这个章节描述了flex如何处理动态内存,以及如何覆盖默认行为。
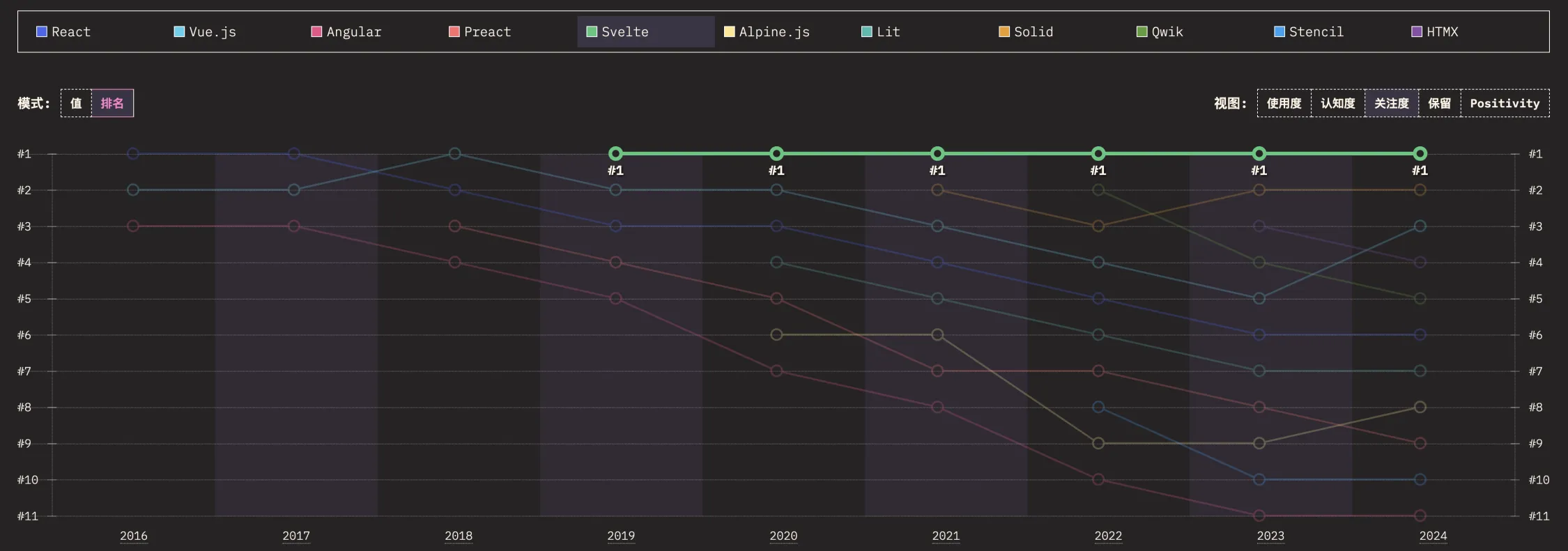
19.1 默认的内存管理
flex在初始化期间分配动态内存,并且偶尔在调用yylex()时分配动态内存。初始化在第一次调用yylex()时进行。此后,如果需要扩大缓冲区,flex可以重新分配更多内存。从2.5.9版本开始,当你调用yylex_destroy时flex将清理所有内存(查看faq-memory-leak章节)。
flex分配动态内存有4个目的,如下所示(注意2):
1、16KB作为输入缓冲区
flex为用于执行模式匹配的字符缓冲区分配内存。flex必须从输入流中提前读取并将其存储在一个大的字符缓冲区中。这个缓冲区通常是flex消耗的最大的动态内存块。如果需要的话,这个缓冲区会增长,每次都会增加一倍。当你调用yylex_destroy()时,flex会释放这些内存。这个缓冲区的默认大小(16384字节)几乎总是太大。这个缓冲区的理想大小是预期的最长标记的长度(以字节为单位),再加上一点。flex将为内存管理分配一些额外的字节。目前,要覆盖输入缓冲区的大小,您必须#define YY_BUF_SIZE为你想要的任何字节数。我们不打算再不久的将来改变这一点,但如果我们添加了一个更健壮的内存管理API,我们保留这样做的权利。
2、64Kb作为REJECT状态。只有在使用REJECT时才会分配此值。
大小足够大,可以容纳与输入缓冲区中字符相同数量的状态。如果您覆盖了输入缓冲区的大小(通过YY_BUF_SIZE),那么你也会自动覆盖这个缓冲区的大小。
3、100字节作为开始条件栈
flex为启动条件堆栈分配内存。这是用于启动状态的堆栈,即使用yy_push_state()。如果需要它将增长。由于状态是简单的整数,所以这个堆栈不会消耗太多内存。如果没有指定%option stack则不存在此堆栈。你很少需要调优这个缓冲区。此堆栈的理想大小是期望的最大深度。当你调用yylex_destroy()时,此堆栈的内存将自动销毁。查看option-stack章节。
4、40字节作为YY_BUFFER_STATE
flex为每个YY_BUFFER_STATE分配内存。缓冲区状态本身大约是40字节,加上一个额外的大字符缓冲区(如上描述的)。初始缓冲状态是在初始化期间创建的,且每次调用yy_create_buffer()。你不能调整它的大小,但可以如上所述调整字符缓冲区。通过调用yy_create_buffer()显示创建的任何缓冲区状态都不会被自动销毁。你必须调用yy_delete_buffer()来释放内存。该规则的例外是,当你调用yylex_destroy()时flex将自动删除当前缓冲区。如果删除当前缓冲区,请确保将其设置为NULL。这样flex就不会尝试第二次删除缓冲区(可能会使程序崩溃!)在撰写本文时,flex没有为缓冲区状态提供可增长的堆栈。你必须自己处理。查看多输入缓冲区章节。
5、84字节作为可重入扫描器内部
当你调用yylex_init()时,flex为可重入扫描器结构分配大约84个字节。当用户调用yylex_destory()时它将被销毁。
注意2:
这里给出的数量是近似值,可能会因主机体系结构、编译器配置或flex的未来增强而有所不同。
19.2 覆盖默认的内存管理
flex在需要分配或释放内存时调用yyalloc、yyrealloc和yyfree函数。默认情况下,这些函数分别是标准C函数malloc、realloc和free的包装器。你可以通过告诉flex你将提供自己的实现来覆盖默认实现。
为了覆盖默认的实现,你必须做下面两个事情:
1、通过指定以下一个或多个选项来禁用默认实现:
a、%option noyyalloc
b、%option noyyrealloc
c、%option noyyfree
2、提供你自己对以下函数的实现(注意3):
// For a non-reentrant scanner
void * yyalloc (size_t bytes);
void * yyrealloc (void * ptr, size_t bytes);
void yyfree (void * ptr);
// For a reentrant scanner
void * yyalloc (size_t bytes, void * yyscanner);
void * yyrealloc (void * ptr, size_t bytes, void * yyscanner);
void yyfree (void * ptr, void * yyscanner);
下面的示例,我们将覆盖所有三个内存函数。我们假设有一个自定义的垃圾回收分配器。为了使这个示例更有趣,我们将使用一个可重入扫描器,通过yyextra向自定义分配器传递一个指针。
%{
#include "some_allocator.h"
%}
/* Suppress the default implementations. */
%option noyyalloc noyyrealloc noyyfree
%option reentrant
/* Initialize the allocator. /
%{
#define YY_EXTRA_TYPE struct allocator
#define YY_USER_INIT yyextra = allocator_create();
%}
%%
.|\n ;
%%
/* Provide our own implementations. /
void * yyalloc (size_t bytes, void yyscanner) {
return allocator_alloc (yyextra, bytes);
}
void * yyrealloc (void * ptr, size_t bytes, void* yyscanner) {
return allocator_realloc (yyextra, bytes);
}
void yyfree (void * ptr, void * yyscanner) {
/* Do nothing -- we leave it to the garbage collector. */
}
注意3:
没有必要覆盖所有(或任何)内存管理函数。例如,你可以覆盖yyrealloc,但不能覆盖yyfree或yyalloc。
19.3 关于yytext和内存的一些注意
当flex找到匹配时,yytext指向输入缓冲区中匹配的第一个字符。字符串本身是输入缓冲区的一部分,不会单独分配。下次调用yylex()时,yytext的值将被覆盖。简而言之,yytext的值仅在匹配的规则的操作中有效。
通常,你希望将yytext的值保留以供以后处理,即由具有非0前瞻性的解析器进行处理。为了保留yytext,你必须使用strdup()或类似的函数复制它。但是这会带来一些麻烦,因为解析器现在负责释放yytext的副本。如果你使用yacc或bison解析器(通常与flex一起使用),你会发现错误恢复机制可能会导致内存泄漏。
为了防止strdup的yytext内存泄漏,你必须以某种方式跟踪内存。我们的经验表明,在编写解析器时,垃圾回收机制或池内存机制将为您节省很多麻烦。