引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
💡系列文章完整目录: 👉点此👈
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不适用外部框架的前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
本文基于RNN作为编码器/解码器的seq2seq架构实现德语-英语的机器翻译。
上篇文章基于英语-汉语数据集实现了机器翻译,但发现它的验证集损失不下降,纠结了很久还是决定用德语-英语的数据集来做。
seq2seq简介
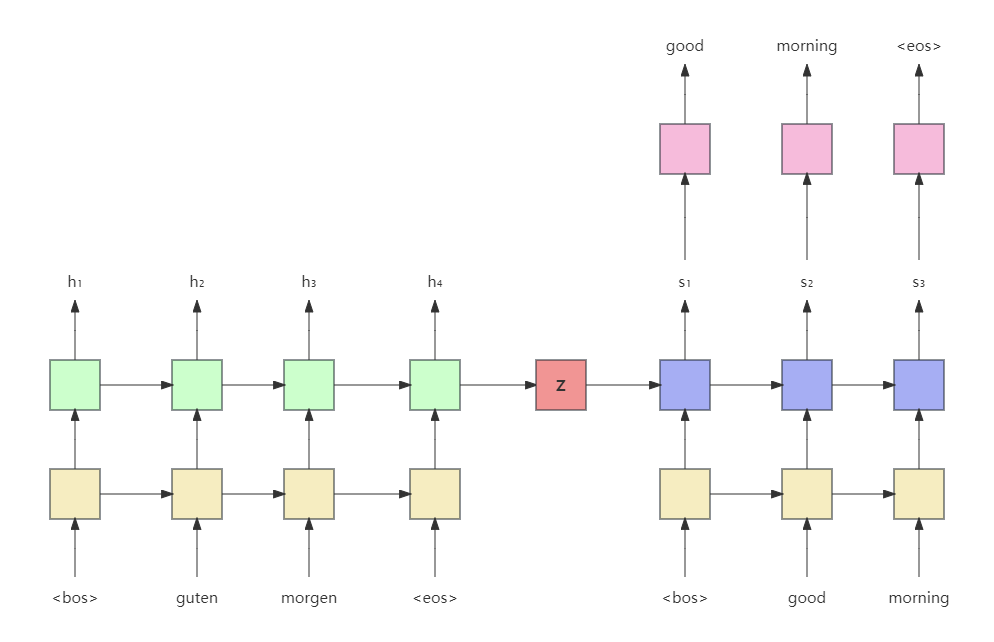
上图是seq2seq翻译德语“早上好”的例子。源语句guten morgen首先经过嵌入层(黄色),然后输入到编码器(浅绿色)。为了表示句子的开头和结束,加入开始和结束标记 <bos>、<eos>。
编码器这里是由GRU实现的,用最后一个token即<eos>输出的隐藏状态表示整个源语句的编码 z z z,这里 h 4 = z h_4=z h4=z。
解码器也是一个GRU网络,它的初始隐藏状态为编码器生成的 z z z。解码器第一个输入的token为<bos>,表示开始生成目标语句。解码器基于输入的token和前一个隐藏状态生成当前隐藏状态 s 1 s_1 s1,这里假设 s 1 s_1 s1经过一个线性映射后投影到输出词表空间,经过softmax得到输出词表所有单词分布。这里可以选择概率最大的单词作为解码器当前时刻的预测。
数据集处理
从数据集处理开始,首先引入所需要的包:
import os
import random
from collections import defaultdict
from typing import Tuplefrom tqdm import tqdmimport metagrad.module as nn
from metagrad import Tensor, cuda
from metagrad import functions as F
from metagrad import init
from metagrad.dataloader import DataLoader
from metagrad.dataset import TensorDataset
from metagrad.loss import CrossEntropyLoss
from metagrad.optim import Adam
from metagrad.tensor import no_grad
from metagrad.utils import grad_clipping

这里我们用multi30k仓库中已经分好词的版本,但它的源语句和目标语句是分开的,因此,先写一个函数生成源语句和目标语句对。
"""
数据集来自已经分好词的版本: https://github.com/multi30k/dataset/tree/master/data/task1/tok
"""base_path = "../data/de-en"def build_nmt_pair(src_path, tgt_path, reverse=False):"""构建机器翻译source-target对:param src_path: 源语言目录:param tgt_path: 目标语言目录:param reverse: 是否逆序源语言:return: 分好词的source和target"""source, target = [], []with open(src_path, 'r', encoding='utf-8') as f:source_lines = f.readlines()with open(tgt_path, 'r', encoding='utf-8') as f:target_lines = f.readlines()for src, tgt in zip(source_lines, target_lines):src_tokens = src.split()if reverse:src_tokens.reverse()tgt_tokens = tgt.split()source.append(src_tokens)target.append(tgt_tokens)return source, target
source, target = build_nmt_pair(os.path.join(base_path, "val.de"), os.path.join(base_path, "val.en"))
print(source[:2])
print(target[:2])
打印前2条记录:
[['eine', 'gruppe', 'von', 'männern', 'lädt', 'baumwolle', 'auf', 'einen', 'lastwagen'], ['ein', 'mann', 'schläft', 'in', 'einem', 'grünen', 'raum', 'auf', 'einem', 'sofa', '.']]
[['a', 'group', 'of', 'men', 'are', 'loading', 'cotton', 'onto', 'a', 'truck'], ['a', 'man', 'sleeping', 'in', 'a', 'green', 'room', 'on', 'a', 'couch', '.']]接下来是构建词典:
class Vocabulary:BOS_TOKEN = "<bos>" # 句子开始标记EOS_TOKEN = "<eos>" # 句子结束标记PAD_TOKEN = "<pad>" # 填充标记UNK_TOKEN = "<unk>" # 未知词标记def __init__(self, tokens=None):self._idx_to_token = list()self._token_to_idx = dict()# 如果传入了去重单词列表if tokens is not None:if self.UNK_TOKEN not in tokens:tokens = tokens + [self.UNK_TOKEN]# 构建id2word和word2idfor token in tokens:self._idx_to_token.append(token)self._token_to_idx[token] = len(self._idx_to_token) - 1self.unk = self._token_to_idx[self.UNK_TOKEN]@classmethoddef build(cls, text, min_freq=2, reserved_tokens=None):'''构建词表:param text: 处理好的(分词、去掉特殊符号等)text:param min_freq: 最小单词频率:param reserved_tokens: 预先保留的标记:return:'''token_freqs = defaultdict(int)for sentence in text:for token in sentence:token_freqs[token] += 1unique_tokens = (reserved_tokens if reserved_tokens else []) + [cls.UNK_TOKEN]unique_tokens += [token for token, freq in token_freqs.items() \if freq >= min_freq and token != cls.UNK_TOKEN]return cls(unique_tokens)def __len__(self):return len(self._idx_to_token)def __getitem__(self, tokens):'''得到tokens对应的id'''if not isinstance(tokens, (list, tuple)):return self._token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]@propertydef id2token(self):'''返回idx_to_token列表'''return self._idx_to_tokendef token(self, indices):'''根据索引获取token'''if not isinstance(indices, (list, tuple)):return self._idx_to_token[indices]return [self._idx_to_token[index] for index in indices]def to_tokens(self, indices):return self.token(indices)def save(self, path):with open(path, 'w') as f:f.write("\n".join(self.id2token))@classmethoddef load(cls, path):with open(path, 'r') as f:tokens = f.read().split('\n')return cls(tokens)
这个和之前见到的差不多,做了一些小的修改。
min_freq = 2
source, target = build_nmt_pair(os.path.join(base_path, "train.de"), os.path.join(base_path, "train.en"))reserved_tokens = [Vocabulary.PAD_TOKEN, Vocabulary.BOS_TOKEN, Vocabulary.EOS_TOKEN]
src_vocab = Vocabulary.build(source, min_freq=min_freq, reserved_tokens=reserved_tokens)
tgt_vocab = Vocabulary.build(target, min_freq=min_freq, reserved_tokens=reserved_tokens)
7859 5921
打印出了源词表和目标词表大小。
接下来实现填充函数:
def truncate_pad(line, max_len, padding_token):"""截断或填充文本序列"""if len(line) > max_len:return line[:max_len] # 截断return line + [padding_token] * (max_len - len(line)) # 填充
print(truncate_pad(src_vocab[source[0]], 20, src_vocab[Vocabulary.PAD_TOKEN]))
注意这里隐式调用了Vocabulary的__getitem__方法将token转换为对应的index,同时在该方法中还会处理未知词。
[4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 0, 0, 0, 0, 0, 0, 0]
下面把转换后的index列表打包成批量数据,以及在前后分别增加<bos>和<eos> token:
def build_array_nmt(lines, vocab, max_len=None):"""将机器翻译的文本序列转换成小批量"""if not max_len:max_len = max(len(x) for x in lines)# 先转换成token对应的索引列表lines = [vocab[l] for l in lines]# 增加BOS和EOS token的索引lines = [[vocab[Vocabulary.BOS_TOKEN]] + l + [vocab[Vocabulary.EOS_TOKEN]] for l in lines]# max_len 应该加2了:额外的BOS和EOS ,并转换为seq_len, batch_size的形式array = Tensor([truncate_pad(l, max_len + 2, vocab[Vocabulary.PAD_TOKEN]) for l in lines])return array
src_array = build_array_nmt(source, src_vocab, 20)
print(src_array[:5])
并且会转换为Tensor变量:
Tensor([[ 1 4 5 6 7 8 9 10 11 12 13 14 15 16 2 0 0 0 0 0 0 0][ 1 17 7 18 19 20 21 3 16 2 0 0 0 0 0 0 0 0 0 0 0 0][ 1 21 22 23 24 11 21 25 26 27 16 2 0 0 0 0 0 0 0 0 0 0][ 1 21 28 11 29 30 31 32 33 34 35 36 37 21 38 16 2 0 0 0 0 0][ 1 4 7 39 40 41 36 42 43 44 16 2 0 0 0 0 0 0 0 0 0 0]], requires_grad=False)
最后通过一个函数结合上面所有方法构建数据集和数据加载器:
def load_dataset_nmt(data_path=base_path, data_type="train", batch_size=32, min_freq=2, src_vocab=None, tgt_vocab=None,shuffle=False):"""加载机器翻译数据集:param data_path: 保存数据集的目录:param data_type: 数据集类型 train|test|val:param batch_size: 批大小:param min_freq: 最小单词次数:param src_vocab: 源词典:param tgt_vocab: 目标词典:param shuffle: 是否打乱:return:"""source, target = build_nmt_pair(os.path.join(data_path, f"{data_type}.de"),os.path.join(data_path, f"{data_type}.en"),reverse=True)# 构建源和目标词表reserved_tokens = [Vocabulary.PAD_TOKEN, Vocabulary.BOS_TOKEN, Vocabulary.EOS_TOKEN]if src_vocab is None:src_vocab = Vocabulary.build(source, min_freq=min_freq, reserved_tokens=reserved_tokens)if tgt_vocab is None:tgt_vocab = Vocabulary.build(target, min_freq=min_freq, reserved_tokens=reserved_tokens)print(f'Source vocabulary size: {len(src_vocab)}, Target vocabulary size: {len(tgt_vocab)}')# 转换成批数据max_src_len = max([len(line) for line in source])max_tgt_len = max([len(line) for line in target])print(f"max_src_len: {max_src_len}, max_tgt_len:{max_tgt_len}")src_array = build_array_nmt(source, src_vocab, max_src_len)tgt_array = build_array_nmt(target, tgt_vocab, max_tgt_len)# 构建数据集dataset = TensorDataset(src_array, tgt_array)# 数据加载器data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle)# 返回加载器和两个词表return data_loader, src_vocab, tgt_vocabtrain_dataset, src_vocab, tgt_vocab = load_dataset_nmt()
for X, Y in train_dataset:print('X:', X.shape)print('Y:', Y.shape)break
X: (32, 46)
Y: (32, 42)
默认加载训练集数据,可以看到这里返回的是batch_first形式。
数据集处理好了之后,下面就可以定义模型了。
编码器
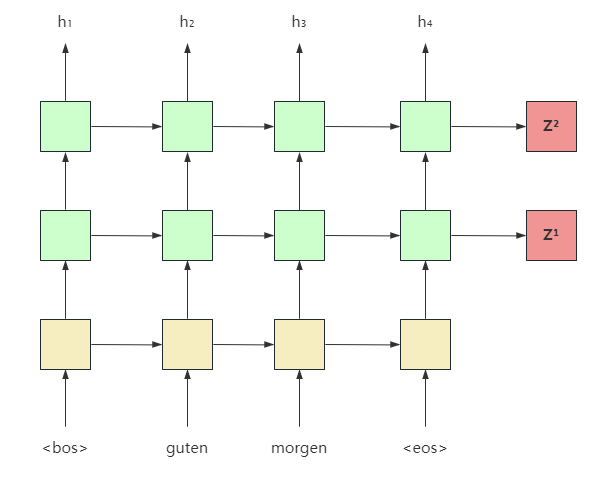
编码器如上图所示,这里可以看到它是由两层的,不过实际上还可以是双向的,没有画出来。每一层都会产生一个编码向量。
class Encoder(nn.Module):def __init__(self, vocab_size: int, embed_size: int, num_hiddens: int, num_layers: int, dropout: float,bidirectional: bool = True) -> None:"""基于GRU实现的编码器:param vocab_size: 源词表大小:param embed_size: 词嵌入大小:param num_hiddens: 隐藏层大小:param num_layers: GRU层数:param dropout: dropout比率:param bidirectional: 是否为双向"""super().__init__()# 嵌入层 获取输入序列中每个单词的嵌入向量 padding_idx不需要更新嵌入self.embedding = nn.Embedding(vocab_size, embed_size, padding_idx=0)# 基于双向GRU实现 注意,这里默认batch_first为Falseself.rnn = nn.GRU(input_size=embed_size, hidden_size=num_hiddens, num_layers=num_layers, dropout=dropout,bidirectional=bidirectional)self.dropout = nn.Dropout(dropout)def forward(self, input_seq: Tensor) -> Tuple[Tensor, Tensor]:"""编码器的前向算法:param input_seq: 形状 (seq_len, batch_size):return:"""# (seq_len, batch_size, embed_size)embedded = self.dropout(self.embedding(input_seq))# embedded = self.embedding(input_seq)# outputs (seq_len, batch_size, num_direction * num_hiddens)# hidden (num_direction * num_layers, batch_size, num_hiddens)outputs, hidden = self.rnn(embedded)# 融合双向的hidden, 因为解码器一定是单向的if self.rnn.bidirectional:hidden = hidden[:self.rnn.num_layers, :, :] + hidden[self.rnn.num_layers:, :, :]# hidden (num_layers, batch_size, num_hiddens)return outputs, hidden
代码有很详细的注释,self.rnn(embedded)返回的是outputs和hidden,前者是每个时间步顶层的隐藏状态,这里我们用不到。后者是每层的最终隐藏状态。由于是双向的,实际上它的形状为 (num_direction * num_layers, batch_size, num_hiddens)。为了和解码器的初始隐藏状态形状保持一致,这里需要融合双向上的信息。
为了防止过拟合,除了在初始化GRU层时指定了dropout,还在词嵌入层上加了一层dropout。
解码器
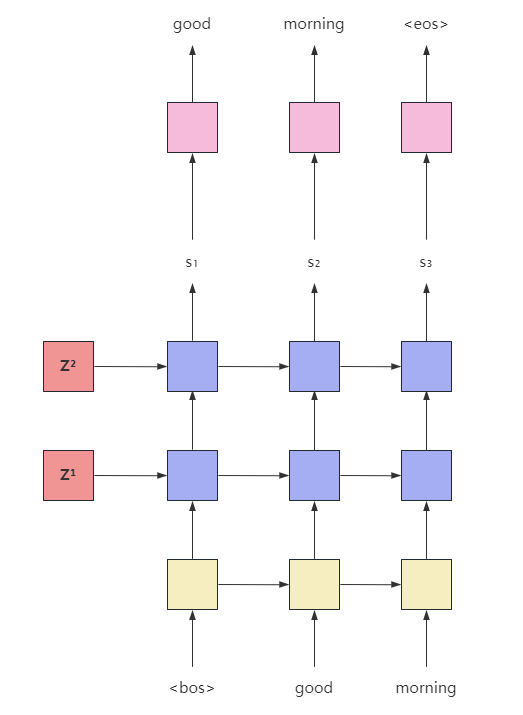
解码器如上图所示,由于我们这里的编码器和解码器层数一致,所有编码器每层最终的隐藏状态刚好可以作为解码器每层的初始状态。
class Decoder(nn.Module):def __init__(self, vocab_size: int, embed_size: int, num_hiddens: int, num_layers: int, dropout: float) -> None:"""基于GRU实现的解码器:param vocab_size: 目标词表大小:param embed_size: 词嵌入大小:param num_hiddens: 隐藏层大小:param num_layers: 层数:param dropout: dropout比率"""super().__init__()self.embedding = nn.Embedding(vocab_size, embed_size, padding_idx=0)self.rnn = nn.GRU(input_size=embed_size, hidden_size=num_hiddens, num_layers=num_layers, dropout=dropout)# 将隐状态转换为词典大小维度self.fc_out = nn.Linear(num_hiddens, vocab_size)self.vocab_size = vocab_sizeself.dropout = nn.Dropout(dropout)def forward(self, input_seq: Tensor, hidden: Tensor) -> Tuple[Tensor, Tensor]:"""解码器的前向算法:param input_seq: 初始输入,这里为<bos> 形状 (batch_size, ):param hidden: 编码器生成的上下文向量 形状 (num_layers, batch_size, num_hiddens):return:"""# input = (1, batch_size)input_seq = input_seq.unsqueeze(0)# embedded = (1, batch_size, embed_size)embedded = self.dropout(self.embedding(input_seq))# output (1, batch_size, num_hiddens)# hidden (num_layers, batch_size, num_hiddens)output, hidden = self.rnn(embedded, hidden)# prediction (batch_size, vocab_size)prediction = self.fc_out(output.squeeze(0))return prediction, hidden其实这里的Decoder每次仅处理一个时间步,从其forward方法中的input_seq大小也可以看出。
也有人直接通过RNNCell来实现。
Seq2Seq
最终组合编码器和解码器就成了序列到序列模型。
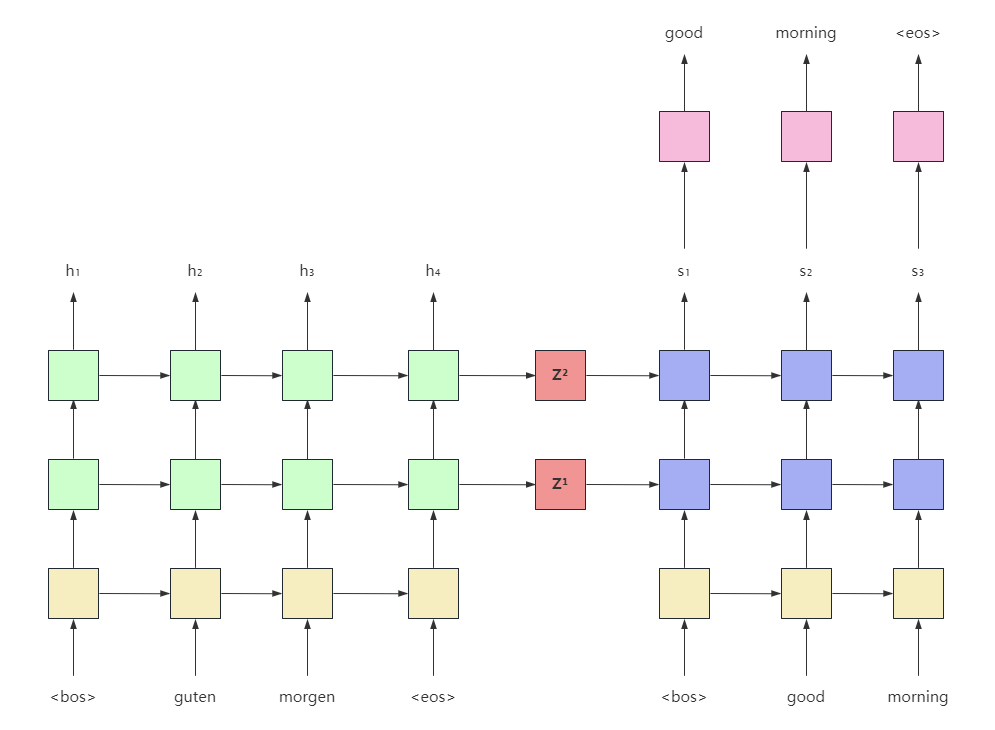
在seq2seq的实现中有一些细节,首先有一个叫做teacher force的东西,仅用于训练阶段。当使用teacher force时,不管解码器的输出是什么,下一步的输入是真实的输入。不使用时,采用解码器自己的输出作为下一步的输入。
teacher force和dropout类似,也可以基于同样的方式实现,目的也是防止过拟合。
解码器的第一个输入token是 <bos>,最后一个token是序列中 <eos>前一个token。我们不会把<eos>输入到解码器中,从上图也可以看出来。
在推理阶段,解码器会一直输出,直到生成了<eos>或达到最大长度。
class Seq2seq(nn.Module):def __init__(self, encoder: Encoder, decoder: Decoder) -> None:"""初始化seq2seq模型:param encoder: 编码器:param decoder: 解码器"""super().__init__()self.encoder = encoderself.decoder = decoderdef forward(self, input_seq: Tensor, target_seq: Tensor, teacher_forcing_ratio: float = 0.0) -> Tensor:"""seq2seq的前向算法:param input_seq: 输入序列 (seq_len, batch_size):param target_seq: 目标序列 (seq_len, batch_size):param teacher_forcing_ratio: 强制教学比率:return:"""tgt_len, batch_size = target_seq.shape# 保存了所有时间步的输出outputs = []# 这里我们只关心编码器输出的hidden# hidden (num_layers, batch_size, num_hiddens)_, hidden = self.encoder(input_seq)# decoder_input (batch_size) 取BOS tokendecoder_input = target_seq[0, :] # BOS_TOKEN# 这里从1开始,确保tgt[t]是下一个tokenfor t in range(1, tgt_len):# output (batch_size, target_vocab_size)# hidden (num_layers, batch_size, num_hiddens)output, hidden = self.decoder(decoder_input, hidden)# 保存到outputsoutputs.append(output)# 随机判断是否强制教学teacher_force = random.random() < teacher_forcing_ratio# 如果teacher_force==True, 则用真实输入当成下一步的输入,否则用模型生成的# output.argmax(1) 在目标词表中选择得分最大的一个 (batch_size, 1)decoder_input = target_seq[t] if teacher_force else output.argmax(1)# 把outputs转换成一个Tensor 形状为: (tgt_len - 1, batch_size, target_vocab_size)return F.stack(outputs)其实把所有变量的形状标出来就不难理解了,把形状注释出来不仅可读性更好,还可以防止犯错。
注意这里forward函数最终返回的形状是 (tgt_len - 1, batch_size, target_vocab_size)。
注意循环从1开始而不是0,我们的target_seq和outputs看起来是这样:
target = [ <bos> , y 1 , y 2 , y 3 , <eos> ] outputs = [ y ^ 1 , y ^ 2 , y ^ 3 , <eos> ] \text{target} = [\text{<bos>}, y_1,y_2,y_3, \text{<eos>}] \\ \text{outputs} = [\hat y_1,\hat y_2,\hat y_3, \text{<eos>}] target=[<bos>,y1,y2,y3,<eos>]outputs=[y^1,y^2,y^3,<eos>]
这里 y ^ \hat y y^表示模型的预测token。
后面当我们计算损失时,需要切掉target_seq的第一个token,变成:
target = [ y 1 , y 2 , y 3 , <eos> ] outputs = [ y ^ 1 , y ^ 2 , y ^ 3 , <eos> ] \text{target} = [y_1,y_2,y_3, \text{<eos>}] \\ \text{outputs} = [\hat y_1,\hat y_2,\hat y_3, \text{<eos>}] target=[y1,y2,y3,<eos>]outputs=[y^1,y^2,y^3,<eos>]
训练seq2seq
至此我们的模型已经实现好,可以开始训练了。
一开始我们定义必要的参数:
# 参数定义
embed_size = 256
num_hiddens = 512
num_layers = 2
dropout = 0.5batch_size = 64
max_len = 40lr = 0.001
num_epochs = 10
min_freq = 2
clip = 1.0 # 梯度裁剪,防止梯度爆炸tf_ratio = 0.5 # teacher force ratioprint_every = 1device = cuda.get_device("cuda" if cuda.is_available() else "cpu")
然后加载数据集:
# 加载训练集
train_iter, src_vocab, tgt_vocab = load_dataset_nmt(data_path=base_path, data_type="train", batch_size=batch_size,min_freq=min_freq, shuffle=True)# 加载验证集
valid_iter, src_vocab, tgt_vocab = load_dataset_nmt(data_path=base_path, data_type="val", batch_size=batch_size,min_freq=min_freq, src_vocab=src_vocab, tgt_vocab=tgt_vocab)接着构建模型:
# 构建编码器
encoder = Encoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 构建解码器
decoder = Decoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)model = Seq2seq(encoder, decoder)
model.apply(init_weights)
model.to(device)print(model)
Seq2seq((encoder): Encoder((embedding): Embedding(7859, 256, padding_idx=0)(rnn): GRU(input_size=256, hidden_size=512, num_layers=2, dropout=0.5, bidirectional=True)(dropout): Dropout(p=0.5))(decoder): Decoder((embedding): Embedding(5921, 256, padding_idx=0)(rnn): GRU(input_size=256, hidden_size=512, num_layers=2, dropout=0.5)(fc_out): Linear(in_features=512, out_features=5921, bias=True)(dropout): Dropout(p=0.5))
)
上面的init_weights是初始化权重:
def init_weights(model):for name, param in model.named_parameters():init.uniform_(param, -0.08, 0.08)
然后定义优化器和损失函数,这里使用交叉熵损失函数即可,指定了忽略填充索引。
TGT_PAD_IDX = tgt_vocab[Vocabulary.PAD_TOKEN]optimizer = Adam(model.parameters())
criterion = CrossEntropyLoss(ignore_index=TGT_PAD_IDX)
Adam优化器的实现后面也会出文章介绍。
下面是单epoch的训练代码:
def train_epoch(model, data_iter, optimizer, criterion, clip, device, tf_ratio):model.train()epoch_loss = 0for batch in data_iter:optimizer.zero_grad()inputs, targets = [x.to(device).T for x in batch] # 变成batch_first=False outputs = model(inputs, targets, tf_ratio)# outputs (tgt_len - 1, batch_size, target_vocab_size)# view ( (tgt_len-1) * batch_size, target_vocab_size)outputs = outputs.view(-1, outputs.shape[2])# targets 去掉所有的bos token# view ((tgt_len-1) * batch_size, ) targets = targets[1:].view(-1)# 计算损失loss = criterion(outputs, targets)loss.backward()with no_grad():# 梯度裁剪grad_clipping(model, clip)optimizer.step()epoch_loss += loss.item()# 每个样本的平均损失return epoch_loss / len(data_iter)
同时实现在验证集上评估的函数:
def evaluate(model, data_iter, criterion, device):model.eval()epoch_loss = 0with no_grad():for batch in data_iter:inputs, targets = [x.to(device).T for x in batch]outputs = model(inputs, targets, 0) # 评估时不用teacher forcingoutputs = outputs.view(-1, outputs.shape[2])targets = targets[1:].view(-1)loss = criterion(outputs, targets)epoch_loss += loss.item()return epoch_loss / len(data_iter)
最终定义训练函数:
def train(model, num_epochs, train_iter, valid_iter, optimizer, criterion, clip, device, tf_ratio):best_valid_loss = float('inf')for epoch in tqdm(range(1, num_epochs + 1), desc="Training", leave=False):train_loss = train_epoch(model, train_iter, optimizer, criterion, clip, device, tf_ratio)valid_loss = evaluate(model, valid_iter, criterion, device)if valid_loss < best_valid_loss:best_valid_loss = valid_lossmodel.save()tqdm.write(f"epoch {epoch:3d} , train loss: {train_loss:.4f} , validate loss: {valid_loss:.4f}, best validate loss: {best_valid_loss:.4f}")
训练过程如下:
Source vocabulary size: 7859, Target vocabulary size: 5921
max_src_len: 44, max_tgt_len:40
Source vocabulary size: 7859, Target vocabulary size: 5921
max_src_len: 33, max_tgt_len:30
Seq2seq((encoder): Encoder((embedding): Embedding(7859, 256, padding_idx=0)(rnn): GRU(input_size=256, hidden_size=512, num_layers=2, dropout=0.5, bidirectional=True)(dropout): Dropout(p=0.5))(decoder): Decoder((embedding): Embedding(5921, 256, padding_idx=0)(rnn): GRU(input_size=256, hidden_size=512, num_layers=2, dropout=0.5)(fc_out): Linear(in_features=512, out_features=5921, bias=True)(dropout): Dropout(p=0.5))
)
TGT_PAD_IDX is 0
Training: 10%|█ | 1/10 [06:42<1:00:18, 402.01s/it]Save module to model.pkl
epoch 1 , train loss: 0.0696 , validate loss: 0.0673, best validate loss: 0.0673
Training: 20%|██ | 2/10 [13:21<53:23, 400.49s/it] Save module to model.pkl
epoch 2 , train loss: 0.0554 , validate loss: 0.0598, best validate loss: 0.0598
Save module to model.pkl
epoch 3 , train loss: 0.0485 , validate loss: 0.0578, best validate loss: 0.0578
Training: 40%|████ | 4/10 [27:08<40:54, 409.05s/it]Save module to model.pkl
epoch 4 , train loss: 0.0441 , validate loss: 0.0554, best validate loss: 0.0554
Training: 50%|█████ | 5/10 [33:53<33:57, 407.60s/it]Save module to model.pkl
epoch 5 , train loss: 0.0405 , validate loss: 0.0553, best validate loss: 0.0553
Save module to model.pkl
epoch 6 , train loss: 0.0377 , validate loss: 0.0550, best validate loss: 0.0550
Training: 70%|███████ | 7/10 [47:19<20:14, 405.00s/it]epoch 7 , train loss: 0.0354 , validate loss: 0.0555, best validate loss: 0.0550
epoch 8 , train loss: 0.0333 , validate loss: 0.0552, best validate loss: 0.0550
Training: 90%|█████████ | 9/10 [1:00:35<06:41, 401.47s/it]epoch 9 , train loss: 0.0315 , validate loss: 0.0555, best validate loss: 0.0550
epoch 10 , train loss: 0.0299 , validate loss: 0.0552, best validate loss: 0.0550
可以看到,整个过程哪怕在GPU上跑也是挺久的,由于RNN无法并行化,这在很大程度上影响了速度,除非也像Pytorch一样,将核心代码迁移到C++实现,后面有机会进行这样的尝试。
我们重复造轮子的目的不是替代Pytorch等深度学习框架,而是为了了解它的实现原理,让我们更好地使用Pytorch。
这里的train loss和validate loss看起来很小,因为求的是平均。好在验证损失确实也下降了。
后面几篇文章还是关于seq2seq的,我们会尝试优化它的效果,具体如何优化,请看下文分解。
完整代码
点此 → Github