蒸馏实战小实验
本实验相关代码已开源至github
失败经历
爱爱医数据蒸馏Qwen2.5-7B
1.用爬虫在爱爱医网站爬取1k条数据。(刚学一点爬虫,不会越过验证码,还是自己一次一次验证😅)
2.数据格式预处理,例如:
{"instruction": "你需要基于我提供的患者病历,推理并生成完整的诊断推理过程和最终诊断结果。请使用<think></think>标签标注推理过程,并在标签外直接输出最终诊断结果。例如:<think>(详细的诊断推理过程)</think>(诊断结果)。", "input": "【基本信息】男,46岁 【主诉】头痛恶心呕吐1个月。 【现病史】病人在住院一个月之前,没有任何明显的诱发因素,伴有恶心、呕吐,呕吐物为胃内容物,伴有发烧、意识障碍、行走受限,行头 CT检查示:全脑室系统扩张,现为求进一步诊治来我院,门诊以脑积水收入我科。在此期间,病人没有出现痉挛,饮食不佳,第二天睡眠良好。 【既往史】平时健康状况良好。 【查体】T:36.6℃,P:79次/分,R:18次/分,BP:118/72mmHg神清语明,双眼视力正常,双侧瞳孔等大,左:右约25mm:25mm,光反射存在,浅表淋巴结未触及肿大, 颈软,气管居中,无颈静脉怒张,心律齐,肺部未闻及干湿啰音,腹部平坦,无压痛及反跳痛,四肢肌力正常,四肢肌张力正常。 【辅助检查】头CT显示脑室扩张。 【诊治经过】入院后完善头CT显示脑积水,向患者及家属交代病情,患者及家属商量决定保守治疗,入院后完善相关采血:离子测定(急诊):葡萄糖*:6.50mmol/L↑葡萄糖测定(各种酶法):葡萄糖*9.08mmo1/L↑高密度脂蛋白-胆固醇:1.74mmoL↑载脂蛋白AI:1.73g/L↑甲功五项:游离三碘甲状腺原氨酸*:7.74pmo1/L↑促甲状腺激素测定*:0.0619uIU/mL血流变学检查:红细胞比积测定:0.37红细胞流变特性检测(刚性指数):10.03;目前诊断脑积水,给予甘露醇注射液125ml,一天一次静脉点滴;给予甘油果糖注射液250ml,一天一次静脉点滴、给予醒脑静注射液20ml,一天一次静脉点滴;给予舒血宁注射液20ml,一天一次静脉点滴;给予复方氨基酸注射液500ml,一天一次静脉点滴,通过7天保守治疗,患者头痛恶心呕吐症状明显缓解,达到出院标准,嘱咐患者出院后注意休息,继续口服药物治疗,定期复查。", "output": "<think>患者为中年男性,主诉头痛、恶心、呕吐1个月,伴意识障碍及行走受限,提示中枢神经系统受累。查体虽未见明显神经系统定位体征,但头CT显示全脑室系统扩张,符合脑积水影像学特征。发热史需与感染性脑膜炎鉴别,但病程长达一个月且缺乏脑膜刺激征(颈软、无克氏征/布氏征),不支持急性感染。血糖升高可能与应激反应相关,甲功异常需排除代谢因素但非主要矛盾。甘露醇和甘油果糖的脱水降颅压治疗有效,症状缓解验证了颅内压增高的病理机制。需注意脑积水病因未明,梗阻性脑积水可能性大,需排除肿瘤或中脑导水管狭窄等结构异常,但当前资料未提供进一步影像学证据。</think>脑积水。", "system": "你是一名专业的临床医生。"
}
3.调用DeepSeek官方API进行蒸馏推理依据(Ratonales)
蒸馏结果如上面示例"output"里用
吐槽:DeepSeek官方API响应很慢,而且一次请求可能得重复请求两三次才能得到回复(重复消费)
历经几小时最后得到820条包含推理的蒸馏数据集iiyiTrainData
4.安装LLama-Factory框架,使用iiyiTrainData蒸馏数据集进行LoRA微调
具体的安装命令在下面会细讲这里不再阐述
5.输入与回复
输入:
任务:你需要基于我提供的患者病历,推理并生成完整的诊断推理过程和最终诊断结果。请使用
【基本信息】男,46岁 【主诉】头痛恶心呕吐1个月。 【现病史】病人在住院一个月之前,没有任何明显的诱发因素,伴有恶心、呕吐,呕吐物为胃内容物,伴有发烧、意识障碍、行走受限,行头 CT检查示:全脑室系统扩张,现为求进一步诊治来我院,门诊以脑积水收入我科。在此期间,病人没有出现痉挛,饮食不佳,第二天睡眠良好。 【既往史】平时健康状况良好。 【查体】T:36.6℃,P:79次/分,R:18次/分,BP:118/72mmHg神清语明,双眼视力正常,双侧瞳孔等大,左:右约25mm:25mm,光反射存在,浅表淋巴结未触及肿大, 颈软,气管居中,无颈静脉怒张,心律齐,肺部未闻及干湿啰音,腹部平坦,无压痛及反跳痛,四肢肌力正常,四肢肌张力正常。 【辅助检查】头CT显示脑室扩张。 【诊治经过】入院后完善头CT显示脑积水,向患者及家属交代病情,患者及家属商量决定保守治疗,入院后完善相关采血:离子测定(急诊):葡萄糖:6.50mmol/L↑葡萄糖测定(各种酶法):葡萄糖9.08mmo1/L↑高密度脂蛋白-胆固醇:1.74mmoL↑载脂蛋白AI:1.73g/L↑甲功五项:游离三碘甲状腺原氨酸:7.74pmo1/L↑促甲状腺激素测定:0.0619uIU/mL血流变学检查:红细胞比积测定:0.37红细胞流变特性检测(刚性指数):10.03;目前诊断脑积水,给予甘露醇注射液125ml,一天一次静脉点滴;给予甘油果糖注射液250ml,一天一次静脉点滴、给予醒脑静注射液20ml,一天一次静脉点滴;给予舒血宁注射液20ml,一天一次静脉点滴;给予复方氨基酸注射液500ml,一天一次静脉点滴,通过7天保守治疗,患者头痛恶心呕吐症状明显缓解,达到出院标准,嘱咐患者出院后注意休息,继续口服药物治疗,定期复查。
回复:
Qwen2.5-7B-Base模型:
微调后:

// 评估结果
{"predict_bleu-4": 15.410856707317073,"predict_model_preparation_time": 0.0065,"predict_rouge-1": 33.76439756097561,"predict_rouge-2": 13.446685487804878,"predict_rouge-l": 20.279881707317074,"predict_runtime": 5382.5632,"predict_samples_per_second": 0.152,"predict_steps_per_second": 0.076
}
微调前:

// 评估结果
{"predict_bleu-4": 11.915909756097559,"predict_model_preparation_time": 0.0055,"predict_rouge-1": 29.76750548780488,"predict_rouge-2": 9.160844268292683,"predict_rouge-l": 17.595996707317074,"predict_runtime": 5725.6516,"predict_samples_per_second": 0.143,"predict_steps_per_second": 0.072
}
Qwen2.5-7B-Instruct模型:
微调后:

微调前:

6.总结
①Base模型输入中增加“任务”这一内容,模型会有“思考”过程,但是最终会乱输出,如果不增加“任务”,模型并不会出现“思考”过程,但回复合理
②Instruct模型本身就有“思考”能力,只要增加“任务”进行指导,就会出现“思考”过程。但是不会自主进行“思考”。而且“思考”过程比未经过微调好一点。此外,Instruct模型经过大量数据对齐,并不会乱回复,但是即便是使用微调的数据进行询问,最终诊断的结果也不会和该数据的真实诊断结果相同。
思考:如果使用Base模型需要使用大量微调数据进行对齐,使用Instruct模型又不一定能微调出自主涌现的“思考”能力,可能需要进行强化学习。数据集格式可能需要重新构建。
LLMs推理能力蒸馏
概览:本次实验使用的是网上开源且与医学相关的数据集,这些数据集都是从DeepSeek或者ChatGPT-O1模型中蒸馏的,具体来说是给定问题和参考回复,让LLM生成相关的推理过程。然后使用这些数据对Qwen2.5-7B-Base模型进行LoRA微调,以增强小模型的推理能力。结果上来说比起失败经历效果更好了一些,但是还是有一定的问题,作为蒸馏和模型微调实战还是有一定的意义。
故不积跬步,无以至千里;不积小流,无以成江海。 —— 荀子《劝学》
环境搭建
本次用到的机器为Linux系统, 3块 RTX 3090 24G显卡(两块也能跑,时间更长一些)
默认你已经对机器学习有了一定的基础,对于Anaconda的安装就不再细说,网上有大把资料。
# 虚拟环境创建
conda create -n MedicalKD python=3.10
# 进入虚拟环境
conda activate MedicalKD# 安装pytorch
# CUDA 12.0
# 版本对应参考https://blog.csdn.net/ttrr27/article/details/144162171
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124 -i https://pypi.tuna.tsinghua.edu.cn/simple/# 安装LLaMa Factory
# 安装前可以自行创建一个文件夹(文件管理方便) 命令:mkdir xxx
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simple# 环境校验
python
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__
# 框架校验
llamafactory-cli train -h# 可以安装一下deepspeed,加速训练,减少显存消耗(WebUi最下方有选项可以使用deepspeed)
pip install deepspeed

出现错误,缺少socksio,下面命令安装
pip install socksio
模型下载
国内可以使用魔塔下载,速度快些,外网可使用huggingface
这里用魔塔示例
# 下载Qwen 7B //通过魔塔
# git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B.git# 模型直接推理
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \--model_name_or_path /mnt/mxy/models/Qwen2.5-7B-Instruct/ \--template qwen
数据集介绍
本实验涉及四个中文开源数据集,并最终将它们打乱顺序合并成一个
medical_o1_sft_Chinese.json 医疗 24772条 [下载链接](medical_o1_sft_Chinese.json · FreedomIntelligence/medical-o1-reasoning-SFT at main)
medical_r1_distill_sft_Chinese.json 医疗 17000条 [下载链接](FreedomIntelligence/Medical-R1-Distill-Data-Chinese at main)
distill_psychology-10k-r1.json 心理健康 8775条 [下载链接](distill_psychology-10k-r1.json · Kedreamix/psychology-10k-Deepseek-R1-zh at main)
hwtcm_deepseek_r1_distill_data.json 中医 12219条 [下载链接](Monor/hwtcm-deepseek-r1-distill-data · Datasets at Hugging Face)
共计:62766 条
注:如果你想自己构建蒸馏数据集可参考代码中蒸馏爱爱医数据部分,调用的DeepSeek官方接口生成推理依据。
但是这样开销很大,只蒸馏小部分数据不足以达到训练预期目标。
github仓库中缺少medical_r1_distill_sft_Chinese.json请自行下载后放入下方文件夹中
数据格式
代码已经完成格式转换
包含三部分:问题,推理依据(rationales)和总结回复
推理依据包含在

使用LLaMA-Factory进行微调
数据集注册
首先确保所适用数据集放在data目录下:
打开data目录下的dataset_info.json文件,在其中增加内容:
"mergedData": {"file_name": "merged_dataset_random.json"},
使用webui进行微调
LLaMA-Factory提供了可视化页面,可以实现无代码进行模型训练、评估和对话,非常方便。
# 下面命令用于启动webui
# 请确认系统已经在llama-factory文件目录下
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui# 训练时间过长,可以在服务器上建一个screen,这样本地电脑即使断开ssh连接,服务器上也会继续训练
# 类似服务器电脑上打开一个窗口,一直不关闭
# 新建screen
screen -S your_screen_name
# 显示screen list
screen -ls
# 进入screen
screen -r your_screen_name
# 删除screen
Ctrl+D # 在当前screen下,输入Ctrl+D,删除该screen
Ctrl+A,Ctrl+D # 在当前screen下,输入先后Ctrl+A,Ctrl+D,退出该screen
如果你是windows系统调用远程云服务器,可能需要端口映射
# 端口映射
# xxx为远程服务器地址
ssh -L 7860:localhost:7860 root@xxx.xxx.xxx.xxx
然后在本地浏览器打开localhost:7860,然后会看到如下界面
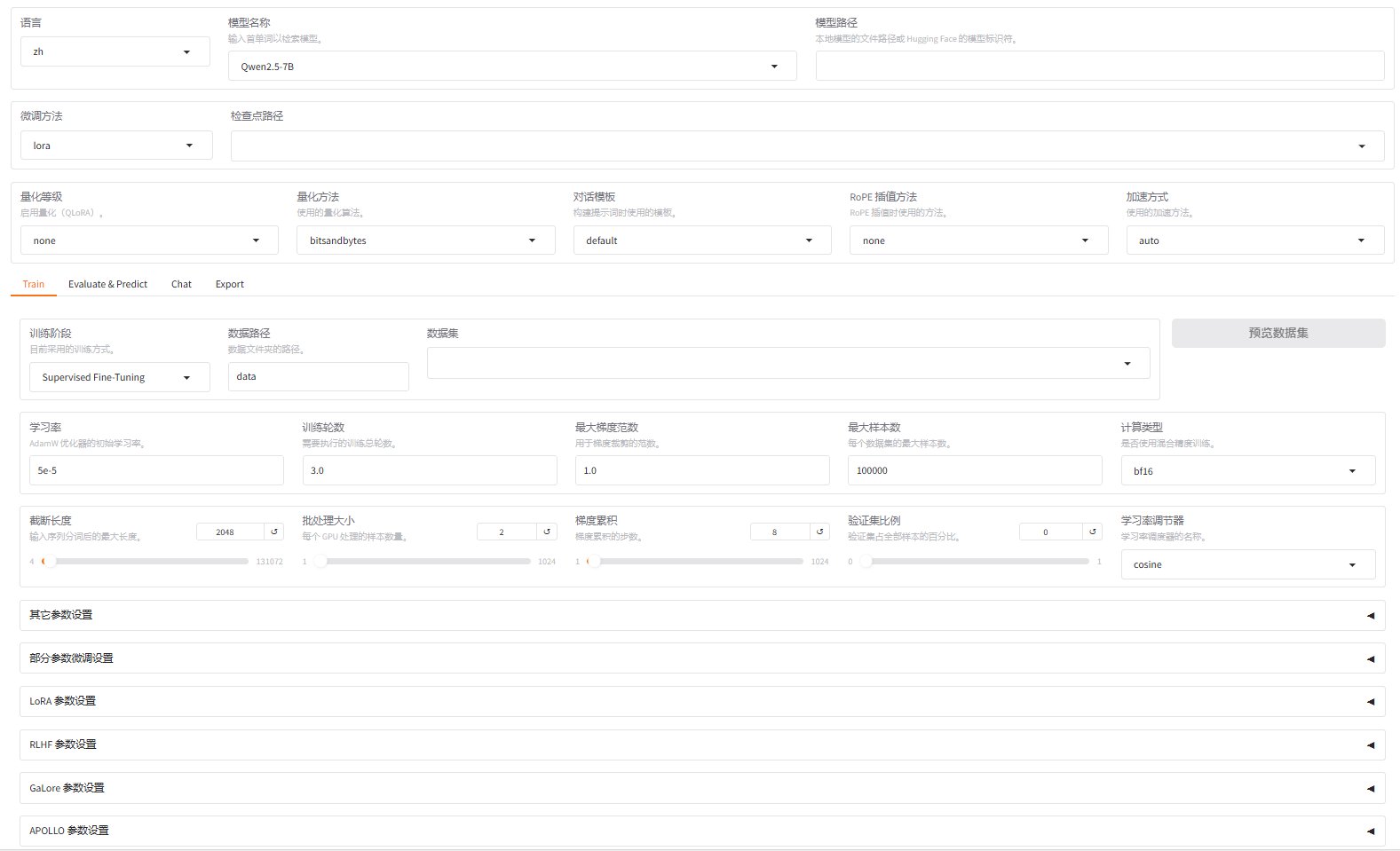
微调参数设置
模型选择:Qwen2.5-7B 模型路径:下载到的本地路径
对话模版:qwen
微调方法:lora 训练阶段:SFT 训练轮数(epoch):2.0 批处理大小(batch_size):2
预热步数:5 验证集比例:0.1 保存间隔:200
LoRA秩:16 LoRA缩放系数:32
启用DeepSpeed stage
其余参数全默认,训练时间大概40小时
结果对比
选择webui中的Chat,然后检查点路径选择训练时保存的checkpoint路径,加载模型就可以与训练后的模型对话,反之不填检查点路径,就是和原始模型对话。
下面问题是微调数据集外的问题
Prompt:
任务:请先输出推理过程并将其包含在
微调前Qwen2.5-7B-Base

微调前会依据指令强行将回复内容包含在
不加prompt中任务部分内容,模型正常回复:

微调后Qwen2.5-7B-Base


模型有概率不会将推理过程包含在
(优化提示词?增加数据量进一步训练?)

不加prompt中任务部分内容,模型正常回复:


微调后模型合并
进入Export,填写导出目录即可合并
问题
1.模型可能会出现重复输出无法停止、乱回复问题
2.不加下面任务部分提示词,模型不会自主输出思考过程
任务:请先输出推理过程并将其包含在
标签内,然后在标签后直接输出最终总结回复。例如: (详细的诊断推理过程) (总结回复)。
展望
后续可能会增加强化学习阶段,观察模型是否会涌现出自主出现思考过程的能力,做一些小调整解决模型重复输出问题。
如果成功了就会再写一个随笔来记录
参考文档
1.LLaMA-Factory github地址
2.LLaMa-Factory入门文档
3.LLaMa Factory参数详解