引子
前文也写了DeepSeek R1模型的安装测试,感兴趣的童鞋移步(https://blog.csdn.net/zzq1989_/article/details/145400876?spm=1001.2014.3001.5502)。那么在多模态方面R1方法(GRPO,Group Relative Policy Optimization)能不能用呢?毫无疑问,已经有不少人在尝试了。今天就看到一个VLM-R1的开源项目。OK,我们开始吧。
一、模型介绍
这个项目的团队在 Qwen2.5-VL 的基础上,同时对比了 R1 和传统的 SFT 方法。结果相当惊艳:
(1)稳定性强,R1 方法在复杂场景下也能保持高性能,对实际应用意义重大。
(2)泛化能力卓越,在领域外测试数据上,传统 SFT 模型性能随训练步数增加而下滑,R1 模型却能持续提升,表明 R1 方法让模型真正理解视觉内容而非简单记忆。
(3)上手简单,VLM-R1 项目团队提供完整训练和评估流程,四步即可开始训练,对开发者友好

作为一个 AI 领域的从业者,VLM-R1 的出现也为开发者和行业提供了许多新的思路:
(1)证明了 R1 方法的通用性,不止文本领域玩得转;
(2)为多模态模型的训练提供了新思路;
(3)或许能够引领一种全新的视觉语言模型训练潮流;
二、环境搭建
模型下载
https://huggingface.co/omlab/Qwen2.5VL-3B-VLM-R1-REC-500steps/tree/main
生成镜像
cd /datas/work/zzq/VLM-R1/VLM-R1-main
docker build . -f Dockerfile -t vlm_r1:v1.0

三、推理测试
docker run -it --rm --gpus=all -v /datas/work/zzq:/workspace vlm_r1:v1.0 bash
下载验证图片集
https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/refgta.zip
下载验证数据集
https://huggingface.co/datasets/omlab/VLM-R1/resolve/main/rec_jsons_processed.zip
修改代码路径
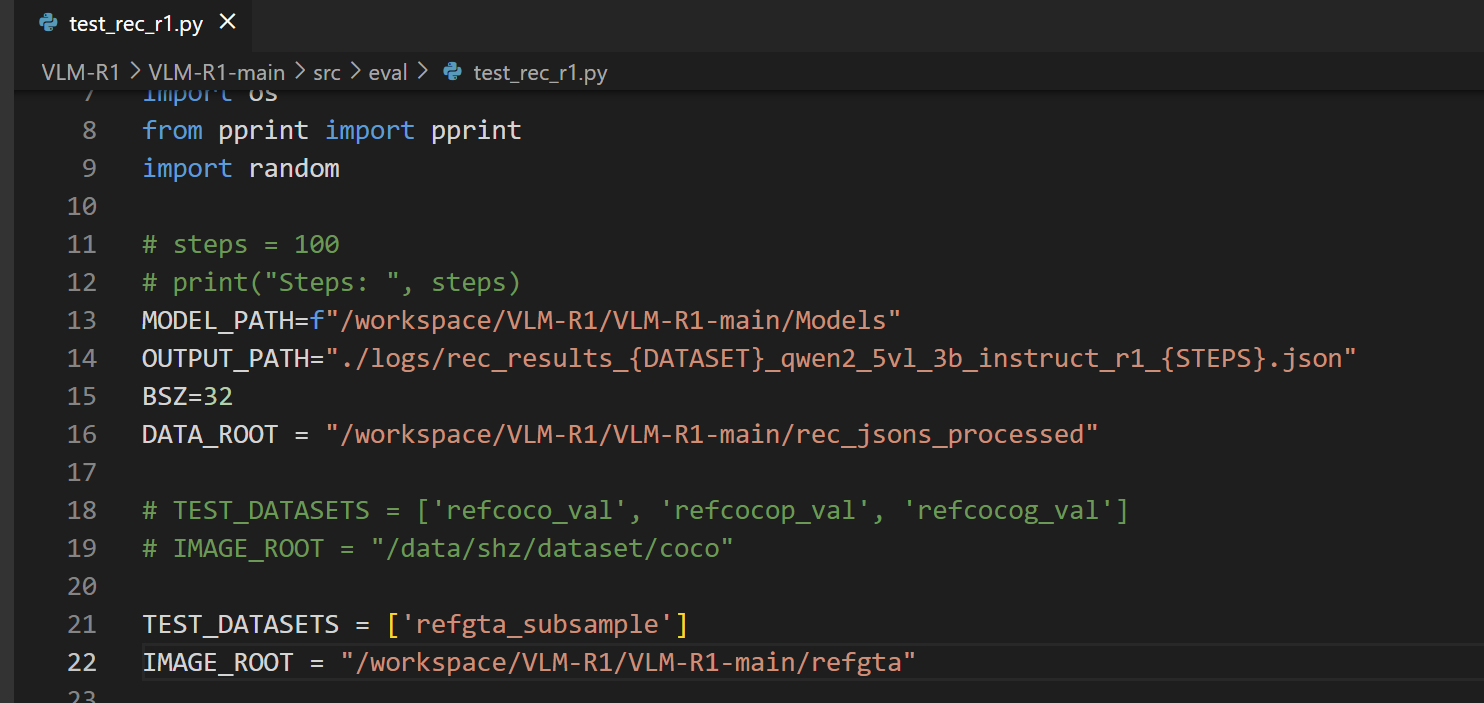
cd /workspace/VLM-R1/VLM-R1-main/src/eval
python test_rec_r1.py