在 SciChart 中,XyDataSeries 和 UniformXyDataSeries 是两种用于处理数据序列的核心类,主要差异体现在数据存储方式、性能优化及适用场景上。
以下是具体对比:
1. 数据存储与结构差异
**XyDataSeries<TX, TY>** 需要同时存储 X 和 Y 值的完整坐标对。例如,对于每个数据点 (x0, y0)、(x1, y1),需显式定义 X 和 Y 数组。适用场景:X 轴数据非均匀分布(如散点图、不规则时间戳数据)。**UniformXyDataSeries<TY>** 仅存储 Y 值,X 值根据 startX(起始值)和 step(步长)自动计算生成。例如,给定 startX=0 和 step=1,X 序列为 0,1,2,3...。适用场景:X 轴数据均匀递增(如实时波形、等间隔采样数据)。
2. 性能与内存优化
**内存占用**
UniformXyDataSeries 仅需存储 Y 数组,内存占用比 XyDataSeries 减少约 50%(无需存储 X 数组),尤其适合处理百万级数据点。**数据追加效率**
UniformXyDataSeries 支持通过 Append(values) 或 AppendRange(values) 快速批量追加 Y 值,X 值自动计算,减少 CPU 开销。
3. 使用场景对比
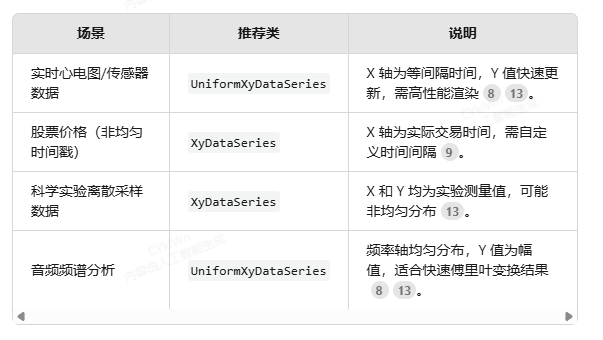
4. 代码示例对比
// 使用 XyDataSeries(非均匀 X 值)
var xySeries = new XyDataSeries<double, double>();
xySeries.Append(1.5, 10); // (x=1.5, y=10)
xySeries.Append(3.0, 20); // (x=3.0, y=20)// 使用 UniformXyDataSeries(均匀 X 值)
var uniformSeries = new UniformXyDataSeries<double>();
uniformSeries.StartX = 0; // 起始 X 值
uniformSeries.Step = 1; // 步长
uniformSeries.Append(10); // (x=0, y=10)
uniformSeries.Append(20); // (x=1, y=20)
5. 注意事项
动态修改步长:UniformXyDataSeries 的 Step 属性可在运行时调整,但需注意重新计算 X 值可能导致性能损耗。
数据覆盖策略:两者均支持循环缓冲区(Capacity 属性),当数据量超过容量时自动丢弃旧数据,适合实时流。
混合使用场景:若数据部分均匀、部分非均匀,可结合两种系列,通过 CompositeSeries 叠加显示。
通过合理选择数据系列类型,可显著提升 SciChart 在大数据量场景下的渲染性能。