探秘Transformer系列之(18)--- FlashAttention
- 0x00 概述
- 0.1 问题
- 0.2 其它解决方案
- 0.3 Flash Attention
- 0x01 背景知识
- 1.1 GPU相关概念
- 硬件概念
- 运行单元
- 内存
- 软件概念
- 运行模式
- 线程模型
- Grid & Device
- Block & SM
- Thread & SP
- Thread & Warp
- 总结
- 硬件概念
- 1.2 Transformer的内存和计算
- 基本概念
- 计算受限与内存受限
- 注意力机制的计算强度
- 如何平衡
- 1.3 Tiling
- 1.4 算子融合
- 1.1 GPU相关概念
- 0x02 优化注意力机制
- 2.1 标准注意力机制
- 计算公式
- 实现算法
- 细化拆解
- 问题所在
- 2.2 解决方案
- 思路
- 算子融合
- 分块计算
- 限制
- 方案1
- 方案2
- 总结
- 思路
- 2.1 标准注意力机制
- 0x03 Softmax改进
- 3.1 原生softmax
- 公式
- 实现
- 限制
- 3.2 历程
- 3.3 3-Pass Safe Softmax
- 当前问题
- 解决方案
- 实现
- 存在缺陷
- 3.4 online softmax 2-pass
- 动机
- 算法
- 分析
- 实现
- 存在缺陷
- 3.5 Multi-pass Self-Attention
- 动机
- Multi-pass Self-Attention算法
- 引入到FlashAttention
- 3.6 1-pass FlashAttention
- 3.7 Algorithm FlashAttention (Tiling)
- 3.8 小结
- 3.1 原生softmax
- 0x04 FlashAttention V1
- 4.1 总体思路
- 4.2 算法
- 4.3 证明
- 定义
- 推导
- 常规softmax
- safe softmax
- 结合O来分析
- 4.4 分块
- 如何切分
- 分块大小
- 局限性
- 4.5 流程
- 前置条件
- 第一步
- 第二步
- 第三步
- 第四步
- 循环计算
- 第五步
- 第六步
- 第七步
- 第八步
- 循环内计算
- 第九步
- 第十步
- 第十一步
- 第十二步
- 第十三步
- 第十四、十五、十六步
- 总结
- 0x05 计算量与显存占用
- 5.1 IO复杂度
- 标准注意力
- FlashAttention
- 反向传播
- 5.2 计算复杂度
- 标准注意力
- FlashAttention
- 5.1 IO复杂度
- 0xFF 参考
0x00 概述
0.1 问题
Transformer架构的核心是自注意力机制这个强大的组件。然而,自注意力机制的执行速度很慢,并且内存占用很大,特别是在处理长上下文长度时。对于Transformer模型,假设其输入序列长度为N,则其Transformer模型的计算复杂度和空间复杂度都是\(O(N^2)\),即模型的计算量和存储空间随着序列长度N呈二次方增长。当输入序列(sequence length)较长时,Transformer的计算过程缓慢且耗费内存,这限制了大语言模型的最大序列长度N的大小,这就是在发展初期,大模型往往只支持2K或4K token输入的原因。所以人们寻求降低Transformer模型的\(O(N^2)\)复杂度,争取让复杂度逼近\(O(N)\)或者降到\(O(N)\)。
0.2 其它解决方案
在FlashAttention之前,人们已经做了很多尝试,基本上有两条路径:降低注意力机制的计算复杂度和降低注意力机制的空间复杂度。通常将由这些方法改进得到的模型称为Efficient Transformer。
在计算复杂度方面,一些工作尝试提出近似的注意力机制算法,来降低 attention 的理论上的计算复杂度。主要可以分为稀疏 (sparse) 估计、低秩 (low-rank) 估计等。其中,稀疏估计的基本思想是通过一个稀疏的矩阵来近似完整的、稠密 (dense) 的注意力矩阵,比如,Reformer]对 Q 和 K 进行局部敏感哈希(Local Sensitive Hashing),只对同一个 桶 (bucket) 中的 Q 和 V 计算 attention,将 attention 的时间复杂度从 $O(n^2) $降低到 \(o(nlog(n))\) 。再比如,低秩近似的基本思想通过一个低秩 (low-rank) 矩阵来估计注意力矩阵,比如,linear transformer引入核函数 \(\phi(x)\) ,将 \(score=softmax(QK^T)V\) 形式化成 \(score=\phi(Q)(\phi(K)^TV)\) ,来解耦开 softmax 运算中的 Q 和 K 。这样操作之后,可以先计算\(score=\phi(Q)(\phi(K)^TV)\),该运算的时间复杂度为 \(O(n)\)。虽然降低注意力机制的计算复杂度在理论上非常具有吸引力,但是在实际应用中仍然存在一些短板,比如以下两点:
- 性能比不上原始注意力机制。不论是稀疏估计、低秩估计还是其他,这些方法都采用了某种近似算法来估算注意力权重矩阵,难免会丢失信息。目前主流的还是原始的注意力机制;
- 无法减少内存读取的时间消耗。这些方法只能降低注意力机制的计算复杂度,但是无法对注意力机制的运算过程中的空间复杂度等进行控制,无法减少内存读写带来的时间损耗。
在空间复杂度方面,这方面工作的基本思路是降低注意力机制对于显存的需求,减少 HBM 和 SRAM 之间的换入换出,进而减少注意力机制运算的时间消耗。一种具有代表性的方法是 kernel fusion,其思想很简单,即将需要通过多个 CUDA kernel 来分步完成的操作融合到一个或者少数几个 CUDA kernel,从而减少数据在HBM和SRAM之间换入换出的次数,进而节省运算时间。
0.3 Flash Attention
FlashAttention的作者们发现,这些Efficient Transformer虽然能够有效降低模型的FLOPS,但它们的计算速度并没有显著降低。导致该现象的根本原因是大多数Efficient Transformer通常只关注FLOPS(Floating Point Operations Per Second),该指标是计算密集型应用程序和深度学习模型性能的常用指标。然而,模型的计算速度除了与FLOPS有很大关系,同时也与MAC(Memory Access Cost,存储访问开销)有关。尤其是当计算本身已经很高效的情况下,MAC的开销更加不能忽略。MAC的开销主要来自两方面。一是从存储中读取数据;二是向存储中写数据。与CPU的情况类似,在GPU中,当需要计算时,需将数据从显存中读取并由计算单元进行计算操作。在计算完毕后,再写回到显存中。
Flash Attention所作的工作体现在其论文题目“FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”中,具体如下:
-
Fast(with IO-Awareness),计算快。Flash Attention之前加速Transformer计算方法的着眼点在于“减少计算量FLOPs”,比如用稀疏Attention来近似计算。但Flash Attention作者发现计算慢的瓶颈是IO读写速度而非计算能力,因此Flash Attention通过减少访问显存(HBM)的次数来提高整体运算速度,这就是IO感知(with IO-Awareness)。具体而言,减少访问显存(HBM)的次数是通过分块计算(tiling)和核函数融合(kernel fusion)技术来实现的。
-
Memory Efficicent,节省显存。在标准Attention场景中,前向传播时会保存\(N^2\)大小的注意力矩阵\(P,S\),反向传播时又会读取注意力矩阵来计算梯度,这就是显存复杂度为\(O(N^2)\)的原因。Flash Attention通过引入统计量来改变注意力机制的计算顺序,避免了实例化注意力矩阵,从而使得存储压力降至 O(N) 。
-
Exact Attention,精准注意力,计算结果完全相同。Flash Attention之前的“稀疏Attention”属于近似计算,虽然可以减少计算量,但是其计算结果与标准Attention计算结果不同。Flash Attention的计算结果与标准Attention计算结完全相同。
简单来说,注意力公式为:\(Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\),FlashAttention不需要在全局内存上实现 中间矩阵,而是将上述公式中的整个计算融合到单个 CUDA 内核中,这样,我们就不需要大量的I/O。另外,对于矩阵乘法等经典算法,还会使用平铺(tiling)来确保片上内存不超过硬件限制。
0x01 背景知识
因为大模型主要是在GPU上进行训练和推理,所以我们首先看看GPU相关知识,然后看看Transformer的计算特点。
1.1 GPU相关概念
我们在学习和使用CUDA时候,经常见到很多概念,比如SM,SP,Grid等,通常令人感到疑惑。接下来就带领大家做简要的解读。这些概念通常分为两类:
- 硬件资源或者概念,包括:SP,SM,HBM和SRAM;
- 软件抽象或者概念,包括:Thread、Warp、Block和Grid;
硬件概念
首先来看看一些硬件概念。
运行单元
这里主要包括SM(Streaming Multiprocessors,流式多处理器)和SP(Streaming Processor,计算单元)概念。GPU由一系列SM组成。SM是GPU的基本计算单元,其好比多核的CPU芯片里面的一个核。不同之处在于,CPU的一个核一般是运行一个线程,而SM能够运行多个轻量线程。每个SM都拥有一定数量的寄存器、片上内存(on-chip memory)、控制单元和若干SP或其他加速计算单元。这些片上内存和控制单元被所有的SP共享。此外,每个SM都配备了基于硬件的线程调度器,用于执行线程。
内存
我们用A100-40GB为例来揭示GPU的内存状况。下面是A100-40GB的内存层级结构图。
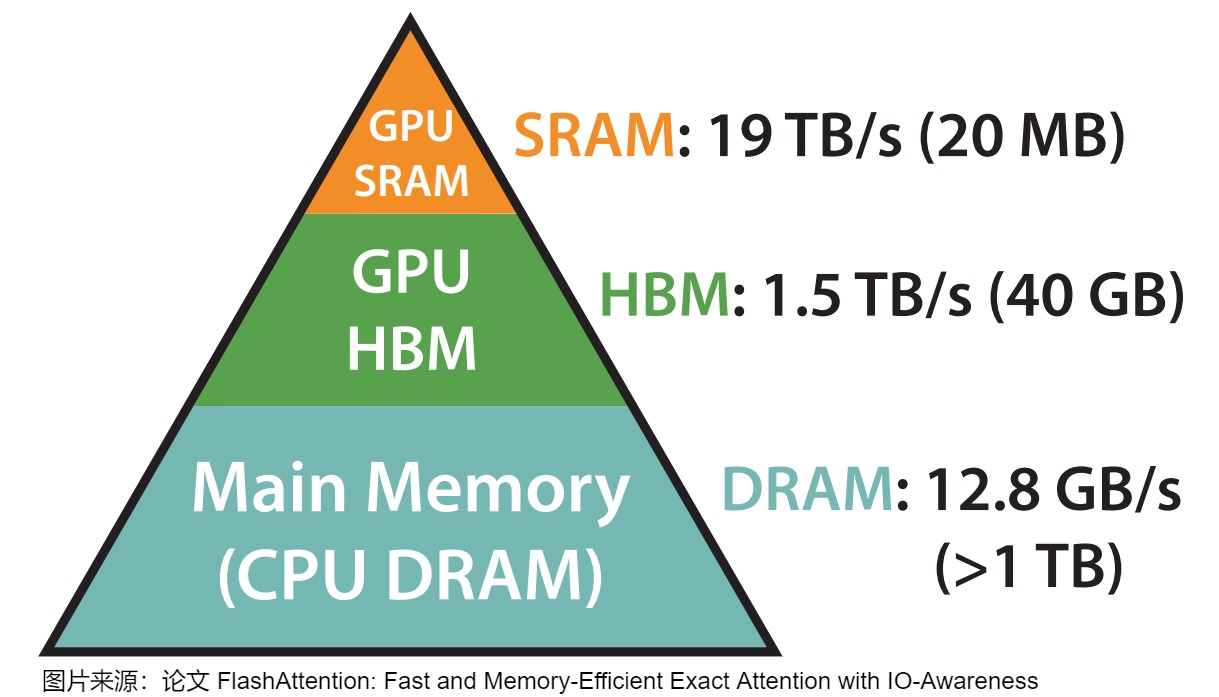
上面是三层金字塔,最下面是CPU上的内存,量大,但是很慢。上面两层则属于GPU,GPU的内存由多个不同大小和不同读写速度的内存组成,可以按照是否在芯片上分为片上内存和片下内存(off chip),在NVIDIA A100-40GB卡上两种内存的信息如下。
| 类型 | 名称 | 作用 | 大小 | 读写速度 | 特点 |
|---|---|---|---|---|---|
| 片上内存 | SRAM(Static Random-Access Memory) | 主要用于缓存(cache)及少量特殊存储单元(例如texture) | 分布在108个流式多处理器上,每个处理器大小为192K。合计为 192∗108KB=20,736KM=20MB | 19TB/s | 存储空间小,带宽大 |
| 片下内存 | HBM(High Bandwidth Memory) | 主要用于全局存储(global memory),即我们常说的显存 | 40~80GB | 1.5~2.0TB/s | 存储空间大,带宽小 |
这里要再次强调一点:SRAM 是 L1 Cache(组合共享内存和数据缓存)。
可以看到,显存的带宽相比SRAM要小的多,读一次数据很费时,但是SRAM存储又太小,装不下太多数据。所以我们就以SRAM的存储为上限,尽量保证每次加载数据都把SRAM给打满,节省数据读取时间。
软件概念
运行模式
一个CUDA程序可以分为两个部分(两者拥有各自的存储器):
- 在CPU上运行的称为Host程序,或者可以把CPU理解为Host。
- 在GPU上运行的称为Device程序,又被叫做Kernel函数。或者可以把GPU理解为Device。
对应的GPU执行操作的典型方式分为以下几步:
- CPU把计算指令传送给GPU;
- 把数据从CPU的内存拷贝到GPU的内存,即HBM;
- GPU将输入数据从低速的HBM中加载到高速的SRAM中;
- GPU把计算任务分配到各个SM并行处理;
- SM从SRAM读取数据进行计算操作;
- 计算完毕后将计算结果从SRAM写到HBM里;
- 计算结果再从HBM拷贝到CPU内存;
线程模型
在GPU上需要启用多个线程来执行kernel。比如在向量相加的示例中,如果我们要对256维的向量进行相加运算,那么可以使用256个线程并行处理,这样每个线程就可以处理向量的一个元素。如果数据更大,GPU上也许没有足够的线程可用,这时我们可能需要每个线程能够处理多个数据点。因此需要程序员依据数据的大小和我们所需的并行度来仔细配置线程。
为了方便程序员设计、组织线程,在CUDA编程上把软件资源抽象成为一个线程模型,该模型包括Grid、Block、Thread和Warp等概念,每个概念对应的软件抽象和硬件资源对应如下。
- Thread:并行执行的基本单元。一个CUDA并行程序由多个thread来执行,thread是最基本的执行单元(the basic unit of execution)。Thread的执行由SP来完成。一个SP可以执行一个thread。
- Block:数个threads组成一个block。一个block占用一个SM运行。
- Grid(线程网格):多个blocks则会再构成Grid。一个Kernel函数对应一个Grid。Grid运行在device之上。
- Warp: 执行程序时的调度单位,32/16个threads组成一个warp。每个warp中的thread可以同时执行相同的指令,从而实现SIMT(单指令多线程)并行。warp是SM中最小的调度单位(the smallest scheduling unit on an SM),一个SM可以同时处理多个warp;
Grid、Block、Thread是线程组织的三个层次,是一种软件架构,和硬件无关。因此理论上我们可以以任意的维度(一维、二维、三维)去排列Grid,Block,Thread。这个软件架构落实到硬件上就分别对应一个个的SM或者SP。硬件并没有维度这一说,只是软件上抽象成了具有维度的概念。具体如下图所示。
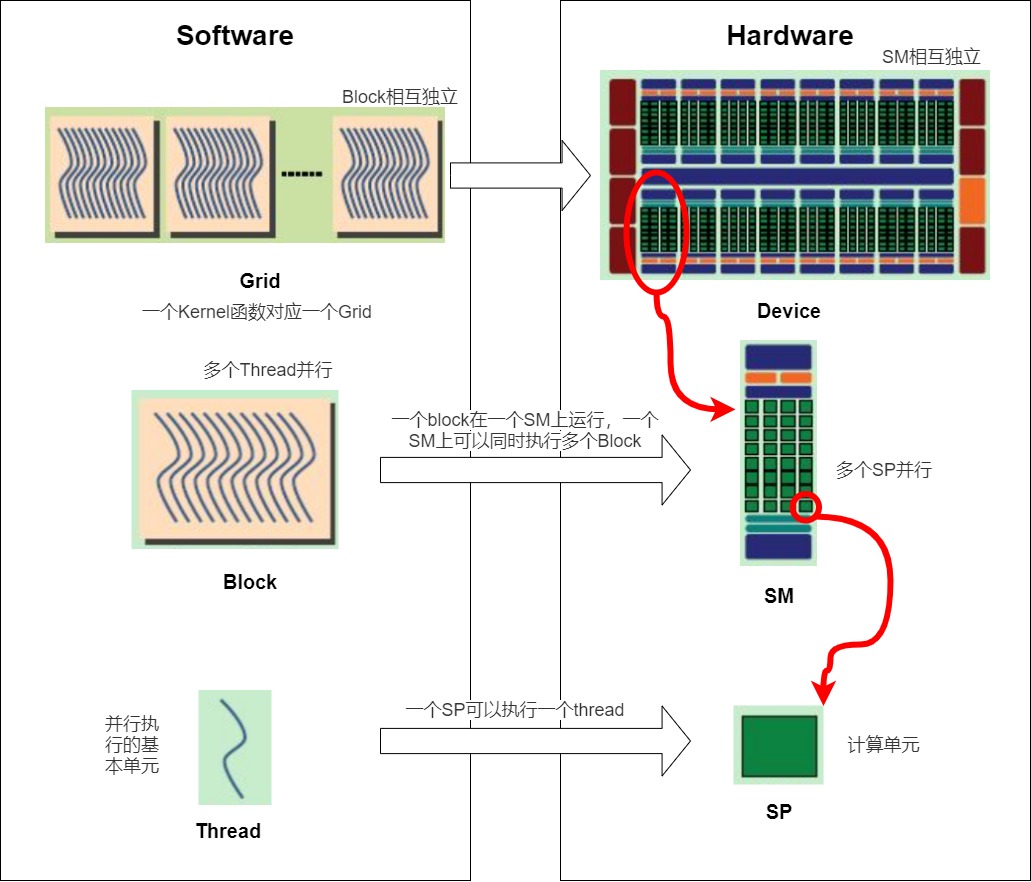
这些软件概念和硬件资源的具体解释如下,我们这次按照从上到下的层级来进行介绍。
Grid & Device
Grid的作用是线程数量控制和差异性执行。CUDA让Host程序里的一个个Kernel函数按照Grid的概念在device上执行。一个Kernel函数对应一个Grid;Grid跑在device上的时候,可能是独占一个device,也可能是多个kernel并发占用一个 device;
Block & SM
Block是线程块,同一个block中的threads可以同步,也可以通过共享内存来加速通信。每个Grid承接了一个kernel函数的任务。当执行任务时,每一个Grid又把任务分成若干Block(线程块)在SM上运行。Grid和SM的关系是:
- 同一 Grid 下的不同 Block 可能会被分发到不同的 SM 上执行。一个Block的thread只能在一个SM上调度,即Block不能跨SM。
- SM上可以同时执行多个Block,这些Block不一定来自同一个kernel函数。有时候即便SM上剩余资源不足以再容纳一个kernel A的Block,但却仍可能容纳下一个kernel B的Block。多个block需要轮流进入SM。
- 每个线程会占用一定数量的寄存器和Shared Memory,因此SM上同时存活的Block数目不应当超过这些硬件资源的限制。
- 一个thread block可以包含多个warp,同一个block中的thread可以同步,也可以通过shared memory进行通信。thread block是GPU执行的最小单位(the smallest unit of execution on the GPU)。一个warp中的threads必然在同一个block中,如果block所含thread数量不是warp大小的整数倍,那么多出的那个warp中会剩余一些inactive的thread。也就是说,即使warp的thread数量不足,硬件也会为warp凑足thread,只不过这些thread是inactive状态,但也会消耗SM资源。
Thread & SP
一个CUDA的程序(即kernel的任务)最终被拆分到线程来完成。每个Thread中的局域变量被映射到SM的寄存器上,而Thread的执行则由CUDA Core也就是SP来完成。
Thread & Warp
因为Block的大小不定,所以我们实际上无法对一个任意大小的Block都给出一个同等大小的CUDA核心阵列去并行计算。为了更好的管理和执行Thread,GPU采用了SIMT(Single Instruction Multiple Threads)架构,提出了Wrap(线程束)概念。我们首先看看SIMT和SIMD的区别。
-
CPU中通过SIMD来处理矢量数据。纯粹使用SIMD不能并行的执行有条件跳转的函数,很显然条件跳转会根据输入数据不同在不同的线程中有不同表现。
-
GPU则使用SIMT来处理数据。无需开发者费力把数据凑成合适的矢量长度,并且SIMT允许每个线程有不同的分支,利用SIMT 才能做到不同分支的并行操作。
Wrap是GPU编程架构中的最小调度/执行单元,同一个Warp里的线程执行相同的指令,即SIMT。Block被划分成一块块的warp分别映射到CUDA核心阵列上执行,每一个warp就都可以理解为是一个线程的集装箱,为的是线程数量固定统一可以给他分配统一的硬件资源,每个集装箱只装一种货物,也就是同步执行的意思。一般为32个线程为一个warp,它们在同一个时钟周期内并行执行相同的指令,实现了单指令、多线程。每个线程能够访问自己的寄存器,不同的warp在计算时会从SRAM中读取计算所需的数据(即共享存储寄存器),即不同的Warp从不同的地址加载和存储,并遵循不同的控制流路径。
总结
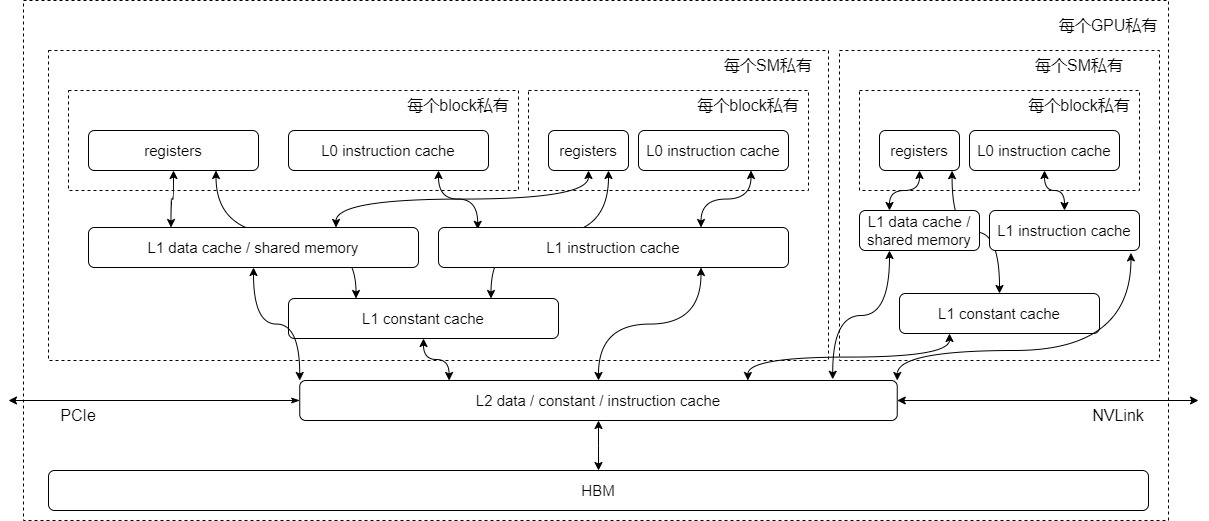
现在,我们将GPU的计算核心SM及不同层级GPU存储结构综合起来,绘制一张简化图。
- 寄存器:GPU中的每个SM都拥有大量寄存器。这些寄存器在核心之间共享,并根据线程需求动态分配。在执行过程中,每个线程都被分配了私有寄存器,其他线程无法读取或写入这些寄存器。
- L1缓存/shared memory:每个SM都有自己的L1缓存,用于存储SM内的数据,被SM内所有的cuda cores共享。SM间不能互相访问彼此的L1。NV Volta架构后(Volta架构前只有Kepler做过合并),L1和shared memory合并,目的是为了进一步降低延迟。合并过后,用户能写代码直接控制的依然是shared memory,同时可控制从L1中分配多少存储给shared memory。其中FlashAttention中SRAM指的就是L1 cache/shared memory。
- L2缓存:所有SM共享L2缓存。L1/L2缓存的带宽都要比显存的带宽要大,也就是读写速度更快,但是它们的存储量更小。
- HBM:即显存。
1.2 Transformer的内存和计算
从计算科学角度来看,操作的性能瓶颈有两类:计算受限(Compute-bound或者math-bound)和内存受限(Bandwidth-bound或者Memory-bound)。而想降低Transformer模型的计算复杂度和空间复杂度,就需要找出Transformer核心组件注意力机制的资源瓶颈究竟是计算能力还是显存,这样我们就可以知道应该在哪个方面进行优化。
基本概念
我们接下来从基本概念入手进行分析。
- 计算带宽(math bandwidth)\(\pi\)。此概念可以理解为算力,具体指的是处理器每秒钟可以执行的数学计算次数,单位通常是OPS(operations/second)。如果用浮点数进行计算,则单位是FLOPS(每秒执行的浮点数操作次数)。
- 内存带宽 (memory bandwidth)\(\beta\)。此概念指的是处理器每秒钟从内存中读取的数据量,单位是bytes/second。
- 计算强度 (arithmetic intensity) \(I = \frac{N_{op}}{N_{byte}}\)。此概念指的是算法对于内存带宽的需求,即在此算法中,平均每读入单位数据(IO)能支持多少次浮点运算操作(FLOP)。它可以通过将FLOPs的总数除以访问的字节总数(也称为MOPs或内存操作)来计算。
- 计算强度上限 \({I_{max} = \frac{\pi}{\beta}}\)。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是
FLOPs/Byte。计算带宽和内存带宽这两个指标相除即可得到计算平台的计算强度上限。 - 模型的理论性能 \(P\):模型在计算平台上所能达到的每秒浮点运算次数(理论值)。单位是
FLOPSorFLOP/s。
计算受限与内存受限
程序的执行时间主要花在两个地方:计算和读写数据。因此我们得到以下两个时间。
一般来说,计算时间和访存时间可以重叠,即“一边计算,一边读/写下一个”,因此总的运行时间为\(max(计算时间,访存时间)\)。
- 计算受限(math-bound)。当计算时间大于访存时间,即完成某操作的大部分时间是在GPU的流多处理器上计算(GPU执行块状并行计算),就说明计算带宽是算法的瓶颈。读得快,算得慢,这就是计算受限(math-bound)。此时HBM访问所花费的时间相对较低,不管模型的计算强度有多大,它的理论性能最大只能等于计算平台的算力。比如:大矩阵乘法、通道数很大的卷积运算。
- 内存受限(memory-bound)。当访存时间大于计算时间,即完成某操作的部分时间是将数据从内存移动到流多处理器(而不是实际在流多处理器上计算),就说明内存带宽是算法的瓶颈。算得快,读得慢,这就是内存受限(memory-bound)。当模型的计算强度 小于计算平台的计算强度上限时,此时模型理论性能的大小完全由计算平台的带宽上限以及模型自身的计算强度决定。逐点运算的操作大多是内存受限的,比如:激活函数、dropout、mask;另外规约类(reduction)操作也是内存受限的,比如:sum,softmax,batch normalization和layer normalization。
注意力机制的计算强度
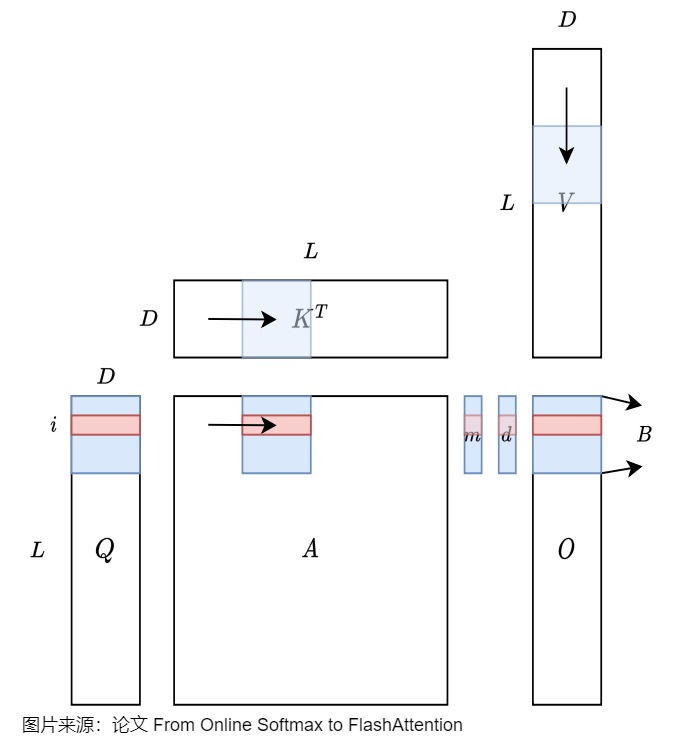
为了评估Transformer中的瓶颈,需要对计算Transformer仅编码器和仅解码器模型所需的浮点运算(FLOPs)数量以及这些网络的算术强度进行建模。注意力机制的计算过程中最重要的部分是计算注意力权重,我们来看看其计算强度。假定有 \(Q,K \in R^{N \times d}\),计算 \(P=QK^T \in R ^{N \times N}\),\(O=PV \in R ^{N \times N}\),其中d是注意力头维度。参考下面图例,得出注意力权重的计算强度如下:
注意:有的论文或者博客省略了第3,4步,所以计算MAC会和本文不同。

矩阵乘法是计算受限还是内存受限,取决于这个公式和所在平台计算强度$I_{max} \(的比较结果。A100-40GB SXM的平台计算强度\)I_{max} $为201 flops/bytes。因此,如果矩阵乘法的计算强度大于201,此时的性能受限于计算带宽;反之,性能受限于内存带宽。而GPU的计算速度会“远快于”显存带宽。因此,对于注意力机制这类访存密集型任务,决定生成速度的不是GPU的计算能力,而是显存的带宽。另外,注意力机制中的一些操作也是内存受限的逐点运算,比如对S的mask操作、softmax操作和对P的dropout操作,这些逐点操作的性能也受限于内存带宽。
如何平衡
有研究人员对BERT Base和BERT Large编码器以及GPT-2解码器在不同序列长度上的算术强度进行分析。
- 对于短序列长度(例如128-512),大多数计算在FFN模块的投影层中,而MHA计算的大部分在投影层中。
- 随着序列长度的增加,矩阵乘法开始占主导地位,因为它们都是按序列长度二次缩放的。这导致算术强度在起初会增加,因为较大的矩阵维度允许每个加载的参数执行更多的计算。
- 然而,在较高的序列长度下,算术强度会降低。这是因为,对于长序列长度,MHA模块的矩阵乘法和Softmax计算开始占主导地位。与FFN模块中的投影层相比,这些具有相对较低的算术强度。
这些观察结果证实了,解码器推理是一个内存约束问题,而不是计算约束问题。那么要平衡利用 GPU 算力和内存带宽,batch size 需要是多少呢?其计算公式是 2 byte * 参数量 / 卡的数量 / 内存带宽 = batch size * 2 * 参数量 / 卡的数量 / 算力。等式左右两边参数量和卡的数量互相抵消,最终得到 batch size = 算力 / 内存带宽。这就需要依据不同芯片的参数来进行调节。另外,也要考虑网络延迟以及通信库本身的开销。
1.3 Tiling
Tiling(平铺)是一种通过分割输入和维护一些中间变量来递推式地完成操作,从而减少内存消耗的技术。这种平铺方法是有效的原因是:加法是关联的,允许将整个矩阵乘法分解为许多平铺矩阵乘法的总和。
对于大矩阵,如果对整个矩阵直接进行操作,则会消耗巨大的内存。我们知道矩阵乘具有分块和累加的特性,因此一个大的矩阵乘法可以通过Tiling技术来分解成更小的子矩阵,然后分别把这些小矩阵从慢速HBM加载到快速SRAM,在SRAM中对这些小矩阵进行计算,最后再把各个分块矩阵乘的结果进行累加获得最后的正确结果。
下图简要解释了如何对矩阵乘法\(C=A \times B\)的输入和输出矩阵进行划分。每个矩阵被划分为\(T \times T\)分片。对于每个输出分片,我们从左到右扫描A中的相关分片,从上到下扫描B中的相关分片,并将值从全局内存加载到片上内存(颜色为蓝色,整个片上内存占用面积为\(O(T^2)\))。对于位置(i,j),我们从片上存储器为分片内的所有k来加载A[i,k]和B[k,j](用红色表示),然后在片上存储器中将\(A[i,k]\times B[k,j]\)聚合到C[i,j]。在一个分片的通信完成后,我们将片上C分片写回主存,然后继续处理下一个分片。
另外,我们也可以将计算所需的数据提前或者异步的方式从HBM加载到SRAM,结合流水线编排就可以进一步隐藏掉数据加载所需时间。
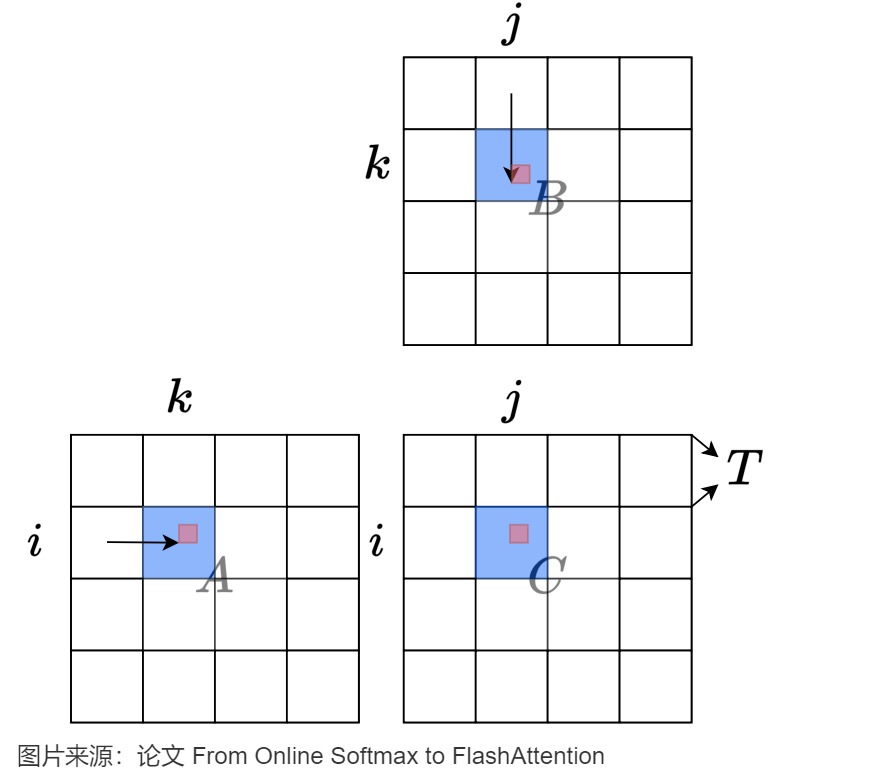
该操作对于的伪代码如下:
a = A_i
b = B_j
c = C_ijfor k in range(k):c += a[k] * b[k]final c done
1.4 算子融合
在推理引擎实现中,对于性能受限于内存带宽的操作进行加速的常用方式就是算子融合,其基本思想是:在SRAM存储容许的情况下,将多个操作融合成一个操作来完成,从而避免反复执行“从HBM中读取输入数据,执行计算,将计算结果写入到HBM中”。
我们通过实例来进行分析。假设要连续执行算子A和算子B,其中算子A的输出是算子B的输入。最朴素的执行顺序如下:
- 启动算子A,把A所需要的数据从HBM拷贝到SRAM。
- 运行算子A。
- 把算子A的结果写回到HBM。
- 启动算子B,把B需要的数据从HBM拷贝到SRAM。
- 运行算子B。
- 把算子B的结果写回到HBM。
这个序列涉及到四次读写HBM操作和两次启动算子操作,会造成运行时间增加。
在算子融合的思路下,如果发现SRAM完全有能力存下算子A的输出结果,我们会把算子A和算子B合并成一个操作。这样A的输出就直接暂存在SRAM中让B来读取,从而可以减少读写HBM的次数,启动算子的动作等,从而有效减少内存受限操作的运行时间。
0x02 优化注意力机制
因为FlashAttention优化了注意力计算过程中的访存(HBM)的过程。所以我们先来看下标准注意力机制的计算访存。
2.1 标准注意力机制
计算公式
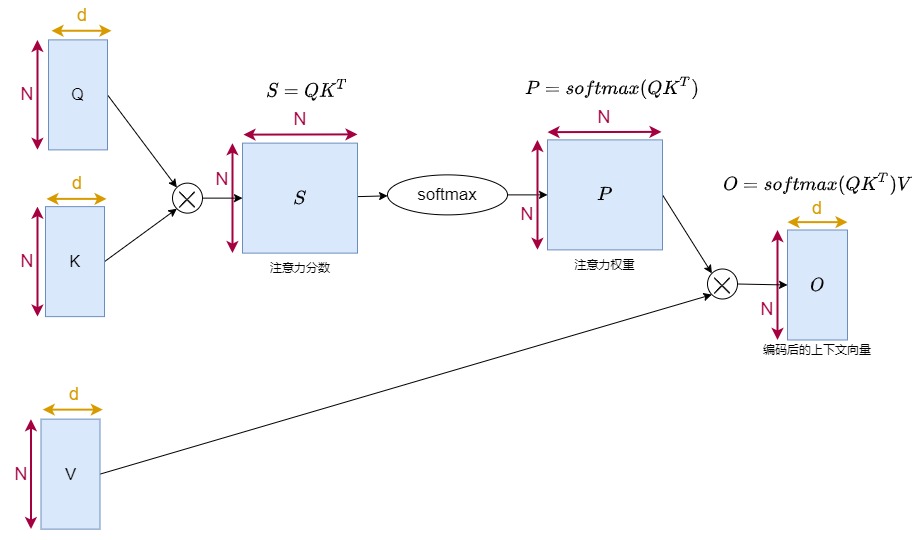
回顾缩放点积注意力(Scaled Dot-Product Attention)模块的公式如下:
这个公式中,Q和K的维度均是\((N,d_k)\),V的维度是\((N,d_v)\),其中\(N\)是输入序列长度,\(d_k,d_v\)是特征维度。\(softmax(QK^T)\)的维度是\((N,N)\),\(Attention(Q,K,V)\)的输出维度是\((N,d_v)\)。
为了描述方便,后续在讨论中省略了Mask和Scale。由于多头注意力各个头的计算逻辑是一致的。这里也只描述单个头的情况。因此,假设一共有 N 个token,每个token向量的维度为 d ,则一个简化版注意力计算过程如下图:
实现算法
FlashAttention论文中给出的标准注意力机制的实现算法如下图所示。算法具体分成三步(也叫做3-pass算法):
- \(S=QK^T\)(计算注意力分数)。\(QK^T\)目的是获得每个query相对于所有key的点积。直观上,点积越大,某个Q行和某个\(K^T\)的列的相关性就大。具体操作时,注意力机制会从HBM中加载\(Q,K\)矩阵,执行计算点积\(S=QK^T\)的操作得到相似度得分\(S\),再将结果\(S\)写回HBM。
- \(P=softmax(S)\)(计算注意力权重)。softmax操作的目的是对注意力分数进行归一化。具体操作是将\(S\)从HBM中读取出来,执行\(P=softmax(S)\)的计算得到注意力权重,再将\(P\)写回HBM。
- \(O=PV\)(计算最终注意力结果)。将\(P\)和\(V\)从HBM中读取出来,执行\(O=PV\)的计算,最后把向量\(O\)写回HBM中。

注:算法中省略了mask和dropout操作,Q,、K、V、O都是2D矩阵,形状为(N,d)。N为序列长度,d为注意力头维度。
我们将上述算法用图例展示如下。

细化拆解
上面的图没有展示出SRAM和HBM之间的交互,我们从其他论文中找出更加详细的算法实现如下。

下图展示了算法中SRAM和HBM之间的交互流程和读写的数据量大小,图中的序号和上面算法的序号一致。
注意:有的论文或者博客省略了第3,4步,所以计算MAC会和本文不同。

问题所在
标准注意力算法在GPU内存分级存储的架构下存在两个缺陷:显存占用多和HBM读写次数多。造成缺陷的罪魁祸是\(QK^⊤\)操作。该操作一方面决定了注意力机制的算法复杂度是\(O(N^2)\),另一方面其产生的两个中间矩阵S和P的内存占用过大,需要在HBM和SRAM中搬运,而 HBM 的读写带宽 相比 SRAM 低很多,于是减慢了运行时间(wall-clock time)。我们接下来一一进行分析。
- 显存占用多。3-pass算法的输入和输出变量Q,K,V,O 所需要的内存为$ O(Nd)$ ,步骤一和步骤二会分别产生两个中间矩阵S和P,内存需求均是\(O(N^2)\),因此总内存需求是\(O(N^2+Nd)\)。当序列长度N很大(即 N≫d)时P和S 需要的内存 $O(N^2) \(远大于 Q,K,V,O 所需要的内存\) O(Nd)$ ,这样会耗尽显存,同时GPU HBM的访存压力也会急剧变大为\(O(Nd+N^2)\)。
- HBM读写次数多。因为中间矩阵内存占用过大,无法被SRAM容纳,因此需要从SRAM转移到HBM中。但是因为计算需要,S和P在存入HBM后又立即被访问,所以导致多次读写HBM操作。3-pass算法的三个步骤分别对应三个kernel(具体在算法图中有标明):gemm、softmax和gemm。三个kernel依次执行。每个kernel的计算过程都存在如下操作:从HBM读取数据;计算;写回HBM。一共包含八次HBM的矩阵读写操作,总HBM访问次数为\(O(Nd+N^2))\)。具体八次操作分别为:
- 第一步有三次操作。两次读操作为从HBM中读取完整的Q和K矩阵(每个大小为\(R^{N×d}\) ),一次写操作为把相似度得分S(大小为\(R^{N×N}\) )写回到HBM。总共需要进行\(O(Nd + N^2)\)次HBM访问,其中涉及到一次超大矩阵S的读取。
- 第二步有两次操作。一次读操作为从HBM中读取完整的S矩阵,一次写操作为把P(大小为\(R^{N×N}\) )回写到HBM。总共需要进行\(O(N^2)\)次HBM访问,而且涉及到两次超大矩阵的读写。
- 第三步有三次操作。两次读操作为从HBM中读取完整的P和V矩阵(大小为\(R^{N×d}\)),一次写操作为把输出向量O(大小为\(R^{N×d}\))写回到HBM,总共需要进行\(O(Nd)\)次HBM访问,其中涉及到一次超大矩阵P的读取。
2.2 解决方案
既然知道了\(QK^⊤\)操作是罪魁祸首,我们就思考下如何把计算过程中间结果所需的内存空间减低,让中间结果可以暂存在SRAM中,从而减少I/O读写,优化IO时间。
思路
我们的目标是计算O,一般来说,我们需要获取所有的Q,K,V,然后分三步计算;我们也可以先获取一小块Q,K,V,一次计算得到部分的O,再想办法将部分的O合成全部的O。
前面提到,注意力机制(\(softmax( \frac{QK^T}{\sqrt d_k} ) \times V\))的三个主要计算模块为计算注意力分数,归一化和根据注意力权重的加权求和,分别对应依次执行的三个kernel:gemm(query×key)、point-wise的softmax、gemm(attn_score×value)。如果SRAM可以存储中间结果,我们将这三个kernel融合起来,让中间结果数据停留在SRAM上面,就会避免重复从HBM上读写中间全局内存,从而达到对 pointwise 操作加速的目的。注,我们暂时抛开softmax计算的特殊性,假设其可以融合。
因此,我们的总体方案是:用“融合+分块”来避免频繁从HBM读写大型矩阵。即抹去对大型矩阵S,P的读写。融合+分块是一个硬币的两面,互相交织,需要统一对方案思路进行分析,即:
- 因为要减少IO,所以要以两个gemm kernel为中心来进行算子融合。
- 融合的前提是要把所有中间变量都存起来,不写回HBM;
- 而SRAM没有这么大空间来容纳中间矩阵,因此就需要做融合时候考虑分块。只要分块矩阵和中间注意力结果可以在SRAM内存放,就可以在计算过程中只访问SRAM了。
我们接下来就看看算子融合和分块计算。
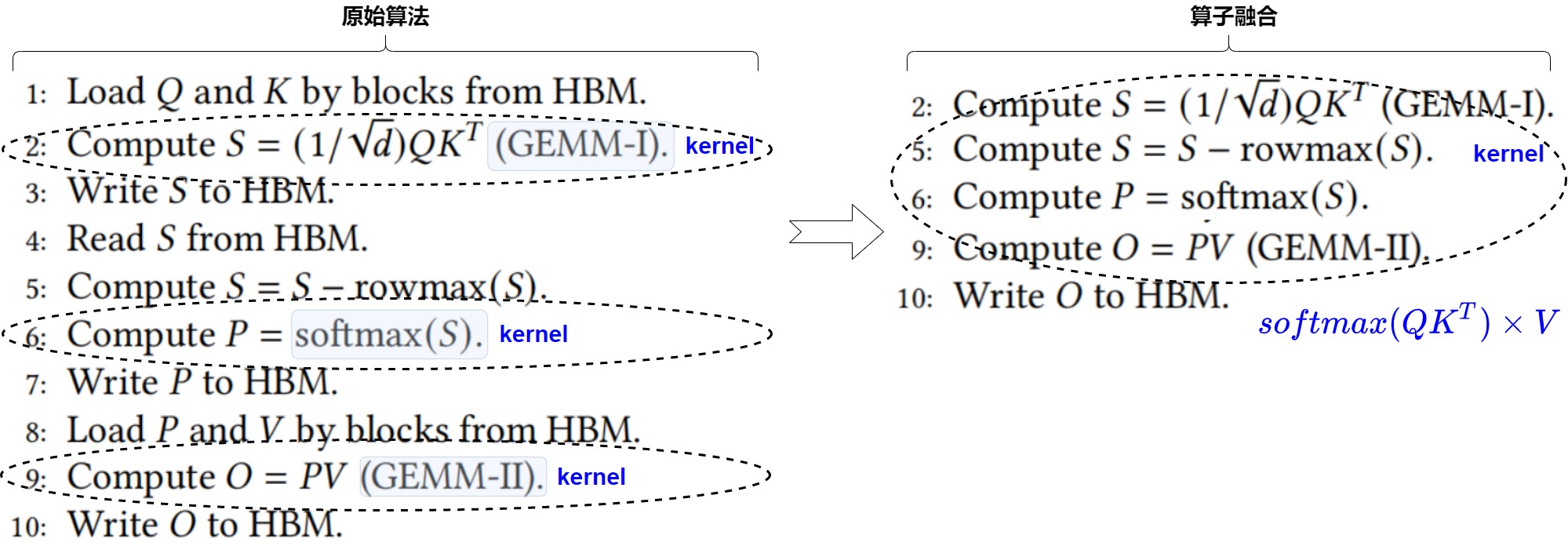
算子融合
针对注意力计算,我们的思路就是:针对数据的换入换出进行优化,把两个gemm和softmax融合成一个算子:\(softmax( QK^T) \times V\)一次性在SRAM中处理,从而减少S和P的读写。
标准注意力的算法是:在 SRAM 上计算 \(S=QK^T\) ,将矩阵 S 写入到 HBM 中,然后再将矩阵 S 从 HBM 读入到 SRAM 中,计算 P=softmax(S) 。
在算子融合方案下,上述操作可以合并在一个 kernel 中完成,即在 SRAM 中计算完 S 之后紧接着就通过 S 计算 P ,这样就可以避免在 HBM 和 SRAM 交换 S 。
分块计算
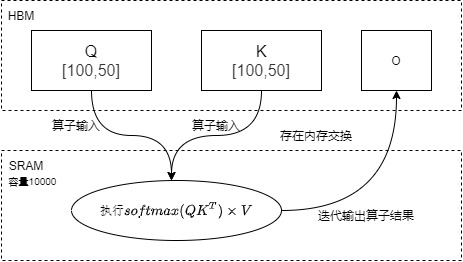
前面提到,算子融合的前提是SRAM存储足够大,或者说,只有SRAM能够容纳中间结果,才有算子融合的可行性。这是因为虽然算子融合有效,但是解决不了内存开销太大的问题。
比如下图中SRAM能容纳10000个数据,但是Q和K都是5000个数据。如果一次性运行融合算子\(softmax( QK^T) \times V\),则需要加载10000个数据到SRAM,但是这样就无法容纳中间计算结果,会造成OOM,因此只能通过迭代方式进行计算,依然导致大量对HBM的读写操作。
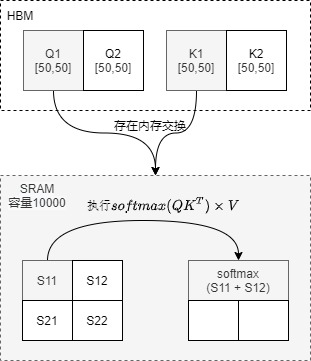
因为SRAM的内存大小有限,不可能一次性计算完整的注意力。而全连接层和根据注意力权重的加权求和其实都是通过矩阵乘法实现的,因此可以通过tiling操作来进行分块计算。在分块计算中只加载必要的参与计算的Q,K,V的分块到SRAM ,这样其总体内存不超过SRAM的大小,并且计算完成S后,直接使用S来计算P。借此来提高整体读写速度(减少了HBM访问次数)。具体如下图所示
- 将Q [100,50] 切分成两个矩阵
- 将 K [100,50] 切分成两个矩阵
- 此时\(softmax( QK^T) \times V\)算子可以在SRAM 一次性算完这些小块的注意力操作。
因此,我们得到了总体思路如下:QK^T 生成了一个形状为 (b, n, s, s) 的临时输出,而我们只需要 Softmax(QK^T)V 的最终结果,其形状为 (b, n, s, d)。只要 s 和 d 相对较小,我们就可以将这三个矩阵的乘法融合成一个单独的Cuda核(Kernel)函数,直接产生 Softmax(QK^T)V。
限制
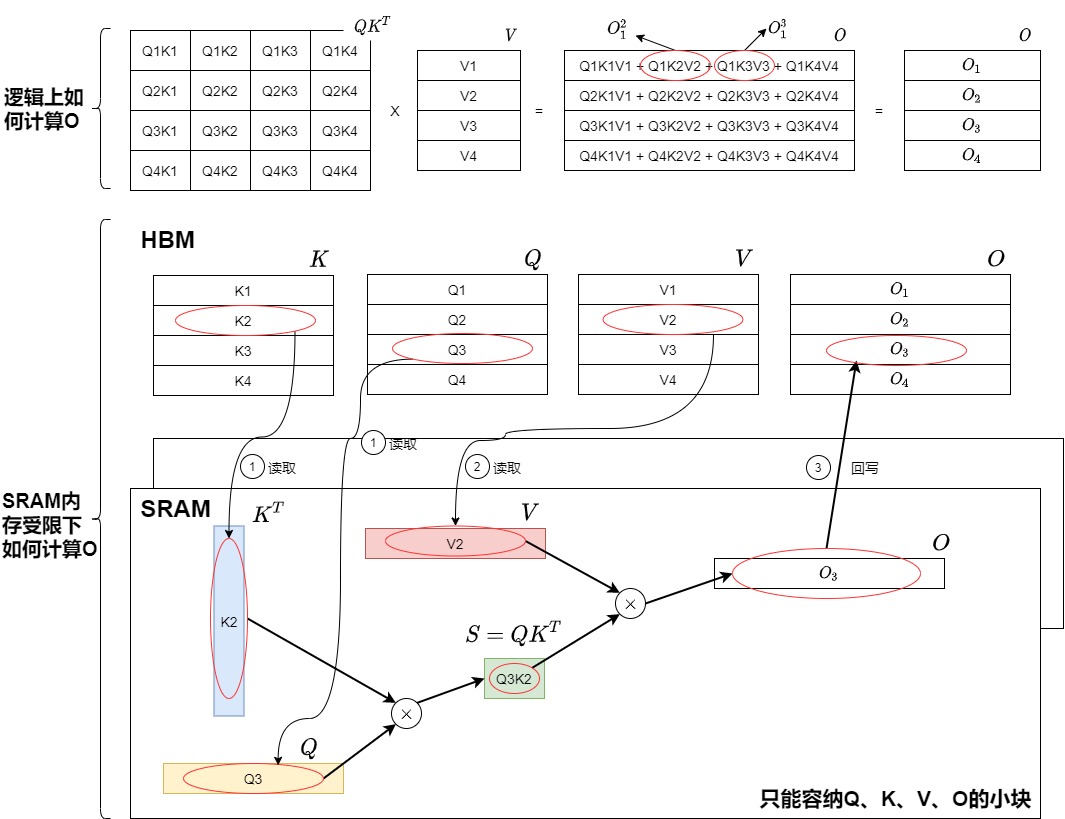
看过了Softmax(QK^T)V 得大致思路,我们再仔细看看如何计算O以及的SRAM的限制,这里做几点说明。
- 生成\(O_j\)是累加更新操作。我们以\(O_1\)为例进行说明。
- \(O_1\)是从\(O_1 = Q1K1V1\)一直累积更新,最终得到\(O_1 = Q1K1V1 + Q1K2V2 + Q1K3V3 + Q1K4V4\)。
- 为了更好的分析,我们把\(O_j\)看做是包含 i 个元素的一行向量,即把加法的每项看作是一个元素(如下图所示,\(O_1^2\)和\(O_1^3\)是两个元素),即\(O_1^2\)是第一行的第二列。
- 每次更新\(O_1\)需要把\(O_1\)前面一列加载到SRAM,然后才可以对\(O_1\)进行增加新列的操作。
- 省略softmax操作,即kernel函数是计算
(QK^T)V。 - SRAM每次只能够容纳Q、K、V、O的小块。
如何计算O是难点所在,我们接下来看看两个方案。
方案1
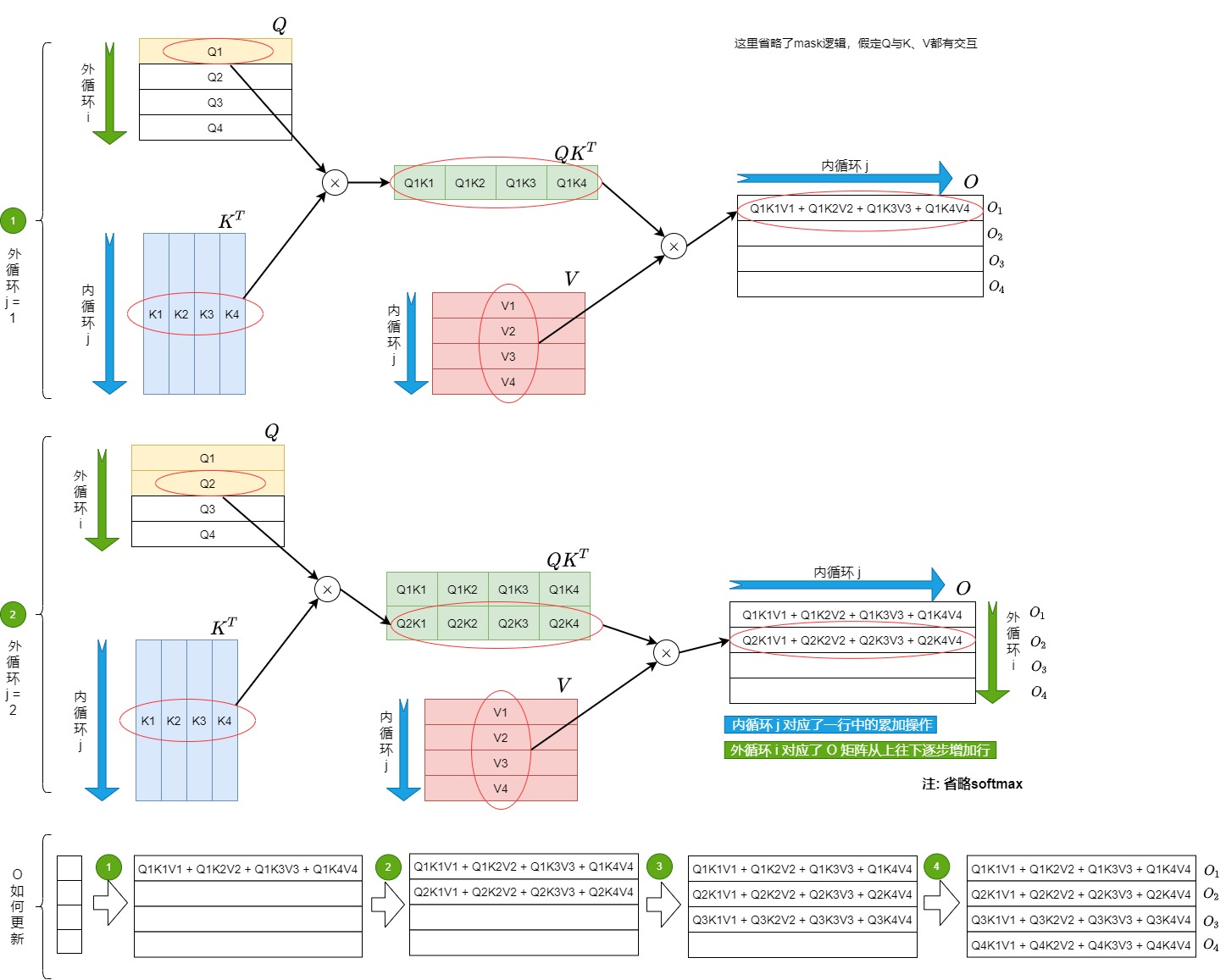
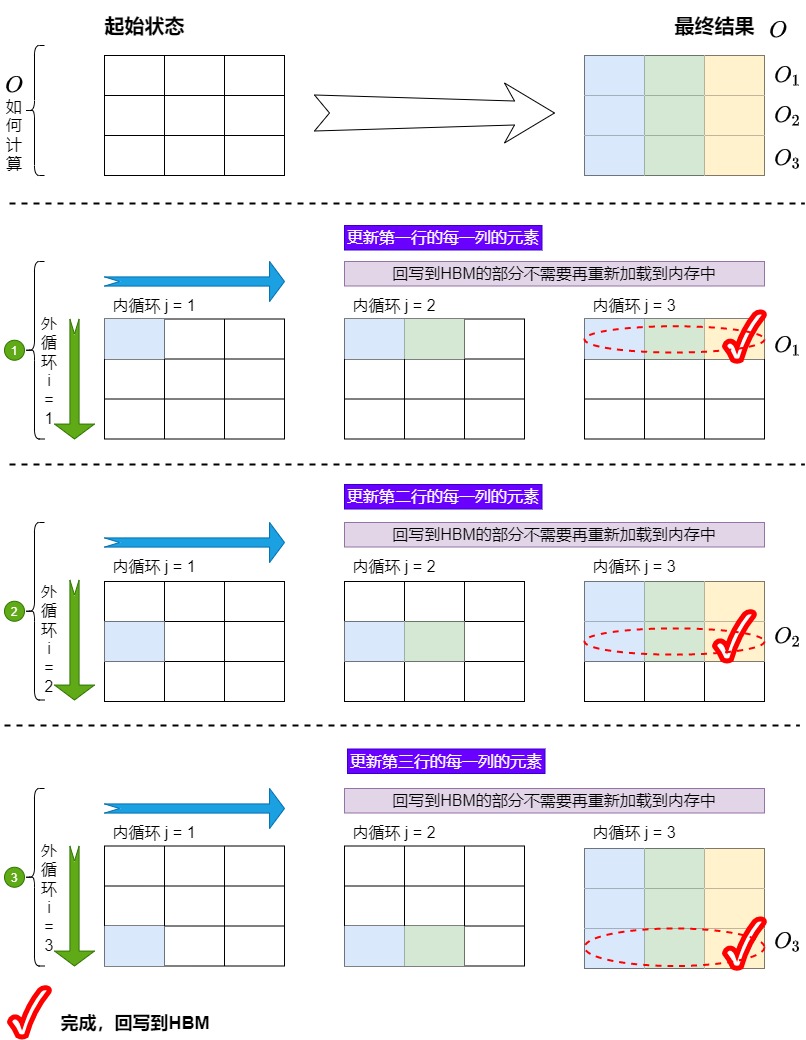
我们得到方案1的逻辑方案如下图,具体思路是:
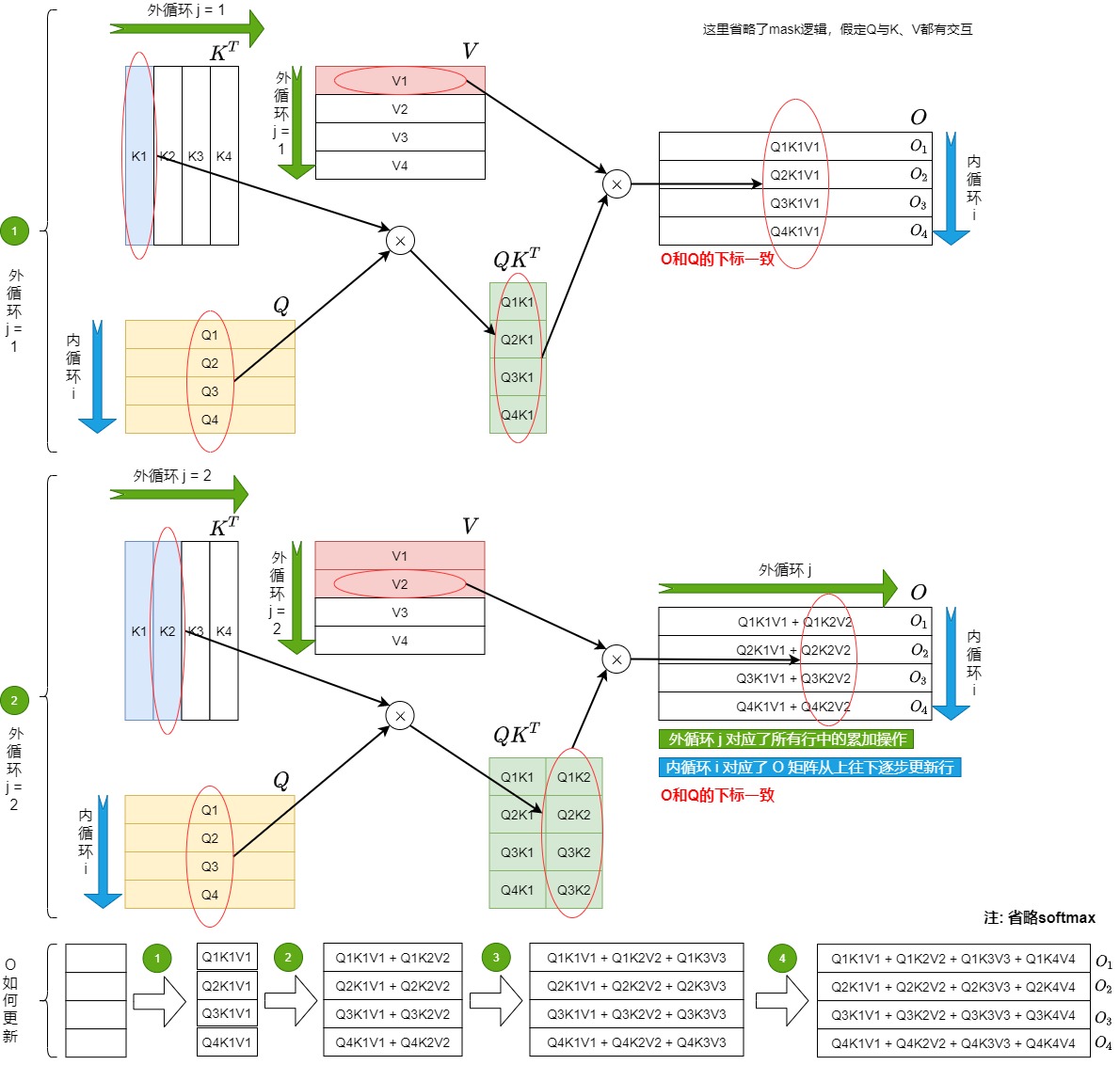
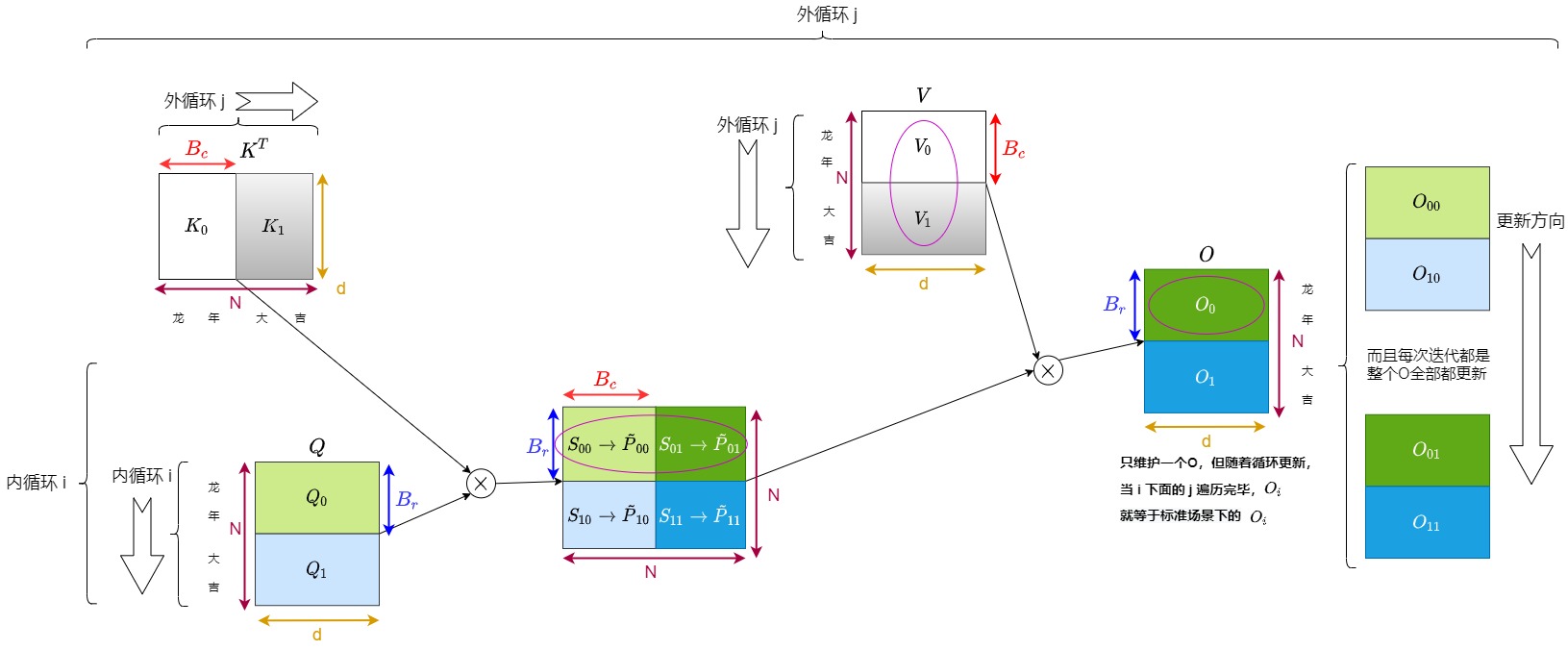
首先将K、V切成了Tc个小块,将Q和O切分为Tr个小块。
接下来开始进行循环计算。j 是外循环, i 是内循环,或者说K和V是外循环j,Q和O是内循环i。
外循环逻辑如下:
- 外层第j次循环拿到了K矩阵和V矩阵的第j个块 \(K_j\),\(V_j\),加载到SRAM中。
- 每次外循环都对 \(O_{1}\)到\(O_{tr}\)全部进行更新,但是每次分别只更新 \(O_{1}\)到\(O_{tr}\)的一部分。
- 最终所有j循环结束后,得到的最新的完整O就是期望的结果, \(O_{1}\)到\(O_{tr}\)是直到外循环结束之后才一次性全部更新完成。
第j个外循环的内循环 i 会逐行更新\(O\)的每一行$$O_i$$,其逻辑如下:
- 把Q矩阵的第i个块\(Q_i\)和O矩阵的第i个块\(O_i\)(即\(O_i\)行的前一个状态,可以简单理解为\(O_i\)的前一列\(O_i^{j-1}\))加载到SRAM。
- 用\(K_j\)和\(Q_i\)计算得到了S和P,再和\(V_j\)相乘得到了\(O_i\)行的新一列$$O_i^j$$。
- 用\(O_i^{j-1}\)和\(O_i^j\)累积,更新\(O_i\)。
- 把\(O_i\)回写到HBM。
- 内循环期间一共对O进行\(Tr\)次更新。
写成伪代码如下。
# ---------------------
# Tc: K和V的分块数
# Tr: Q和O的分块数量
# ---------------------
O_0 = 0
for 1 <= j <= Tc: # 对K和V进行外循环load V_j, K_jfor 1 <= i <= Tr: # 对Q和O进行内循环load O_i^{j-1}, Q_iS = softmax(Q_i @ K_j) #计算得到了SO_i^j = S @ V_j # 得到O_i行的第j列O_i = O_i^j + O_i^{j-1} # 完成O_i的一次累加更新。这里需要从HBM中读取之前的O_i^{j-1} store O_i # 回写
对应图如下,绿色标号表示外循环。
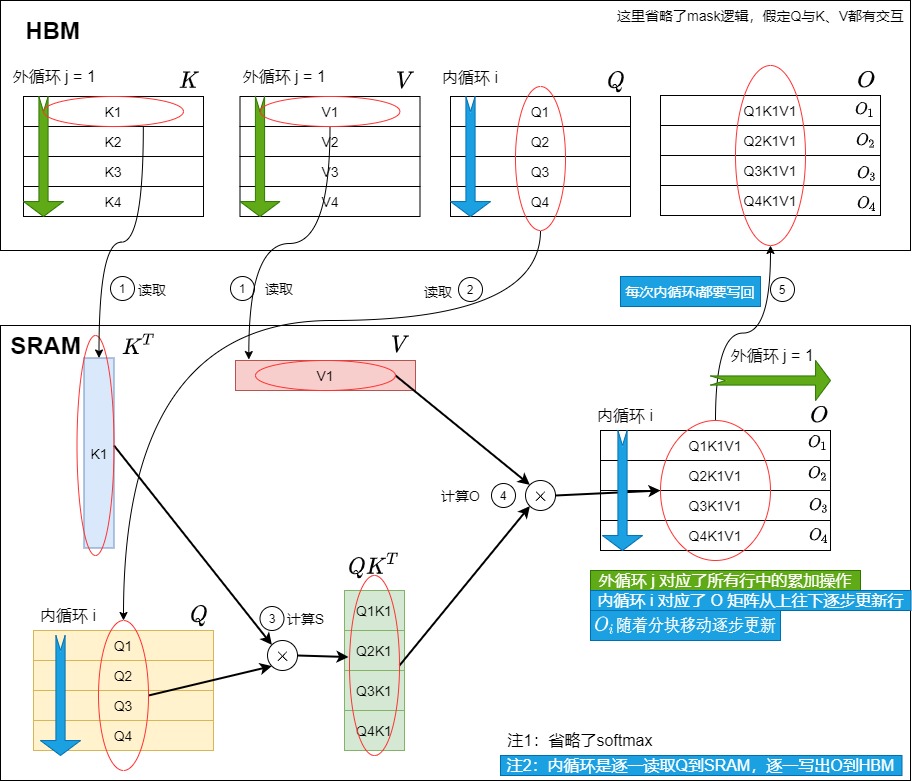
我们再结合HBM和SRAM得到物理方案的分步操作。
- 我们在外循环 j = 1 时,先遍历一次所有的 i,在这个阶段中我们产出 \(O_{1}\)到\(O_{tr}\),并将它们和一些其它重要数据写回HBM中。
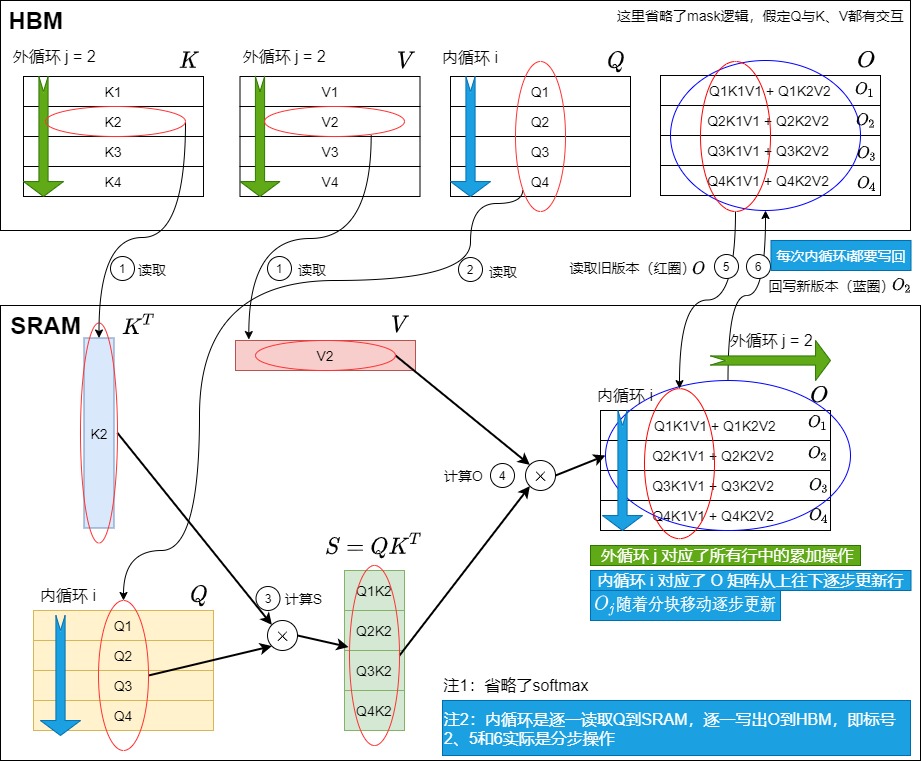
- 接下来我们进行第二次外循环,即 j=2。在这个阶段中我们在内循环中要把之前产出的 \(O_{1}\)到\(O_{tr}\)逐一载入到SRAM,然后在内循环中逐一更新\(O_{1}\)到\(O_{tr}\)。
注意,下图简化了内循环的操作,图中假设一次性把Q读进SRAM,然后进行内循环,最后再一次性写回HBM。实际上是每次内循环都利用\(Q_i\)来计算\(O_i^j\),每次内循环都要回写\(O_i^j\)。
外循环j = 1时如下图所示。
外循环j = 2时如下图所示。
方案2
注意,为了和FlashAttention V2论文一致,此处i是外循环,j是内循环。
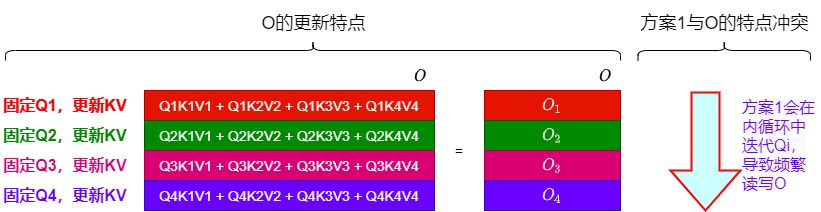
方案1的问题是需要频繁的读写O。即,上面的两重循环中,是先外层循环加载K, V,然后内层循环再加载Q。这就会导致内层循环每次计算的只是\(O_i\)的一部分,每次内循环迭代都需要对\(O_i\)进行频繁的全局内存读写。具体如下:
- 如下图所示,O的更新特点是:O的每一行都是和Q绑定的,即\(O_i\)的更新和\(Q_i\)严格绑定。
- 而在方案1中,其内循环是对Q进行迭代,这与O更新的特点冲突,导致每次迭代\(Q_i\)时,会对 \(O_{1}\)到\(O_{tr}\)逐一加载和更新。而且需要等待外循环全部迭代完成之后,一次性把 \(O_{1}\)到\(O_{tr}\)都更新完成。
而在注意力计算中,不同query的注意力计算是完全独立的。也就是说,如果外部循环是先加载Q,那么就可以把不同的query块的Attention分配不同线程块进行计算,这些线程块之间是不需要通信的。这样\(O_j\)在一个\(Q_j\)周期内完成,就可以减少读写HBM操作。那么,我们为什么不以Q为外循环,以KV为内循环做遍历呢?这样就能避免往HBM上读写中间结果,从而在每次外循环中一次性把\(O\)的一行给算出来。同时,softmax这个操作也是在行维度上的,所以固定Q、循环KV的方式更天然符合softmax的特性。
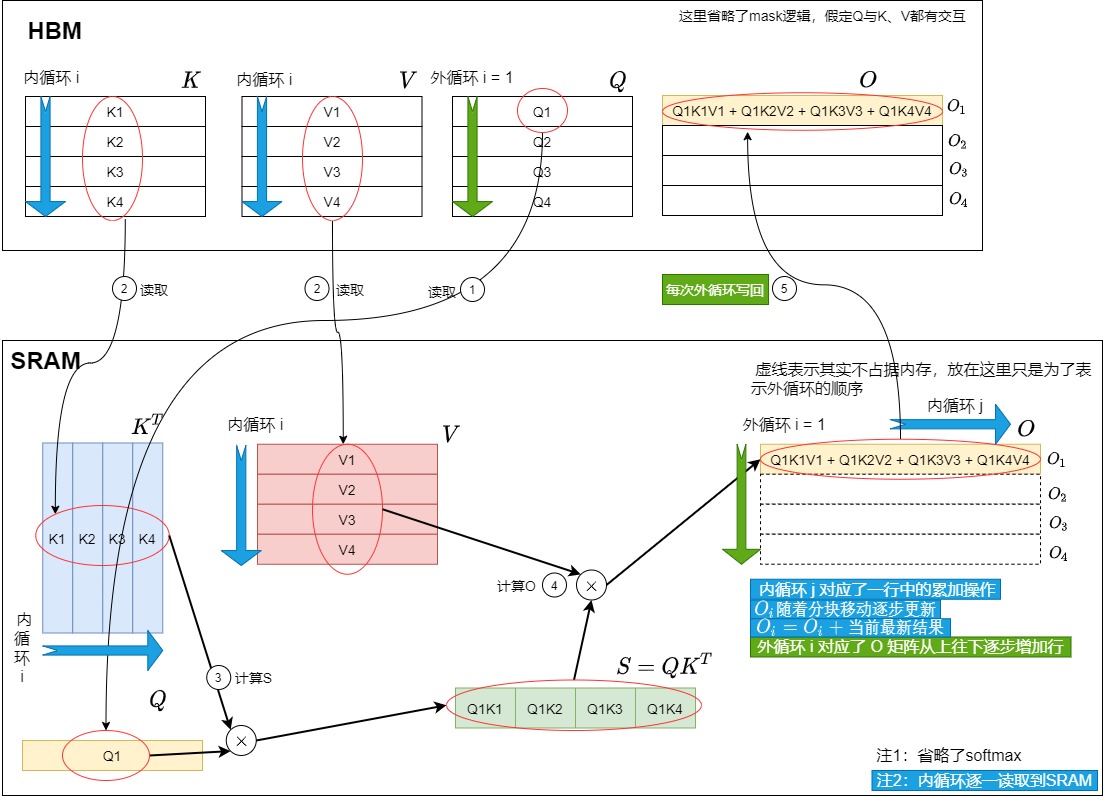
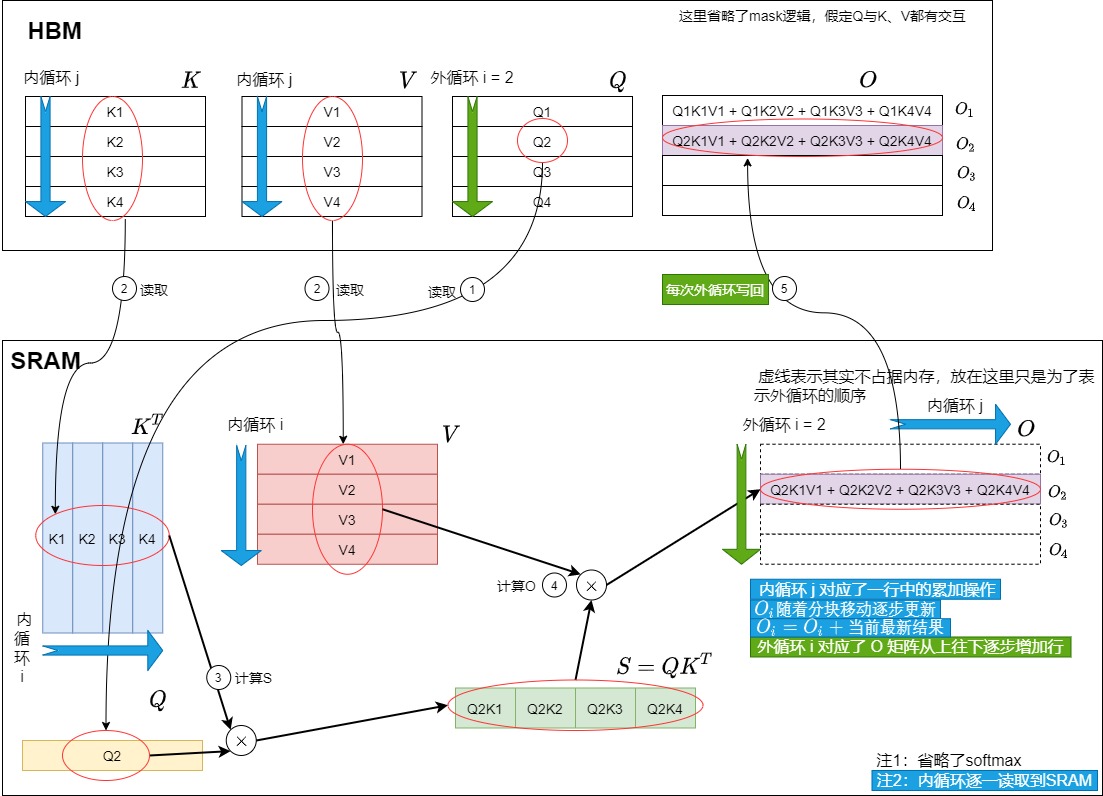
所以,我们新算法调换了方案1中循环的位置,先加载Q和O,再加载K, V,这样就得到了方案2的逻辑图如下。调整循环顺序后,方案2的内循环先计算\(O_i^1\) 为Q1K1V1,然后计算Q2K2V2,在Q1K1V1的基础上得到\(O_i^2\)为Q1K1V1 + Q2K2V2,依次类推。这样在内循环中不需要每次读写\(O_i^j\) 到HBM,从而减少了IO-Accesses,耗时也会随之减少。
我们再结合HBM和SRAM得到物理方案的分步操作。此处简化了内循环的操作,假设一次性把K、V读进SRAM,然后进行内循环,最后再一次性写回HBM。实际上是内循环每次都读\(K_i\)和\(V_i\),计算\(O_i^j\),最后统一回写\(O_i\)。
外循环 i = 1时如下图所示。
外循环 i = 2 时如下图所示。
总结
\(O(N^2)\)复杂度的矩阵对HBM及其重复读写是注意力计算的一个主要瓶颈,为了解决这个瓶颈,我们想出了两个解决方案。实际上,我们的方案1就是FlashAttention V1的雏形,方案2就是FlashAttention V2的雏形。
我们用类似刷墙的方式展示,该刷墙的特殊需求是:当横向刷时,后续的刷需要基于前面刷的结果之上。
方案1如下。每次外循环都要对O的每行都做更新,每次更新都回写。如果把O看作是一个矩阵,则外循环每次固定一列,内循环更新该列中对应的行。
而且,K,V是在外层循环,Q在内层循环,所以一块 K,V 对应的是 Q 的全量,那么中间的 O 也是一个全量,与全尺寸的 Q 大小相同,这个尺寸是相当大的。所以 O 不可能保存在片上,而是写到HBM上。
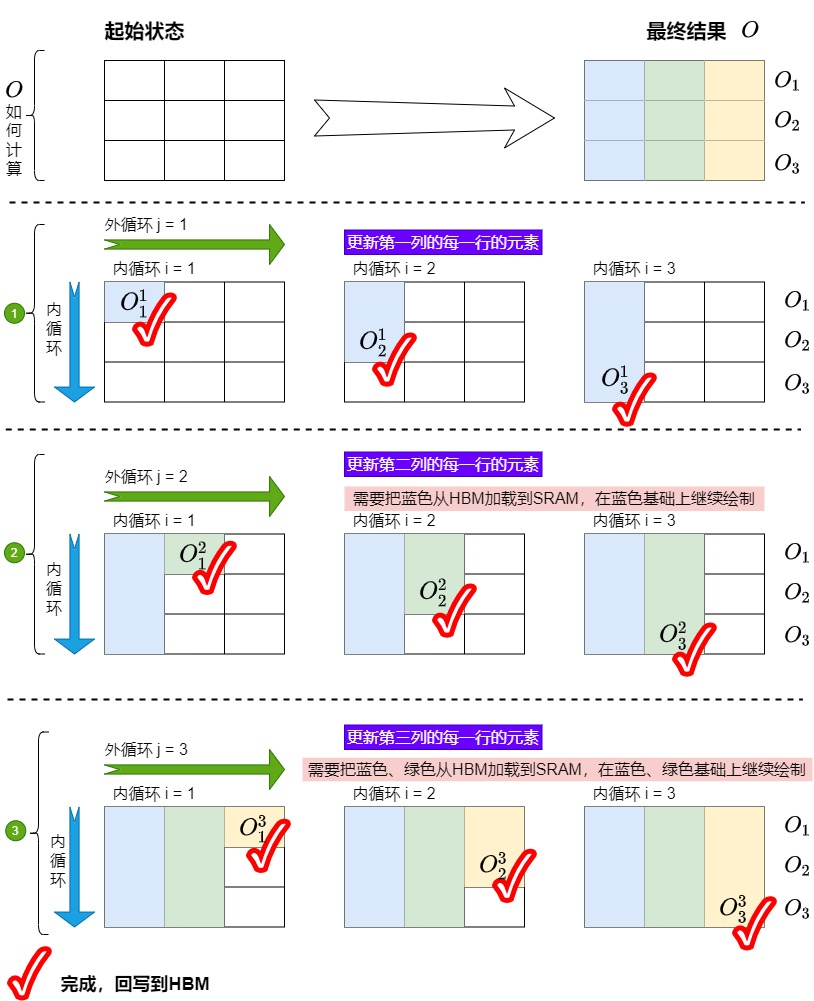
我们用类似刷墙的方式展示方案 2 如下。每次外循环只更新O的一行,正行更新完毕后回写。如果把O看作是一个矩阵,则外循环每次固定一行,内循环更新该行中对应的列。
此时 Q 放到了外循环,K、V 变成内循环,此时一个分块的\(Q_i\),完成了所有分块 \(K_j, V_j\),即得到最终的结果分块\(O_i\),与内循环\(K_j, V_j\)的计算结果可以一直复用\(O_i\),可以保证\(O_i\)一直在片上,甚至一直在寄存器上。
Flash attention(截至目前位置的雏形)的意图就是从 GPU 底层数据存储的角度出发进行优化来减少对HBM的操作和中间矩阵。具体如下。
- 首先进行了算子融合,将\(softmax(\frac{QK^T}{\sqrt d_k})V\)融合成了一个算子,让多步操作依次在 SRAM 执行,避免对中间矩阵S和P的读写。
- 其次依靠tiling技术来解决内存问题。因为SRAM太小,因此将输入 QKV 分割成小块,分块把它们从HBM加载到SRAM中,这样可以保证SRAM可以容纳矩阵运算的中间结果。
- 因为矩阵乘法具有分块和累加的特性,所以大矩阵可以通过拆分成多个小的矩阵乘来完成(拆的越小则 SRAM 需求越低),所以接下来在SRAM中按块进行注意力计算,然后通过将各个分块矩阵乘的结果进行累加获得最后的正确结果。
- 另外,在模型训练更新过程也要存储中间状态,FlashAttention 通过 Recomputation 的方式用计算换存储,减少中间状态的大小。
注意力机制的计算过程是“矩阵乘法 --> scale --> mask --> softmax --> dropout --> 矩阵乘法”,矩阵乘法和逐点操作(scale,mask,dropout)的分块计算是容易实现的。
因为我们只关注了矩阵乘,所以目前看起来一切美好。然而我们的前进路上还有一个拦路虎:softmax。制约注意力机制性能的关键因素,其实是Softmax。我们接下来就看看softmax的问题所在,以及如何解决。
0x03 Softmax改进
我们首先从原生softmax开始看看其存在的问题,以及如何改进。先给出问题概述:矩阵是可加的,但是softmax是不可加的。即,Self-Attention 包含一个不直接关联的 softmax 运算符,因此很难简单地平铺 Self-Attention。
3.1 原生softmax
Softmax 函数是一种常用于机器学习,特别是多分类问题中的激活函数。它的作用是将一个任意实数向量转换为一个概率分布,并确保输出的概率和为 1。
公式
假设某一数组是 \([x_1, x_2, ..., x_V]\),\(x_i\)是数组中某一个元素,原生softmax的计算公式如下:
具体算法如下图所示,算法流程需要两个循环,涉及两次从内存读取和一次写回内存操作:
- 计算归一化项(normalization term) \(d_V\)。Softmax 函数中,分母的求和项被叫做归一化项 \(𝑑_𝑉\),作用是将输入向量中每个元素 \(𝑒^{𝑥_𝑖}\)变为比例较小的数值,保证它们的和为 1,从而符合概率的定义。因此算法首先需要对数组进行遍历,对每个元素都需要进行指数运算,最终得到d这个指数和,把d作为接下来计算的分母。
- 计算输出值\(y_i\)。然后再迭代计算数组中每一个元素的指数跟d的商,即对每一个元素进行缩放。最终完成对整个数组的softmax操作。
每个向量元素都需要进行三次内存访问:两次读取和一次写入。

实现
简单实现的代码如下。
import torch
A = torch.tensor([1., 2., 3., 5., 4.])def native_softmax(x):A_exp = torch.exp(x) # 计算e的指数次幂A_sum = torch.sum(A_exp) # 计算指数和return A_exp / A_sum # scale操作print(torch.softmax(A,dim=-1))
print(native_softmax(A))
限制
回到之前的优化思路和方案,我们希望把“gemm、point-wise的softmax、gemm”这三个算子进行融合,这就需要利用tiling对矩阵进行分块操作。
然而,softmax和tiling策略其实是冲突的。这是因为softmax不具备加法结合律,其计算公式的分母部分需要计算全局元素的求和,即需要获取到完整的输入数据之后,得到全局的max和sum结果才能对每一个元素进行计算。而分块之后只能计算局部的和,导致softmax的分块计算变得复杂。
具体到注意力操作,就是:softmax操作是row-wise的。对于完整的\(QK^T\)结果矩阵,softmax需要沿着Inner Loop维度进行归一化。即单独计算每一行的整行的max/sum。本地算出一块\(QK^T\)的结果还不能立刻和V进行运算,还要等同一行的后面的\(QK^T\)都算完才能开始,这就造成依赖关系,影响计算的并行。所以融合softmax就对第一个gemm的块切分加上了限制,要么行方向不切,减少并行度,要么做类似k-slicing,增加通信成本。同理,如果想把这三个融合到一个kernel,不改变softmax计算的前提下,总是要在这两种方法中取一个平衡。
对注意力进行分块计算的真正难点在于对 softmax 的分块计算。为了克服这个限制,我们需要找到一种聪明的方式来计算Softmax,做到不依赖整行结果来计算softmax。即在不访问整个输入的情况下计算 softmax(在注意力机制中就是注意力分数S),以确保softmax保持结合性。这样即融合softmax,但是也还是能做tiling。
FlashAttention想解决的核心问题,正是如何将算法本身从这个全局的依赖中解耦,从而可以使用Tiling进行快速的片上计算。FlashAttention之所以可以省显存(显存开销随Seq length线性增加),是因为解开了softmax以及后面GEMM的行方向依赖,并且通过辅助数组保存的辅助信息re-scale到正确的数值。
因此我们接下来就要研究分块后如何正确得到分数,如何正确得到softmax,如何正确得到O,如何优化IO,从而解决memory-bound问题。
3.2 历程
从原生softmax发展到FlashAttention需要经历以下几个主要步骤,,其中最主要的研究节点有两个:
- NVIDIA 2018' Online normalizer calculation for softmax. 这篇文章首次提出了Online Softmax技巧,通过等价变换使得Softmax没有了行方向依赖,可以Tiling并行计算。
- Google Research Rabe, MarkusN., and Charles Staats. Self-Attention Does Not Need \(O(N^2)\) Memory. 更进一步将算法从Softmax Tiling扩展到Fused Attention Tiling,并且在TPU & JAX上实现了Fused Attention without O(N^2) Memory。
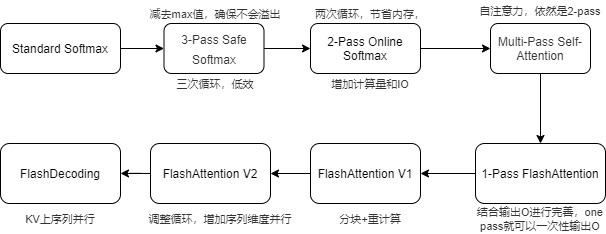
接下来,本文将从online-softmax开始,逐步讲解FlashAttention算法。
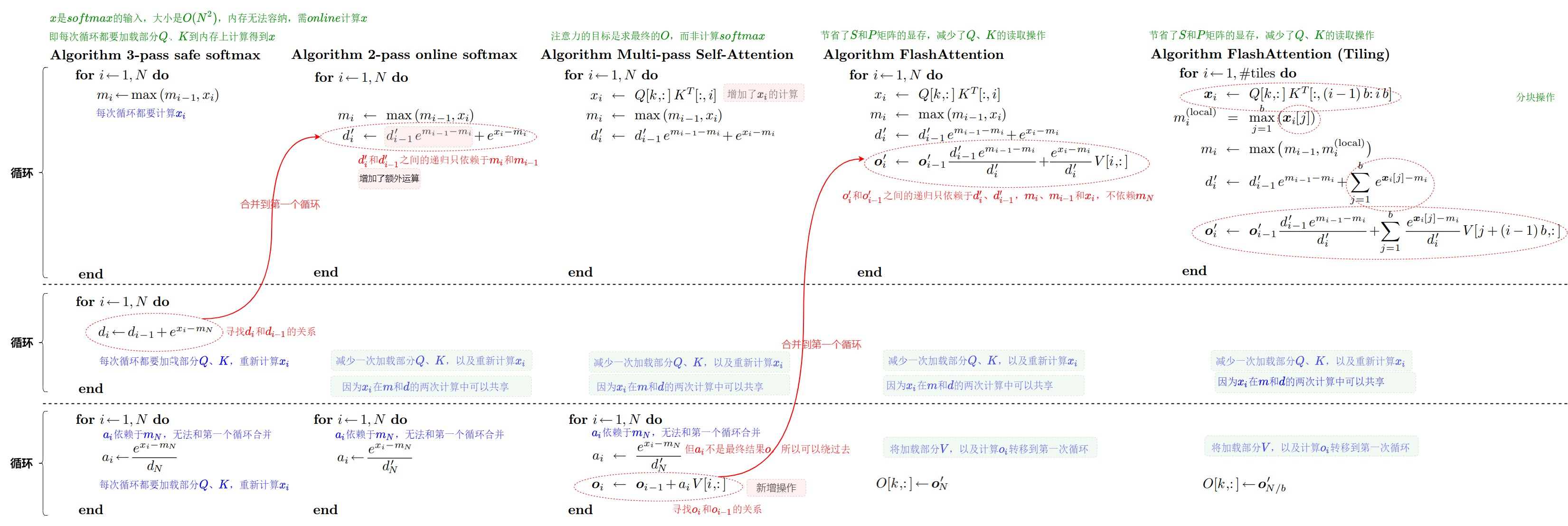
3.3 3-Pass Safe Softmax
当前问题
在实际的计算中,指数计算exp的不稳定性会导致softmax可能出现问题。比如因为浮点数表示的范围有限,所以对于float32和bfloat16来说,当 x≥89 时,\(e^x\) 就会变成inf,发生数据上溢的问题;又比如当数组中每个元素都是较大负值时,每个\(e^{x_i}\)都可能下溢导致整个分母为0,进而导致softmax出错。
解决方案
人们实际使用safe softmax算法,即基于softmax的“平移不变性”,把每个元素减去所有元素最大值之后,再做softmax操作,具体公式如下:
该算法需要对数组执行三次循环,分别为:
- 对每行求最大值。首先需要遍历一遍数组,求最大值max。
- 计算指数并求和得到归一化项\(d_V\)。再遍历一遍数组,将每个元素减去最大值后,再计算指数,这个过程是逐元素操作。
- 计算 softmax 输出。最后遍历一次数组,求每个元素减去max之后的指数,再除以\(d_V\),即对每个元素做缩放之后得到softmax的值。
safe softmax的算法伪代码如下所示,上面三次循环之间存在数据依赖。第二次迭代依赖\(m_V\),第三次迭代依赖\(m_V\)和\(d_V\)。

实现
import torch
A = torch.tensor([1., 2., 3., 5., 4.])def safe_softmax(x):m = torch.max(x) # 计算每行的最大值A = x - m # 每行元素都需要减去对应的最大值,否则求exp(x)会溢出,导致inf情况A_exp = torch.exp(A) # 计算e的指数次幂A_sum = torch.sum(A_exp)return A_exp / A_sum #广播print(torch.softmax(A,dim=-1))
print(safe_softmax(A))
存在缺陷
safe softmax和原始softmax相比,增加了一次循环。结合Transformer的注意力机制的背景下来看,softmax的输入是由\(QK^T\)计算的pre-softmax logits。这意味着,我们需要对输入实施下面两种方案之一:
- 提前计算好pre-softmax logits,并且保存在全局显存中,显存需求为\(O(N^2)\)。
- 在算法中进行online计算,每次循环中加载一部分Q,K到片上内存,计算得到pre-softmax logits。
目前Attention优化的目标就是避开第一种情况,尽可能节省显存,因为没有足够大的SRAM来保存pre-softmax logits。而Attention优化的结果就是第二种情况。但是如果考虑safe softmax的情况,就需要访问Q和K三次,并实时重新计算x,整个计算过程的开销三次读取和一次存储操作,对于访存IO来说,这样是非常低效的。这样虽然不需要保存中间矩阵pre-softmax logits,节省了显存,但是计算没有节省,并且增加了HBM IO Accesses(需要不断地load Q, K)。
3.4 online softmax 2-pass
动机
我们拿出"From Online Softmax to FlashAttention"中的图例作为对照。从下面的代码可以看出,softmax 函数需要三个循环,第一个循环计算数组的最大值,第二个循环计算 softmax 的分母,第三个循环计算 softmax 输出。

上面 3-pass算法的问题主要是太慢,我们期望能够对它加速。比如减少一次访存?减少一次循环?比如能不能将上图中的公式(3),(7)和(10)fuse成一个计算呢?从而可以将对全局内存的访问从3次减少为一次。不幸的是,我们不能对(7)和(10)公式直接做融合,因为公式(10)依赖于 \(m_V\) ,这个值必须等(7)这一次循环跑完才能获得,即不得不通过两轮遍历完成计算的根因在于一个冗余的依赖: \(m_V\)。所以我们需要一个把前两个迭代合并的途径。这就是下面的2-pass算法。
算法
在safe softmax中,Softmax需要拿到每一行的max/sum。所以一般来说,我们需要等某一行的数据全部就绪之后,才进行Softmax操作。而向量的最大值\(m\)的计算是在一个单独的for循环中,求和则是在另外一个单独循环中。那能不能做分块(tiling)累积呢?即,不是一次性算出max/sum,而是每次保存当前的max/sum,再逐步累积更新,最后也可以得到同样结果。这样就通过迭代可以同时找到M和D,将前两次循环减少到一次循环。
online safe softmax中就是通过两次循环完成了任务。其中第二个循环和3-pass相同,所以不再赘述,重点看第一个循环。在第一个循环中会通过一次遍历输入向量,同时计算最大值 𝑚 和归一化项𝑑。具体而言,算法针对输入\([x_1, x_2, ..., x_V]\),在 for 循环的第 j 步, \(m_j\) 为子数组 \(x_{1:j}\) 的最大值, \(d_j\) 为对子数组 \(x_{1:j}\) 计算 softmax 时的分母。当 for 循环结束以后, \(m_V\) 为整个数组的最大值, \(d_V\) 为对整个数组计算 softmax 时的分母。
online safe softmax将 Softmax 函数计算的内存访问次数从每个向量元素的 4 次减少到 3 次。

算法 3 的 pytorch + python 实现如下所示:
def online_softmax(x: torch.Tensor) -> torch.tensor:"""Iterative calculation and 2.5x faster than native softmax """row_cont, col_count = x.shapeassert x.ndim == 2, f"only accepts 2D tensor now"output = torch.zeros_like(x)for r in range(row_cont):row_max = x[r][0]normalizer = 0for c in range(1, col_count):pre_max = row_maxcur = x[r][c]row_max = max(pre_max, cur)# if cur > pre_max:# print(f"Update row max now is {row_max}, row = {r}")normalizer = normalizer * torch.exp(pre_max - row_max) + torch.exp(cur - row_max)output[r, :] = torch.exp(x[r, :] - row_max) / normalizerreturn output
分析
2-pass算法的本质上就是把 softmax 分母的计算做了一个优化,让它不依赖全局的最大值 \(m_N\),而是依赖局部的最大值 \(m_i\),这样就把前两个步骤合并成了一个。或者说,为了移除对N的依赖,我们创建另一个序列作为原始序列的替代。即找到一个等比数列(递归形式),去除N的依赖。这个递归形式只依赖于$m_j $和 \(m_{j-1}\),我们可以在同一个循环中同时计算$ m_j $和 \(d_j\)。
具体而言,2-pass算法在遍历输入数组元素的过程中,会持续更新最大值 𝑚 和归一化项 𝑑。在每次迭代时,算法基于新的最大值 \(𝑚_𝑗\) 更新归一化项 𝑑,之后再将新值加入归一化项中。2-pass算法最大值 m 的更新和3-pass safe softmax相同,计算\(m_k\)时,只用到了\(m_{k-1}\)和\(x_k\),没有用到位置大于k的元素。因此分块求最大值的思路比较好理解。但是 softmax 分母的更新却稍有区别。
- 3-pass safe softmax算法在计算\(d_j\)时用到了\(m_V\),即所有元素最大值。这是因为我们已经通过第一个循环拿到了整个数组 \(x_{1:V}\) 的最大值,因此在第二个循环中可以直接计算 d。
- 在online safe softmax中,\(m\)的计算是迭代进行的,因此得到的\(m\)不是一个向量中最大的值,而是迭代过程中的局部极大值。即当进行到 for 循环的第 j(1≤j<V) 步时,我们手头只有子数组 \(x_{1:j}\) 的最大值。此时计算得到的 d 并不等于$ d_v $。为了一直维护正确的 d ,我们需要同步地对 $d_j \(进行更新。相应的对softmax的分母\)d\(的计算也要加一个补偿项\)e^{m_{j-1}-m_j}$。这样得出的结果与直接使用safe softmax是一致的。
因此online safe softmax中最重要的是如何用一个递归公式生成分母\(d_V\),即让\(d_i\)和\(d_{i-1}\)之间存在一个不依赖于\(m_V\)的递归关系,这时也只需要用到截至到位置k的元素,就可以融合成一轮遍历了。我们接下来看看如何推导。
- 首先,d的计算原理是利用了指数运算规则:同底的两个指数相乘等于两个指数幂的相加,除法同理。
- 其次,d的推导规程如下。
- \(d_{j−1}\)表示数组x[1....n]的前j-1个指数和,它不是基于全局最大值来计算,而是基于\(m_{j-1}\)和\(m_j\)来计算的。
- \(m_{j−1}\)是前j-1个元素的最大值,\(m_j\)表示前j个元素的最大值。\(m_j\)跟\(m_{j−1}\)的区别在于,它有可能等于\(m_{j−1}\),也有可能是最新的第j个元素\(x_j\)。
- 下图蓝框的部分就是表示前S-1项之和\(d_{S−1}\),从公式可以看出,里面每个元素都减去了前S-1个元素的最大值\(m_{s−1}\),因此根据前面讲到的指数运算定律:同底的两个指数相乘等于两个指数幂的相加, 通过跟左边的指数相乘,自动将前S-1项的指数和更新到了最新的\(m_S\)上,进一步更新当前的\(d_S\),
- 这样一次遍历就可以得到数组x[1....n]的前n项指数和,和最大值max,后面的计算步骤就跟safe softmax保持一致了。
具体证明参见下图。

另外,m 和 𝑑 的迭代计算操作同时满足交换律和结合律,任意分块分别计算 m 和 𝑑 之后,将所有子块结果重新聚合在数学上完全等价,即序列中 max 值带来的影响可以延迟到最后一步再被修正。这样就可以分块(乱序执行)计算归一化常数,这个方法可以发挥 GPU 多线程的特性。

实现
简单实现的代码如下。
import torch
A = torch.tensor([1., 2., 3., 5., 4.])def online_softmax(x):m = torch.tensor(-1000.0)d = 0N = len(x)a = torch.zeros(N)for i in range(N):m_pre = mm = torch.max(m, x[i])d = d * (m_pre - m).exp() + (x[i] - m).exp()for i in range(N):a[i] = (x[i] - m).exp() / dreturn aprint(torch.softmax(A,dim=-1))
print(online_softmax(A))
存在缺陷
那么,2-pass算法对比3-pass算法到底有啥优势呢?
相对于3-pass算法,2-pass算法可以在第一个循环中同时对最大值 m 以及 softmax 的分母 d 进行更新,从而减少了一个循环,也减少一次整体加载 Q, K。而且,也可以减少一次对 \(x_i\) 的online recompute,因为在2-pass的第一个pass中, $x_i $是被两次计算共享的。所以最终我们可以借助 GPU 的 share memory 来存储中间结果,这样就只需要与 global memory 通信两次,一次写入数据,一次读取结果。
但是,2-pass算法的FLOPs计算量并没有减少,甚至还略有增加,因为现在每次都需要计算额外的scale,也就是 \(d_{j-1}e^{m_{i-1} - m_i}\) 。因此,我们还需要继续优化。
3.5 Multi-pass Self-Attention
从这一小节开始,我们将进入到FlashAttention部分。
动机
让我们顺着2-pass online softmax继续思考。既然我们可以得到2-pass,那么我们是否可以更进一步得到一个1-pass online softmax算法呢?遗憾的是,我们无法做到。因为第二步的计算仍然需要依赖第一步计算的分母 \(d_V\),所以还是需要两步计算s。
然而,注意力的目标是计算\(O=softmax(QK^T)V\),而非softmax。虽然无法做到1-pass online softmax,但是可以做到1-pass注意力算法。即,虽然\(P = softmax(QK^T)\)这一步只能压缩成两个for循环,但如果把O=PV的计算考虑进来,就可以进一步把\(O=softmax(QK^T)V\)压缩成一个for循环,即找到 O 的一次递归形式。让我们看看其可行性。
Multi-pass Self-Attention算法
我们先看一下Multi-pass Self-Attention的算法。这是一个在2-pass online softmax基础上的2-pass FlashAttention算法。
在算法的第一个循环,使用了2-pass online-softmax中推导得到的公式,第一个循环实际上和 2-pass online softmax一样,只是增加了对\(x_i\)的计算。
算法的第二个循环步骤如下:
- 计算得到了注意力权重\(\alpha _i\)和当前迭代步得到的\(o_i\)。因为O依赖\(m_N\),所以无法合并到第一个循环中,必须等到第一个循环结束得到\(m_N\)。
- 和2-pass相比,第二个循环多了\(o_i \leftarrow o_{i-1} + \alpha_i V[i,:]\),即每遍历一个分块, \(O\) 就更新一次。
具体参见下图。

引入到FlashAttention
既然 \(O_i\) 每遍历一块就更新一次,而\(o_i \leftarrow o_{i-1} + \alpha_i V[i,:]\)和2-pass的\(d_i \rightarrow d_{i-1} + e^{x_i - m_N}\)似乎有相同的范式,因此我们要看看是否可以像2-pass那样找到一个递归关系(\(O_i\) = \(O_i\) + 当前最新结果),等到遍历完最后一块,这时的\(O_i\) 就和标准场景下的结果完全一致,也就可以融合了。
我们接下来就看看是否可以像2-pass online softmax那样,找到\(o_i\)和\(o_{i-1}\)之间不依赖于\(m_N\)的递归关系。具体而言,就是把上图中的标号2用标号1来拓展。然后再转换为递归形式,具体如下图所示。

可以看到,\(o_i^\prime\)和\(o_{i-1}^\prime\)之间的递归只依赖于 \(d_i^\prime\)、\(d_{i-1}^\prime\),\(m_{i}\)、\(m_{i-1}\)和\(x_i\),不依赖\(m_N\),即,\(𝑂_𝑖\) 的计算也是可以同时满足交换律和结合律,任意分块分别计算 𝑀、𝐷 和 𝑂之后,将所有子块结果重新聚合在数学上完全等价,,从而实现在一个 𝑖=(0,𝑁) 的循环中计算\(m_i\)、\(d_i\)和 \(o_i\)。因此我们可以把第二个循环的计算合并到第一个循环中,得到1-pass FlashAttention算法。
3.6 1-pass FlashAttention
最后得到 1-pass FlashAttention算法如下图所示。Online Softmax 实现在一个 for 循环中计算 \(m_i\)和 \(d_i\),FlashAttention-v1 基于它的思想更进一步,实现在一个 for 循环中计算 \(m_i\)、\(d_i\) 和注意力输出 \(o_i\),也就是说,在一个 kernel 中实现 attention 的所有操作。由3-pass的原始Self Attention到1-pass 的FlashAttention,节省了S和P矩阵的显存,并且减少了Q,K的HBM IO Accesses。
我们再强调下 Flash Attention 能做到 one-pass 计算的原因:Flash Attention 让 Attention 的所有计算都符合加法结合律。虽然单独的 softmax 运算不能做到 one-pass,但是 self-Attention 中的 softmax 求完之后,它的每一项的值会与 V 中向量相乘,然后累加。这里的累加很关键,有了这个累加的操作,所有的计算又符合结合律了。这样就可以充分利用 GPU 的并行优势。
FlashAttention最核心的部分是构造出一个递归(等比数列),让部分结果可以累计到全局,这样就不用一下子加载所有值并分步计算了。

3.7 Algorithm FlashAttention (Tiling)
在上述 tiling 形式的 softmax 中,我们的每一步只更新一个元素,而在实际使用中,Flash Attention 会将输入分为多个块,每个块包含多个元素。所以,我们进一步对矩阵Q, K进行Tiling,就可以得到分块Tiling版本的FlashAttention。首先,将Q, K, V进行分块,然后把各个小的分块从性能低的全局显存加载到速度快的SRAM,在SRAM上完成当前分块的注意力计算,最后再写入HBM,整个过程,不需要保存中间矩阵S和P,从而大大减少了 HBM 访问次数(内存读/写的次数)。然后FlashAttention会分别计算这些块的注意力输出,最后,将每个块的输出按正确的归一化因子缩放之后相加后可得到精确的注意力输出。

3.8 小结
我们通过下图来看看主要版本之间的优化过程。
0x04 FlashAttention V1
知道了softmax改进的可行性,我们来看看FlashAttention的优化思路。
4.1 总体思路
前面提到过,标准注意力算法在GPU内存分级存储的架构下存在两个缺陷:显存占用多和HBM读写次数多。具体来说就是在标准注意力计算过程中产生的S和P这两个中间矩阵过大,造成了多次读写HBM的操作。
FlashAttention的主要优化思路是:减少大尺寸的中间矩阵在 HBM 和 SRAM 之间的换入换出,即通过利用更高速的上层存储计算单元,减少对低速更下层存储器的访问次数,来提升模型的训练性能。可以说,FlashAttention主要是从GPU block/thread并行度的视角对访存进行了优化,而非节约FLOPs。
为此 FlashAttention 提出了两种方法来分布解决上述问题:tiling 和 recomputation。本质是对矩阵连乘问题进行定制化的的Tiling+重计算。
- Tiling(分割输入,在前向传播和后向传播时使用)。将输入的Q、K和V进行分块,然后把小块从HBM加载到SRAM中。然后按块去计算注意力。在将每个块的输出相加之前,将其按正确的归一化因子进行缩放,从而得到正确的结果。最后再写入HBM,整个过程不需要保存中间矩阵S和P。
- recomputation(重计算,仅在后向传播时使用)。在反向传播过程中不保留整个注意力权重矩阵,而是只保留前向过程中的某些中间变量(比如归一化因子),然后在反向传播过程中重新计算注意力权重矩阵。重计算虽然导致FLOPS增加,但是由于目前GPU的计算效率要高于显存访问,大量减少HBM访问也可以使FlashAttention的运行速度更快。
接下来我们主要针对前向传播进行分析。
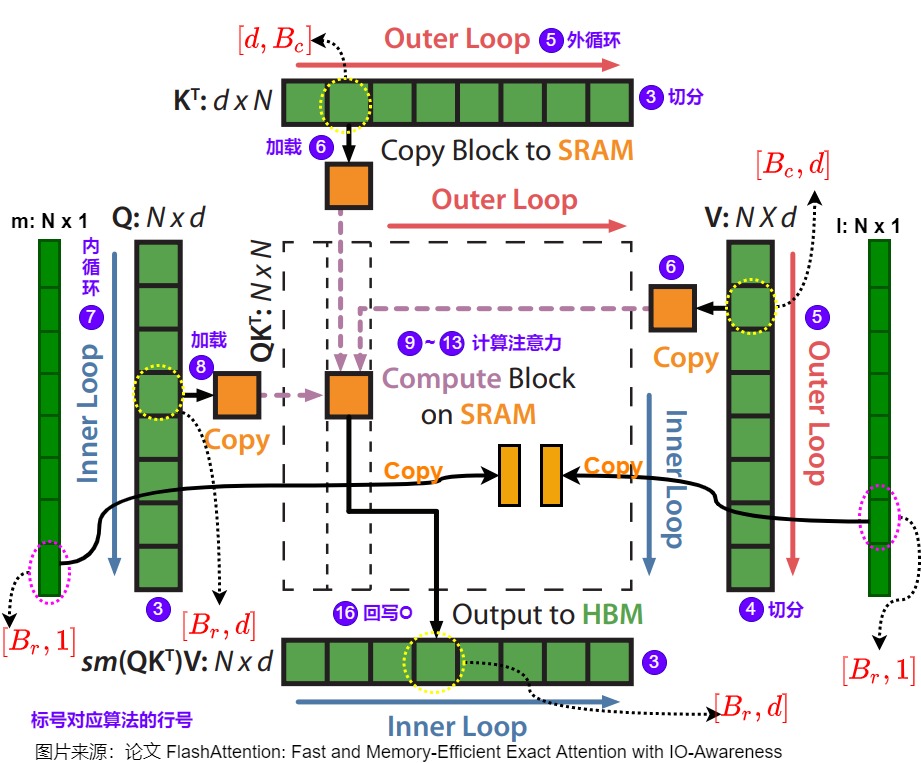
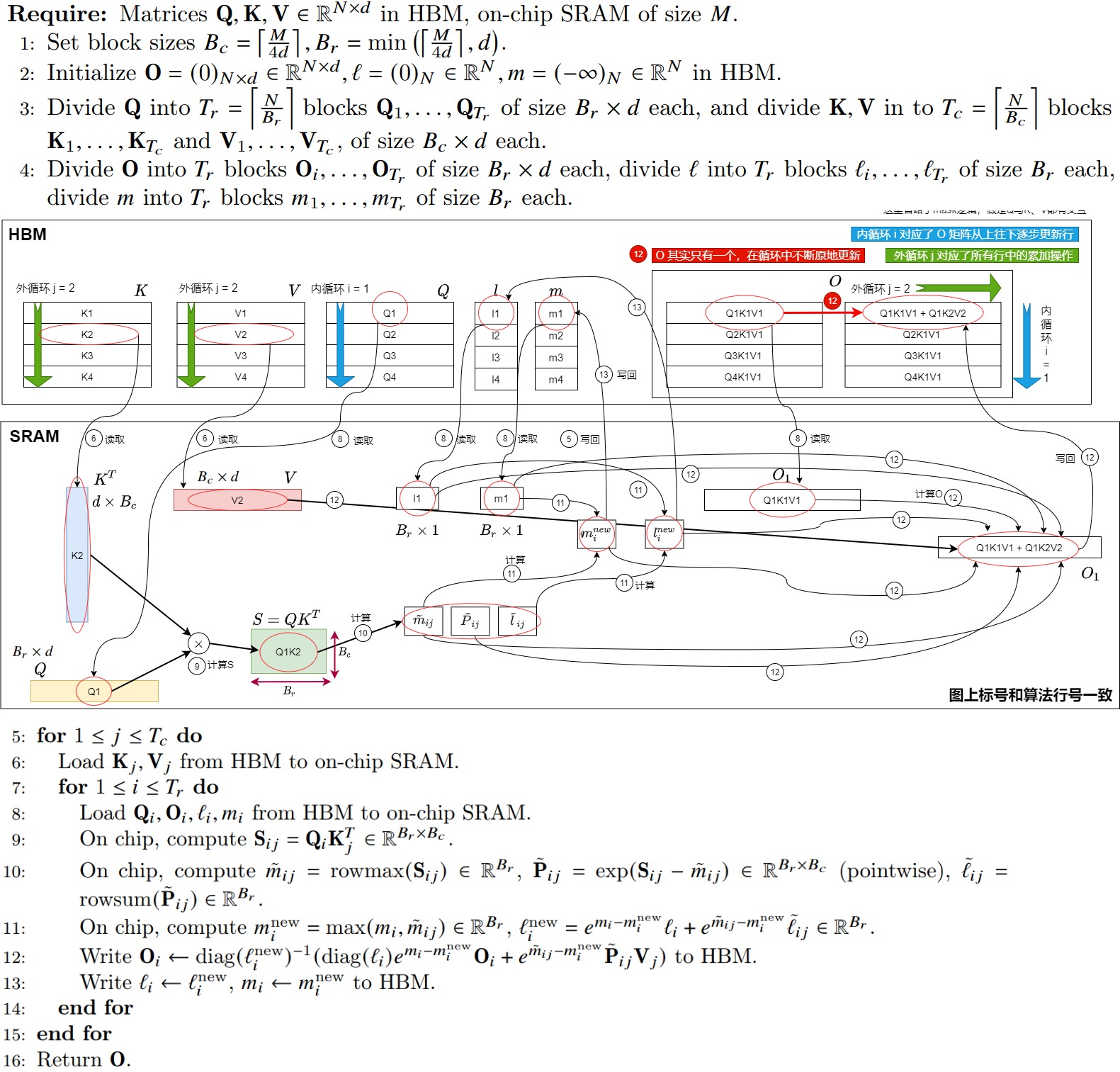
4.2 算法
在注意力计算过程中,节省显存或者说分块计算的主要挑战是:softmax与 K,V 的列是耦合的,在注意力计算中,softmax需要将所有的列耦合在一起计算。因此需要在不访问整个输入的情况下计算 softmax。FlashAttention就是解开了softmax以及后面GEMM的行方向依赖,并且通过辅助数组保存的辅助信息re-scale到正确的数值。

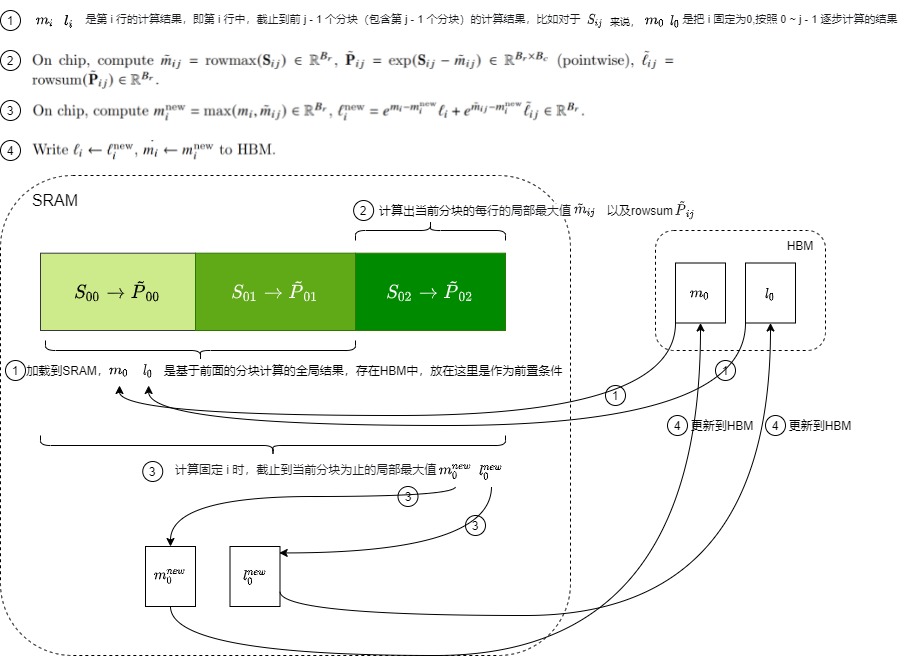
上图算法流程是FlashAttention V1的前向传播实现。首先要对算法中的一些变量做下说明:
- 所有以 ij 作为下标的,都表示当前分块的计算结果。
- 所有以 i 作为下标的,都表示截止到前一个分块(包含前一个分块)的计算结果。
- 所有以 new 为上标的,都表示引入当前分块做更新后的结果。
- 所有没有下标的,都表示全局结果。
- S表示attention矩阵未softmax前的值,\(S_{ij}\)表示Q的第i块和K的第j块相乘得到的矩阵。
- 把S矩阵每行最大值记作rowmax,每行求和值记作rowsum。\(\tilde P\) , \(P\) 分别表示做归一化前和做归一化后的结果。即,\(\tilde P\) 表示(s-rowmax),\(P\)表示(s-rowmax)/rowsum的结果。
然后,我们再逐步的看一下计算过程,下面标号和图中行号一一对应。
- 首先根据SRAM的大小,计算出合适的分块大小;
- 将\(O,l,m\)在HBM中初始化为对应shape的全0的矩阵或向量。\(l,m\)是引入的两个统计量,通过这两个统计量就可以对softmax进行解耦,实现分块计算;
- 将\(Q,K,V\)按照分块block的大小切分成许多个块,这样就可以把全局softmax计算也相应分割成多个不同的块来分别计算局部softmax值。
- \(O,l,m\)也切分成对应数量的块;
- 执行外层循环,基于递推实现块粒度的softmax计算;
- 在外层循环中会将分块的\(K_j,V_j\)从HBM中加载到SRAM中;
- 执行内层循环;
- 将\(Q_i,O_i,l_i,m_i\)从HBM中load到SRAM中,然后分块计算上面流程的中间值,在每个内层循环里面都将\(O_i,l_i,m_i\)写回到HBM中,因此与HBM的IO操作还是相对较多的。
- 在on-chip SRAM上进行\(softmax(QK^T)\)计算。
- 由于我们将\(Q,K,V\)都进行了分块计算,而\(softmax\)却是针对整个向量执行计算的,因此在上图的第10、11、12步中使用了safe online softmax技术。这里具体会做如下操作:通过迭代更新两个统计量 m(x), l(x) ;利用m(x)、当前块softmax的分子与l(x)更新全局的softmax的分子和分母;当所有计算完毕,softmax的全局的分子分母也计算完毕,即可求得最终的输出值O。
4.3 证明
我们接下来证明算法的有效性。
定义
相关定义如下:
-
\(x=[x_1,x_2,...,x_d]\):S 矩阵某一行的向量。因为分块的原因,它被我们切成了两部分 \(x=[x^{(1)},x^{(2)}]\) 。
-
\(m(x)\) ,标准场景下,该行的全局最大值。
-
\(m(x^{(1)})\) 分块1的全局最大值。
-
\(m(x^{(2)})\) 分块2的全局最大值。
-
\(f(x)\):标准场景下, \(exp(x-m(x))\) 的结果。
-
\(f(x^{(1)})\):分块场景下, \(exp(x^{(1)}-m(x^{(1)}))\) 的结果,是softmax的分子部分。
-
\(f(x^{(2)})\):分块场景下, \(exp(x^{(2)}-m(x^{(2)}))\) 的结果。
-
\(l(x)\):标准场景下, $rowsum[f(x)] $的结果。
-
\(l(x^{(1)})\):分块场景下, $rowsum[f(x^{(1)})] $的结果,是softmax的分母部分。
-
\(l(x^{(2)})\):分块场景下, $rowsum[f(x^{(2)})] \(的结果。其中\)l(x^{(i)})$表示的并不是对 i 求和,而是表示对 \(x^{(i)}\)这个向量中所有的元素求和。
l 和 m 都是标量,而\(x^{(1)}\)中 i 的一次数值变化,表示一个数据块的变化,数据块表示的可以是向量,也可以是矩阵。
推导
常规softmax
先考虑常规的softmax如何分块计算。即没有减去最大值的非safe版本,就是native版本。
一次性输入,一次迭代
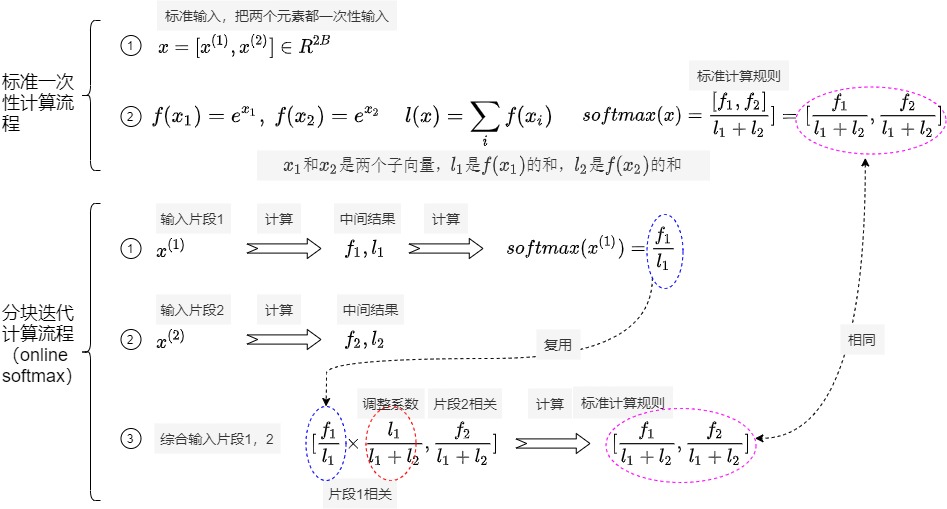
如果一次性输入$$x=[x^{(1)}, x^{(2)}] \in R^{2B}$$,即x只包含两个元素,则计算softmax就如下图的标准一次性计算流程那样简单。
online-softmax
如果输入序列长度太大,则softmax计算所需要的内存会很大,不可能一并存入 SRAM 中进行计算,只能进行分块。分块难点在于softmax分母l(x)项依赖于输入向量x中的每一个值。于是我们看看如何用online-softmax来进行多块累加处理。
论文中切片后softmax 的计算方式如下。即对于向量 \(x^{(1)}, x^{(2)} \in R^B\),可以把拼接向量 \(x=[x^{(1)}, x^{(2)} ]\in R^{2B}\) 的softmax计算分解为两个向量 $x^{(1)}, x^{(2)} $的计算,然后再拼凑起来。
假设\(f_i = f(x^{(i)})\),\(l_i = l(x^{(i)})\),则有如下:
\(x_1\)和\(x_2\)是两个子向量,\(l_1\)是\(f(x_1)\)的和,\(l_2\)是\(f(x_2)\)的和。\(l2\)和\(x_1\)没关系。也就是说,假如我们事先不知道完整的 x,而只有 \(x^{(1)}\),那么可以先计算 \(f_1\) 和 \(l_1\),当 \(x^{(2)}\) 准备好之后,再计算 \(f_2\) 和 \(l_2\),并对之前计算的 \(\frac{f_1}{l_1}\) 进行修正,从而得到最终的\(softmax(x)\)。
推导如下。
safe softmax
我们接下来看看safe softmax如何处理。
一次性输入,一次迭代
为了保证数值稳定性,对于 \(x \in R^B\) ,执行“减去最大值”的safe softmax的计算过程如下,这里的max和sum都需要一行的完整结果。

online-softmax
接下来看看多块累加如何处理,即用online-softmax来处理。此处同样把拼接向量 \(x=[x^{(1)}, x^{(2)} ]\in R^{2B}\) 的softmax计算分解为两个向量 $x^{(1)}, x^{(2)} $的计算,然后再拼凑起来。可以看到,只需维护一个全局的 m(x) ,剩余状态可以根据局部计算的 softmax 中间值进行换算。

我们接下来证明有效性。
计算第一个子向量
假如我们事先不知道完整的 x,而只有 \(x^{(1)}\),那么可以先计算 \(f_1\) 和 \(l_1\)。
使用稳定版softmax计算第一块 \(x^{(1)}\) 的结果,同时记录下第一块的最大值\(m(x^{(1)})\) 和第一块的局部求和结果 \(l(x^{(1)}) = \sum {e^{x^{(1)} - m(x^{(1)})}}\)
此时如果计算softmax,则是
但这只是局部的 softmax,需要等待后续计算完进行更新或者废弃。
更新全局值
设置变量\(m_{max}\) 记录迭代到此的全局最大值,设置变\(l_{all}\) 记录迭代到此的全局EXP求和结果,后续随着迭代计算不同的分块\(x^{(i)}\) 逐步更新\(m_{max}\) 和 $ l_{all}\(。计算完第一块之后\)m_{max} = m(x^{(1)})$ , $ l_{all} = l(x^{(1)})$
如果后续更新,可以保留子向量\(x^{(1)}\)以备后续计算,但是\(x^{(1)}\)很可能很大,所以不如保留两个标量\(m(x^{(1)})\)和\(m(x^{(1)})\)更经济。此外,还需要保留全局标量,当前最大值\(m_{max}\)和全局EXP求和项\(l_{all}\),就是全局 softmax分母项。
计算第二个子向量
当 \(x^{(2)}\) 准备好之后,再计算 \(f_2\) 和第一块的局部求和结果 \(l_2\),
同时记录下第二块的最大值\(m(x^{(2)})\) 和第二块的局部求和结果 \(l(x^{(2)})\)
此时如果计算第二个子向量的softmax,则是
但这也只是局部的 softmax,需要等待后续计算完进行更新或者废弃。
更新全局值
更新迭代到此时的全局最大值\(m_{max}^{new} = max(m_{max}, m(x^{(2)}))。\)
更新迭代到此时的全局求和结果$ l_{all}^{new} = e^{m_{max} - m_{max}^{new}}*l_{all} + e{m(x) - m_{max}{new}}*l(x)\(。\)l\(并不能直接累加更新,因为不同的\)l$不能保证减去了全局最大值。
计算全局softmax
因为\(softmax(x) = \frac{f(x)}{l(x)}\), 现在\(l(x)\)已经被更新,我们接下来看看\(f(x)\)如何更新。
由于最大值发生了变化,因此之前i个block对应的f(x)要进行修正:
- 对于局部\(softmax_1\),之前减去\(m(x^{(1)})\),因此要将它加回来,再减去新的m(x),即\(e^{m({x^{(1)} - m_{max}^{new})}} f(x^{(1)})\)。
- 对于局部\(softmax_2\),之前减去\(m(x^{(2)})\),因此要将它加回来,再减去新的m(x),即\(e^{m({x^{(2)} - m_{max}^{new})}} f(x^{(2)})\)。
因此合并得到:
从而得到最终的\(softmax(x)\)。
总结
上述其实是一个增量计算的过程:
- 我们首先计算一个分块的局部 softmax 值,将其处理完毕便先暂存下来,记录全局最大值,和全局 softmax 分母值。
- 等到下一个分块处理完毕之后,也保持这个局部分块的softmax值;再去新的全局最大值,和全局 softmax 分母值。
- 然后对已有的两个局部 softmax 进行更新操作,对于每个局部\(x_i\),更新其 局部softmax_i 时,需要用到的变量是:\(x_i\)的局部最大值\(m(x^{(i)})\),局部EXP求和项\(l(x^{(i)})\),局部softmax值\(softmax(x^{(i)})\),全局最大值\(m_{max}^{new}\),全局EXP求和项\(l_{all}^{new}\)。
- 假设存在\(x^{(3)}\), 那么便可以将\(x^{(1)}\)和\(x^{(2)}\)合并成一个序列,重复前面步骤即可。
- 由此往复,使得我们始终获得的是不断更新的全局 softmax 值。当处理完所有分块后,此时的所有分块的softmax值都是“全局的”。
具体如下图所示。

代码论证
import numpy as np
import torchdef softmax(x):m_x = np.max(x)f_x = np.exp(x - m_x)l_x = np.sum(f_x)soft_x = f_x / l_xreturn m_x, f_x, l_x, soft_xm_x1, f_x1, l_x1, soft_x1 = softmax(np.array([1, 2]))
m_x2, f_x2, l_x2, soft_x2 = softmax(np.array([3, 4]))
m_x_new = np.max([m_x1, m_x2])
l_new_all = np.exp(m_x1 - m_x_new) * l_x1 + np.exp(m_x2 - m_x_new) * l_x2
soft_x1_new = soft_x1 * l_x1 * np.exp(m_x1 - m_x_new) / l_new_all
soft_x2_new = soft_x2 * l_x2 * np.exp(m_x2 - m_x_new) / l_new_all
soft = torch.nn.functional.softmax(torch.Tensor([1, 2, 3, 4]), dim=0)# [0.0320586 0.08714432] [0.23688282 0.64391426]
print(soft_x1_new, soft_x2_new)
# [0.0320586 0.08714432 0.23688284 0.6439143 ]
print(soft.numpy())
结合O来分析
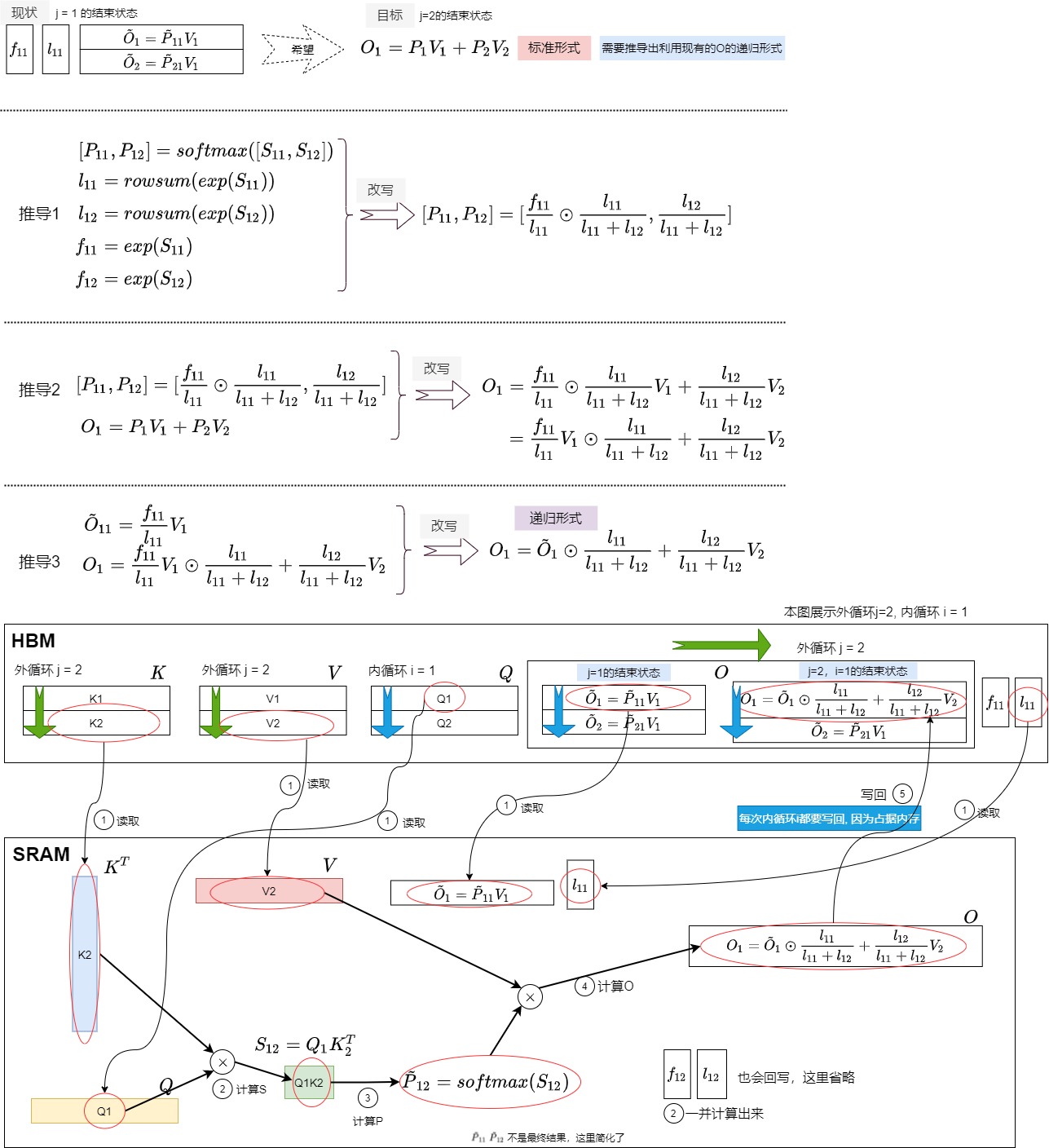
我们再结合输出值O来进行分析。从矩阵角度理解,外循环 j 对应的是O矩阵的列,内循环 i 对应的是 O 矩阵的行在外层loop的第j的循环结束之后,HBM中得到如下:
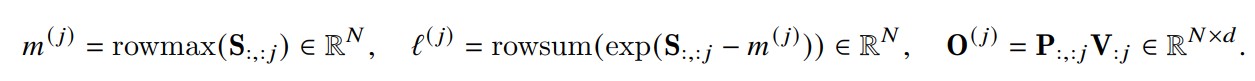
在第j+1的循环中,我们将做如下处理,最终得到输出O。

也可以如下图所示。
4.4 分块
如何切分
我们要结合SRAM大小来看看在算法中的四个矩阵Q, K,V,O如何被分块。四个矩阵都是按行来分块。
- 将Q矩阵切分为\(T_r\)个块(block),每块长度为\(B_r\)。切分完的某个块记作\(Q_i\),其维度是\((B_r, d)\),里面存储着\(B_r\)个token的query信息。
- 将K矩阵切分为\(T_c\)个块(block),每块长度为\(B_c\)。切分完的某个块记作\(K_j\),其维度是\((B_c, d)\),里面存储着\(B_c\)个token的key信息。
- 将V矩阵切分为\(T_c\)个块(block),每块长度为\(B_c\)。切分完的某个块记作\(V_j\),其维度是\((B_c, d)\),里面存储着\(B_c\)个token的value信息。
- 将O切分为\(T_r\)个块(block),每块长度为\(B_r\),其维度是\((B_r, d)\),切分完的某个块分别记作\(O_i\)。对O是按照行方式分块。
另外,还会将l,m切分为\(T_r\)个块(block),每块长度为\(B_r\),其维度是\((B_r, 1)\),切分完的某个块分别记作\(m_i,l_i\)。
分块大小
每次内循环,会读取\(Q_i\),\(K_j\),\(V_j\)到SRAM中,然后计算得出\(O_{i}\)。我们设定分块的尺寸的目的是使得SRAM尽量可以容纳尽量大的子块。因为有四个“矩阵”blocks分别被导入到了on-chip SRAM中,所以在切片的时候(分块的时候)需要除以4d。从而就拿到了每个block的“序列长度”了。其中 M 就是系统可用的SRAM上限,d是维度。M是on-chip SRAM的大小(例如20M)。
- Q和O分块大小是\(B_c = \lceil \frac{M}{4d} \rceil\)
- K和V分块大小是\(B_r = min(\lceil \frac{M}{4d} \rceil, d)\)
这样设置的目的是,为了确保SRAM能够放下所有Q, K, V,O的小块。而4d代表了4和d的乘积,4表示Q, K, V, O四个blocks。另外,除了输入 QKV 和输出 O 外,仅需要存储最大值向量 \(m \in R^N\) 和指数和 \(l \in R^N\) ,它们带来的存储开销为 O(N) ,与这四个块相比可以忽略。
因此得到如下。对于每一个Q的分块\(Q_i\),\(O_i\)以及K, V的分块\(K_i\),\(V_i\)需要的共享内存为M。加上\(l_i\),\(m_i\)所需要的存储,SRAM基本可以完全利用。

当然,这这是算法伪代码上的分析结论。具体工程上的实现还是会有细微的差别,但总体的思路基本一致。
局限性
我们接下来看看维度d对FlashAttention的影响。
FlashAttention中,SRAM的需求量,和Br/Bc以及head_dim(d)有关系,Br和Bc是常量,通常可以选择设置为64或128,而d是可变的。
- 如果head_dim=d越大,则\(B_r\)和\(B_c\)会越小,从而块会变小,则运行耗时越大。
- 小的块意味着,对于相同的seqlen,需要遍历更多的次数,也就是更多的thread block。在相同的occupancy下,需要schedule更多次才能将计算算完,耗时就变高了。
- 由于Br变小,意味着外层Q循环的次数变多了,对于每一次Q的循环,都要分块加载全部的K、V到SRAM,也就是说,Memory Accesses也会增加,这也会导致耗时的增加。
- 如果d越小,则块会变大,增大block的大小通常意味着减少对SRAM的IO操作,但是会增加对寄存器和SRAM的使用量。由于每个thread block的SRAM能放的数据是有限的,这限制了系统中活跃的SM上限。
4.5 流程
我们按照算法来梳理流程。
前置条件
前置条件是
- Q,K,V位于HBM中。
- 已经获取SRAM的大小(假设为M)。
第一步
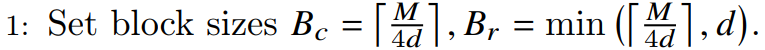
第一步作用是设定分块的尺寸。在SRAM需要存的数据是:Q矩阵的子块,K矩阵的子块,V矩阵的子块,计算过程的中间输出O。于是依据SRAM的大小M和输入向量维度d来设定Q矩阵和O矩阵的子块尺寸是\(B_r\),K、V矩阵子块尺寸是\(B_c\)。向上取整的目的是让有空间冗余,不会丢失数据。
第二步
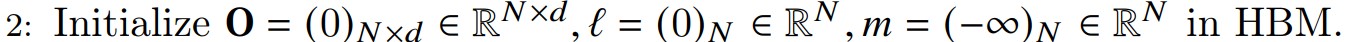
第二步会初始化O,l,m,具体操作是:
- 把HBM上的输出矩阵O初始化为全0。
- 把HBM上的变量l设置为全0,l 将保存softmax的累积分母。
- 把HBM上的变量m设置为-inf,m 用于记录每一行的最大数值。
第三步
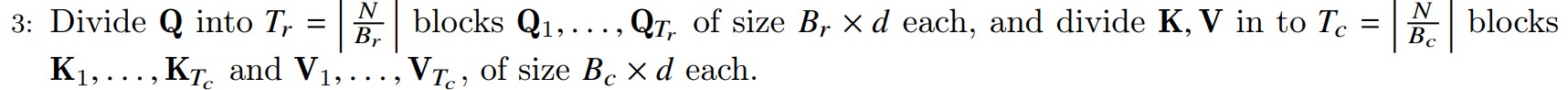
第三步将矩阵进行分块。将Q划分成\(T_r\)个Block,将K、V划分成\(T_c\)个Block,对它们都是按照行方式分块。
-
将Q矩阵切分为\(T_r\)个块(block),每块长度为\(B_r\)。切分完的某个块记作\(Q_i\),其维度是\((B_r, d)\),块里面存储着\(B_r\)个token的query信息。
-
将K矩阵切分为\(T_c\)个块(block),每块长度为\(B_c\)。切分完的某个块记作\(K_j\),其维度是\((B_c, d)\),块里面存储着\(B_c\)个token的key信息。
-
将V矩阵切分为\(T_c\)个块(block),每块长度为\(B_c\)。切分完的某个块记作\(V_j\),其维度是\((B_c, d)\),块里面存储着\(B_c\)个token的value信息。
第四步
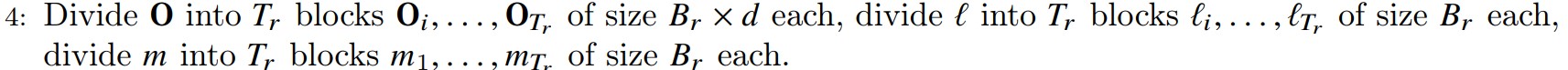
第四步把O,l,m进行分块,即将O,l,m切分为\(T_r\)个块(block),每块长度为\(B_r\),其维度是\((B_r, d)\),切分完的某个块分别记作\(O_i,m_i,l_i\)。对O是按照行方式分块。
循环计算
接下来开始进行循环计算。j 是外循环, i 是内循环,这个意思就是说,对于每个 j ,我们都把所有的 i 遍历一遍,得到相关结果。在论文里,又称为K,V是外循环,Q是内循环。写成代码就是:
# ---------------------
# Tc: K和V的分块数
# Tr: Q和O的分块数量
# ---------------------
for 1 <= j <= Tc:for 1 <= i <= Tr:do....
具体见下图。
第五步
外循环由\(T_C\)控制,会遍历K、V进行跨列循环。
第六步
第六步将从HBM(显存)上读取当前遍历中的 \(K_j\), \(V_j\) 到on-chip存储SRAM。在这个时间点上我们仍然有50%的SRAM未被占用(专用于Q和O)。
第七步
第七步开始跨行内部循环。内循环由\(T_r\)控制,其会遍历Q、O、l、m。
第八步
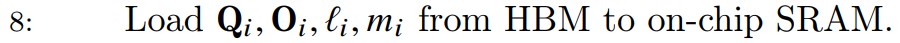
第八步将当前循环中的\(Q_i (B_r \times d)\)和\(O_i (B_r \times d)\)块以及\(l_i (B_r)\)和\(m_i (B_r)\)加载到SRAM中。
循环内计算
接下来会进行循环内计算,我们先概述内外循环的工作,
- 外循环:把K和V的子块从HBM加载进SRAM。
- 内循环:把Q,O,l,m的子块从HBM加载进SRAM,然后在SRAM上完成注意力S计算。
- 首先,根据上一步计算的子块\(S_{ij}\),来计算当前块的行最大值\(m_{ij}\),当前块\(P_{ij}\)(即softmax的分子),\(l_{ij}\)为\(P_{ij}\)的累积值。
- 其次,计算子块与子块间的最大值\(m^{new}\)和多个子块的\(P_{ij}\)的累积值\(l^{new}\)。
- 最后,依据前面提到的softmax算法计算出\(O_i\);将最后的\(l^{new}\)赋值给\(l_i\),\(m^{new}\)赋值到\(m_i\)。并且将这些变量从SRAM回写到HBM。
论文的图完美解释了这个循环过程。我们在下图上也做了算法标注。这里要注意的是,\(O_i\), \(l_i\), \(m_i\)其中存储的可能是上一个循环计算的中间结果。
第九步
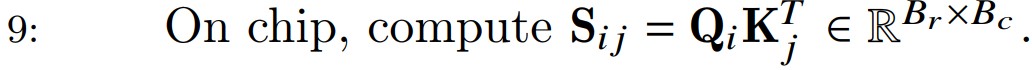
第九步对于每一对分块($$Q_i ,K^T_j$$)来计算它们的点积,就是这两个块之间的相关性分数。
\(S_{ij}\) 表示前 \(B_r\) 个token和前 \(B_c\) 个token间的原始相关性分数。\(S_{ij}\)的形状变化是\(S_{ij} = Q_i * K^T_j = (B_r,d) * (d, B_c) = (B_r, B_c)\),
第十步

使用上一步计算的分数继续操作,即基于当前分块 \(S_{ij}\)计算每个分块的中间状态 $ \tilde {m}{ij}\(,\)\tilde{P}\(,\)\tilde {l}_{ij}$ 。
-
$ \tilde {m}{ij}$ 是找到上面每一行的最大元素,即当前分块\(S_{ij}\)的每行的局部最大值。对应了 \(m(x^{(1)})\) 或者 \(m(x^{(2)})\)。 对应 \(m(x^{(1)})\) 是分块1的全局最大值,\(m(x^{(2)})\) 是分块2的全局最大值。$ \tilde {m}$ 可能不是S的第i行的最大值。
-
\(\tilde{P}_{ij}\) 是取行最大值并从行分数中减去它,然后EXP操作,即分块场景下,各块的P矩阵(归一化前)结果。注意,这里还没有除以softmax公式里面的分母。对应了\(f(x^{(1)})\)或者\(f(x^{(2)})\)。
第十一步

在计算完每个分块后,实时更新这些中间状态,以确保全局结果是正确的,具体为:
- \(m_i\) 如果当前分块是 \(S_{ij}\) ,则 \(m_i\) 表示固定 i 时,前 j−1 个分块中的局部最大值。当固定 i ,遍历完 j 后, \(m_i\) 的结果就是全局最大值了。
- \(m^{new}_i\) 是固定 i 时,即维护截止到当前分块为止的局部最大值。
- \(m^{new}_i\) 和 \(l^{new}_i\) 是遍历完最新的 \(S_{ij}\) 后得到的rowmax和rowsum结果,所以每遍历完一块 \(S_{ij}\) ,我们就执行伪代码的第13行,做一次更新。
- \(l_i\) 和 \(m_i\) 同理,即当我们将 j 遍历完后,我们就能得到针对 i 的全局rowmax和全局rowsum。
- \(\tilde {l}_{ij}\) 是矩阵P的逐行和,是分块场景下,rowsum的结果。相当于\(l(x^{(1)})\)或者\(l(x^{(2 )})\)
注意,此时还不会用计算出的\(m_i^{new}\)和\(l_i^{new}\)来更新旧的\(m_i\)和\(l_i\)。
第十二步
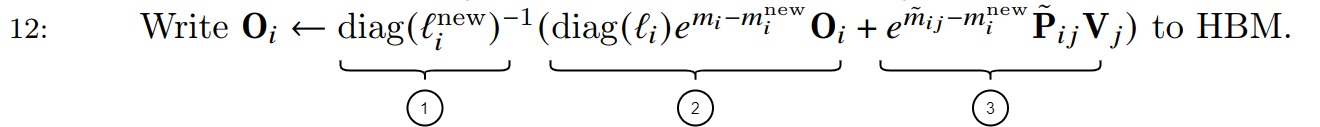
第12步伪代码说明如下:
- \(l_i\)是每一行的\(P_{ij}\)构成的向量。P表示当前块内部的未激活的注意力矩阵。
- 标号1实现了softmax的分母。标号1作为整体和其右面括号一起操作,就可以理解为对右侧括号内的值全部除以\(l^{(new)}\),借此抵消之前迭代中除以的相同常数(这个常数隐藏在\(O_i\)中)。\(diag(l_i)\)是对向量l进行操作来得到一个对角矩阵,该矩阵每一行只有对角线位置一个元素(\(p_{ij}\)),这样可以实现相同长度的两个向量进行element-wise相乘。-1是求对角矩阵的逆(对角矩阵的对角值的倒数),刚好就是softmax的分母。
- 标号2是目前为止“累计”计算出来的\(O_i\)。其作用是更新了之前块的局部softmax数值。
- 标号3是本次按照\(Q_j\)和\(K_i\) \(V_i\)计算出来的\(O_{ij}\)。
- 标号2和标号3的系数\(e^x\)项用来修改矩阵\(\tilde P_{ij}V_j\)和\(O_i\),具体方法是消去前一次迭代中的\(m_i\),并用最新的估计\(m^{new}_i\)来更新它,\(m^{new}_i\)包含到目前为止逐行最大值。相当于说,undo原来的分别的softmax。即分别再乘以原本的老的softmax的时候的分母,从而和本次的新的softmax的分母实现“颗粒度对齐”!
- 标号2和标号3加权求和与标号1相乘就得到了新的\(O_i\)。另外由于最终的 \(O_i\) 只会存在一个值,因此在所有块计算完成后,\(O_i\) 的输出值就是准确的。
这一步其实就是下面公式的伪代码实现。
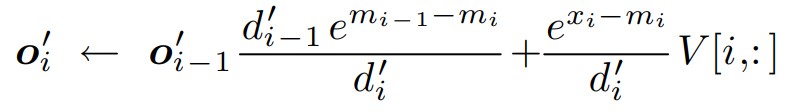
是把标准的计算O公式展开为递归形式。
因为我们是对Q,K,V进行分块计算,每个\(O_i\)只是部分输出,需要把所有分块的输出合并起来,才能得到最终输出O,这就是对所有\(O_i\)的累加操作。展开为递归形式之后,每遍历一个分块,就更新一次 \(O_i\) ,也就是在上一个 \(O_i\) 的基础上,引入当前分块的信息做更新。\(O_i\) = \(O_i\) + 当前最新结果。遍历完全部的分块后,我们就能得到和标准场景下完全一致的 \(O_i\)
下面是推导。

第十三步
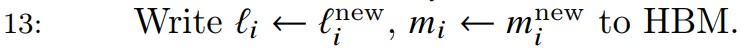
用 \(m^{new}_i\)和\(l^{new}_i\) 去更新 \(m_i\),\(l_i\)。
即将最新的累加到统计数据(l_i & m_i)写回HBM。注意它们的维数是B_r。
总结m,l的操作如下。
第十四、十五、十六步
嵌套的for循环结束,O将包含最终结果:每个输入令牌的注意力加权值向量

总结
我们用下图总结算法。再来看伪代码5-13行,你会发现,在整个计算过程中,只有 \(m_i\),\(l_i\),\(O_i\) 被从on-chip的SRAM中写回到显存(HBM)中。把 i 都遍历完后,读写量也不过是 m,l, O 。而在标准场景下,我们要读写的是 S,P,O。所以,分块计算safe softmax的意义,就是抹去对 S,P 的读写,从而减少内存需求。
0x05 计算量与显存占用
5.1 IO复杂度
我们首先假定N是Sequence的长度,d是attention head的维度,M是SRAM大小。
标准注意力
通过前面的空间复杂度分析,attention 运算需要占据的显存空间随着序列长度 n 的增长呈平方级增长。由于运算需要在 GPU 的 SRAM上 完成,这一过程需要不停地在 HBM 和 SRAM 之间交换数据,因此会导致大量的时间都消耗在 SRAM 和 HBM 之间的数据的换入换出上。

根据参与计算的各矩阵大小,可以分析它的MAC次数(以访问单个float值为基准)。
-
计算S。算法中第一行,从HBM中读取\(Q,K \in R^{N \times d}\),读MAC次数是2Nd,计算 \(S=QK^T \in R ^{N \times N}\),然后将
S写回 HBM,写MAC次数是\(N^2\)。总IO次数是\(O(Nd + N^2)\)。 -
计算P。算法中的第二行,从 HBM 中读取\(S=QK^T \in R ^{N \times N}\),读MAC次数是 \(N^2\) ,计算\(P = softmax(S))\),将\(P=QK^T \in R ^{N \times N}\)写回 HBM,IO次数是\(O(N^2)\)。
-
计算O。算法中的第三行,从 HBM 中读取\(P=\in R ^{N \times N}\),读MAC次数是 \(N^2\) ,读取\(V \in R^{N \times d}\),读MAC次数是Nd,计算 \(O=PV\),将\(O \in R^{N \times d}\)写回 HBM,写MAC次数是Nd,IO次数是\(O(Nd + N^2)\)。
上述所有加起来的总MAC开销为 \(4Nd+4N^2\) 。忽略掉其中的常数项,可以将复杂度写为 \(O(Nd+N^2)\) 。所以总的来说,标准的 Attention 计算的访存复杂度为\(O(Nd + N^2)\)。
计算 \(P=QK^T \in R ^{N \times N}\),\(O=PV \in R ^{N \times N}\),得到注意力权重的计算强度:
FlashAttention
从具体代码角度来看,
- 外层加载K, V小块,每个小块是\(R^{B_c \times d}\)。第6行把K,V的每个块都只加载一次,每次HBM的MAC是\(B_c \times d\)。外循环为 \(T_c\) 次。所以总的是\(T_c \times B_c \times d\) 。
- 内循环加载Q和O小块,每个小块是\(R^{B_r \times d}\)。第8行把Q, O 的每个块都只加载了一次,第12行回写了O的分块。综合来看就是内循环把 Q,O 整体都加载了进来。内循环的次数是\(T_r\),结合外循环看,总的就是$ T_c \times T_r \times B_r \times d$。
因此总的IO是\(O(T_c \times B_c \times d + T_c \times T_r \times B_r \times d) = O(Nd+T_cNd) = O(T_cNd)\)。
因为$T_c=⌈\frac{N}{B_c}⌉=⌈\frac{4Nd}{M}⌉ \(,所以FlashAttention总IO为\)O(N2d2/M)\(。d一般为64或者128,M通常为100K左右,因此\)d^2/M$ 远小于1。所以FlashAttention v1的MAC远小于标准的Transformer。

反向传播
以上是关于FlashAttention v1整个前向过程(Forward Pass)的细节。反向过程(Backward Pass)就不再赘述了,因为它本质上和前向高度相关,且思路接近。唯一需要额外解释的是,在反向过程中,除了采用了类似前向过程的方法来降低MAC之外,还使用了一些技巧来降低整体Memory的开销,比如:
- 反向传播需要矩阵 P 和 S 来计算关于 Q 、 K 和 V 的梯度。但是可以通过保存输出 O 和最大值 m 、EXP求和项 l 来重算矩阵 P 和 S ,从而节省内存开销。
- 通过保存前向过程的随机数生成器的状态,来在反向过程中生成Dropout的Mask,从而节约存储所有Dropout Mask的开销。
5.2 计算复杂度
标准注意力
时间复杂度方面,attention 需要对矩阵 Q 和矩阵 K 的转置做乘法来得到注意力权重矩阵。不考虑 batch 维度,假设矩阵 Q 和 K 的尺寸都为 (n, dim),一个 (n, dim) 和 (dim, n) 的矩阵相乘的时间复杂度是序列长度 n 的平方级,即 attention 的时间复杂度为 $O(N^2) $。当序列较长(即 n 较大)时,attention 的计算非常耗时。
假设输入序列长度为N,维度是d,分成h个头,对应Attention的计算过程分为以下步骤:
- 线性变换:对输入序列进行线性变换,得到 Q、K、V 三个矩阵。假设每个 token 的 embedding 维度为 k,则该步骤的复杂度为 \(O(N * k * 3d)\)。
- 计算相似度得分:通过 Q、K 两个矩阵计算相似度得分,得到注意力权重矩阵。注意力权重矩阵的大小为 N * N,计算该矩阵的时间复杂度为 \(O(N^2 * d * h)\)。
- 加权求和:将注意力权重矩阵与 V 矩阵相乘并加权求和,得到最终输出。该步骤的复杂度为 \(O(N * d * h)\)。
因此,Attention 的总计算复杂度为约为\(O(N^2)\)。
FlashAttention
计算量主要来源于矩阵乘法。
- 第9行,FLOPs为$$FLOPs=O(B_rB_cd)$$。
- 第12行,FLOPs为$$FLOPs=O(B_rB_cd)$$。
- 循环总次数 \(T_cT_r\),总的\(FLOPs=O(T_c \times T_r \times B_c \times B_r \times d)=O(\frac{N^2}{B_cB_r}B_rB_cd)=O(N^2d)\)。与标准 attention 计算一致。

0xFF 参考
https://arxiv.org/abs/2410.01359
A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library. https://research.colfax-intl.com/wp-content/uploads/2023/12/colfax-flashattention.pdf
Andrew Kerr. Gtc 2020: developing cuda kernels to push tensor cores to the absolute limit on nvidia a100. May 2020.
FLASHDECODING++: FASTER LARGE LANGUAGE MODEL INFERENCE ON GPUS. https://arxiv.org/pdf/2311.01282.pdf
Flash-Decoding for long-context inference. https://crfm.stanford.edu/2023/10/12/flashdecoding.html
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. https://arxiv.org/abs/2307.08691
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. https://arxiv.org/pdf/2205.14135.pdf
FlashMask: Efficient and Rich Mask Extension of FlashAttention. https://arxiv.org/abs/2410.01359
FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention. https://pytorch.org/blog/flexattention/
From Online Softmax to FlashAttention. https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
Maxim Milakov and Natalia Gimelshein. Online normalizer calculation for softmax. CoRR, abs/1805.02867, 2018.
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. https://arxiv.org/pdf/1909.08053.pdf
Self-attention Does Not Need O(n^2) Memory https://arxiv.org/abs/2112.05682
The I/O Complexity of Attention, or How Optimal is Flash Attention? https://arxiv.org/pdf/2402.07443.pdf
(Beta) Implementing High-Performance Transformers with Scaled Dot Product Attention (SDPA)
Antinomi:FlashAttention核心逻辑以及V1 V2差异总结
Decode优化-Lean Attention 手抓饼熊
Flash Attention V2 的 Triton 官方示例学习[forward] 来自L77星云
Flash Attention on INTEL GPU 毛毛雨
FlashAttention v2论文温故 进击的Killua
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention:加速计算,节省显存, IO感知的精确注意力 回旋托马斯x
FlashAttentions Chenfan Blog
FlashAttention图解(如何加速Attention) Austin
FlashAttention核心逻辑以及V1 V2差异总结 Antinomi
FlashAttention算法详解 deephub
FlashAttention计算过程梳理 胖胖大海
From Online Softmax to FlashAttention by Zihao Ye
From Online Softmax to FlashAttention
GitHub: LLMForEverybody
LLM 推理加速技术—— Flash Attention 的算子融合方法 sudit
NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能
紫气东来
Online normalizer calculation for softmax (arxiv.org) Maxim Milakov and Natalia Gimelshein. Online normalizer calculation for softmax. CoRR, abs/1805.02867, 2018.
Online normalizer calculation for softmax
Scaled Dot Product Attention (SDPA) 在 CPU 上的 性能优化 Mingfei
[ 大模型训练 ] FlashAttention v1、v2 - 最清晰的公式推导 && 算法讲解 Alan小分享
[Attention优化][2w字]🔥原理&图解: 从Online-Softmax到FlashAttention V1/V2/V3 DefTruth
[Attention优化][万字]🔥TensorRT 9.2 MHA/Myelin Optimize vs FlashAttention-2 profile DefTruth
[FlashAttention][2w字]🔥原理&图解: 从Online-Softmax到FlashAttention-1/2/FlashDecoding/FlashDecoding++ DefTruth
flash attention论文及源码学习 KIDGINBROOK
flashattention1-2-3 系列总结 Zhang
https://github.com/Dao-AILab/flash-attention
online-softmax 论文解读 Zhang
ops(7):self-attention 的 CUDA 实现及优化 (上) 紫气东来
ops(8):self-attention 的 CUDA 实现及优化 (下) 紫气东来
【手撕LLM-FlashAttention2】只因For循环优化的太美 小冬瓜AIGC
【手撕LLM-FlashAttention】从softmax说起,保姆级超长文!! 小冬瓜AIGC
【手撕Online Softmax】Flash Attention基础,一问一个不吱声!!! 小冬瓜AIGC [手撕LLM](javascript:void(0)😉
一心二用的Online Softmax TaurusMoon
万字长文详解FlashAttention v1/v2 Civ
万字长文详解FlashAttention v1/v2 Civ
使用cutlass cute复现flash attention 66RING
回旋托马斯x:FlashAttention:加速计算,节省显存, IO感知的精确注意力
图解大模型计算加速系列:Flash Attention V2,从原理到并行计算 猛猿
图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑 猛猿
大模型解析之Flash Attention 猩猩滚雪球
大模型训练加速之FlashAttention系列:爆款工作背后的产品观 方佳瑞
学习Flash Attention和Flash Decoding的一些思考与疑惑 稻壳特溯
我的 Transformer 加速笔记(一):FlashAttention 篇 delin
手撕Flash Attention!原理解析及代码实现 [
手撕Flash Attention!原理解析及代码实现 晚安汤姆布利多
线性Attention的探索:Attention必须有个Softmax吗? By 苏剑林
细嚼慢咽地学习FlashAttention2-举例子1 迷途小书僮
细嚼慢咽地学习FlashAttention 迷途小书僮
详细推导 Flash Attention 怪兽
通俗易懂聊flashAttention的加速原理 Tim在路上
通透理解FlashAttention与FlashAttention2:让大模型上下文长度突破32K的技术之一 v_JULY_v
降低Transformer复杂度O(N^2)的方法汇总(一) Civ
降低Transformer复杂度O(N^2)的方法汇总(二) Civ
https://tridao.me/publications/flash2/flash2.pdf
从Coding视角出发推导Ring Attention和FlashAttentionV2前向过程 杨鹏程
结合代码聊聊FlashAttentionV3前向过程的原理 杨鹏程