龙信年终技术考核wp
容器密码:MjAyNeWKoOayuQ==
假期里打的第一场取证比赛,一开始名次还挺高,后面服务器不太会做了,排名直接狂掉,获奖的名额太少了。其实上学期打的第一场取证也是龙信办的龙信杯,真的好难,还是这个友好。
1. 分析手机备份文件,该机主的QQ号为?(标准格式:123)
1203494553
手机备份文件里面内容比较少,只能分析出一点点内容。
所以直接看微信,因为微信可以绑定qq号,这里可以看见关联了一个qq账号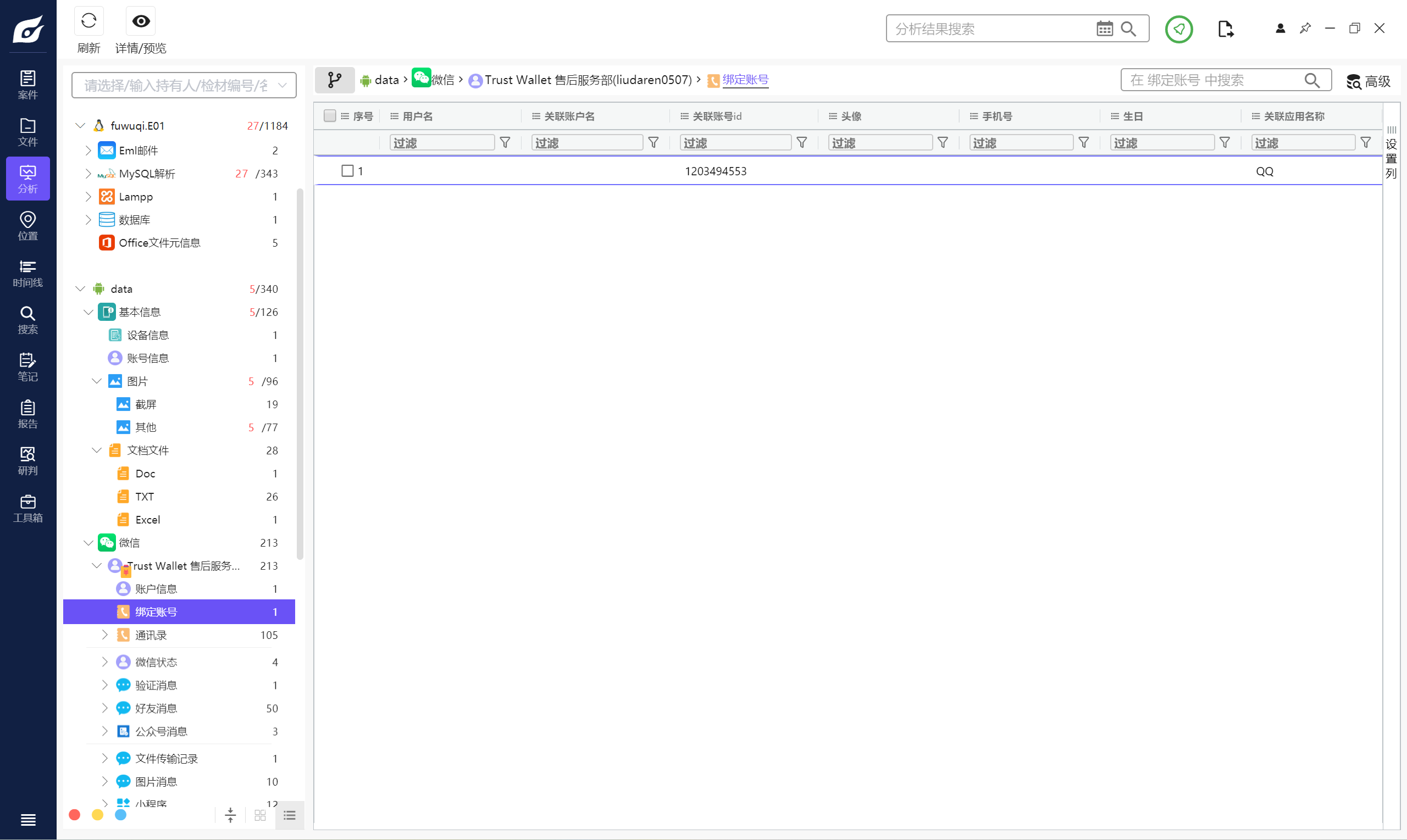
2. 分析手机备份文件,该机主的微信号为?(标准格式:abcdefg)
liudaren0507
直接就是用户id这个,后面那个是微信为每个用户分配的内部ip,就是如果创建了一个新微信,它的微信号就是这个内部id。但是这里显然是前面这个用户id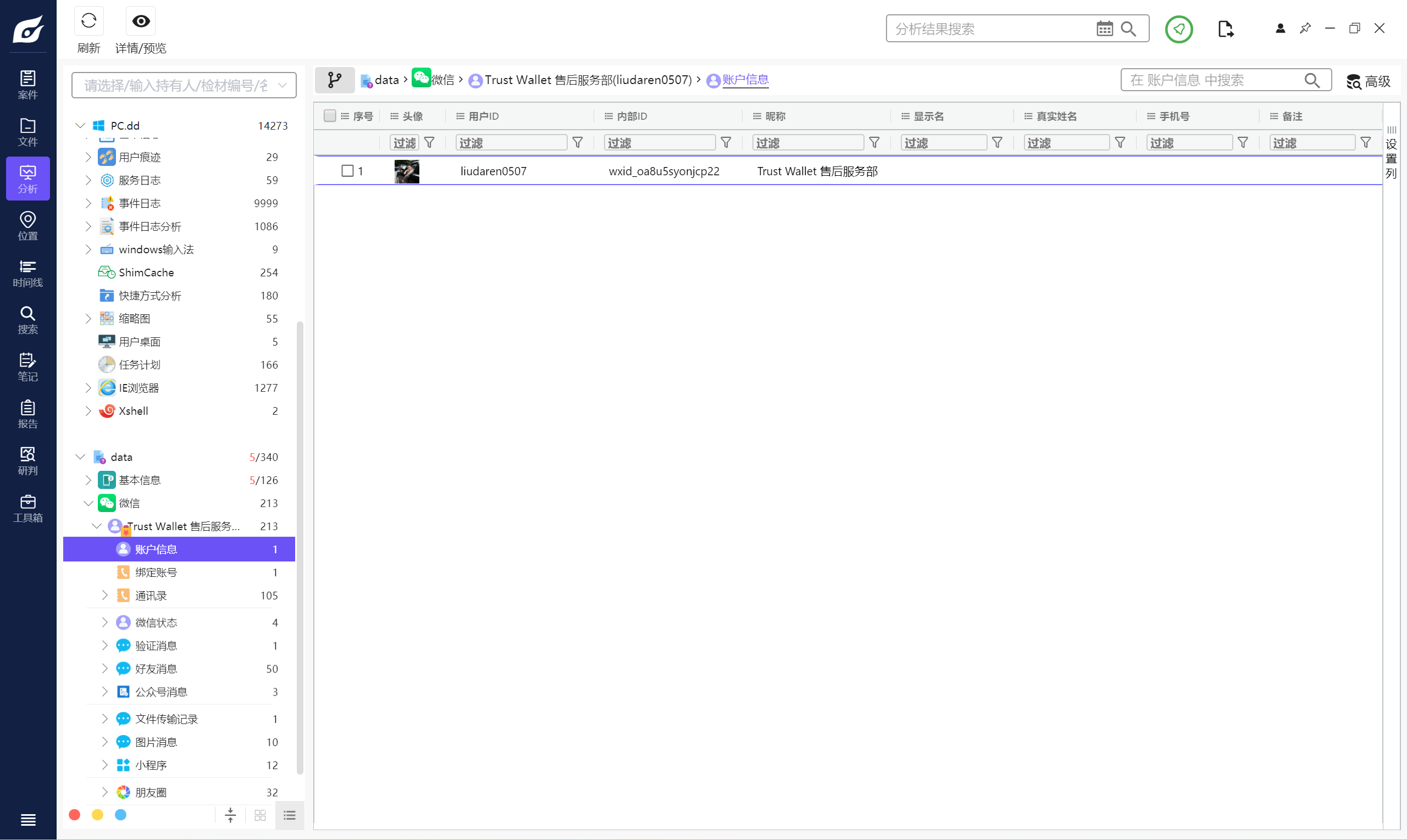
3. 请问该手机机主微信共有_____个现有好友?(标准格式:12)
15
现在回来复现才发现比赛的时候这道题做错了,好友列表里面16个用户,包括机主,所以是15个好友。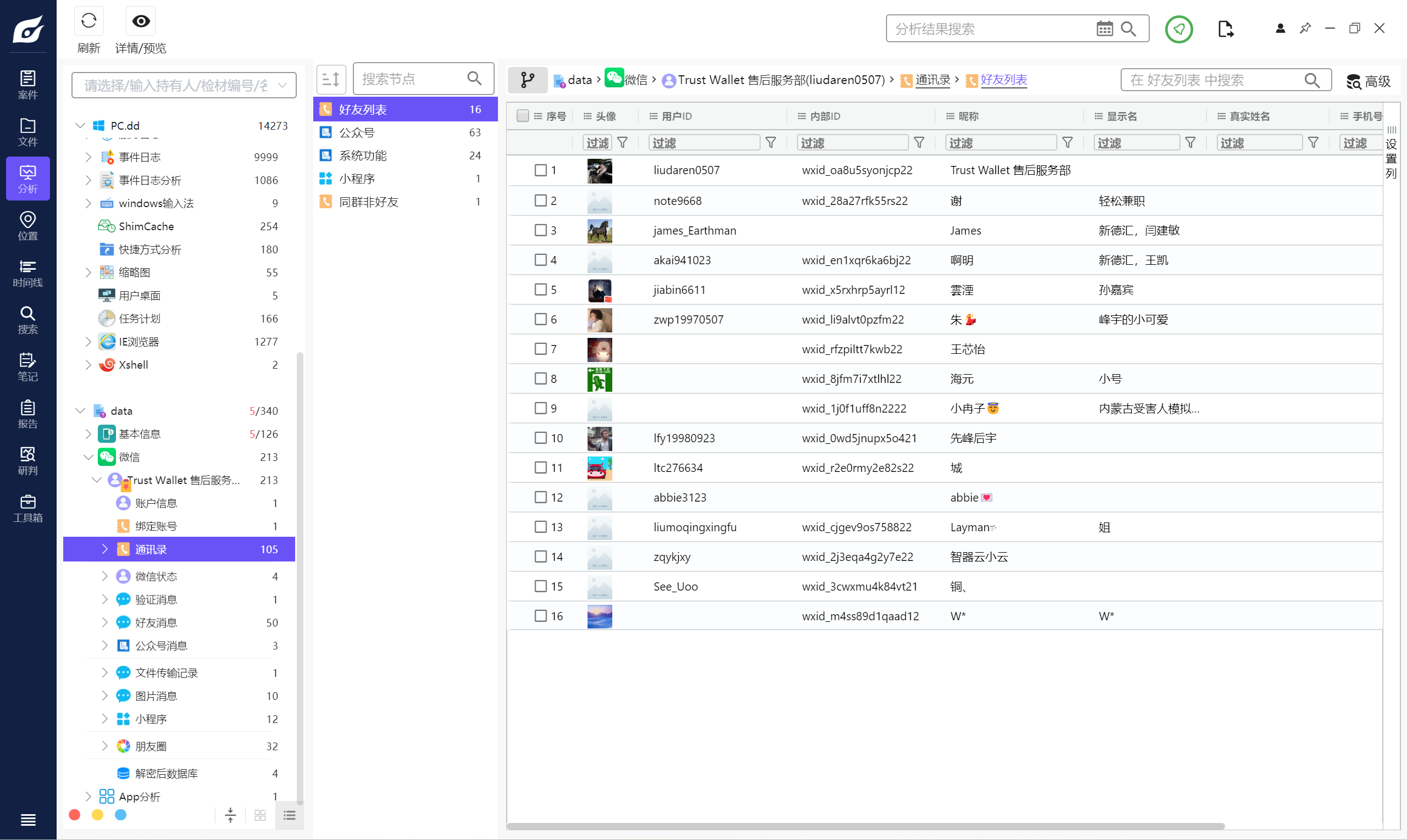
4. 请分析机主的银行卡卡号是多少?(标准格式:按照实际值填写)
6231276371853671344
手机检材里面没有多少信息了,直接看看没有被分析出来的内容,发现有个可疑的包,应该就是勇哥发过来的那个apk了
找到数据库,稍微分析一下聊天记录,发现第一个就是机主的银行卡号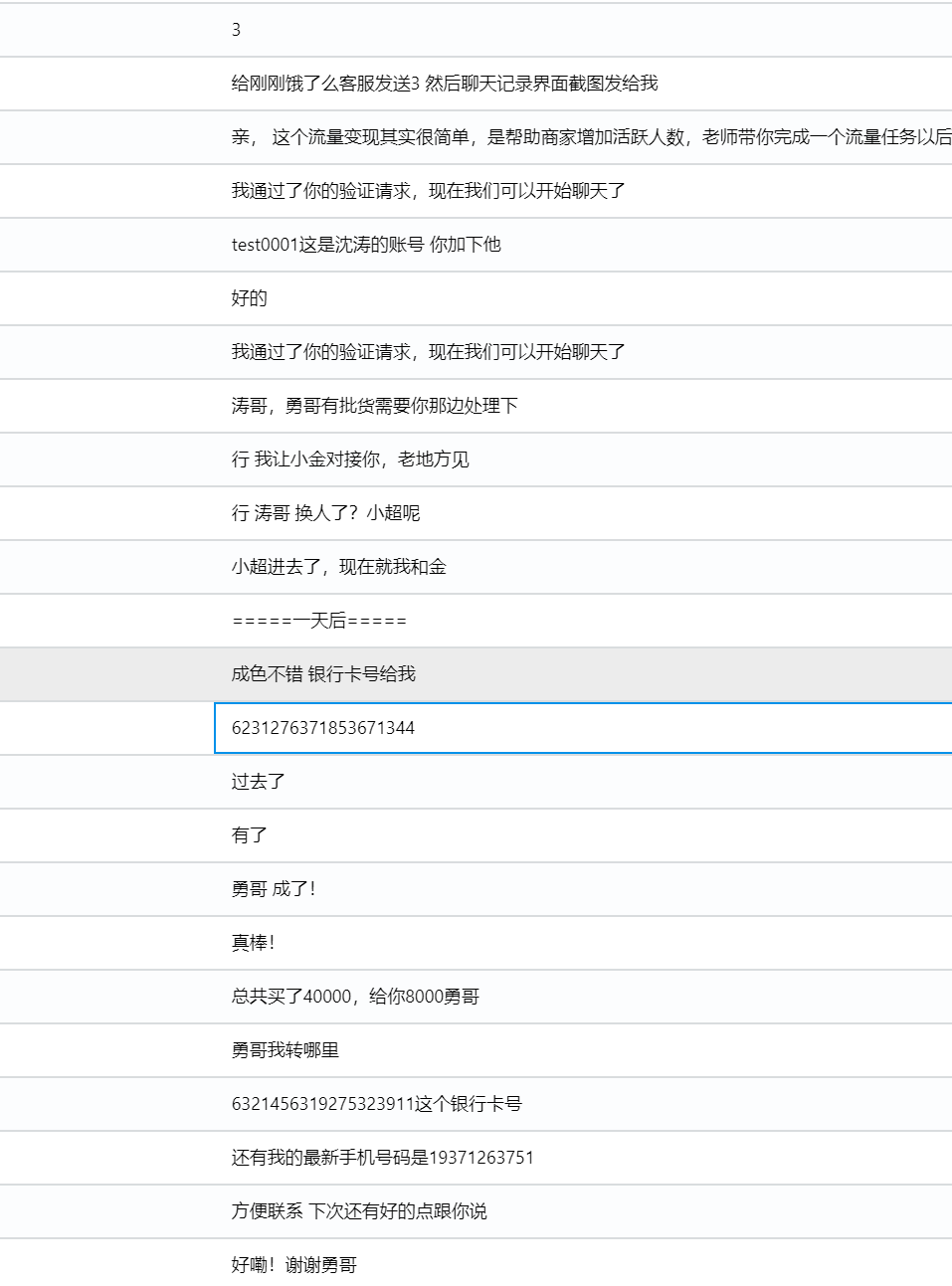
5. 请分析出幕后老大王子勇的最新手机号码是多少?(标准格式:1234567)
19371263751
接上题最后一张图,说了最新的手机号
6. 请分析幕后老大的可疑的银行卡卡号是多少?(标准格式:按照实际值填写)
6321456319275323911
同样的位置,就是上面手机号的上一行聊天记录
7. 请问计算机的网卡MAC地址是多少 。(标准格式:00-0S-25-C6-E3-5F)
00-0C-29-C5-3C-F8
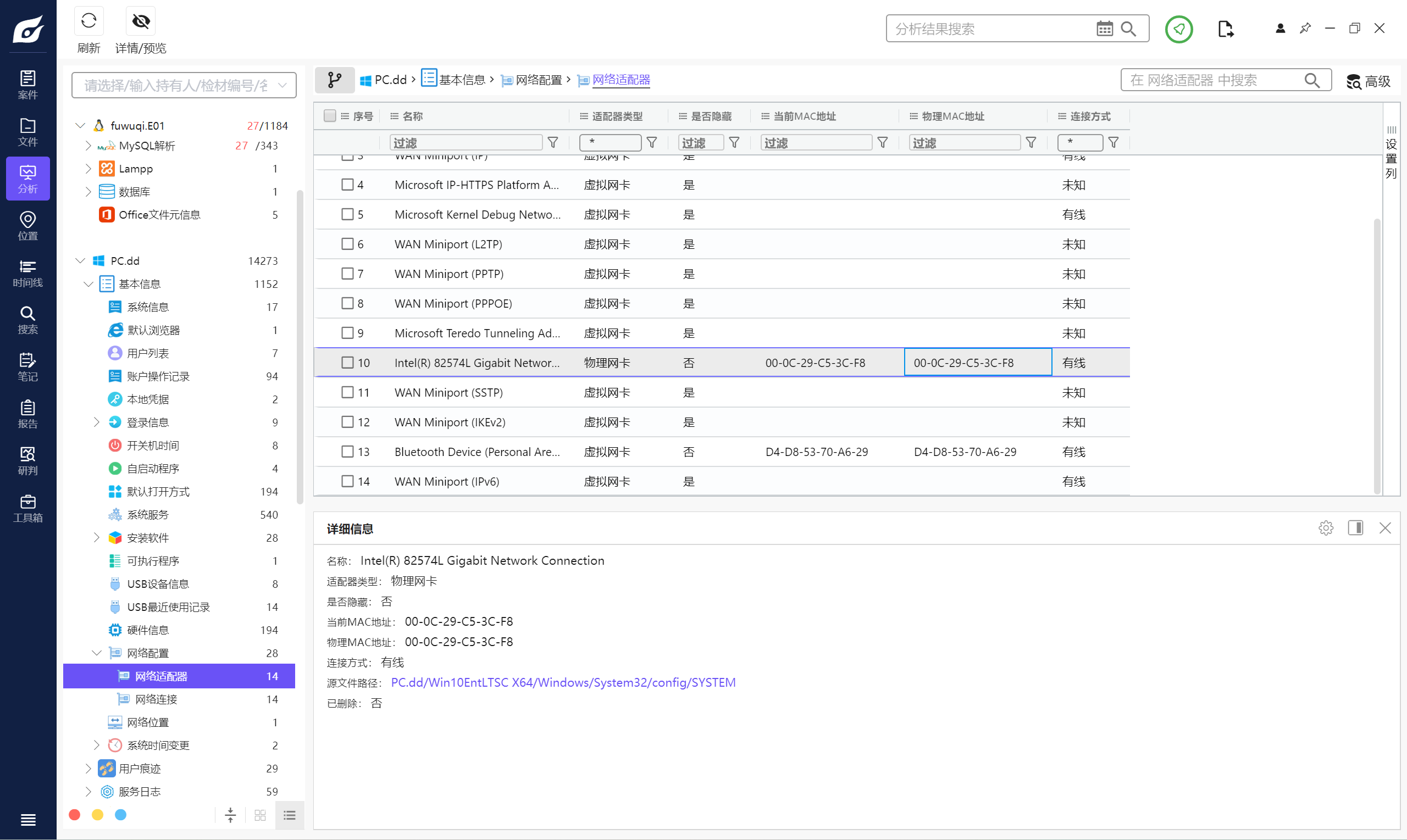
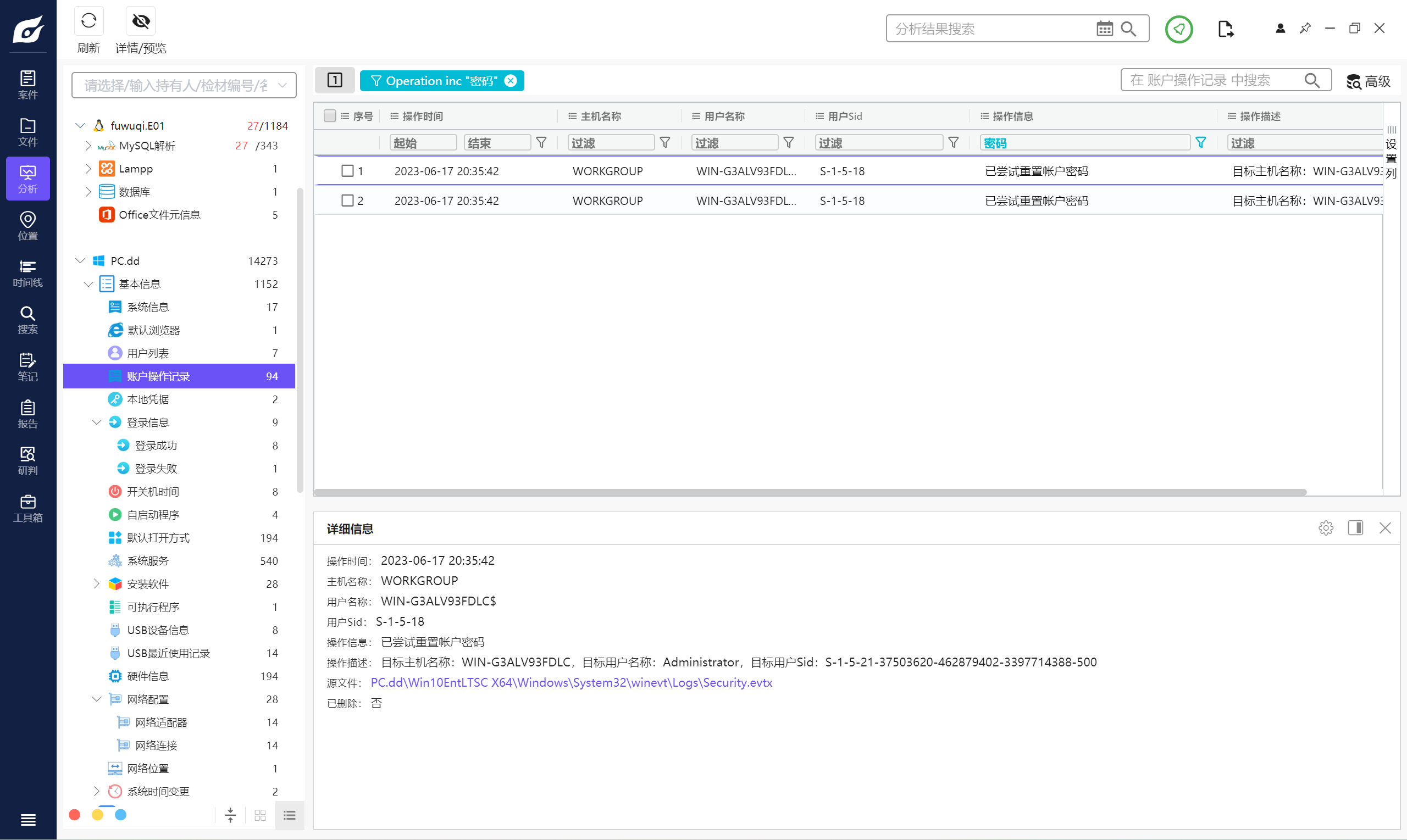
8. 请问计算机管理员用户的设置密码时间是什么时候 。(标准格式:1970/06/17 23:25:41)
2023/06/17 20:35:42
9.请分析数据文件夹中的表格文件共有有多少个两个字的姓名人数。(标准格式:10)
908
直接ai跑脚本然后就行了,下面几题同理
import pandas as pd
import osdef count_two_character_names(excel_files):two_character_names_count = 0for file in excel_files:try:# 验证文件是否存在if not os.path.exists(file):print(f"警告: 文件 {file} 不存在")continue# 读取Excel文件df = pd.read_excel(file)# 检查是否存在姓名列,假设列名为 '姓名'if '姓名' in df.columns:# 筛选出姓名为两个字的行two_character_names = df[df['姓名'].apply(lambda x: isinstance(x, str) and len(x) == 2)]# 统计数量two_character_names_count += len(two_character_names)else:print(f"警告: 文件 {file} 中不存在 '姓名' 列")except Exception as e:print(f"错误: 无法读取文件 {file},错误信息: {e}")print(f"当前工作目录: {os.getcwd()}")return two_character_names_count# 获取脚本所在目录
script_directory = os.path.dirname(os.path.abspath(__file__))# 构造文件的绝对路径
excel_files = [os.path.join(script_directory, 'fake_data_1_prefix_1.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_2.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_3.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_4.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_5.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_6.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_7.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_8.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_9.xlsx'),os.path.join(script_directory, 'fake_data_1_prefix_10.xlsx')
]# 打印文件路径以确认
for file in excel_files:print(f"文件路径: {file}")# 统计并打印结果
result = count_two_character_names(excel_files)
print(f"十个Excel文件中姓名为两个字的总数: {result}")
10.请分析数据文件夹中表格共有表格共有多少个男性。(标准格式:10)
479
import pandas as pd
import os
import re# 文件前缀和后缀
file_prefix = 'fake_data_1_prefix_'
file_extension = '.xlsx'# 男性计数
total_male_count = 0# 遍历所有文件
for i in range(1, 11): # 假设文件名从 1 到 10file_name = f"{file_prefix}{i}{file_extension}"print(f"正在检查文件: {file_name}") # 调试信息if os.path.exists(file_name):try:# 读取 Excel 文件df = pd.read_excel(file_name)# 检查是否存在身份证号列if '身份证号' not in df.columns:print(f"警告: 文件 {file_name} 中缺少身份证号列")continue# 确保身份证号列中的所有值都是字符串df['身份证号'] = df['身份证号'].astype(str)# 定义一个函数来根据身份证号判断性别def get_gender_from_id(id_number):if len(id_number) == 18: # 确保是18位身份证号gender_digit = int(id_number[16]) # 第17位return '男' if gender_digit % 2 != 0 else '女'return None# 应用函数到身份证号列,创建性别列df['性别'] = df['身份证号'].apply(get_gender_from_id)# 统计男性数量male_count = (df['性别'] == '男').sum()print(f"文件 {file_name} 中男性数量为: {male_count}")# 累加男性数量total_male_count += male_countexcept Exception as e:print(f"错误: 在处理文件 {file_name} 时发生错误: {e}")else:print(f"警告: 文件 {file_name} 不存在")# 打印总男性数量
print(f"数据文件夹中所有表格的男性总数为: {total_male_count}")
11.请分析数据文件夹中表格共有多少姓陈的人。(标准格式:10)
106
import pandas as pd# 初始化计数器
chen_count = 0# 假设表格文件名是 'table1.xlsx', 'table2.xlsx', ..., 'table10.xlsx'
for i in range(1, 11):file_name = f'fake_data_1_prefix_{i}.xlsx'# 读取Excel文件try:df = pd.read_excel(file_name)# 检查是否存在“姓名”列if '姓名' in df.columns:# 统计姓“陈”的人数chen_count += df[df['姓名'].str.startswith('陈')].shape[0]else:print(f"警告:文件 {file_name} 中没有“姓名”列。")except FileNotFoundError:print(f"警告:文件 {file_name} 未找到。")except Exception as e:print(f"错误:读取文件 {file_name} 时出错:{e}")# 输出统计结果
print(f"总共有 {chen_count} 个姓陈的人。")
12.请分析数据文件夹中表格共有1950年至1970年的人数是多少。(标准格式:10)
419
import pandas as pd
import os
import refile_prefix = 'fake_data_1_prefix_'
file_extension = '.xlsx'
total_count = 0 # 用于统计1950年至1970年出生的总人数# 正则表达式用于从18位身份证号中提取出生年份
birth_year_pattern = re.compile(r'(\d{6})(\d{8})(\d{3}[\dXx])')for i in range(1, 11):file_name = f"{file_prefix}{i}{file_extension}"if os.path.exists(file_name):try:df = pd.read_excel(file_name)# 检查身份证号列是否存在if '身份证号' not in df.columns:print(f"警告: 文件 {file_name} 中缺少身份证号列")continue# 确保身份证号列中的所有值都是字符串df['身份证号'] = df['身份证号'].astype(str)# 提取出生年份def extract_birth_year(id_number):match = birth_year_pattern.match(id_number)if match:birth_date_str = match.group(2)[:4] # 提取YYYY部分return int(birth_date_str)return Nonedf['出生年份'] = df['身份证号'].apply(extract_birth_year)# 筛选出1950年至1970年出生的记录mask = (df['出生年份'] >= 1950) & (df['出生年份'] <= 1970)# 统计符合条件的记录数total_count += mask.sum()except Exception as e:print(f"错误: 在处理文件 {file_name} 时发生错误: {e}")else:print(f"警告: 文件 {file_name} 不存在")print(f"1950年至1970年间出生的总人数为: {total_count}")13. 请问计算机映射盘的挂载位置盘符是什么 。(标准格式:B)
Z
仿真起来直接看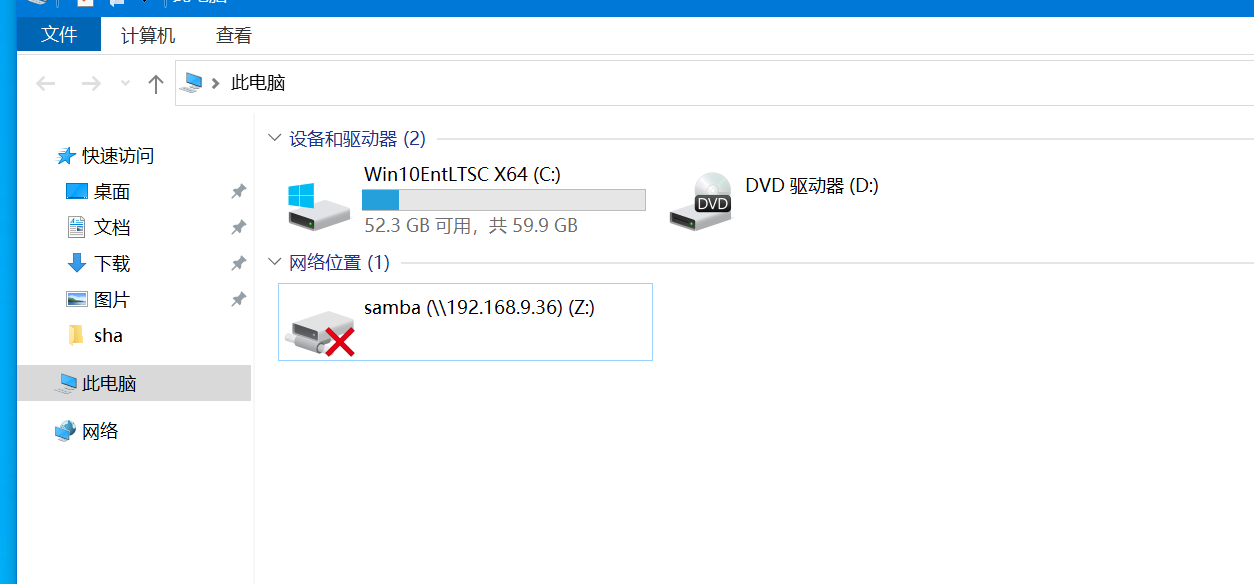
14. 请问机主邮箱账号的显示名称是什么 。(标准格式:abcd)
kkkk
仿真服务器,然后发现计算机里面有网络映射,连上去,打开foxmail
15. 请问机主邮箱的定时收取邮件是间隔多少分钟 。(标准格式:10)
15
在邮箱设置里面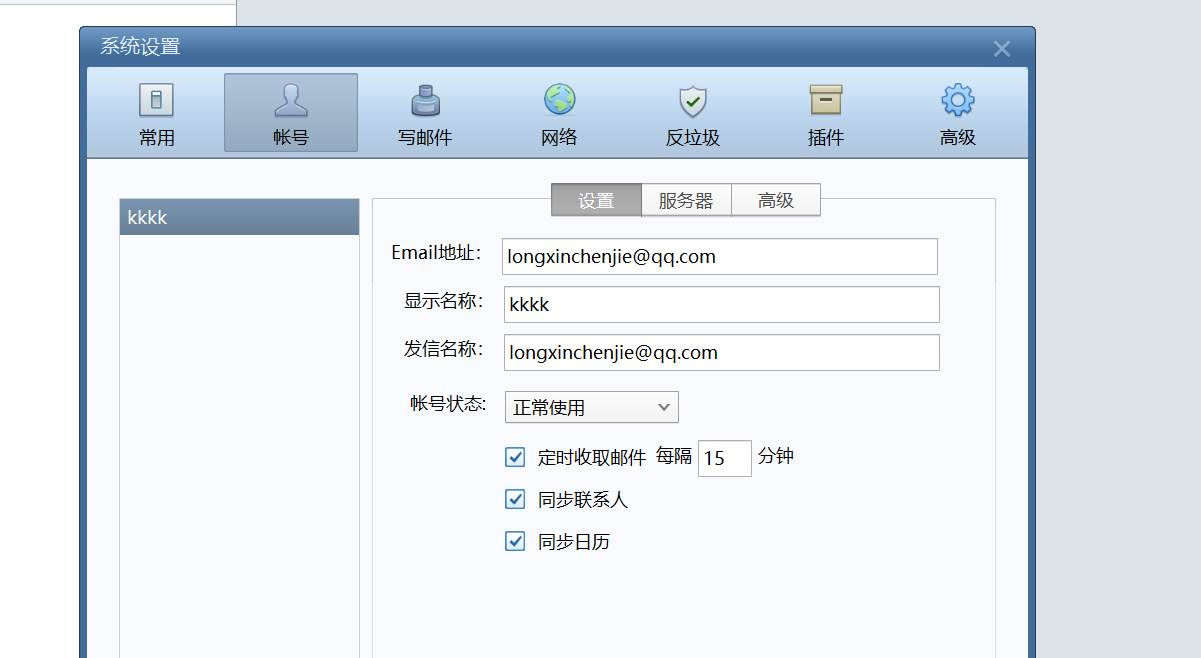
16. 请问机主邮箱最近⼀次发送邮件的主题是什么 。(标准格式:按照实际值填写)
我是卧龙
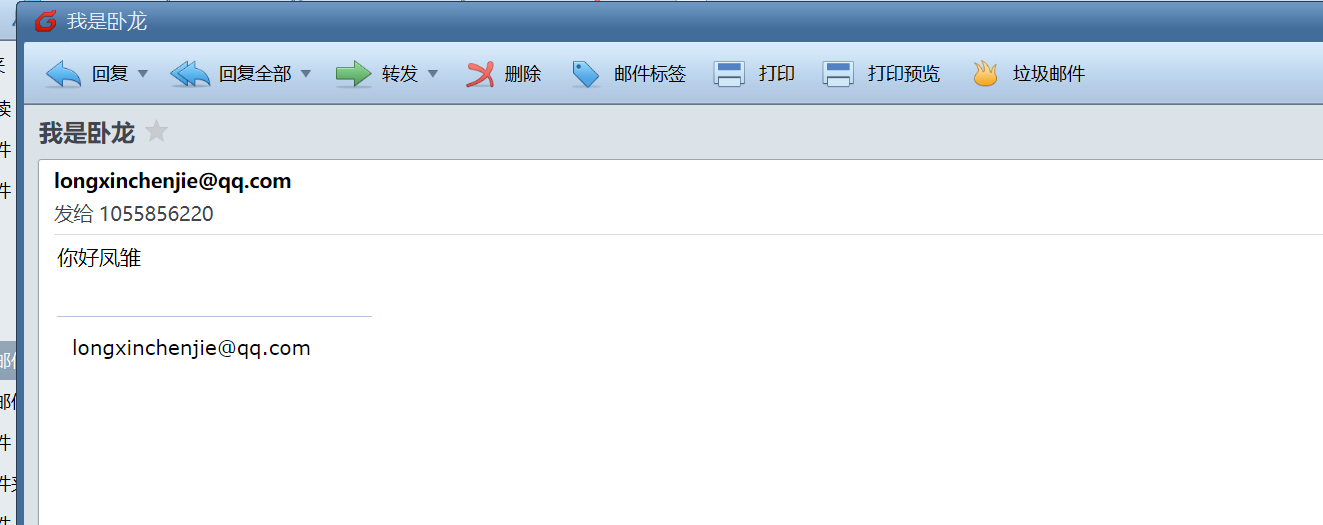
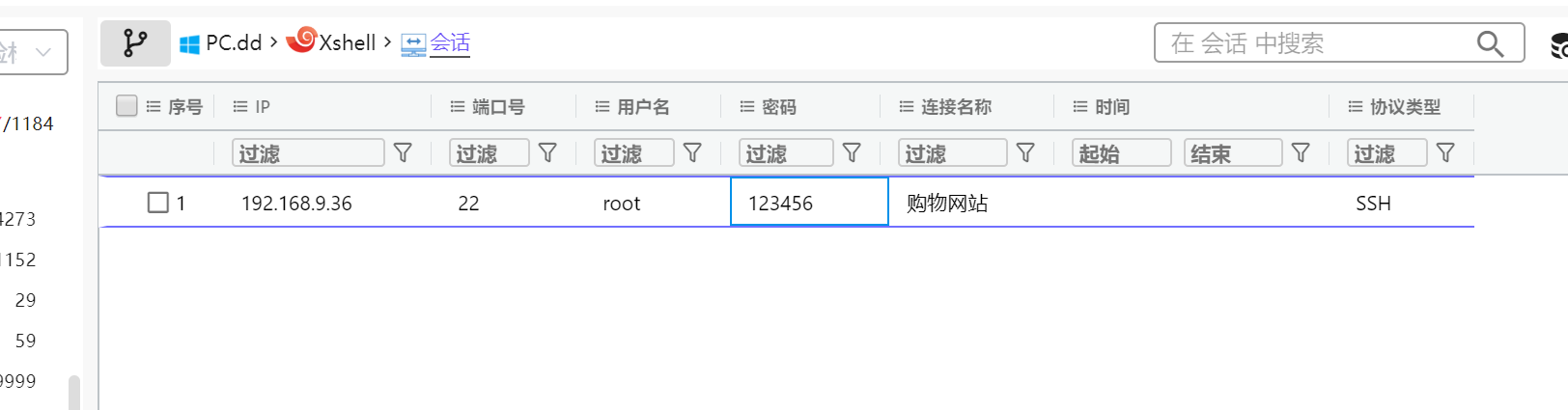
17. 请问购物网站服务器的root密码是什么 。(标准格式:按照实际值填写)
123456
18. 请问购物网站管理后台admin用户的密码是什么 。(标准格式:按照实际值填写)
longxin
要找密码,就需要找数据库,先连上宝塔,面板里没看见有数据库,日志里可以发现是把数据库删了
所以需要去找这个数据库文件,注意到文档目录下面有一个一个G大小的js文件,结合桌面上有vc软件,推测这是加密容器,然后在服务器里面有miyao.txt文件,于是用密钥文件解密容器的方法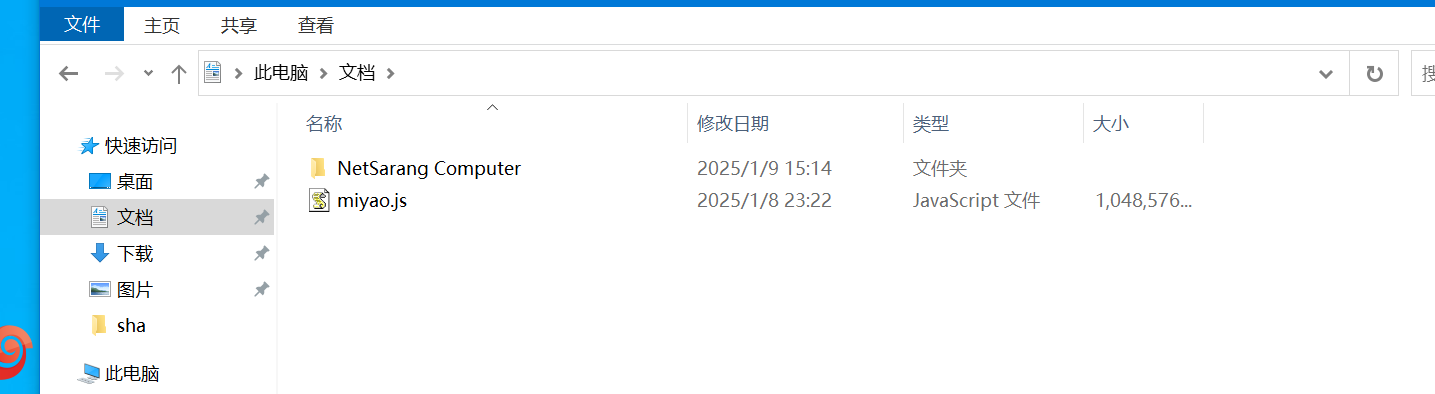
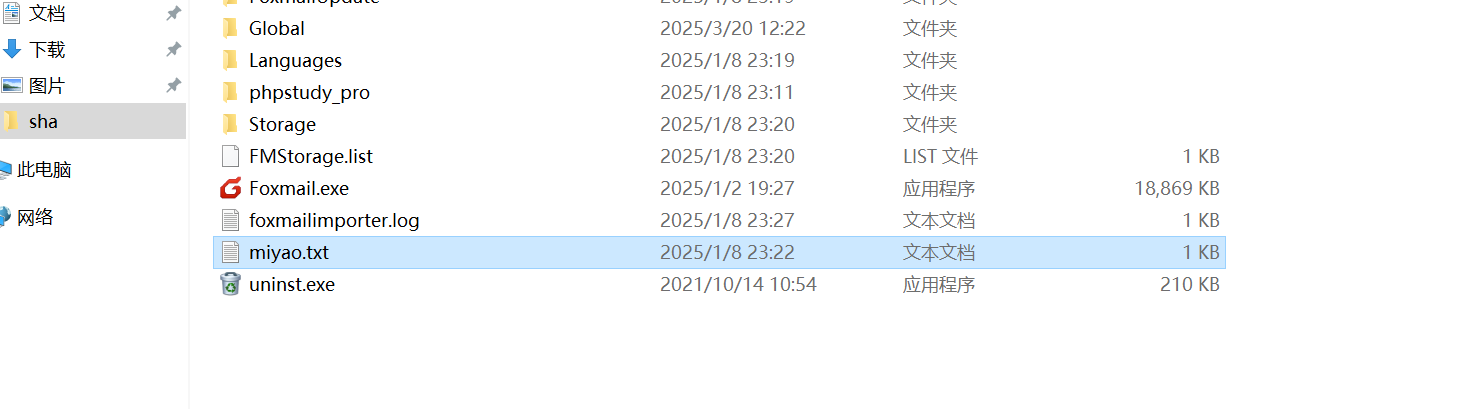
恢复数据库,找到加密的密钥
找一下密码加密逻辑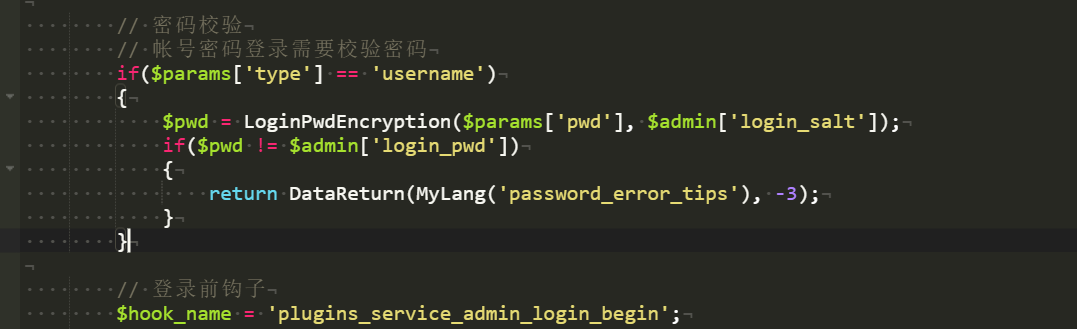
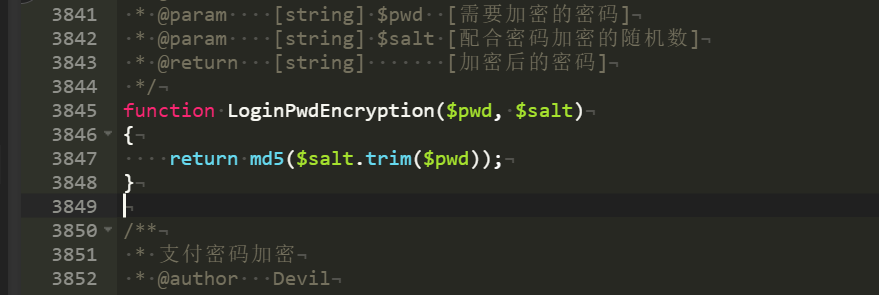
cmd5说这是需要付费的内容,这里考虑用hashcat爆破密码,理论上应该需要从少的位数慢慢爆到大的位数以及尝试多种密码组合可能,但是这里已知是知道答案复原过程,主要是了解工具使用。
hashcat.exe -m 20 -a 3 -w 4 hash.txt "?l?l?l?l?l?l?l"
-m 指定哈希类型
-a 代表攻击模式(attack mode)
-w 代表 工作负载级别(workload profile),影响计算性能: 1 -> 最低,占用最少的 CPU/GPU 资源 2 -> 适中(默认) 3 -> 高 4 -> 最大性能,但可能会导致系统卡顿 hash.txt 存放待破解的哈希值。 格式示例(如果是 MD5($salt.$pass),通常是 salt:hash 形式)
?l?l?l?l?l?l?l 掩码模式(mask attack),表示密码的格式: ?l -> 小写字母(a-z) ?u -> 大写字母(A-Z) ?d -> 数字(0-9) ?s -> 特殊字符(!@#$%^& 等) * ?a -> 所有字符(?l?u?d?s 组合) ?l?l?l?l?l?l?l 表示: 7 位的小写字母密码(例如:abcdefg, qwertyu)

19. 该购物网站上架了几个支付方式 。(标准格式:10)
4
导入数据库,然后修改配置文件
这里卡了好一会,数据库都导入对了,但是网站起不来,发现是ip有问题,网站起来之后找后台地址,日志中翻翻就找到了,密码是上一题爆破出来的密码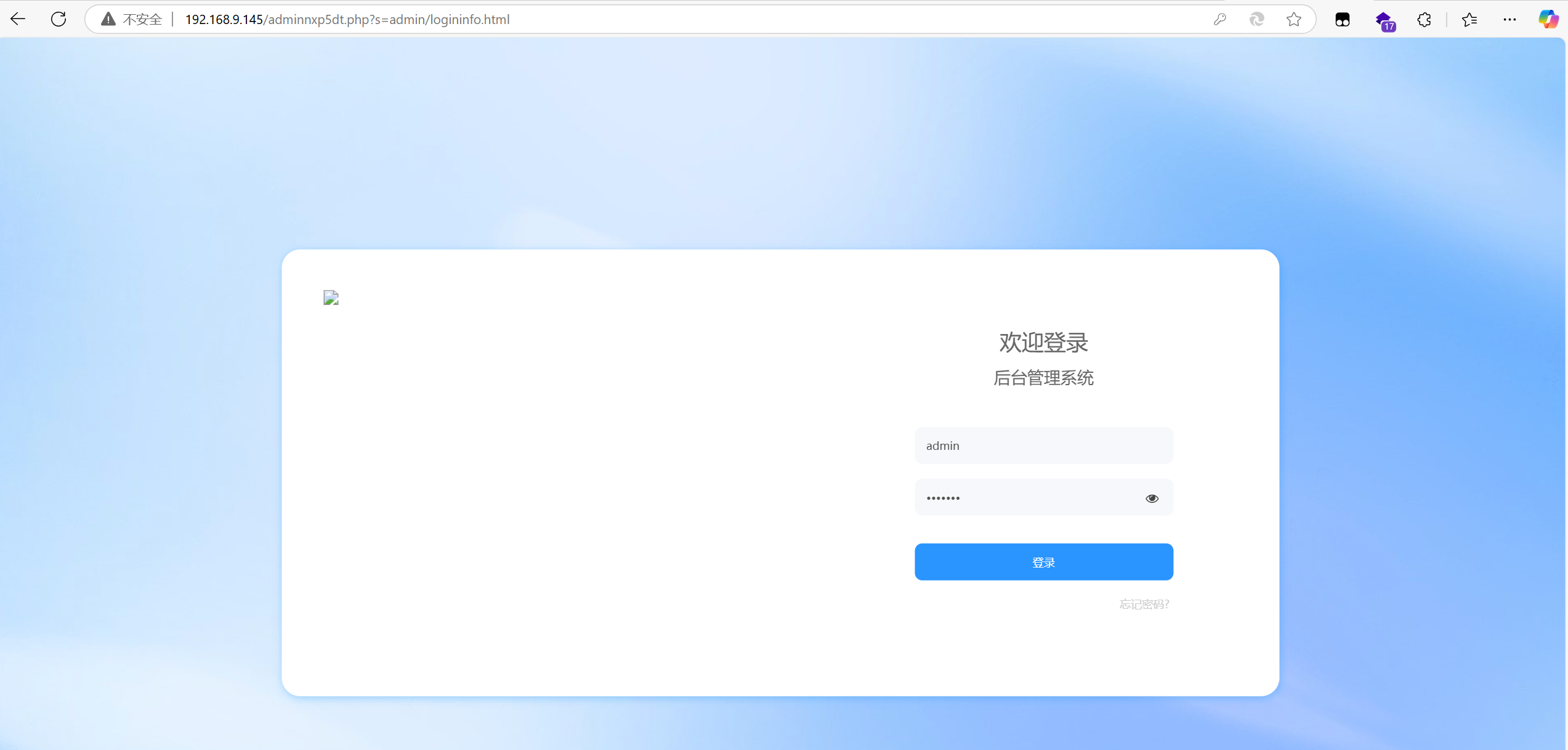
找到支付方式,本来以为是五种,发现有一种没有启用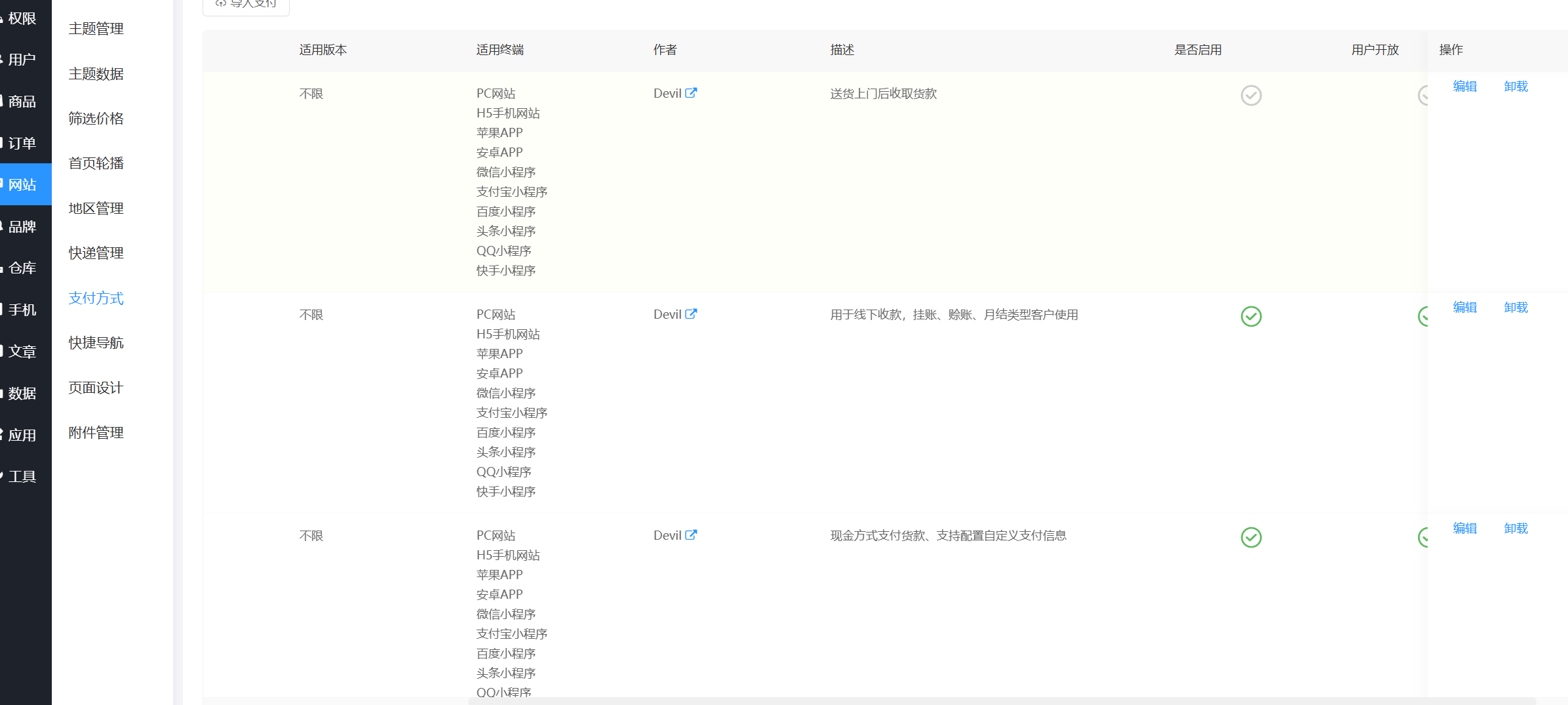
20.该购物网站管理后台的登录地址是什么 。(标准格式:/adminxx5?=admin/admin.html)
/adminnxp5dt.php?s=admin/logininfo.html
接上题
21. 该购物网站共上架多少商品 。(标准格式:10)
29
一共29个商品都是上架了的,或者在前台也能看一共的商品数量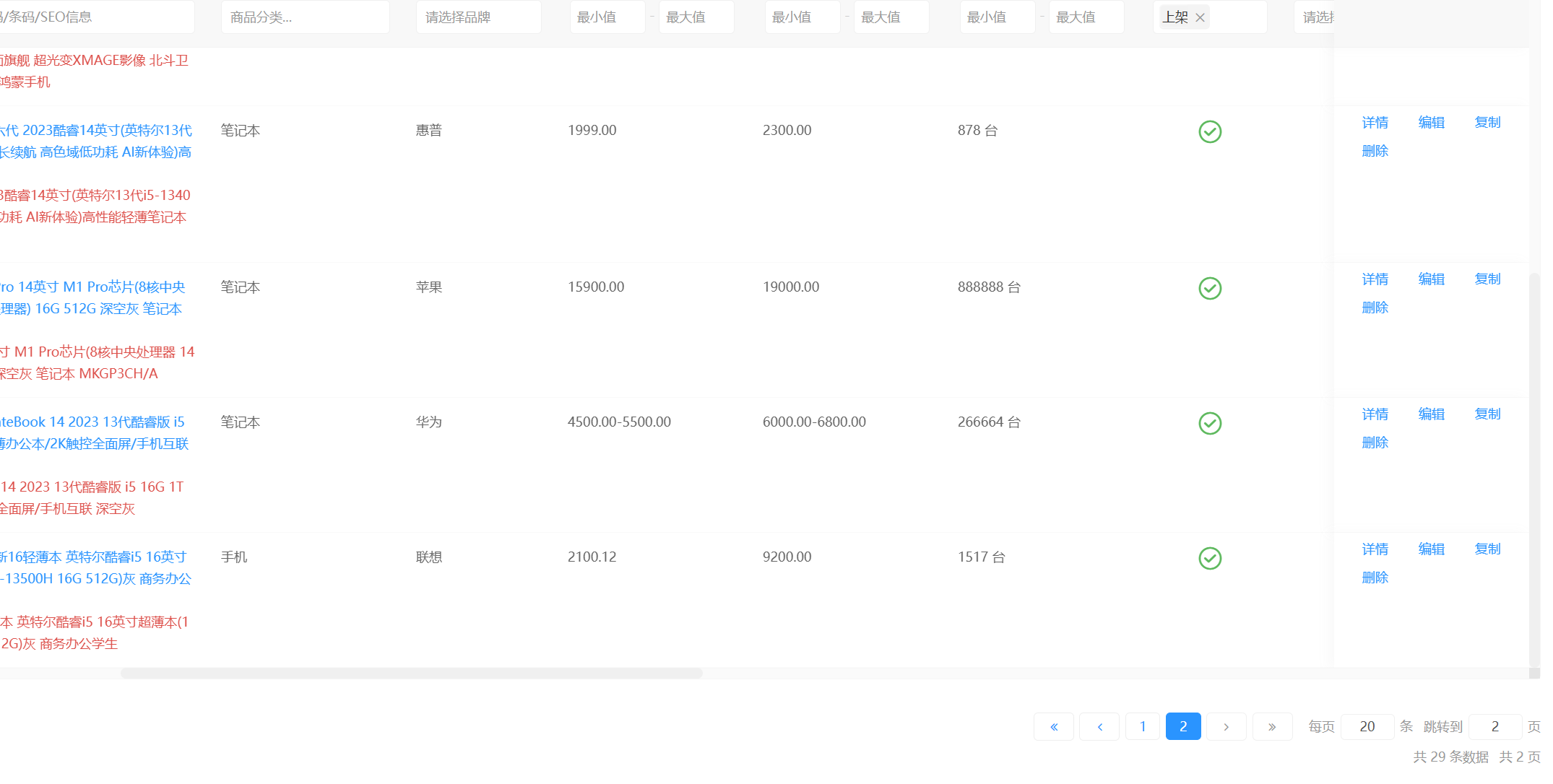
22. 该购物网站的数据库配置的文件名是什么 。(标准格式:db.php)
database.php
前面出现过
23. 该购物网站上架的最新的商品的上架时间是什么 。(标准格式:2025-01-01 11:11:11)
2025-01-08 22:03:50
看了很多wp都说是后面那个更新时间,个人感觉不对,创建时间就是上架时间,我进入编辑之后保存了,没有进行任何修改,更新时间已经变成刚刚进行更改的时间了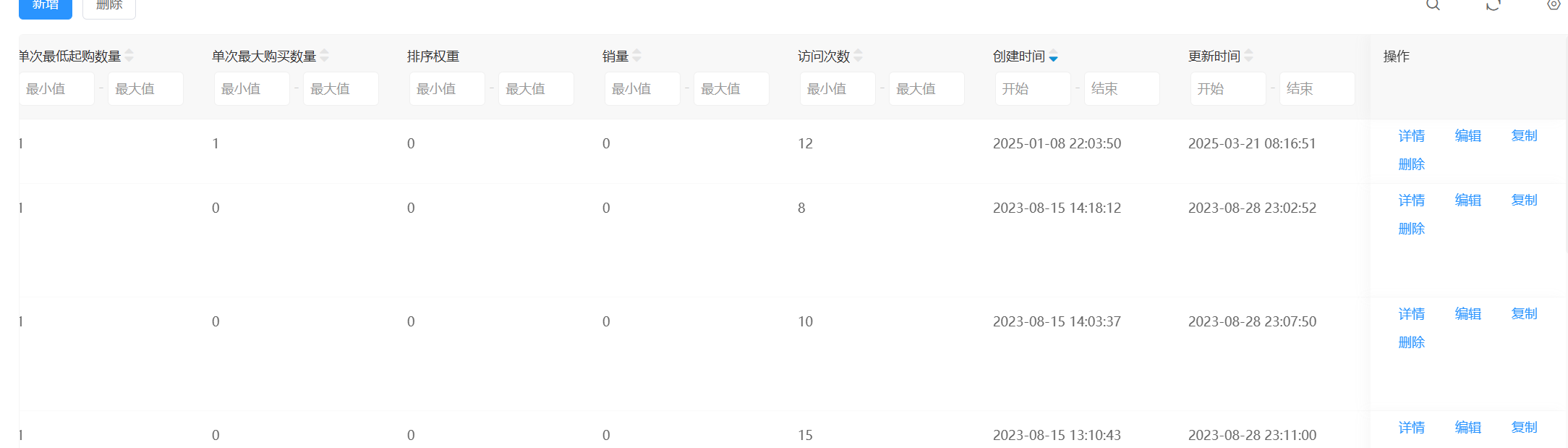
24. 服务器的ssh对外端口是什么 。(标准格式:22)
22

25. Java网站备份文件中配置文件(*.properties) 的SHA256校验值后六位是什么 。(标准格 式:全小写)
4dd523
这题我当时直接在服务器里面找到了内容,但是发现不对,应该服务器里面里面是已经起了的东西。根据川佬的博客,可以在宝塔的备份文件夹里面找到一个gz压缩文件。发现文件损坏,修改文件头,解压。还是能发现两个文件的差别的,计算文件的sha256值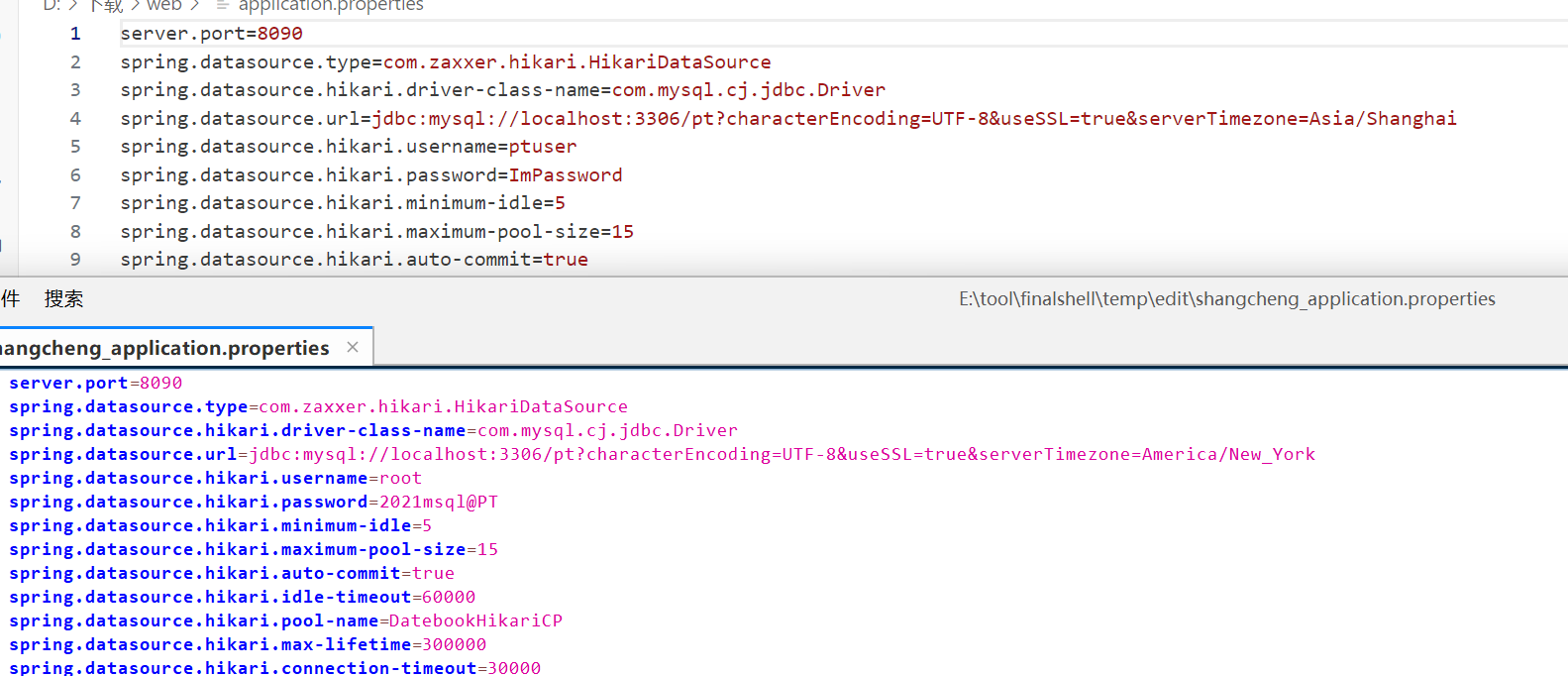
26. Java网站使用的MySQL数据库名称为() 。(标准格式:按照实际值填写)
pt

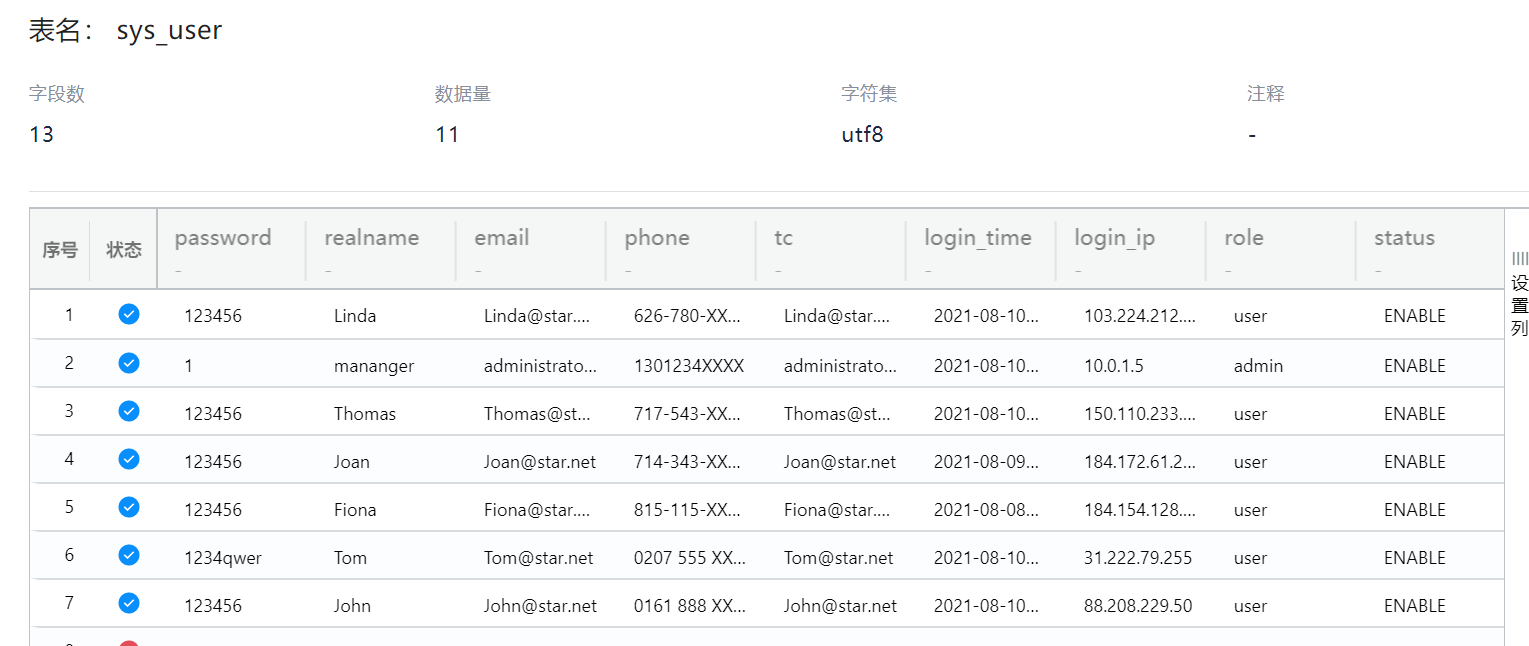
27. Java网站数据库表sys_user中的用户类型为user的用户数为() 。(标准格式:按照实际值填写)
6
火眼可以搜到这个文件
找到同目录下面还有一共ibd文件,本来还在思考如何恢复这两个文件,发现火眼里面已经把这个恢复了
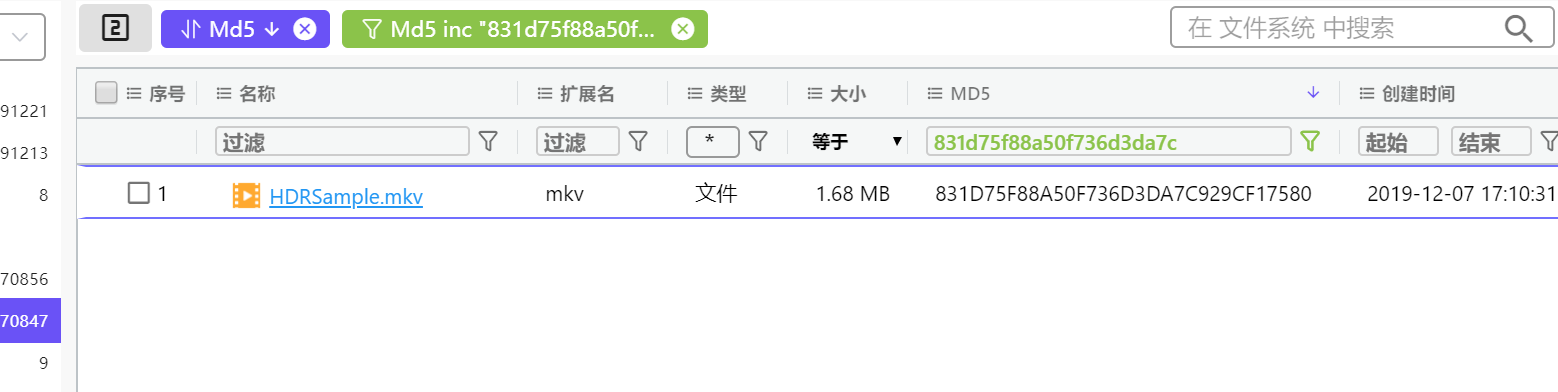
28. 请问md5值为831d75f88a50f736d3da7c929cf17580的文件名是什么 。(标准格式:按照实际值填写)
831D75F88A50F736D3DA7C929CF17580
稍微算算就出了,不知道为什么当时没有做这题