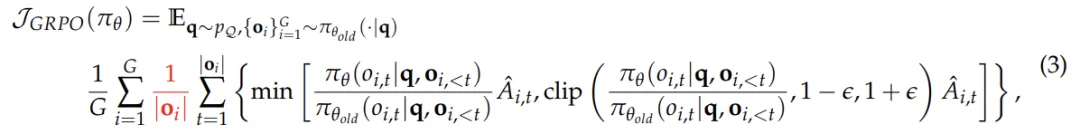- 1. 整体结构回顾
- 2. 输入处理:词嵌入(Embedding)
- ① 单词 → 数字向量
- ② 位置编码(Positional Encoding)
- 3. 自注意力机制(Self-Attention)
- ① 计算 Query, Key, Value
- ② 计算注意力分数
- ③ 加权求和 Value
- ④ 多头注意力(Multi-Head Attention)
- 4. 前馈神经网络(Feed Forward Network)
- 5. 残差连接 & 层归一化
- ① 残差连接(Residual Connection)
- ② 层归一化(Layer Normalization)
- 6. 多层堆叠(Encoder Layers)
- 7. 最终输出
- 总结:Transformer 的低层流水线
- 关键点
1. 整体结构回顾
Transformer 的核心是一个 编码器-解码器(Encoder-Decoder) 结构,但今天我们主要关注最关键的 编码器部分(解码器类似)。它的工作流程可以简化成以下几步:
- 输入处理(把单词变成数字)
- 自注意力计算(找出词与词之间的关系)
- 前馈神经网络(进一步加工信息)
- 重复多层(像流水线一样层层提炼)
下面我们拆解每个步骤的底层实现。
2. 输入处理:词嵌入(Embedding)
① 单词 → 数字向量
计算机不懂文字,所以需要把每个单词转换成一组数字(向量),例如:
- “猫” →
[0.2, -0.5, 0.7, ...](假设是 512 维) - “鱼” →
[0.8, 0.1, -0.3, ...]
这个过程叫 词嵌入(Word Embedding),可以通过训练学习到(比如“猫”和“狗”的向量会比“猫”和“汽车”更接近)。
② 位置编码(Positional Encoding)
Transformer 没有 RNN 那样的顺序处理能力,所以需要额外告诉它单词的位置。比如:
- “猫 吃 鱼” → 给“猫”加
[位置1],“吃”加[位置2],“鱼”加[位置3]。
实现方式是用一组固定或可学习的正弦/余弦函数生成位置信号,然后和词向量相加。
💡 类比:就像给每个快递包裹贴上编号,让分拣员知道顺序。
3. 自注意力机制(Self-Attention)
这是 Transformer 最核心的部分!它的作用是让每个单词去“关注”其他相关的单词。
① 计算 Query, Key, Value
每个单词会生成三个向量:
- Query(Q):“我要找什么?”
- Key(K):“我能提供什么?”
- Value(V):“我的实际信息是什么?”
它们是通过对输入向量做线性变换得到的(即乘上一个可训练的权重矩阵)。
② 计算注意力分数
- 用
Q和所有单词的K做点积(衡量相关性),得到分数。
比如“猫”的 Q 和“鱼”的 K 算出一个高分,说明它们关系密切。 - 然后用 softmax 归一化,得到权重(0~1 之间的概率)。
③ 加权求和 Value
用上一步的权重对 V 加权求和,得到最终的注意力输出。
比如“猫”会重点关注“鱼”的 V,而忽略“汽车”的 V。
💡 代码伪代码(帮助理解):
# 输入: X (句子矩阵) Q = X @ W_Q # 计算 Query K = X @ W_K # 计算 Key V = X @ W_V # 计算 Valuescores = Q @ K.T / sqrt(dim) # 点积缩放 weights = softmax(scores) # 归一化 output = weights @ V # 加权求和
④ 多头注意力(Multi-Head Attention)
- 实际应用中,Transformer 会并行做多组自注意力(比如 8 组),每组关注不同的“关系模式”。
- 最后把多组结果拼接起来,再通过一个线性层融合。
💡 类比:就像一群人同时读一篇文章,有人关注“谁做了什么”,有人关注“时间地点”,最后汇总大家的笔记。
4. 前馈神经网络(Feed Forward Network)
自注意力层的输出会经过一个简单的全连接网络(通常是两层 MLP),作用是对信息进一步非线性变换。
- 输入:自注意力的输出(比如 512 维向量)
- 操作:先扩大维度(如 2048 维),再缩小回原尺寸。
- 激活函数:ReLU 或 GELU。
💡 为什么需要这个?
自注意力擅长捕捉关系,但前馈网络能更好地加工特征。
5. 残差连接 & 层归一化
为了防止深层网络训练困难,Transformer 用了两个技巧:
① 残差连接(Residual Connection)
- 每个子层(自注意力、前馈网络)的输入和输出会相加。
公式:输出 = 子层(输入) + 输入 - 作用是防止梯度消失(让信息更容易反向传播)。
② 层归一化(Layer Normalization)
- 对每一层的输出做归一化(均值为 0,方差为 1),加速训练。
💡 类比:就像写作业时先保留初稿(残差),再润色修改,最后统一格式(归一化)。
6. 多层堆叠(Encoder Layers)
上述过程(自注意力 + 前馈网络)会重复多次(比如原始论文用了 6 层)。
- 每一层都会逐渐提取更高阶的特征。
- 浅层可能关注局部语法(主谓宾),深层可能捕捉语义逻辑(指代、因果关系)。
7. 最终输出
编码器的最后一层输出会传给解码器(如果是翻译任务),或者直接用于分类/生成等任务。
总结:Transformer 的低层流水线
- 输入 → 词嵌入 + 位置编码
- 自注意力 → 计算 Q/K/V,加权求和
- 前馈网络 → 非线性变换
- 残差 & 归一化 → 稳定训练
- 重复 N 层 → 逐步抽象
- 输出 → 任务应用
关键点
- 自注意力:动态计算词与词的关系(权重不固定)。
- 多头机制:并行捕捉多种关系模式。
- 残差连接:让深层网络可训练。
- 位置编码:弥补无顺序处理的缺陷。