flex扫描器能够将DFA表保存到文件中,并在需要时在运行中加载它们。这个特征的动机是减少运行时内存占用。传统意义上,这些表已经作为C数组编译到扫描器中,并且有时相当大。由于表被编译到扫描程序中,表所使用的内存永远不会被释放。这是对内存的浪费,特别是如果应用程序使用多个扫描器时,但没有一个是同时使用的。
序列化特征允许在运行时扫描开始之前加载表。扫描结束后,这些表可能会被丢弃。
20.1 创建序列化表
你可以通过指定以下命令创建带有序列化表的扫描器:
%option tables-file=FILE
or
--tables-file=FILE
这个选项指示flex将DFA表保存到FILE文件中。这个表不会被嵌入到生成的扫描器中。扫描器不能自己工作。扫描器将依赖于序列化的表。你必须在运行时从该文件加载表,然后才能扫描任何内容。
如果没有为--table-file指定文件名,表将被保存到lex.yy.tables中,这里的’yy’是适当的前缀。
如果你的项目使用几个不同的扫描器,你可以将序列化表连接到一个文件中,flex将使用扫描器前缀作为查找键的一部分,找到正确的表集合。示例如下:
$ flex --tables-file --prefix=cpp cpp.l
$ flex --tables-file --prefix=c c.l
$ cat lex.cpp.tables lex.c.tables > all.tables
上面的示例创建了两个扫描器,’cpp’和’c’。当我们没有指定文件名,所以表被分别序列化为lex.c.tables和lex.cpp.tables。然后,我们将这两个文件连接到all.tables中,它将与我们的项目一起分发。在运行时,我们将打开文件并告诉flex从中加载表。flex将自动找到正确的表。(查看下一章节)
20.2 加载和卸载序列化表
如果你使用%option tables-file来构建扫描器,那么你必须在运行时加载扫描器表。这可以通过以下函数来实现:
函数:int yytables_fload(FILE * fp[,yyscan_t scanner])
在fp所指向的流中定位扫描程序表并加载它们。表的内存是通过yyalloc分配的。必须在第一次调用yylex之前调用这个函数。scanner参数只出现在可重入扫描程序中。此函数成功时返回0,错误时返回非0。
当调用yylex_destroy时,已加载的表不会自动销毁(卸载)。原因是你可以创建几个相同类型的扫描器(在可重入扫描器中),每个扫描器都需要访问这些表。为了避免严重的内存泄漏,你必须调用以下函数:
函数:int yytables_destroy([yyscan_t scanner])
卸载扫描器表。在你可以扫描任何更多的数据前这个表必须被再次加载。scanner参数仅出现在可重入扫描器中。这个函数返回0表示成功,错误时返回非0。
函数yytables_fload和yytables_destroy不是线程安全的。你必须确保在线程程序中,在任何线程调用yylex之前,这些函数只被调用一次(对于每种扫描器类型)。在加载表之后,它们永远不会被写入,此后也不需要线程保护 - 直到销毁它们。
20.3 表的文件格式
这个章节定义了序列化flex表的文件格式。
表格式允许指定一组或多组表,其中每组表对应于给定的扫描器。扫描器按名称索引,如下所述。文件格式如下:
TABLE SET 1
+-------------------------------+
Header | uint32 th_magic; |
| uint32 th_hsize; |
| uint32 th_ssize; |
| uint16 th_flags; |
| char th_version[]; |
| char th_name[]; |
| uint8 th_pad64[]; |
+-------------------------------+
Table 1 | uint16 td_id; |
| uint16 td_flags; |
| uint32 td_hilen; |
| uint32 td_lolen; |
| void td_data[]; |
| uint8 td_pad64[]; |
+-------------------------------+
Table 2 | |
. . .
. . .
. . .
. . .
Table n | |
+-------------------------------+
TABLE SET 2
.
.
.
TABLE SET N
上图显示了一组完整的表,它由一个表头和多个单独的表组成。此外,在同一个文件中可能存在多个完整的集合,每个集合都有自己的头和表。集合在文件中是连续的。知道后面是否由另外一个集合的唯一方法是检查后面4个字节的幻数(或检查EOF)。头和表部分被填充到64位的边界。下面我们将详细描述每个字段。这种格式没有指定扫描器将如何扩展给定的数据,也就是说,数据可能被序列化为int8,但在运行时扩展为int32数组。这是为了尽可能减少序列化数据的大小。记住,所有整数值都是按网络字节序排列的。
表头中的域:
th_magic
幻数,总是0xF13C57B1
th_hsize
整个头的大小,单位字节,包括头所有的域加任何的填充字节
th_ssize
整个集合的大小,单位字节,包括头,所有表加填充的字节
th_flags
这个表集合的位标志。当前未使用
th_version[]
以NULL结尾的字符串格式的flex版本,如’2.5.13a’。这是用于创建序列化表的flex版本。
th_name[]
包含这个表集合的名字。默认是’yytables’,且是相应的前缀,如’footables’。必须以NULL结尾。
th_pad64[]
0个或多个NULL字节,填充整个头部到下一个64位的边界,它从头的开始计算。
表的域:
td_id
指定表的识别符。可能的值是:
YYTD_ID_ACCEPT (0x01)
yy_accept
YYTD_ID_BASE (0x02)
yy_base
YYTD_ID_CHK (0x03)
yy_chk
YYTD_ID_DEF (0x04)
yy_def
YYTD_ID_EC (0x05)
yy_ec
YYTD_ID_META (0x06)
yy_meta
YYTD_ID_NUL_TRANS (0x07)
yy_NUL_trans
YYTD_ID_NXT (0x08)
yy_nxt。这个数组可以是二维的。查看下面的td_hilen域。
YYTD_ID_RULE_CAN_MATCH_EOL (0x09)
yy_rule_can_match_eol
YYTD_ID_START_STATE_LIST (0x0A)
yy_start_state_list。这个数组是特殊处理的,因为它是一个指向结构体的指针数组。查看下面的td_flags域。
YYTD_ID_TRANSITION (0x0B)
yy_transition。这个数组是特殊处理的,因为它是一个结构数组。查看下面的td_lolen域。
YYTD_ID_ACCLIST (0x0C)
yy_acclist
td_flags
描述如何解释td_data中的数据的位标志。默认情况下,数据数组是一维的,但也可以是二维的,如td_hilen字段中指定的那样。
YYTD_DATA8 (0x01)
数据被序列化为int8类型的数组
YYTD_DATA16 (0x02)
数据被序列化为int16类型的数组
YYTD_DATA32 (0x04)
数据被序列化为int32类型的数组
YYTD_PTRANS (0x08)
数据是扩展后的yy_transition数组中条目的索引列表。每个索引都应该扩展为指向yy_transition数组中相应条目的指针。我们依靠yy_transition数组已经被看到这一事实。
YYTD_STRUCT (0x10)
数据是yy_trans_info结构的列表,每个结构包含两个整数。结构元素之间或结构之间没有填充。每个成员的类型由YYTD_DATA *位决定。
td_hilen
如果td_hilen非0,则数据是一个二维的数组。其它的,数据是一个一维的数组。td_hilen包含高维数组中的元素个数,td_lolen包含最低维数组中的元素个数。
从概念上讲,td_data要么是sometype td_data[td_lolen],要么是sometype td_data[td_hilen][td_lolen],这里的sometype是由td_flags字段指定。td_lolen和td_hilen都可能为0,在这种情况下,td_data是一个0长度的数组,并且不加载任何数据,也就是说这个表只是被跳过。flex目前不生成0长度的表。
td_lolen
指定最低维数组中的元素的数目。如果这是一个一维数组,那么它就是这个数组中元素的数量。元素的大小由td_flags字段决定。
td_data[]
表数据。该数组可以是一维或二维数组,类型为int8,int16,int32,struct yy_trans_info或struct yy_trans_info *,具体取决于td_flags、td_hilen和td_lolen字段中的值。
td_pad64[]
0个或多个NULL字节,填充整个表到下一个64位的边界,它从这个表的开始计算。
flex学习 - 序列化表
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/903606.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
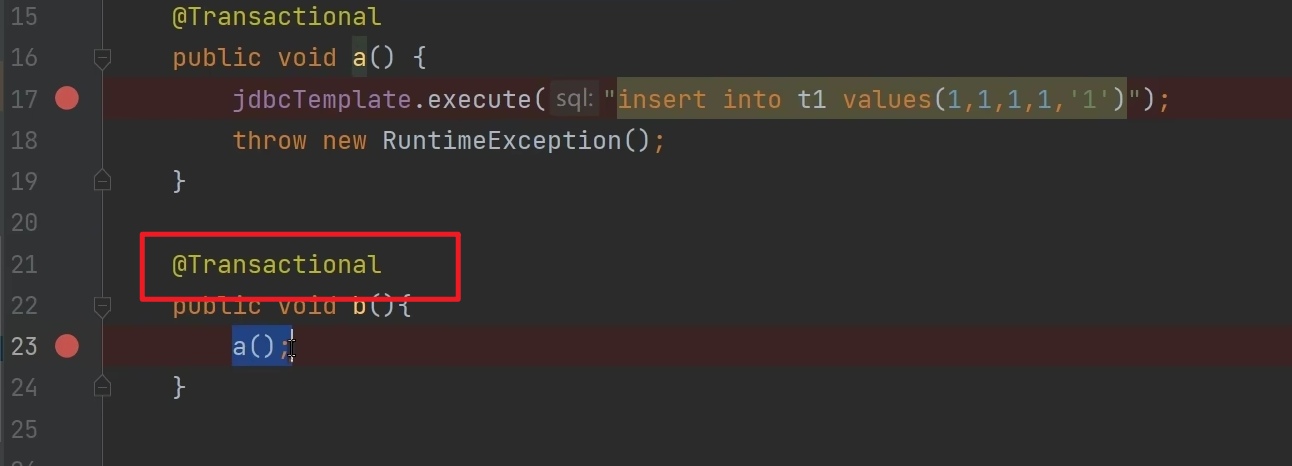
Spring 事务失效
场景1:代码:执行结果:异常抛出,但是数据没有回滚。
代理对象调用 b() 方法 没有开启事务:普通对象调用a() 方法开启事务:在b() 方法上加入事务注解,开启事务就没问题:本文来自博客园,作者:chuangzhou,转载请注明原文链接:https://www.cnblogs.com/czzz/p/18787133
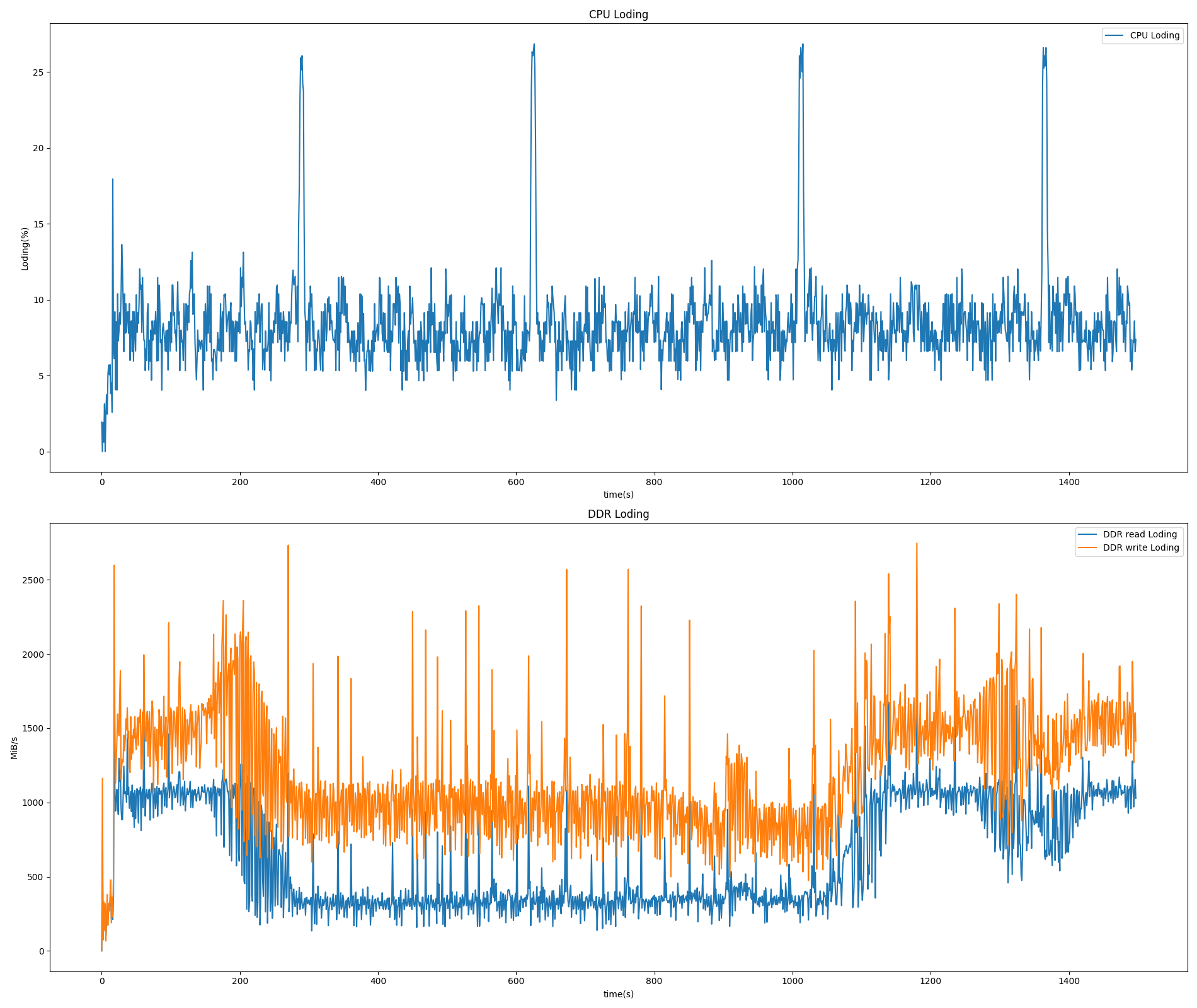
征程 6X CAMSYS 性能测试方案介绍
1.性能测试方法原理
CAMSYS 其性能指标主要包括:帧率、延迟,以及系统的 DDR 带宽、CPU 占用率等。
对于帧率、延迟,通过在驱动中创建 trace event,分别记录通路上的每个 IP,每帧开始处理(frame_start)和结束处理(frame_end)的时间戳信息和帧信息,来实现帧率计算和延迟…


day7 刷牛客华为机试题+学java
https://www.nowcoder.com/exam/oj/ta?page=1&tpId=37&type=37
字符串
第一题:第二题:
省行版:逻辑版:java网课学习:
多态调用成员变量,编译看左边,运行也看左边。调用成员方法时,编译看左边,运行看右边。if(a instanceof Dog d)
导包final 修饰引用类型地址…
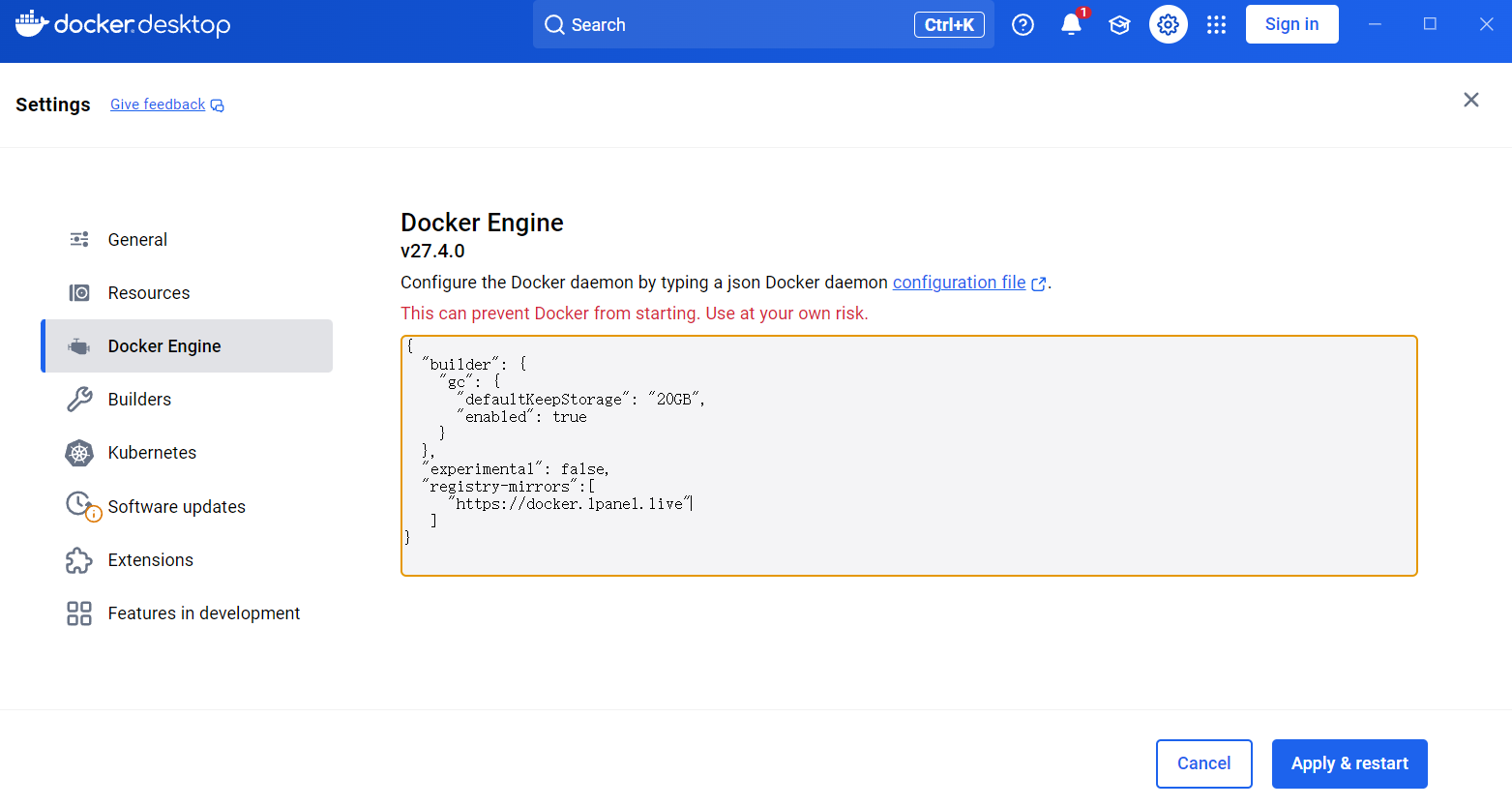
【Docker】MySQL、Reids、Mongodb、Nacos、RabitMQ安装指南
1 docker的下载
建议通过 火绒应用商店 或者 联想应用商店 下载
2 配置Docker
配置镜像站 https://docker.1panel.live
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": fa…

Web前端入门第 22 问:CSS 选择器一览
HTML 在语法上并无大小限制,所以其结构可以浩瀚无边,CSS 选择器的作用则是在这些复杂的 HTML 结构中进行元素定位。
示例代码
记住此代码,后面所有的 css 选择器都是基于此代码。
注意:代码中存在两个一样的 id="p1" 元素,仅为了演示效果,正常编码中请保证 id …

曼哈顿距离和切比雪夫距离
曼哈顿距离(Manhattan Distance)
解释:只能横着或竖着走,坐标上两点的距离
假设存在两点 \(A(x_1, y_1)\) \(B(x_2, y_2)\)
\(dis(A, B) = |x_1 - x_2| + |y_1 - y_2|\)对于上方求曼哈顿距离的式子,有四种情况
\(
\begin{cases}
x_1 > x_2 & y_1 > y_2 & {…
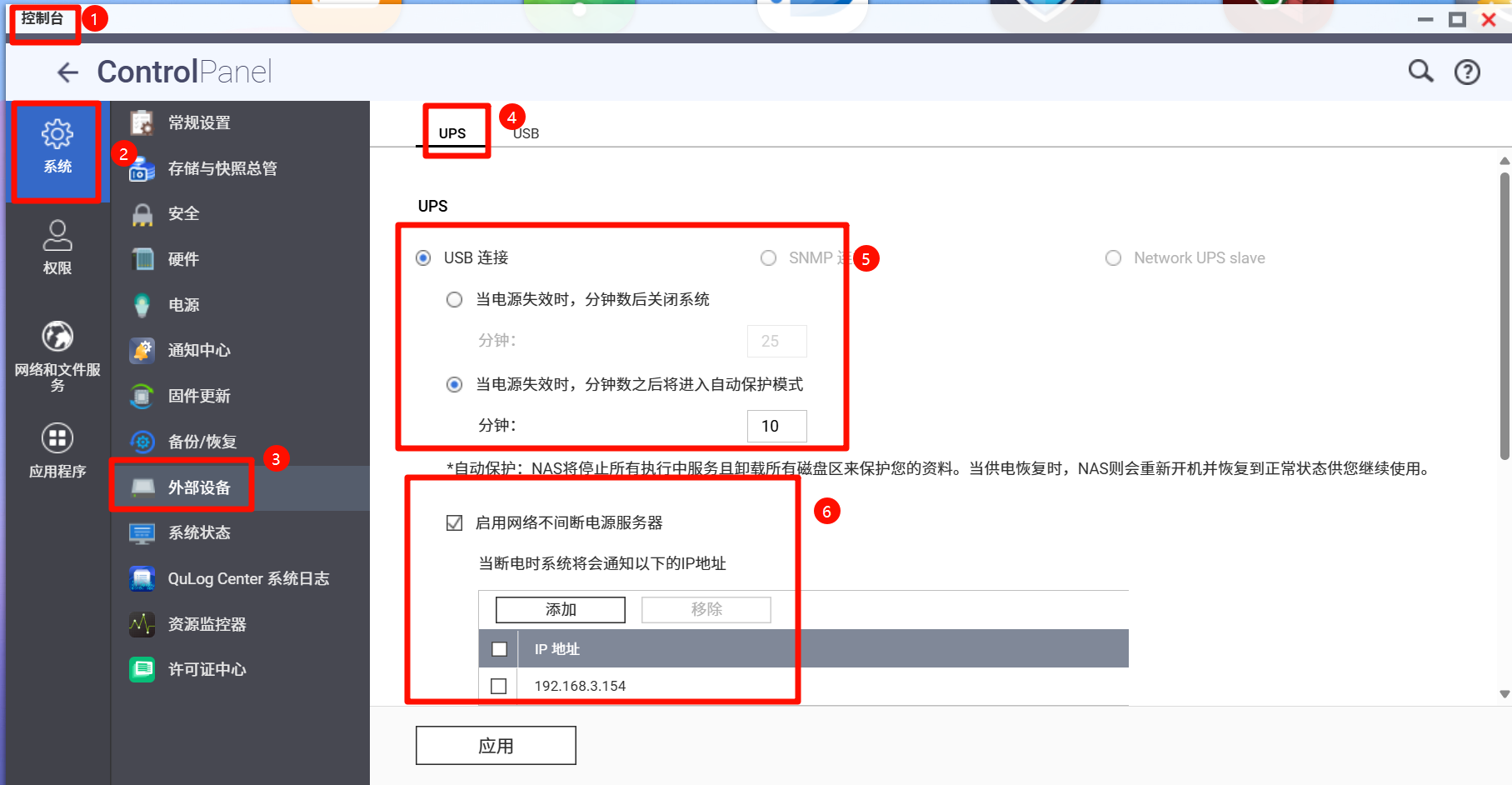
如何设置家用威联通 NAS UPS 断电后自动关机并通知其他设备?
场景📝备注:
求轻喷, 求放过. 😅
我真的是个理线方面的白痴. 这已经是我的极限了. 😂我的家庭实验室 Homelab 服务器集群配置如下.上半部分之前已经介绍过了, 这里就不再赘述了. 今天重点介绍介绍 UPS 和 NAS 部分.1台 UPS, 型号为 APC Back-UPS 650. 插座插着: NAS 和 插…
![[扫描线] 数据结构测试(2025.3.22)](https://nh.51goc.com/static/problemImage/26242/1742616827806.png/)
[扫描线] 数据结构测试(2025.3.22)
暴力大赛,赛时暴力打满喜提80pts,可惜T1没想到暴力。
难度:T2<T1<T3.T1
第1题 团队 查看测评数据信息有n个工人,第i个工人的能力是v[i], 他只与能力在L[i]到R[i]之间的人在一起工作,问最多能选出多少人在一起工作。输入格式第一行,一个整数n, 1 <= n <…
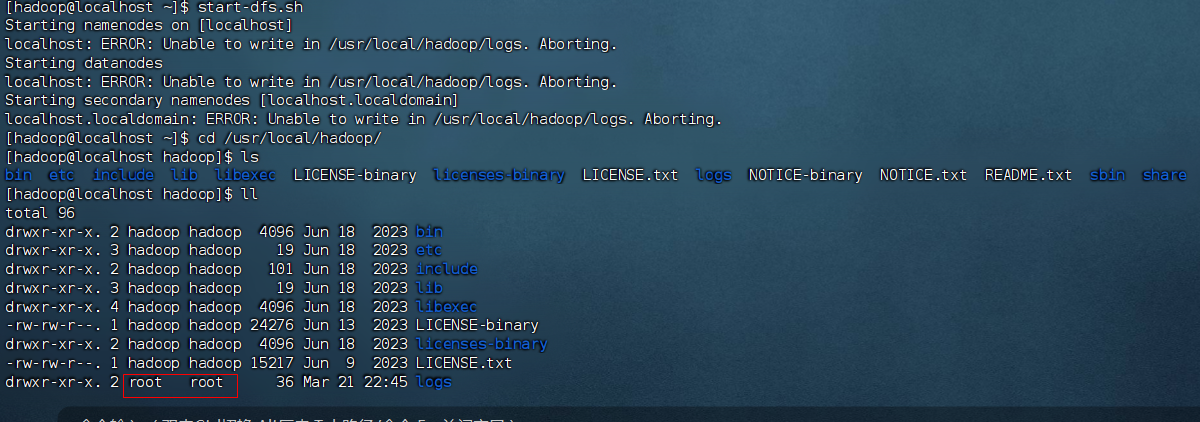
centOS 上部署hadoop+mysql+hive 服务之hadoop安装
以下安装的hadoop版本是3.3.6 ,由于hadoop是运行于java环境,因此,需要提前安装java jdk并配置环境变量。
jdk的安装及配置:
jdk8 国内下载路径:https://repo.huaweicloud.com/java/jdk/8u202-b08/ 可根据实际需要选择对应的jdk版本
1、下载jdkwget https://repo.huaweicl…
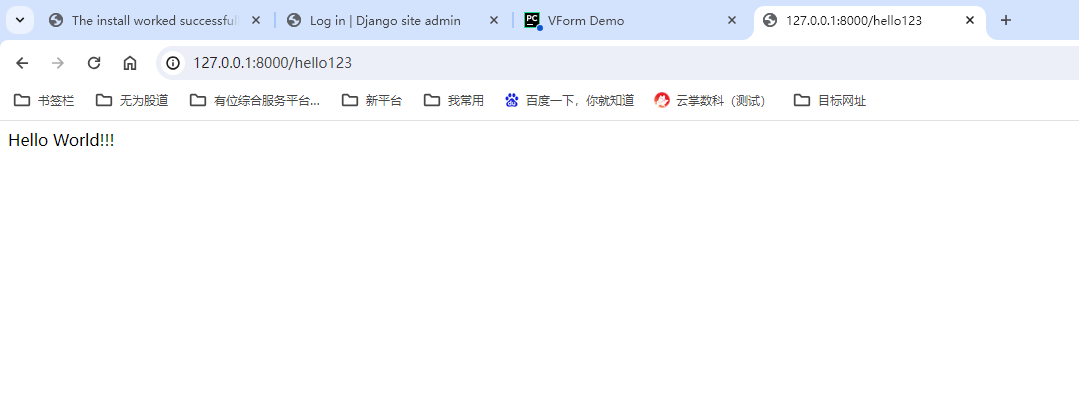
创建django视图和路由
第一个视图
from django.shortcuts import render
from django.http import HttpResponse# Create your views here.
def hello(request):msg = Hello World!!!return HttpResponse(msg)第一个路由
from django.urls import path
from .views import hellourlpatterns = [path(…

8.4.3 基于循环神经网络的字符级语言模型
字符级语言模型的优缺点见下
好处:不用担心\(\left<\text{UNK}\right>\)的出现
坏处:最终的序列要长的多;训练也要复杂得多(对内存和速度的要求都要高得多)
现如今,人们一般使用单词级RNN,但是也有特殊情况会使用字符级RNN
在训练了一个RNN后,我们可以利用这个RN…