分享一个之前在公司内其它团队找到帮忙排查的一个后端服务连接超时问题,问题的表现是服务部署到线上后出现间歇性请求响应非常慢(大于10s),但是后端业务分析业务日志时却没有发现慢请求,另外由于服务容器`livenessProbe`也出现超时,导致容器出现间歇性重启。
分享一个之前在公司内其它团队找到帮忙排查的一个后端服务连接超时问题,问题的表现是服务部署到线上后出现间歇性请求响应非常慢(大于10s),但是后端业务分析业务日志时却没有发现慢请求,另外由于服务容器`livenessProbe`也出现超时,导致容器出现间歇性重启。分享一个之前在公司内其它团队找到帮忙排查的一个后端服务连接超时问题,问题的表现是服务部署到线上后出现间歇性请求响应非常慢(大于10s),但是后端业务分析业务日志时却没有发现慢请求,另外由于服务容器livenessProbe也出现超时,导致容器出现间歇性重启。
复现
该服务基于spring-boot开发,通过spring-mvc框架对外提供一些web接口,业务简化后代码如下:
@Controller
@SpringBootApplication
public class Bootstrap {public static void main(String[] args) {SpringApplication.run(Bootstrap.class, args);}@GetMapping("/ping")public String ping() {return "pong";}
}
客户端访问该服务(记为backend)的路径为: client => ingress => backend,客户端的代码简化如下,其实就是在一个循环里面持续访问ingress(这里以一个nginx代替):
import time
import requestswhile True:try:start = time.time()r = requests.get('http://nginx/ping', timeout=(3, 10))spend = int((time.time() - start) * 1000)r.raise_for_status()print(f'{time.strftime("%Y-%m-%dT%H:%M:%S")} OK {spend}ms {r.content.decode("utf-8")}')except requests.HTTPError as err:print(f'{time.strftime("%Y-%m-%dT%H:%M:%S")} HTTP error: {err}')except Exception as err:print(f'{time.strftime("%Y-%m-%dT%H:%M:%S")} Error: {err}')time.sleep(0.1)
下面是一个docker-compose文件构造了一个最小可复现的环境:
version: '3'
services:backend:image: shawyeok/128-slowbackend:backendnginx:image: shawyeok/128-slowbackend:nginxdepends_on:- backendclient:image: shawyeok/128-slowbackend:clientdepends_on:- nginx
通过docker-compose启动后,检查client容器的日志,你将会在client看到间歇性出现read timeout的记录
$ docker-compose up -d
$ docker ps
$ docker logs -f xxx-client-1
2024-05-23T08:02:51 OK 52ms pong
2024-05-23T08:02:51 OK 6ms pong
2024-05-23T08:02:51 OK 3ms pong
2024-05-23T08:02:51 OK 5ms pong
2024-05-23T08:02:51 OK 17ms pong
2024-05-23T08:02:51 OK 14ms pong
2024-05-23T08:02:51 OK 11ms pong
2024-05-23T08:02:51 OK 16ms pong
2024-05-23T08:02:52 OK 7ms pong
2024-05-23T08:02:52 OK 10ms pong
2024-05-23T08:02:52 OK 6ms pong
2024-05-23T08:02:52 OK 8ms pong
2024-05-23T08:03:02 Error: HTTPConnectionPool(host='nginx', port=80): Read timed out. (read timeout=10)
2024-05-23T08:03:12 Error: HTTPConnectionPool(host='nginx', port=80): Read timed out. (read timeout=10)
2024-05-23T08:03:12 OK 15ms pong
2024-05-23T08:03:12 OK 15ms pong
2024-05-23T08:03:12 OK 15ms pong
完整的复现代码在Shawyeok/128-slowbackend,读者看到这里可以先尝试通过上面步骤把环境运行起来自己动手分析一下原因。
分析
今天终于抽出时间来完成这篇文章,读者在看下面分析过程之前,我建议还是先动手用docker-compose把案例复现一下,然后自己尝试分析,分析过程肯定会遇到这样那样的问题,直到dead-end或者分析完了再回过头看我的分析过程,这样在实际工作中遇到类似问题的时候我想更有可能callback。
当然,如果你有别的思路和手段分析这个问题,非常欢迎在评论区分享你的见解。
下面开始回顾一下我当时记录的分析过程。
尝试问题重现时抓取threaddump(进入到backend容器执行命令jstack -l <pid>),主要观察tomcat工作线程池(线程名:http-nio-0.0.0.0-8080-exec-*)的线程状态,发现都是处于等待从线程池队列获取任务的状态,并未见工作线程卡在一些业务操作上:
"http-nio-0.0.0.0-8080-exec-1" #167 daemon prio=5 os_prio=0 tid=0x00007f0461487000 nid=0xb1 waiting on condition [0x00007f043d8fd000]java.lang.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x00000006f99c3ba8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:108)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:33)at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)at java.lang.Thread.run(Thread.java:748)Locked ownable synchronizers:- None
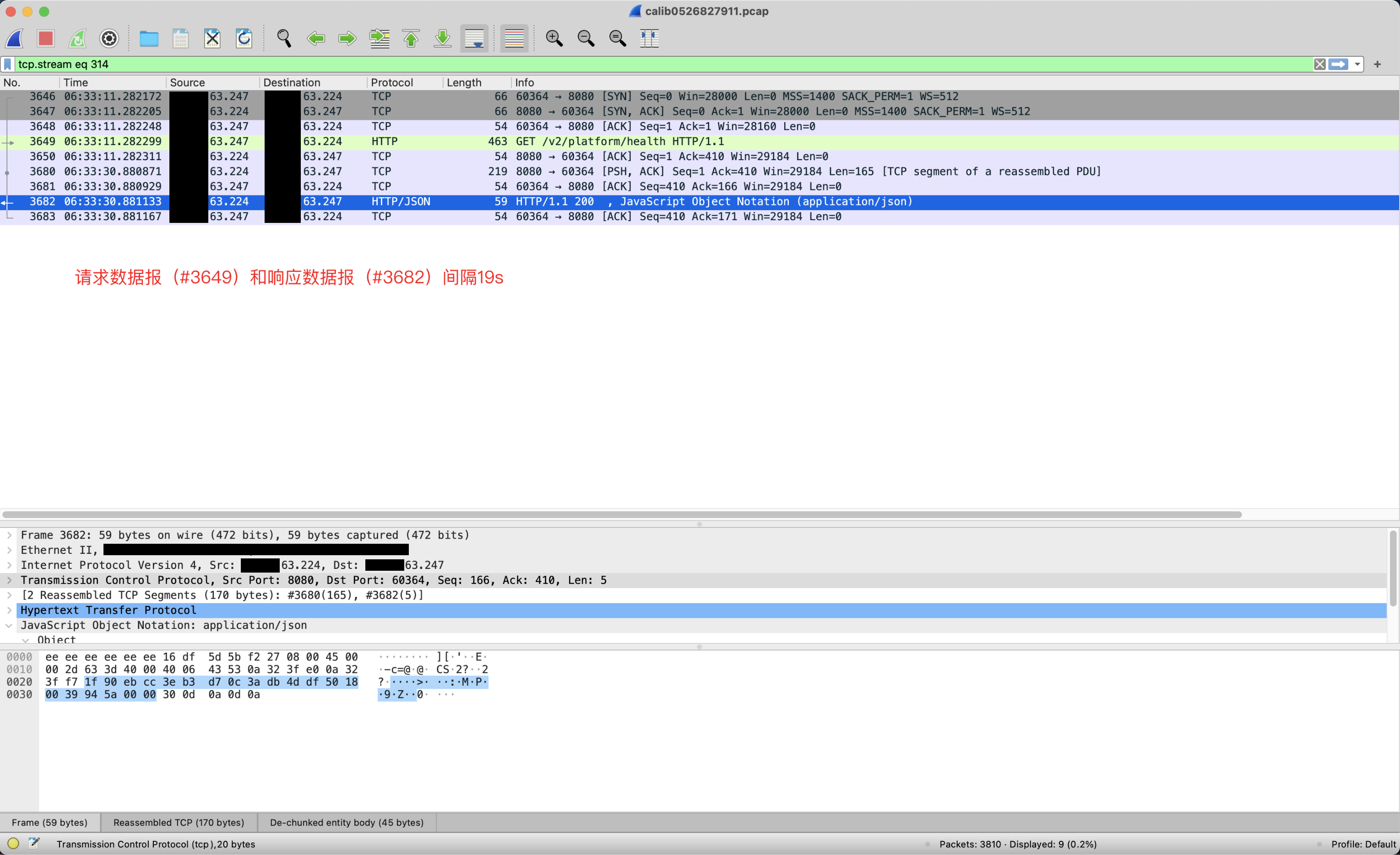
同时通过在服务提供方tcpdump抓包分析,到目前分析结论是延迟发生在backend这一端(但并不能再缩小问题范围,kernel处理慢或者内部队列堆积都有可能):
为了缩小问题范围,尝试开启tomcat的访问日志和内部DEBUG日志,看请求具体什么时间点到达tomcat的队列,什么时间点开始执行用户代码,以及什么时候处理完的,这样就可以进一步确定延迟发生在哪个过程。
# 程序启动添加下面参数
# 开启tomcat访问日志
--server.tomcat.accesslog.enabled=true
# 开启tomcat内部DEBUG日志
--logging.level.org.apache.tomcat=DEBUG --logging.level.org.apache.catalina=DEBUG
在我们的例子中,在compose.yml给backend配置上JAVA_OPTS环境变量即可
services:backend:image: shawyeok/128-slowbackend:backendenvironment:- JAVA_OPTS=-Dserver.tomcat.accesslog.enabled=true -Dlogging.level.org.apache.tomcat=DEBUG -Dlogging.level.org.apache.catalina=DEBUG
开启日志后可以看到tomcat处理的请求的详细过程:
2021-09-28 15:35:06.409 DEBUG 1 --- [0-8080-Acceptor] o.apache.tomcat.util.threads.LimitLatch : Counting up[http-nio-0.0.0.0-8080-Acceptor] latch=10
2021-09-28 15:35:06.409 DEBUG 1 --- [0.0-8080-exec-3] o.apache.tomcat.util.threads.LimitLatch : Counting down[http-nio-0.0.0.0-8080-exec-3] latch=9
2021-09-28 15:35:06.409 DEBUG 1 --- [0.0-8080-exec-3] o.a.tomcat.util.net.SocketWrapperBase : Socket: [org.apache.tomcat.util.net.NioEndpoint$NioSocketWrapper@f099444:org.apache.tomcat.util.net.NioChannel@50bf632e:java.nio.channels.SocketChannel[connected local=java-security-operation-platform-64f57cf5f9-pvnnn/10.50.63.246:8080 remote=/10.50.63.247:45142]], Read from buffer: [0]
2021-09-28 15:35:06.409 DEBUG 1 --- [0.0-8080-exec-3] org.apache.tomcat.util.net.NioEndpoint : Calling [org.apache.tomcat.util.net.NioEndpoint@44c861c].closeSocket([org.apache.tomcat.util.net.NioEndpoint$NioSocketWrapper@f099444:org.apache.tomcat.util.net.NioChannel@50bf632e:java.nio.channels.SocketChannel[connected local=java-security-operation-platform-64f57cf5f9-pvnnn/10.50.63.246:8080 remote=/10.50.63.247:45142]])
2021-09-28 15:35:06.410 DEBUG 1 --- [0.0-8080-exec-1] o.apache.catalina.valves.RemoteIpValve : Incoming request /v2/platform/health with originalRemoteAddr [10.50.63.247], originalRemoteHost=[10.50.63.247], originalSecure=[false], originalScheme=[http], originalServerName=[platform-fengkong.zhaopin.com], originalServerPort=[80] will be seen as newRemoteAddr=[192.168.11.63], newRemoteHost=[192.168.11.63], newSecure=[false], newScheme=[http], newServerName=[platform-fengkong.zhaopin.com], newServerPort=[80]
2021-09-28 15:35:06.410 DEBUG 1 --- [0.0-8080-exec-1] org.apache.catalina.realm.RealmBase : No applicable constraints defined
2021-09-28 15:35:06.410 DEBUG 1 --- [0.0-8080-exec-1] o.a.c.authenticator.AuthenticatorBase : Security checking request GET /v2/platform/health
...
但这个时候注意到一个Logger比较眼熟:o.apache.tomcat.util.threads.LimitLatch,而且有Limit字眼,难道延迟是由于tomcat内部在竞争某种资源?仔细看这个Logger的日志:

看到这里就很值得怀疑了,重新查看之前的threadump文件,发现tomcat Acceptor线程正是block在这里!!
"http-nio-8080-Acceptor" #29 daemon prio=5 os_prio=0 cpu=26.62ms elapsed=112.10s tid=0x00007ffff8ae8000 nid=0x3b waiting on condition [0x00007fff896fe000]java.lang.Thread.State: WAITING (parking)at jdk.internal.misc.Unsafe.park(java.base@11.0.23/Native Method)- parking to wait for <0x0000000083ad3860> (a org.apache.tomcat.util.threads.LimitLatch$Sync)at java.util.concurrent.locks.LockSupport.park(java.base@11.0.23/LockSupport.java:194)at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(java.base@11.0.23/AbstractQueuedSynchronizer.java:885)at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(java.base@11.0.23/AbstractQueuedSynchronizer.java:1039)at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(java.base@11.0.23/AbstractQueuedSynchronizer.java:1345)at org.apache.tomcat.util.threads.LimitLatch.countUpOrAwait(LimitLatch.java:117)at org.apache.tomcat.util.net.AbstractEndpoint.countUpOrAwaitConnection(AbstractEndpoint.java:1309)at org.apache.tomcat.util.net.Acceptor.run(Acceptor.java:94)at java.lang.Thread.run(java.base@11.0.23/Thread.java:829)
原来上面在分析线程dump时真相就在眼前了,却给忽略了,这很致命~
现在这个问题表层的原因已经清楚了:由于该服务配置的tomcat连接数太少,触发了LimitLatch限制,阻塞等待老的连接释放(这点可以通过抓包分析得以验证,被阻塞的请求得以响应之前总是有一个TCP连接释放)
查看源码中src/main/resources/application.yml文件,有如下配置:
server.tomcat.max-connections: 10
这里因为是最简复现Demo,这个配置单独放在这里是非常可疑的,然而现实情况中它可能隐藏在大量的配置中,你未必能注意到,特别是线上排查问题时往往情况都比较急。
查看当前和tomcat 8080端口建立的连接,刚好是10个,查看spring boot文档默认值是8192(server.tomcat.max-connections),关于这个当初为什么要添加上面最大连接数的配置,我就不好细说了,总之是人为方面的原因。
再看nginx的配置,worker_processes配置为16,是大于10的,因此当backend的连接数达到10时,acceptor线程就会阻塞等待,直到有连接释放,这就是为什么会出现间歇性请求响应慢的现象。
worker_processes 16;
解决这个问题,就是把max-connections的配置删掉即可,但是这个问题如果细究的话你可以还会注意其它的点。
问题的表现,往往以多种形式呈现。
在这个case中,我们也可以通过ss命令查看tcp syn连接队列的当前状态,会发现Recv-Q这一列始终大于0,说明有连接正在等待用户线程accept(2)。

tomcat线程模型
我们看一下tomcat线程模型,在一个新连接上发起一次http请求会首先经过Acceptor线程,这个线程只负责接收新的连接然后放到连接队列中,后续的解析http报文、执行应用逻辑、发送响应结果都在Worker线程池中执行。
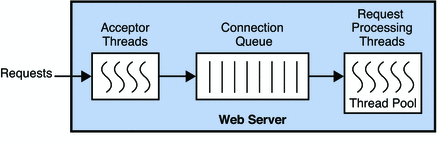
通过上面ss命令的截图,Rec-Q那一列显示3即说明有三个新连接的请求Acceptor线程还没有来得及处理,为什么没有来得及处理呢?即受到了server.tomcat.max-connections配置的约束导致的。
总结
本文主要是分享一个tomcat间歇性响应慢的case,在笔者的第一次排查过程中,其实真相就隐藏在线程dump中,但是最开始的时候错过了。
通过写这篇文章完整回顾了一下这个问题,我最大的感受是,熟悉与否项目中用到的中间件和框架的线程模型,对于排查问题,尤其是涉及到多线程的问题,是两种完全不同的排查体验,不知道线程模型直接像无头苍蝇一样一顿乱打乱撞,掌握线程模型之后,可以从众多信息中找到最关键的那个,犹如百万军中直取上将首级。
欢迎在评论区分享一下,你在排查过程中走过的弯路以及感受较深的地方。
本文最先发表于: https://aops.io/article/tomcat-blocking-on-acceptor.html
作者 萧易客 一线深耕消息中间件,RPC框架多年,欢迎评论区或通过邮件交流。
微信公众号: 萧易客
github id: shawyeok