torch.float)prev_pos = 0eos_reached = torch.tensor([False] * bsz, device="cuda")input_text_mask = tokens != pad_idif min_prompt_len == total_len:logits = self.model.forward(tokens, prev_pos)token_logprobs = -F.cross_entropy(input=logits.transpose(1, 2),target=tokens,reduction="none",ignore_index=pad_id,)stop_tokens = torch.tensor(list(self.tokenizer.stop_tokens))for cur_pos in range(min_prompt_len, total_len):logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)if temperature > 0:probs = torch.softmax(logits[:, -1] / temperature, dim=-1)next_token = sample_top_p(probs, top_p)else:next_token = torch.argmax(logits[:, -1], dim=-1)next_token = next_token.reshape(-1)# only replace token if prompt has already been generatednext_token = torch.where(input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token)tokens[:, cur_pos] = next_tokenif logprobs:token_logprobs[:, prev_pos + 1 : cur_pos + 1] = -F.cross_entropy(input=logits.transpose(1, 2),target=tokens[:, prev_pos + 1 : cur_pos + 1],reduction="none",ignore_index=pad_id,)eos_reached |= (~input_text_mask[:, cur_pos]) & (torch.isin(next_token, stop_tokens))prev_pos = cur_posif all(eos_reached):breakif logprobs:token_logprobs = token_logprobs.tolist()out_tokens, out_logprobs = [], []for i, toks in enumerate(tokens.tolist()):# cut to max gen lenstart = 0 if echo else len(prompt_tokens[i])toks = toks[start : len(prompt_tokens[i]) + max_gen_len]probs = Noneif logprobs:probs = token_logprobs[i][start : len(prompt_tokens[i]) + max_gen_len]# cut to after eos tok if anyfor stop_token in self.tokenizer.stop_tokens:try:eos_idx = toks.index(stop_token)toks = toks[:eos_idx]probs = probs[:eos_idx] if logprobs else Noneexcept ValueError:passout_tokens.append(toks)out_logprobs.append(probs)return (out_tokens, out_logprobs if logprobs else None)
top-p解决了top-p面临的难题。这种动态方法提供了更大的灵活性,因为候选 token 的数量可以根据生成的上下文而变化。通过调整阈值 P,模型可以控制每一步中被考虑的 token 数量,从而在生成输出的多样性和连贯性之间取得平衡。对于固定的p,在最极端的均匀分布的时候,可以取到更多的点;对于分布极其不均匀的时候,top-p只会取到概率最大的一个或者几个值,避免了错误的引入。当然,top-p里面的p如何选择,依然是一个需要考虑的事情。p值减小容易减小diversity,p值增大容易引入更多的小概率token,无论p怎么选,也都有可能把概率值很少的概率取到候选集合。为了解决这个问题,人们引入了temperature调节的机制。
另外,虽然从理论上讲,top_p 似乎比 top_k 更优雅,但这两种方法在实践中都很好用。top_p 也可以与 top_k 结合使用(当结合使用时,token 集首先被限制为 K 个候选,然后进一步缩小到满足概率累积阈值 P 的 token),这可以避免分数非常低的 Token,同时提供一些动态选择的空间。
2.6 性能
有研究人员对比单独应用每种采样方法的结果,结果发现 Top-K 的开销最大,其次是 Top-P,而重复惩罚的开销最小。值得注意的是,与 Top-K 和 Top-P 采样相比,重复惩罚的开销较低,因为前两者需要排序算法。
另外,在计算受限的情况下,采样技术的额外计算开销更加显著。例如高请求速率、解码任务较重的数据集或较大的批量大小。在此类情况下,需谨慎考虑采样开销。
当请求速率较低时,采样几乎没有导致性能下降。这是因为请求速率增加时,工作负载变得更偏向计算受限。较高的请求速率导致更大的运行批量大小(running batch size),以及更高的操作密度。
0x03 采样参数
常见的采样参数如下所示,不同模型可能有不同的参数和阈值。
| 参数 | 默认值 | 含义 |
|---|---|---|
| top_p | 0.95 | top-p概率阈值。如果top_p小于1,则从高到低累加直到top_p,取这前N个词作为候选 |
| top_k | 50 | 保留前K个结果词作为候选 |
| repetition_penalty | 1.0 | 重复处罚的参数。1.0意味着没有惩罚。 |
| temperature | 1.0 | 用于控制生成语言模型中生成文本的随机性和创造性的温度值,越小意味着选择最有可能的词的概率更高。相同的输入更可能出现相同的输出。而值越大,则出现其他结果的可能性越高。 |
3.1 temperature
概念
虽然 Softmax 可以得到一个分布,但同时也有其缺点:容易扩大/缩小内部元素的差异(退化成 max / mean)。即,对于一些数值上相近的向量数值,概率却相差很大。例如对”The boy _ to the market.“进行预测,可能的答案为有 [goes,go,went,comes],假设分类器的输出数值为 [38,20,40,39],则通过上述公式求得其 Softmax 结果为:[0.09, 0.00, 0.6, 0.24]。如果依据该分布采样,60% 的可能为 went,但填空的答案根据上下文也可能是 goes 和 comes。分类器的 words 的初始值是比较接近的,但 Softmax值却会将差距拉得很开。
参数Temperature便是用来解决这个问题,其用于调节 Softmax,让其分布进一步符合我们的预期,进而控制LLM的生成结果的可信度、随机性、创造性和多样性。为什么叫 temperature 呢?我们知道:温度越高,布朗运动越剧烈;同理,temperature 越高,采样得到的结果越随机,生成的内容多样性就会越大。
从数学上来说,设置温度是一个非常简单的操作,temperature就是对每个词的概率分布进行softmax处理时候的温度系数。模型输出 logits 只需除以 temperature即可。具体公式如下图所示。\(z_i\) 是第i个logit。
T会放大logits之间的差异。T设置得越高,生成的结果越随机,输出分布就越平滑。T越小,随机性越弱,输出分布越陡峭。
- T < 1:较低的温度通过锐化概率分布使模型更加自信和确定性,从而产生更可预测的输出。当T→0的时候,极致放大贫富差距,让最大值的元素概率趋向1,其他变成0,此时信息熵为0,softmax的效果和argmax差不多。
- 当 T=1 时,将 logits 除以 1 对 softmax 输出没有影响,输出分布将与标准 softmax 输出相同。
- T > 1:较高的温度会使概率分布更平滑,模型更有可能选择概率较低的 token。这可以生成更具创意和多样化的文本,但也增加了生成不连贯结果的风险。当T→∞的时候会极致缩小贫富差距,让把所有输出概率都趋于一样的值,分布变成均匀分布,就是完全随机,此时信息熵是最大的。有些人称“较高的温度”为模型的“创造力”。
应用代码如下所示:
# logits 是LLM的推理输出, 形状为 [batch_size, seq_len, vocab_size]
# logits[:, -1]表示选择的是最后一个token(seq_len 维度的最后一项)对应的logits,形状为[batch_size, vocab_size]
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
我们还需要对当温度=0时的行为做一些特殊分析。
当温度=0时,模型执行贪婪解码(greedy decoding):它在每一步总是选择概率最高的下一个标记,本质上是预测概率分布中的argmax选择。理论上,贪婪解码应该消除生成过程中的随机性。如果模型和输入固定,每次生成的标记序列应该是相同的。然而,将温度设置为零并不能在实践中保证100%的确定性。比如,如果两个或多个下一个标记选项具有(几乎)相同的最高概率,模型或解码库可能会以任意方式打破平局。这种情况很少见,但可能发生。在这种情况下,即使温度=0,标记之间的选择也可能是非确定性的。另外,现代LLM架构和硬件行为也会引入一定的变异性。比如,专家混合模型架构的复杂性(容量限制和批处理竞争都会造成输出不一致)、并行硬件上浮点运算的微妙之处以及其他实现细节意味着,即使没有任何“随机性”参数,对同一模型的相同提示的两次调用偶尔也会产生分歧。
动态温度系数
vanilla Transformer的温度参数是静态的,我们接下来看看在LLM解码过程中动态调整温度的思路。
KL-Divergence Guided Temperature Sampling
论文"KL-Divergence Guided Temperature Sampling作者提出了一种基于KL散度的方法调整温度的思路。KL散度用于衡量两个分布的统计距离。论文的出发点是根据当前token和prompt的关联性来调整这次解码的T。具体来说,作者又额外引入一个LLM参与解码,它的输入不包括prompt,也含有\(x_{<t}\)(已经解码出来的response前缀)。
两个模型同时运行,然后计算原LLM logit和引入LLM logit的KL散度,再依据KL散度来计算temperature。两个分布越相似,那么值越接近0,反之就会越接近0。物理含义是:对prompt来说,下一个token解码是否重要。
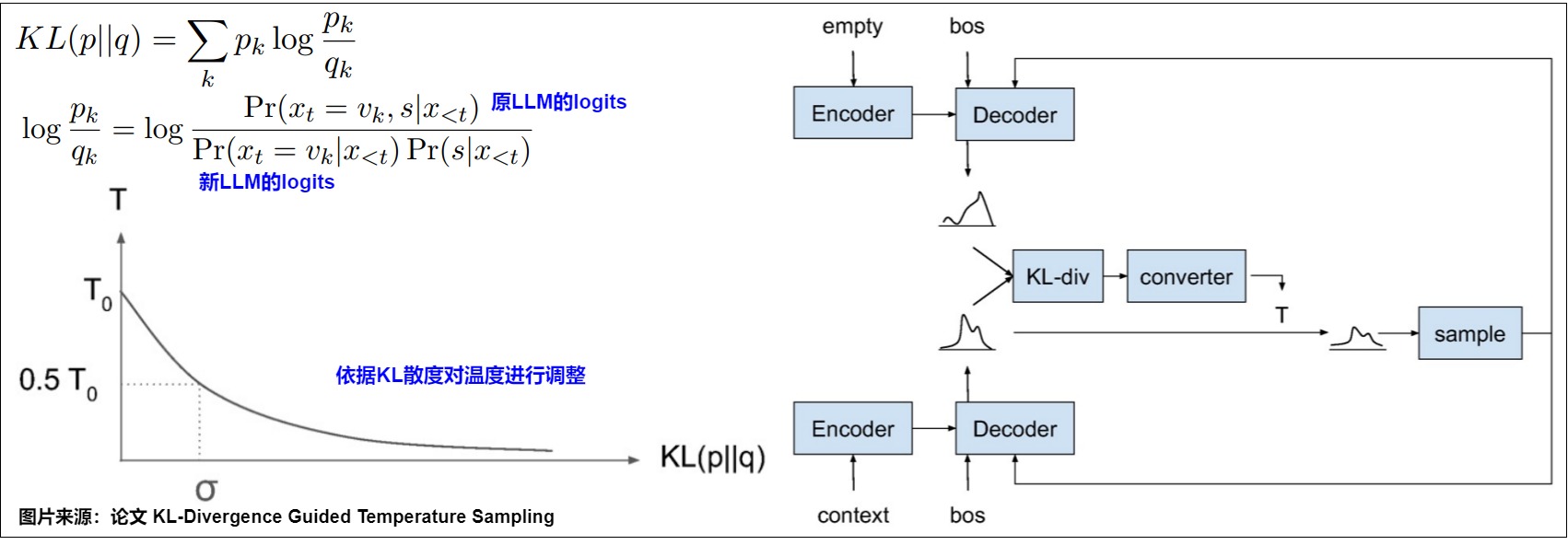
但是这种方法的缺点很明显,需要额外一个LLM,会使用两倍的显存和计算量,对于大模型来说,这是一个非常大的开销。从效率来看基本不可接受。
Hot or Cold
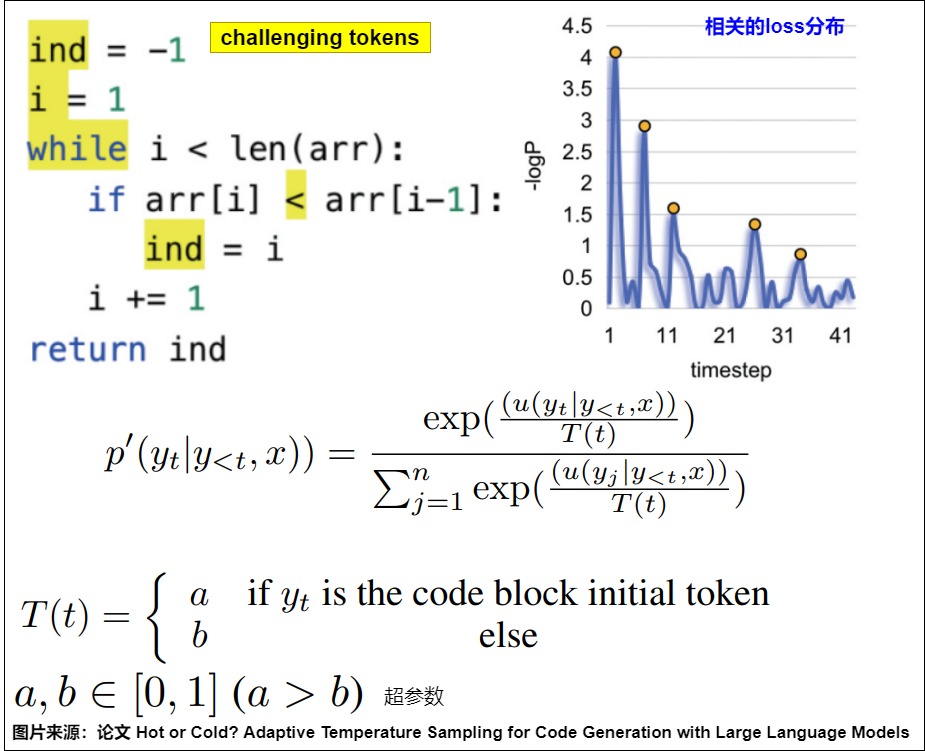
论文"Hot or Cold? Adaptive Temperature Sampling for Code Generation with Large Language Models"提出了一种相当简单的方法,论文在代码生成任务中,把token分为challenging(损失高)和confident两类,前者对于LLM来说难以预测,所以需要更大的让LLM做更多的探索,下图就是判断token是否challenging以及调整T的规则。此方案相对简单,因为是完全基于规则来调节。
EDT
论文”EDT(Entropy-based Dynamic Temperature“通过使用熵来动态计算temperature。一个”n个状态(n-state)“系统的熵定义如下,其中\(p_i\)是第i个事件发生的概率。
论文用logit的熵衡量LLM对下一个token的confident。
- 熵越大代表大模型对于本轮生成的token越不置信,极端情况是每个token的logit值相同。在大模型本身对于生成哪个token都没有把握的时候,我们应该让系统增加多样性,也就是应该使用一个大的temperature去做探索;
- 熵越小代表大模型对于本轮应该生成的token越肯定。大模型对于本轮应该生成哪个token非常置信的时候,我们应该使用一个小的temperature让系统更加肯定它的选择,同时这么做也可以解决掉一些小概率值被错误选中的问题。
下图是EDT解码过程的示意图。在每个解码步骤中,系统首先获得logits(➀)并生成下一个令牌的概率分布(➁)。然后根据初始概率分布计算所有token的熵(➂)。接下来模型依据熵来选择温度(➃),再依据温度获得新的分布(➄),并对下一个令牌进行采样(➅)。
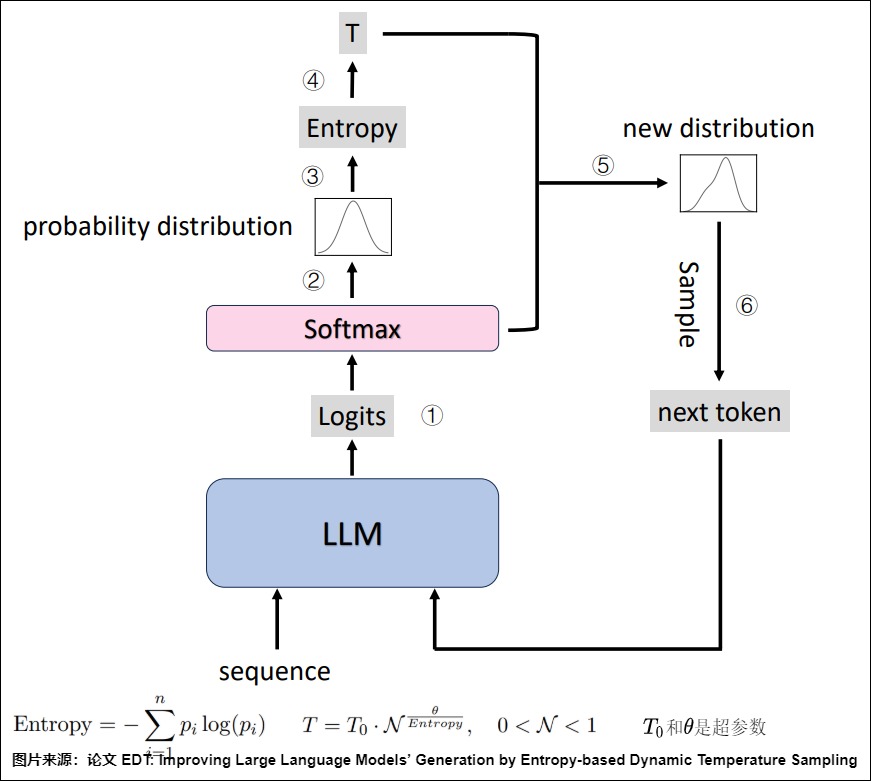
3.2 repetition_penalty
repetition_penalty(重复惩罚)参数用于避免模型一直输出重复的结果,repetition_penalty 越大,出现重复性可能越小,repetition_penalty 越小,出现重复性可能越大。
问题原因
论文"Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation"系统性地研究了LLM为什么会在贪心解码时倾向生成重复句子的问题,并通过定量研究回答了以下提问:
- 为什么会发生句子级的重复?
- 为什么模型会陷入重复循环?
- 什么样的句子更容易被重复?
论文通过分析指出,自我强化效应(Self-Reinforcement Effect)是导致重复的核心问题。模型倾向于生成重复结果的原因可能是:基于最大化的解码算法生成前一句的概率相对较高,且模型倾向于进一步增大该句重复的概率。具体而言,一旦模型生成一个重复句子,则该句之后出现的概率将进一步增加,因为有更多重复共享相同句子级的上下文来支持这个复制的操作。其结果就是,由于自我强化效应,模型陷入了这种句子级重复。我们用输入“I love orange. I love"作为输入来预测下一个token为例。
-
为什么会发生句子级的重复? 由于模型在之前的上下文中已经看到了“I love orange”的模式,因此模型为Pθ('oranges'|'I love oranges . I love')分配的概率高于Pθ('oranges'|'I love')。所以模型可能对之前的上下文重复过于自信,并学习了一种“廉价”的快捷方式,直接复制下一个token “orange”。
-
为什么模型会陷入重复循环? 这个可以从注意力角度来理解。第一次重复的时候,某个token在注意力中的权重为w,这个token在句子中不同位置的表示是相似的。随着前面多次重复出现这个token,那么这个token会在attention weight中多次出现w的权重,相当于增加了这个token的权重。那就更容易重复这个token。
-
什么样的句子更容易被重复?具有高初始句概率\(TP_0\)(average token probability)的句子,具有更强的自我强化效应,而且基于最大化的解码算法生成的句子重复的可能性越大(生成的句子具有更高的初始似然性)。
另外还有一个问题:为什么模型越大,重复却越少?LLM是预测下一个token,而下一个token可以分成几种来讨论:
- true tokens,正确的tokens。
- context tokens,前面出现的tokens。
- random tokens/other,其他tokens。
理想情况下,模型对这三种token的预测概率的大小关系应该是:P(true tokens) > P(context tokens) > P(random tokens)。模型将prefix映射到一个表示空间,对这个表示空间解码来预测下一个token。这个表示空间应该能区分不同语义、解码到对应的正确token;然而存在一种较差的情况:表示空间对不同语义的区分度不够,容易解码到错误的token上。模型能力差、容量小,能表示的空间小,就难以将prefix映射到更好的表示空间并解码到正确的token。也就容易出现P(true tokens) < P(context tokens) ,于是模型开始重复。
参数原理
repetition_penalty参数最早在论文"CTRL: A Conditional Transformer Language Model for Controllable Generation"中被提出,目的是解决语言模型中重复生成的问题。其思路是:记录之前已经生成过的 Token,当预测下一个 Token 时,人为降低已经生成过的 Token 的分数,使其再次被采样到的概率降低(即对在之前步骤中已经被选择的 token 进行惩罚),这样可以平衡文本的连贯性、增加生成的多样性。
如下图所示,直接基于上述带温度系数 T 的 softmax 进行实现,其中的 g 表示已经生成过的 Token 列表,如果某个 Token 已经在生成过的 Token 列表 g 中,则对其对应的温度系数 T 乘上一个系数 θ,θ 为大于 0 的任意值。
- θ=1,表示不进行任何惩罚。
- θ>1,相当于尽量避免重复。用户可以减少退化现象,同时保持句子的连贯性。然而,较高的惩罚可能导致输出的连贯性下降,因为它可能过度惩罚那些对句子结构至关重要的 token。
- θ<1,相当于希望出现重复。
或者说,temperature是对所有token都除以T。repetition_penalty是对已生成的token才除以\(\theta\)。

我们从mnn的代码中来学习下。
int Llm::sample(VARP logits, const std::vector<int>& pre_ids, int offset, int size) {std::unordered_set<int> ids_set(pre_ids.begin(), pre_ids.end());auto scores = (float*)(logits->readMap<float>()) + offset;if (0 == size) {size = logits->getInfo()->size;}// repetition penaltyconst float repetition_penalty = 1.1;for (auto id : ids_set) {float score = scores[id];# 小于0的数会乘以repetition_penalty, 否则是除以repetition_penaltyscores[id] = score < 0 ? score * repetition_penalty : score / repetition_penalty;}// argmaxfloat max_score = scores[0];int token_id = 0;for (int i = 1; i < size; i++) {float score = scores[i];if (score > max_score) {max_score = score;token_id = i;}}return token_id;
}
此外,还有其他方法可以控制重复性输出:频率惩罚(Frequency Penalty)和 存在性惩罚(Presence Penalty)。两者通过从 logits 中减去一定数值来施加惩罚。此外,频率惩罚根据重复次数施加惩罚,而其他方法仅基于 token 是否存在进行惩罚。
0x04 logits分析
Transformer中的token其实是向量在不同维度和不同语义空间的表示,而思考的过程,就是从一个语义空间向另一个语义空间运动的过程。Transformer的最终隐层logits就是最终思考的结果。我们接下来在对logits的性质进行深入分析,也会看看一些基于logits的方案。
4.1 压缩信息
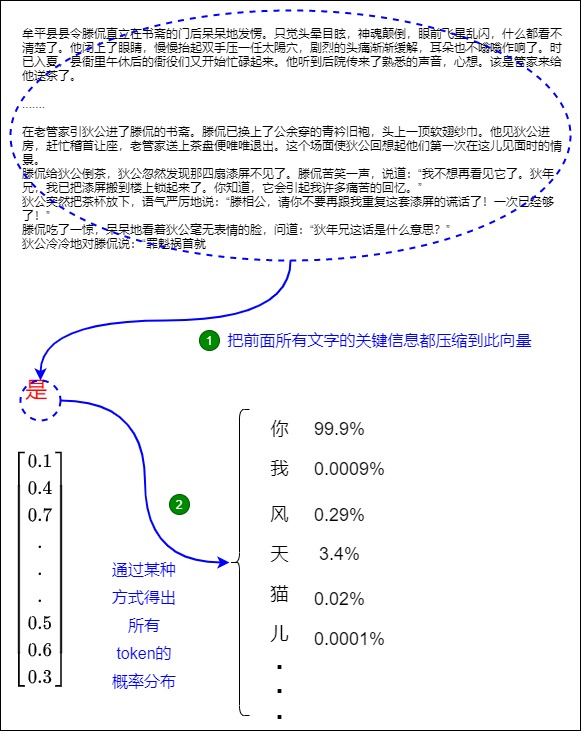
我们先看看为何推理时候只使用最后一个token对应的embedding就可以进行预测下一个token。
示例
我们把《大唐狄公案之四漆屏》的前面部分文字输入到模型:
牟平县县令滕侃直立在书斋的门后呆呆地发愣。只觉头晕目眩,神魂颠倒,眼前飞星乱闪,什么都看不清楚了。他闭上了眼睛,慢慢抬起双手压一任太陽穴,剧烈的头痛渐渐缓解,耳朵也不嗡嗡作响了。时已入夏,县衙里午休后的衙役们又开始忙碌起来。他听到后院传来了熟悉的声音,心想。该是管家来给他送茶了。
.....
在老管家引狄公进了滕侃的书斋。滕侃已换上了公余穿的青衿旧袍,头上一顶软翅纱巾。他见狄公进房,赶忙稽首让座,老管家送上茶盘便唯唯退出。这个场面使狄公回想起他们第一次在这儿见面时的情景。
滕侃给狄公倒茶,狄公忽然发现那四扇漆屏不见了。滕侃苦笑一声,说道:“我不想再看见它了。狄年兄,我已把漆屏搬到楼上锁起来了。你知道,它会引起我许多痛苦的回忆。”
狄公突然把茶杯放下,语气严厉地说:“滕相公,请你不要再跟我重复这套漆屏的谎话了!一次已经够了!”
滕侃吃了一惊,呆呆地看着狄公毫无表情的脸,问道:“狄年兄这话是什么意思?”
我们加入一个新句子:
狄公冷冷地对滕侃说:“罪魁祸首就是”
把上述所有文字输入模型进行预测,则模型大概率会输出:“你”。
分析
处理过程如下。
首先,模型前面对《大唐狄公案之四漆屏》的前面所有文字的处理,得到了一个处理结果。该处理结果被汇聚到”是“这个向量中。”是“这个向量,在训练最初只是从查找表中得到的一个向量,经过训练之后,Transformer把全部文字的所有关键语义都融合到序列的最后一个向量,即“是”。
其次,模型对“是“向量进行操作,得出所有token的概率分布,就是接下来词表中各个token出现的概率。在本例中,我们选择概率最高的单词「你」作为下一个单词。
4.2 变化
论文”How Alignment and Jailbreak Work:Explain LLM Safety through Intermediate Hidden States“指出,语言模型的中间隐藏状态的变化实际上是一个逐层分配特征的过程。即,模型判断输入是否属于“可回答”范畴是在早期的layer中完成的(模型在早期的几个layer之后就为hidden states分配了足以被一个超平面分开的特征),并在中期layer中关联情绪类的浅层猜测,最后细化成对应格式的输出。越狱就是干扰了早期的激活,使得中期的‘猜测关联’发生了变化,并最后导致模型响应有害问题。
4.3 预处理logits
背景和动机
传统的采样策略在推理任务中面临诸多挑战。尤其是,尽管采样方法能够提供多样化的输出,但其在需要精确推理的任务中却经常表现不佳。例如,基于概率的采样方法(如温度缩放、nucleus sampling、top k 采样以及min p 采样等)往往更注重输出的多样性和减少重复,而非推理的准确性。这些技术往往难以有效过滤掉无关的token,从而导致在多样性与推理精度之间产生了一种看似不可避免的权衡。
为了挑战这一传统观念,论文“Top-nσ: Not All Logits Are You Need"提出了top-nσ方法,这是一种全新的采样策略,旨在将统计阈值直接作用于pre-softmax(前softmax)logits。该方法认为,logits自然分布为包含高斯噪声的区域和一个明显的信息区域,这种特点可以在不进行复杂概率运算的情况下也能够高效地过滤出token。与现有方法相比,top-nσ方法即便在高温度下也能保持稳定的采样空间,这一特性使其在推理任务中具有显著优势。
论文主要探寻了三个关键问题:
- 如何从logit空间解释基于概率的采样方法。
- 大语言模型中logit分布的基本特征。
- 如何利用这些分布有效地区分噪声区域和信息区域。
洞察
虽然现有的方法主要侧重于处理概率分布,但该论文认为,检查pre-softmaxl ogits可以揭示对模型生成过程的更深入见解。下图给出了AQuA样本上LLaMA3-8B-Instruct的logits分布和按照降序排序的概率。下图a中的前方(leading)token(概率较高)对应于logits分布的右侧区域。最大logit大约比分布的平均值高10σ。一个有趣的观察结果是,pre-softmax logit分布呈现出高度规则的模式,通常由两个不同的部分组成:背景标记的类高斯分布和一组突出的异常值。尽管大多数标记遵循高斯分布,但异常值尾部(outlier tail )在概率集(mass)中占主导地位(如下图b所示)。我们分别将这些分量称为噪声区域和信息区域。值得注意的是,最大logit与平均值的偏差超过5σ(标准偏差),大大超过了异常值识别的典型统计标准。
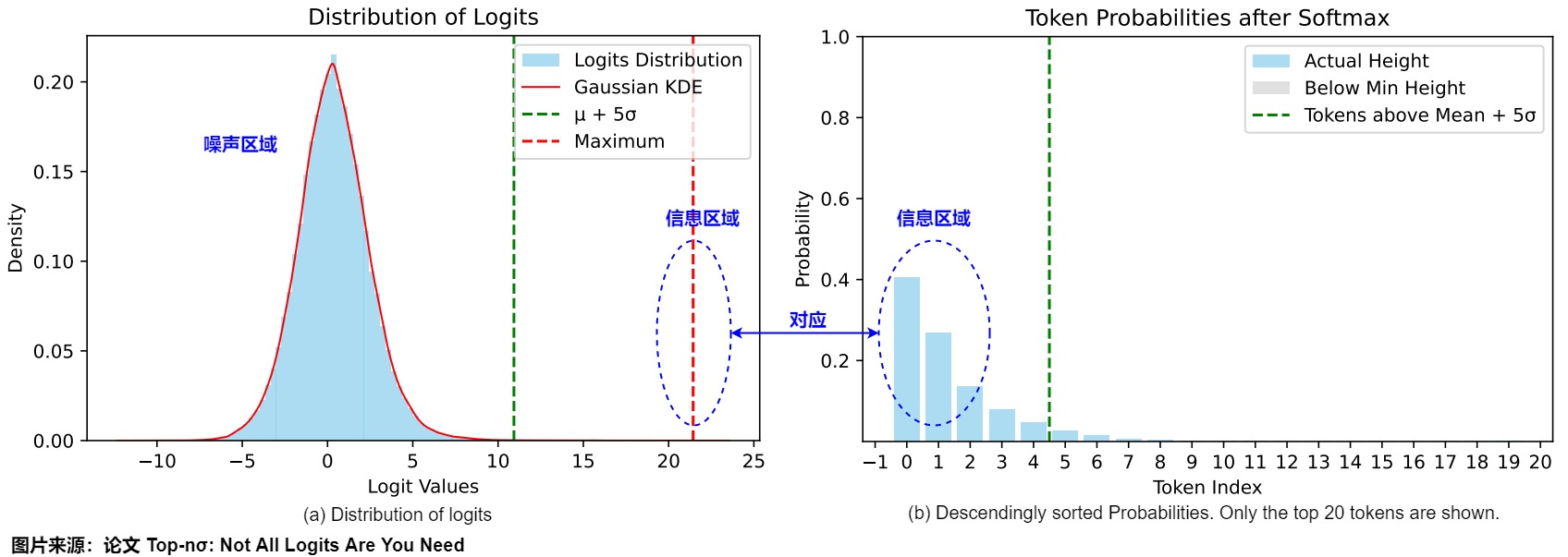
噪声区域
尽管logits确实显示出噪声分布的特征,但大多数token的logits通常表现出高斯分布。当这些logits对应于的概率通常被认为是可以忽略的(negligible),它们被归类为噪声区域。此噪声区域的特征符合统计直觉:高斯分布通常指示系统中的随机噪声存在。
正如上图所示,当噪声区域与信息区域之间的边界越来越窄时,由噪声带来的概率干扰会影响模型生成的质量,尤其在高温采样情境下尤为明显。过高的温度导致当前非确定性采样算法的表现下降,主要原因在于噪声分布主导了概率空间。
信息区域
相反,只有少量token占据了大多数概率集的区域被称为信息区域。正如上图所示,尽管该区域中的token数量有限,但其承载非常多的信息。
这种现象可以被min 𝑝采样方法所利用,带来生成质量方面的改善,这种方法设定了基线概率阈值𝑝,并消除了所有低于\(𝑝_{𝑚𝑎𝑥}⋅𝑝\)的概率值。通过理论推导,我们发现min 𝑝采样本质上是logit空间中的一种静态截断,这进一步指出信息区域近似遵循均匀分布。
核心思路
确定边界
为了有效地区分信息和噪声区域,论文提出可以将信息区域视为噪声分布的异常值。然而,基于实证观察,传统的基于𝜇+3𝜎规则的方法并不适合此任务。因此论文提出了𝜎-distance的概念,它定义为最大概率和分布均值之间的标准差间隔,如下所示:
通过分析,论文作者发现最大概率与均值之间的距离始终大于10𝜎,而且生成过程中表现出显著波动。这一发现表明,信息token并不应被视为噪声token的异常值。相反,更高的𝜎-distance表明模型对生成结果的强置信度。
总结下,我们应该消除噪声区域中的token,保留明显(distinct)信息区域中的token。为此,论文文提出的top-𝑛𝜎算法从最大概率开始向下扩展,并使用标准差动态调整边界,以有效区分信息token和噪声token。
算法
top-nσ算法的核心思想是从logits的最大值开始,结合标准差来确定分界线,从而有效地区分信号tokens和噪声tokens。具体步骤如下:
-
生成logits:给定输入序列,模型首先生成logit向量 \(( l = (l_1, l_2, \ldots, l_V) \in \mathbb{R}^V )\),其中 ( V ) 为词汇表大小。
-
计算最大值和标准差。
-
确定筛选阈值:算法从最大值往下进行扩展\(n\sigma\),参数n通常取1.0。因此阈值为:$ [ M - n\sigma ]$。
-
过滤候选tokens:选择所有满足以下条件的tokens: $[ l'_i \geq M - n\sigma ] $。该条件确保根据logits的统计特性来仅选择具有较高信息量的tokens。
-
进行采样:从筛选出的tokens中随机选择,进行文本生成。

4.2 隐式思维链
我们接下来看看让大模型在隐空间中思考的思路。
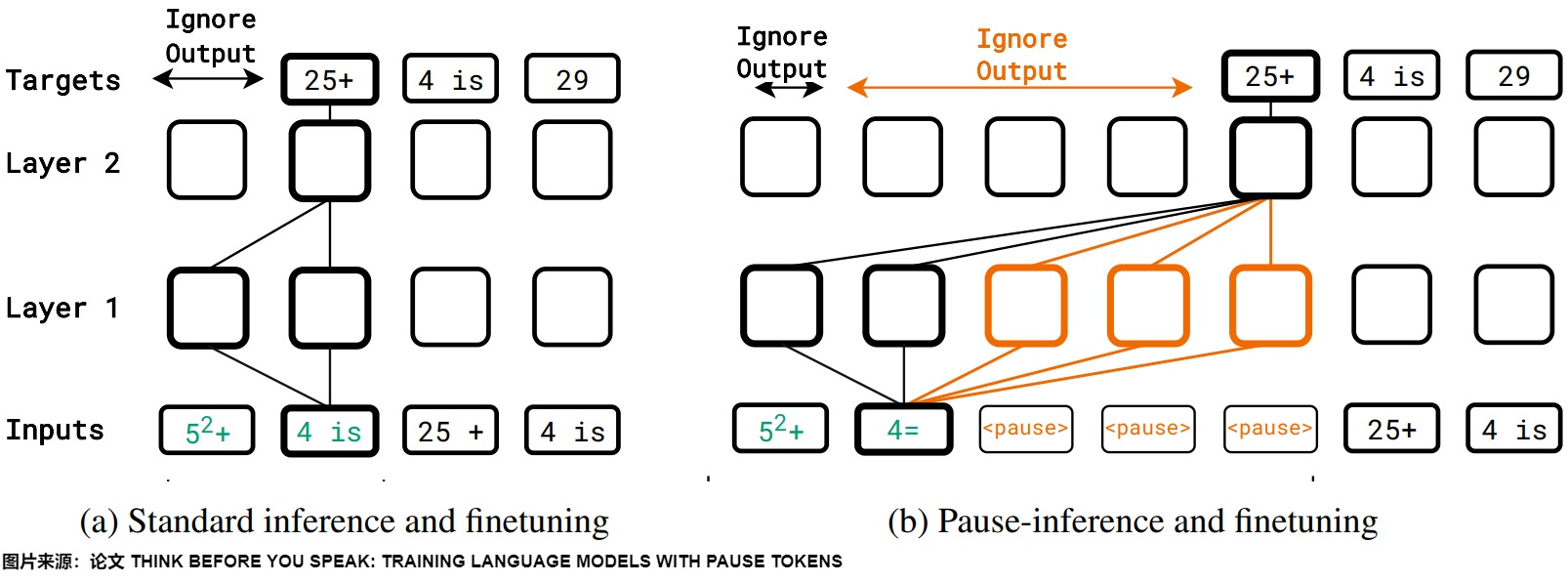
pause tokens/Filler Token
论文"Think before you speak: Training language models with pause tokens "提出了一种独特的方法,通过引入Pause Token来训练语言模型。其核心思想在于模拟人类在思考过程中的停顿,让模型在生成回答之前有一个 “思考” 的间隙,从而提升回答的质量和逻辑性。这种Pause Token还有个好处:在推理的时候不需要再花费时间去生成CoT了,只需要先输入问题,然后拼接上一串Pause Token,就可以改善答案的准确性了。
下图展示了这个思路,在Pretraining/SFT阶段插入Pause Token,在推理的时候也加入。
而论文"Let's think dot by dot: Hidden computation in transformer language models"发现了一个很有趣的现象: 一些无意义的填充Token(Filler Token)可以明显改善LLM的性能。和Pause Token很像。然而,要让模型学会使用Filler Token,需要特定的,密集的监督训练,在普通CoT上训练的模型没办法去利用Filler Token。
CoT
论文"Chain-of-Thought Reasoning without Prompting"发现,LLM 无需任何提示,只需通过简单地改变解码过程,便可展示推理能力。
下图展示了这种现象:给定一个推理问题,LLM通过标准的贪婪解码路径生成了错误答案,而CoT解码通过明确鼓励在首次解码步骤中的多样性来运作,从而取得更好的效果。
LLM确实在仅依赖贪婪解码路径时面临推理困难。采样效果不佳的原因在于,模型在解码过程中有强烈的倾向直接给出答案,因此第一个词元的多样性较低。而CoT 解码模型使用不同的工作流程,它不是直接选择最佳答案(没有采用贪婪解码),而是从最佳答案列表中进行选择。具体而言,CoT解码是在第一步中,通过使用前k个token(top-𝑘)来进行解码,在后续步骤中依然使用贪婪解码。使用这种方法时,模型对最终答案的信心更高。当考虑前k个词元中的替代路径时,CoT推理模式自然地在LLM的解码轨迹中显现。下图中的解码路径2和4就是更准确的答案。该解码修改跳过了提示过程,完全在无监督的情况下实现,无需进行模型微调。
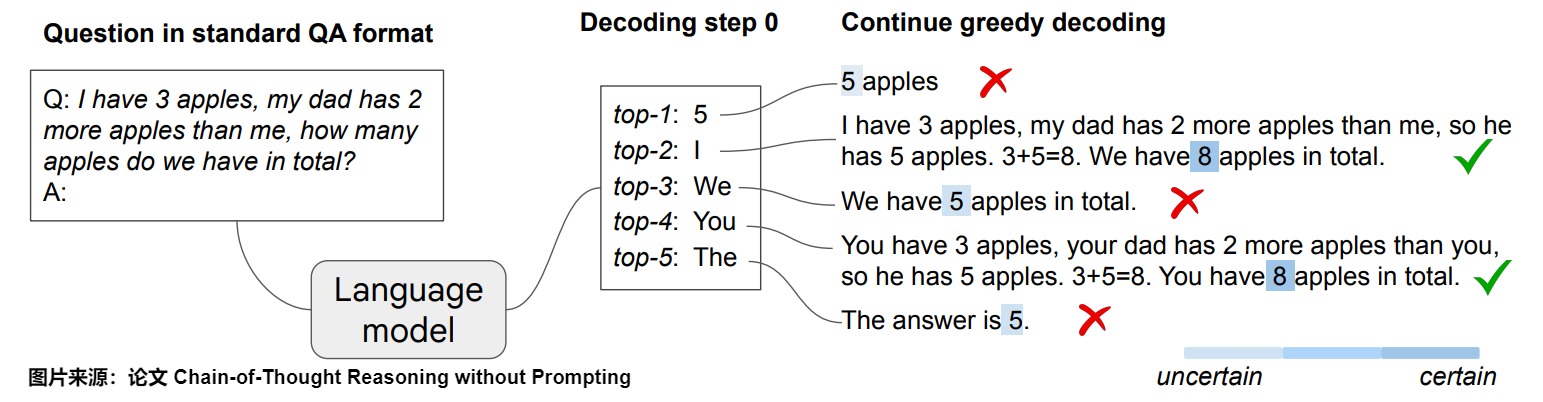
工作流程
让我们看看CoT解码是如何工作的:
- 输入格式:首先,我们需要使用标准的问答(QA)格式进行输入:“Q:[问题] \nA:”,其中[问题]是实际问题。
- 解码过程:我们不再只使用贪婪解码,而是需要探索第一个解码位置上的前 k 个备选标记。默认情况下,本文使用 k=10。
- 路径探索:在考虑了第一个位置的前 k 个标记后,我们可以继续对序列的其余部分进行贪婪解码。这会创建多个潜在的响应路径。
- 路径选择:基于这种置信度模式,我们可以开发一种方法来筛选前 k 条路径并选择最可靠的输出。我们提出了一种加权聚合方法,即选择使 \(\tilde Δ_𝑎=∑_𝑘Δ_{𝑘,𝑎}\) 最大的答案,其中 \(Δ_{𝑘,𝑎}\) 是第 𝑘 条解码路径中答案为 𝑎 的路径。我们发现,采用这种方法可以增强结果的稳定性。
在其他解码步骤进行分支。
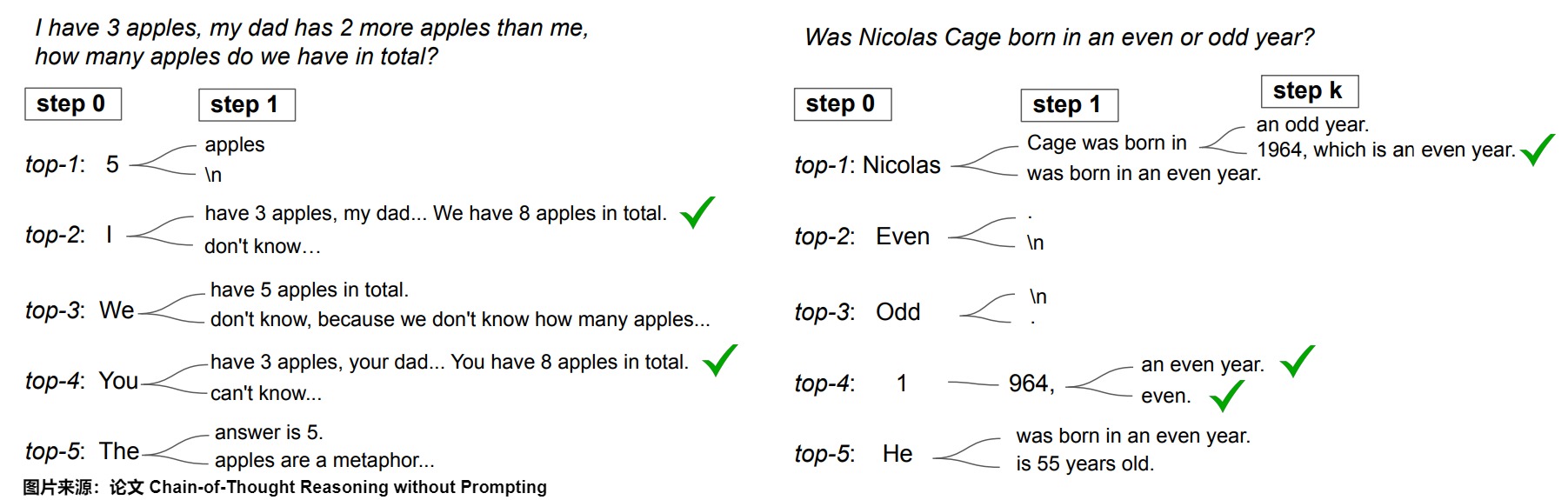
另一个自然的问题是,相比仅在首次解码步骤进行分支,是否可以在后续解码阶段进行分支。在下图中,论文突出了在随后的解码步骤中考虑替代词元的影响。很明显,早期分支(例如在首次解码步骤)显著增强了潜在路径的多样性。相反,后期分支则受到先前生成词元的显著影响。例如,如果解码从词元“5”开始,则纠正错误路径的可能性大大降低。然而,最佳的分支点可能因任务而异;在年份奇偶性任务中,中途分支可以有效地生成正确的CoT路径。
coconut
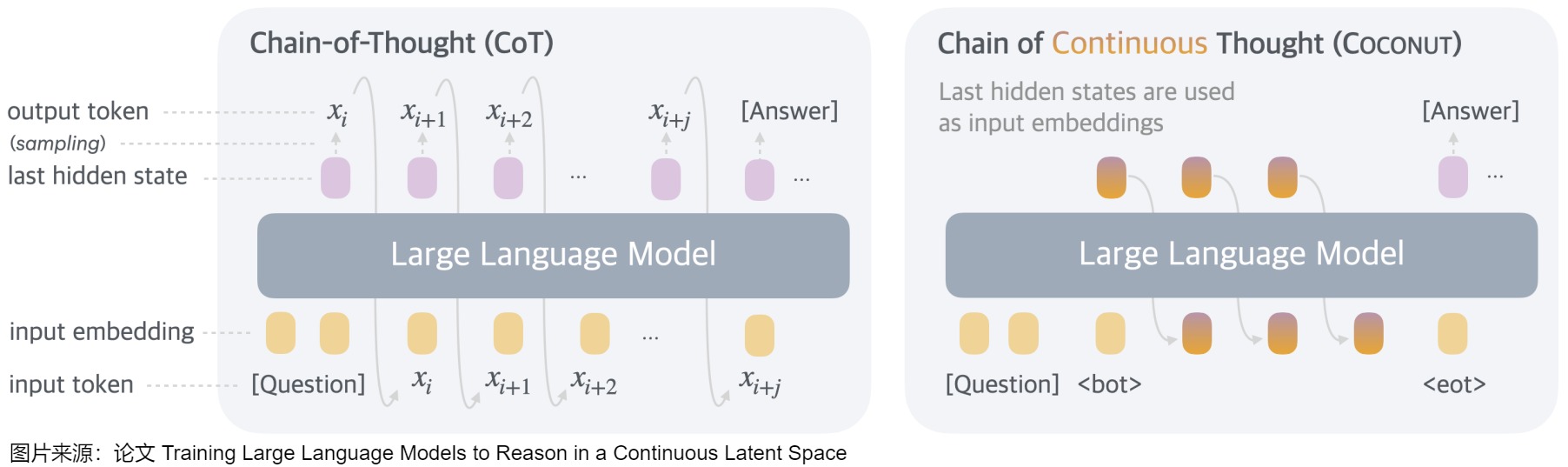
论文"Training Large Language Models to Reason in a Continuous Latent Space"提出来了Coconut。Coconut 涉及对传统 CoT(Chain of Thought)过程的简单修改:Coconut 不再通过语言模型头(language model head)和嵌入层将隐藏状态与语言 token 进行映射,而是直接将最后的隐藏状态(hidden states,即连续思维)作为下一个 token 的输入嵌入(如下图所示)送入到LLM。从而解决了使用Pause Token/Filler Token不好泛化的问题。
下图是连续思维链(Coconut )与思维链(CoT)的比较。
- 在CoT中,该模型作为标准语言模型运行,自回归生成下一个 token。模型将推理过程生成为单词记号序列。即 CoT 会把中间推理步骤用自然语言明文输出。
- 在Coconut中,模型将最后一个隐藏状态作为当前推理状态的表示(称为“连续思维”),并作为下一个输入嵌入。即,CoconUT方法允许模型在"隐藏层"或"潜在向量"里进行中间推理步骤,不必转换成可见的语言符号。这种做法摆脱了语言生成的束缚,让模型可以更加灵活、高效地思考。
这种范式带来了高效的推理模式,具体如下。
- 将推理从语言空间中解放出来,并且由于连续思维是完全可微的,因此可以通过梯度下降对系统进行端到端优化。
- 支持并行探索(类似宽度优先搜索)的潜在能力。在隐空间的推理与基于语言的推理不同,Coconut 中的连续思维可以同时编码多个潜在下一步,从而实现类似于 BFS(breadth-first search)的推理过程。作者强调,模型不一定在第一步就做出"硬性决策",而是能同时在隐藏层里保留多条可能的推理路径。随着推理过程的展开,它会"淘汰"一些看起来不合理的候选路径,保留更加可行的分支。这种方式与普通的自回归生成不同,后者通常一步一步做出"不可撤销"的决策。
- 与输入token相比,输入hidden states也不会被argmax操作所带来的信息损耗/误差累积所影响。
具体训练把CoT里的Discrete Tokens逐渐替换成Continuous Tokens。这是一种多阶段的训练过程(受"渐进式"或者"分段式"思想启发)。这个过程从显式的语言推理开始,一点点引导模型将推理步骤"内化"到连续向量空间中。并且训练过程中会把Continuous Tokens上的Next-Token-Prediction Loss给Mask掉,确保让Continuous Tokens不只是原始CoT的压缩。为了增强潜在推理的训练,论文采用了多阶段训练策略,该策略有效地利用语言推理链来指导训练过程。
4.3 基于熵的采样
当想减少模型的幻觉时,工程师可能会将模型的采样超参数如temperature设为 0。但是这样做并不一定能提高模型不产生幻觉输出的概率,而只是迫使它对相对于其他单词而言的一个单词赋予更高的概率。我们接下来看看基于熵的一些采样思路或者解码思路。
SED
在生成token的过程中的一种极端情况是:所有的token的概率都很小,top-k的概率相差无几。EDT认为这种情况下,选择哪一个都是对的,进而增大temperature来增加LLM的多样性。与此相反,论文"SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation"认为这种情况下,稍不注意就会生成错误的答案。这种错误通过beam-search等方法无法解决,并且PPL指标也很小。要解决这种问题,就需要新的方法来对这种情况进行判别然后修正。
论文把token概率差不多的情况称为chaotic point,下图展示了两种判断方法。

识别到当前step是chaotic point之后,我们就必须采取修正措施了,具体流程如下图。

二者联合起来,就得到了完整的处理算法:

entropix
是否有必要每个token都生成CoT,很显然没必要。比如当前的token是"苹",下一个token根本不需要什么思考,是"果"的概率非常大。有没有什么简单方法就能决定在哪些token后面插入CoT呢?entropix就给出了自己的思路。
相关信息
- 熵 : 在信息理论中,熵量化了概率分布的不确定性和随机性。对于语言模型,熵衡量了预测下一个词的概率分布的不确定性。我们来看看关于熵给模型带来的启示。
- 熵低表示模型对下一个词的预测非常确定。
- 熵尖峰现象。当模型面对多个等概率的下一词选项时,会形成熵尖峰。这些尖峰表明了高不确定性情况下的挑战。
- 中等熵水平下的稳定行为。当熵值在1到2.5这个中等范围内时,模型的行为更加稳定和可预测。这种稳定状态有助于模型生成既有创意又连贯的输出。
- 熵崩溃现象。当模型的不确定性大大降低时,模型的输出变得高度确定。虽然这可以带来自信且正确的预测,但也可能导致模型产生过度自信但不正确的回应。
- 方差熵 : 方差熵是熵的方差,衡量模型的不确定性在不同词或不同模型层上的变化情况。varentropy衡量的是不同可能的下一词信息内容的方差。不同于熵衡量的是平均不确定性,varentropy捕捉的是这种不确定性的变化,有助于模型在复杂情况下的适应性。当熵和varentropy都高时,模型可以识别出复杂情况并调整其采样策略,生成更深层次的推理步骤。
核心思路
Entropix的核心思想是量化模型的不确定性,通过熵和方差熵来指导解码过程中的采样策略。当模型自信时(低熵和低方差熵)继续正常采样;当模型不确定时(高熵和/或高方差熵)就探索不同的词或推理路径。
这种自适应方法是通过调整采样策略来模拟思维链过程,允许模型在更复杂的场景中动态调整,让模型来做出更多的“思考”,提升其决策能力,从而可能产生更准确连贯的输出。
entropix作者在每一个token解码前,计算logit的entropy(熵)和varentropy(熵的方差),这提供了一个关于跨不同token不确定性的度量。低varentropy意味着模型的不确定性在token间是恒定的,高则意味着token间不确定性很大。然后模型根据entropy决定是否插入CoT以及调整温度系数。具体规则举例如下:
- logit的熵和熵方差都小,LLM很有信心,按照常规方法直接greedy decoding。
- logit的熵大,熵方差都小,LLM没啥信心,插入CoT并且用attention的熵调整得到更大的T,会探索替代标记或推理路径。
0x05 权重共享
在大模型中,参数共享技术允许在网络的不同部分重复使用相同的权重集。这不仅有助于减少参数数量,还能在保持性能的同时提高模型的效率。一种常见的方法是embedding-lm的head共享,即单词嵌入层与最终语言模型的head层共享相同的权重。另一个例子是分层注意力/FFN共享,其在模型的多个层中使用相同的权重(Cross-layer parameter sharing)。这种共享技术可以在Gemma和Qwen等模型中看到,层之间的参数共享机制能够有效的防止参数量随着网络深度的加深而增加,显著提升了模型的训练和推理效率。
5.1 vanilla Transformer
vanilla Transformer在两个地方进行了权重共享:
-
Encoder和Decoder间的Embedding层权重共享;
-
Decoder中Embedding层和FC层权重共享。
Transformer原始论文说
In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to (cite). In the embedding layers, we multiply those weights by \(\sqrt{d_{\text{model}}}\).
哈佛作者则写到
- Shared Embeddings: When using BPE with shared vocabulary we can share the same weight vectors between the source / target / generator. See the (cite) for details. To add this to the model simply do this:
具体代码举例如下,其中weight就是形状为[vocab, d_model]的词嵌入矩阵。
if False:# Encoder和Decoder间的Embedding层权重共享model.src_embed[0].lut.weight = model.tgt_embeddings[0].lut.weight# Decoder中Embedding层和FC层权重共享model.generator.lut.weight = model.tgt_embed[0].lut.weight
5.2 共享词表权重
原理
之所以可以共享词表权重,是因为在机器翻译任务中,如果源语言和目标语言很接近(比如英语和德语同属日耳曼语族,有很多相同的词根或者子词),因此源语言和目标语言可以共享一个词嵌入矩阵。而且对于Encoder和Decoder,嵌入时都只有对应语言的embedding会被激活,因此是可以共用一张词表做权重共享的,甚至可以实现编码器的输入embedding、解码器的输入embedding和解码器的输出embedding 三者共享。这样对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示。而像中英这样相差较大的语系,则完全没有共享词嵌入矩阵的必要。
但是,共用词表会使得词表数量增大,增加softmax的计算时间,因此实际使用中是否共享可能要根据情况权衡。
历史基础
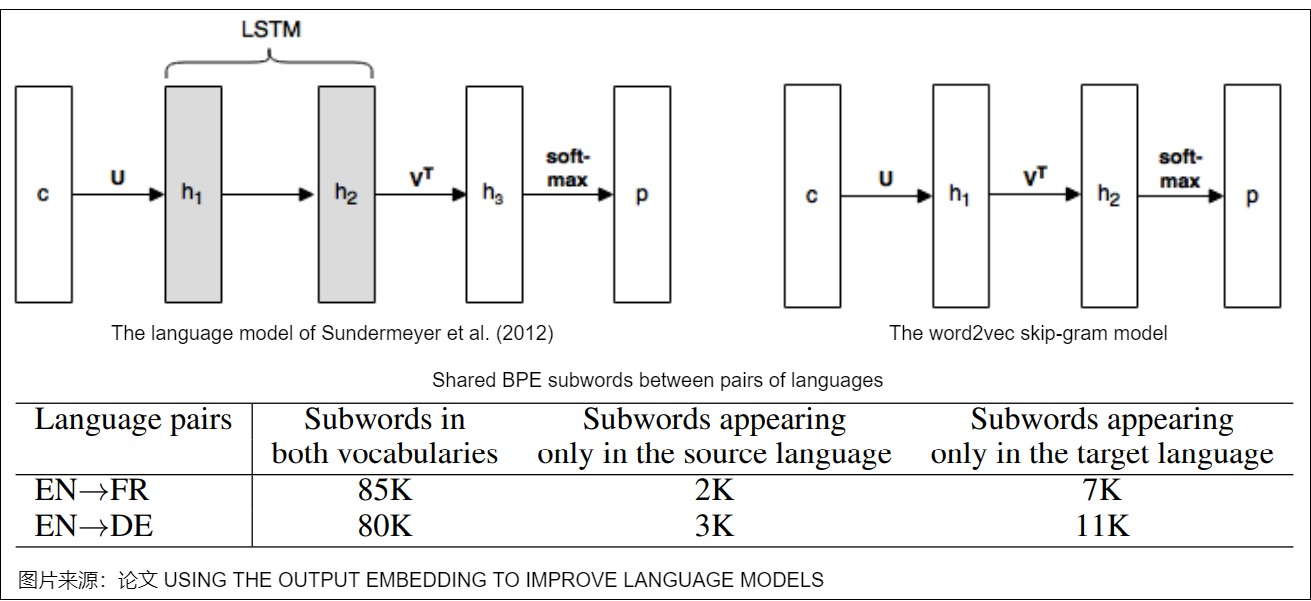
我们再来看看vanilla Transformer可以共享权重的参考。论文"Using the Output Embedding to Improve Language Model"是共享词表早期的工作。该论文将模型的输入词向量和输出词向量绑定在一起,即共享一个词向量空间,同一个词在输入词向量时和输出词向量时会组合成一个词向量。在一个常见的神经网络语言模型中,向量的流转历程如下:
- 当前输入词首先会被表示为向量 \(c\in R^C\)。
- 使用word embedding矩阵 U 将c 投影为稠密的表示。
- 对词向量 \(U^Tc\) 执行一些计算,从而得到激活向量 \(h_2\)。
- 使用第二个矩阵 V 把 \(h_2\) 投影到向量 \(h_3\),即\(h_3=Vh_2\)。向量 \(h_3\)包含很多分数值,词表中每个单词都对应其中一个分数。
- 使用softmax函数将分数向量转换为概率值向量 p,其表示模型对下一个单词的预测。
基于上述历程,论文进行了推导。论文称 U 为输入embedding, V 为输出embedding。模型训练完成后,通常只是用U作为预训练词向量给其他上游模型使用,而忽略V。论文也比较了输入词向量和输出词向量的质量,其主要结果如下:
- 在Word2Vec Skipgram模型中,输出词向量与输入词向量相比,效果较差。
- 在基于RNN的语言模型中,输出词向量的效果要优于输入词向量。
- 通过将两个词向量结合在一起,即强制 U = V,则组合后的词向量更类似于未绑定(untied)模型中的输出词向量的方式发展,而非未绑定模型的输入词向量。
- 将输入和输出词向量结合之后可以改进善各种语言模型的困惑度。无论是否使用dropout。
- 当不使用dropout时,建议在 V 之前添加一个额外的投影 P,并对 P应用正则化。
- 神经翻译模型中的权重绑定(weight tying)可以在不影响性能的前提下,将模型大小(参数数量)减少到其原始大小的一半以下。
相关信息如下图所示。图上方是"Using the Output Embedding to Improve Language Model"中的示例图,下方是英语和法语,英语和德语之间子词的比较情况。
5.2 FC和embedding共享
在语言模型的输出端重用Embedding权重的做法,英文称之为“Tied Embeddings”或者“Coupled Embeddings”。其思想主要是Embedding矩阵跟输出端转换到logits的投影矩阵大小是相同的(只差个转置),并且由于这个参数矩阵比较大,所以为了避免不必要的浪费,干脆共用同一个权重。在某种意义上,我们可以把解码中的Embedding层和线性层看作是逆过程。
- 解码开始前,模型会利用独热编码从Embedding层中获取独热编码对应的embedding向量。
- 解码器生成隐向量之后,FC层(输出端转换到logits的投影矩阵)中和隐向量最接近的那一行对应的词,会获得更大的预测概率。
因为Embedding矩阵跟FC矩阵大小是相同的(只差个转置),并且由于这个参数矩阵比较大,所以为了避免不必要的浪费,就让FC和embedding层共用同一个权重。这样可以减少参数的数量,加快收敛。
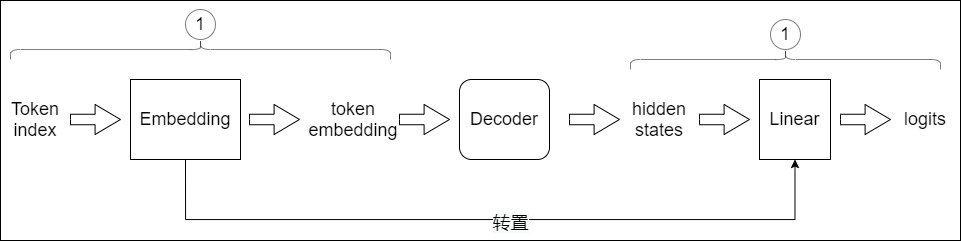
如果语言模型较小时,因为当模型主干部分不大且词表很大时,Embedding层的参数量很可观,所以可以考虑在输出端重用Embedding权重是很常见的操作。如果Embedding层在模型参数的占比较小,则需要考虑是否有必要共享权重。
另外,共享Embedding可能会有些负面影响,比如它会导致预训练的初始损失非常大。这是因为我们通常会使用类似DeepNorm的技术来降低训练难度,它们都是将模型的残差分支初始化得接近于零。换言之,模型在初始阶段近似于一个恒等函数,这使得初始模型相当于共享Embedding的2-gram模型。
0xFF 参考
CTRL: A Conditional Transformer Language Model for Controllable Generation
字节大模型一面:“Beam Search 最坏时间复杂度是多少?” 看图学
A new, and possibly groundbreaking, method to enhancing language model reasoning with entropy-based sampling and parallel
Beam Search 及其优化方法 不畏侠
Beam search搜索算法、相关概念与C++代码 iyayaai
Best-First Beam Search
Chain-of-Thought Reasoning without Prompting
Dola: decoding by contrasting layers improves factuality in large language models
EDT: Improving Large Language Models’ Generation by Entropy-based Dynamic Temperature Samplinghttps://arxiv.org/abs/2403.14541v1)
EDT: 动态调整LLM里面的temperature 杜凌霄 [探知轩]
EDT: 动态调整LLM里面的temperature 木叶
entropix,终于找到了真正解决幻觉的方法了 Python编程杰哥
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Hot or Cold? Adaptive Temperature Sampling for Code Generation with Large Language Models
How Alignment and Jailbreak Work:Explain LLM Safety through Intermediate Hidden States
Kl-divergence guided temperature sampling. arXiv preprint arXiv:2306.01286
KL-Divergence Guided Temperature Sampling
[learning to break the loop: analyzing and mitigating repetitions](https://arxiv.org/pdf/2206.02369.pdf)
LLM 推理常见参数解析 AI闲谈
LLM的解码策略和代码实现 Alex [算法狗]
penalty decoding: well suppress the self-reinforcement effect in open-ended
SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
SED:增强LLM Decoding阶段的正确性 杜凌霄 [探知轩]
Top-nσ: Not All Logits Are You Need Chenxia Tang, Jianchun Liu, Hongli Xu, Liusheng Huang
Training Large Language Models to Reason in a Continuous Latent Space
《Rethinking embedding coupling in pre-trained language models》
不需要Prompt也能激发大模型思维链能力?谷歌DeepMind新作提出CoT新范式 青云遮夜雨
动态温度系数T和最近比较火的entropix 机器爱学习 [一万篇论文笔记]
在解码时解决大模型“幻觉”问题 [
如何生成文本:通过 Transformers 用不同的解码方法生成文本
温度系数与 top-p 采样策略详解 Zhang
生成重复:Learning to Break the Loop 流逝
语言模型输出端共享Embedding的重新探索 - 知乎 (zhihu.com)
语言模型输出端共享Embedding的重新探索 苏剑林
大语言模型中的“温度”参数到底是什么?如何正确设置? 智能体AI
关于Deepseek采用EP推理方式的一些思考 杨鹏程
大模型温度设为0,LLM输出就能完全确定?真相来了! Alex [算法狗](javascript:void(0)😉
隐空间推理的起源 |Meta的COCONUT是什么? Tensorlong 看天下